Computer vision
16 min read
—


Become the image annotation pro and start building AI models for your computer vision projects. Learn about different annotation types and get access to free tools, datasets, and resources.

Hmrishav Bandyopadhyay
Guest Author

Garbage in, garbage out.
This concept rules the computer science world, and for a reason.
The quality of your input data determines the quality of the output. And if you are trying to build reliable computer vision models to detect, recognize, and classify objects, the data you use to feed the learning algorithms must be accurately labeled.
And here comes the bad news—
Image annotation is a whole lot more nuanced than most people realize. And annotating your image data incorrectly can be expensive.
Very expensive.
Luckily, you've come to the right place.
In the next few minutes, we'll explain to you the ins and outs of image annotation and walk you through some of the best practices to ensure that your data is properly labeled.
Here’s what we’ll cover:
What is image annotation?
How does image annotation work?
Tasks that need annotated data
Types of image annotation shapes
How to find quality image data
Image annotation using V7

Data labeling
Data labeling platform
Get started today
And hey—in case you want to skip the tutorial and start annotating your data right away, check out:
What is image annotation?
Image annotation is the process of labeling images in a given dataset to train machine learning models.
When the manual annotation is completed, labeled images are processed by a machine learning or deep learning model to replicate the annotations without human supervision.
Image annotation sets the standards, which the model tries to copy, so any error in the labels is replicated too. Therefore, precise image annotation lays the foundation for neural networks to be trained, making annotation one of the most important tasks in computer vision.
The process of a model labeling images on its own is often referred to as model-assisted labeling.
Image annotations can be performed both manually and by using an automated annotation tool.
Auto annotation tools are generally pre-trained algorithms that can annotate images with a certain degree of accuracy. Their annotations are essential for complicated annotation tasks like creating segment masks, which are time-consuming to create.
In these cases, auto-annotate tools assist manual annotation by providing a starting point from which further annotation can proceed.
Manual annotation is also generally assisted by tools that help record key points for easy data labeling and storage of data.
Pro tip: Looking for other options? Check out 13 Best Image Annotation Tools.
Why does AI need annotated data?
Image annotation creates the training data that supervised AI models can learn from.
The way we annotate images indicates the way the AI will perform after seeing and learning from them. As a result, poor annotation is often reflected in training and results in models providing poor predictions.
Annotated data is specifically needed if we are solving a unique problem and AI is used in a relatively new domain. For common tasks like image classification and segmentation, there are pre-trained models often available and these can be adapted to specific use cases with the help of Transfer Learning with minimal data.
Training a complete model from scratch, however, often requires a huge amount of annotated data split into the train, validation, and test sets, which is difficult and time-consuming to create.
Unsupervised algorithms on the other hand do not require annotated data and can be trained directly on the raw collected data.
How does image annotation work?
Now, let's get into the nitty-gritty of how image annotation actually works.
There are two things that you need to start labeling your images: an image annotation tool and enough quality training data. Amongst the plethora of image annotation tools out there, we need to ask the right questions for finding out the tool that fits our use case.
Choosing the right annotation tool requires a deep understanding of the type of data that is being annotated and the task at hand.
You need to pay particular attention to:
The modality of the data
The type of annotation required
The format in which annotations are to be stored
Given the huge variety in image annotation tasks and storage formats, there are various tools that can be used for annotations. From open-source platforms, such as CVAT and LabelImg for simple annotations to more sophisticated tools like V7 for annotating large-scale data.
Furthermore, annotation can be done on an individual or organizational level or can be outsourced to freelancers or organizations offering annotation services.
Here's a quick tutorial on how to start annotating images.
1. Source your raw image or video data
The first step towards image annotation requires the preparation of raw data in the form of images or videos.
Data is generally cleaned and processed where low quality and duplicated content is removed before being sent in for annotation. You can collect and process your own data or go for publicly available datasets which are almost always available with a certain form of annotation.
Pro tip: You can find quality data for your computer vision projects here: 65+ Best Free Datasets for Machine Learning.
2. Find out what label types you should use
Figuring out what type of annotation to use is directly related to what kind of task the algorithm is being taught. In case the algorithm is learning image classification, labels are in the form of class numbers. If the algorithm is learning image segmentation or object detection, on the other hand, the annotation would be semantic masks and boundary box coordinates respectively.
3. Create a class for each object you want to label
Most supervised Deep Learning algorithms must run on data that has a fixed number of classes. Thus, setting up a fixed number of labels and their names earlier can help in preventing duplicate classes or similar objects labeled under different class names.
V7 allows us to annotate based on a predefined set of classes that have their own color encoding. This makes annotation easier and reduces mistakes in the form of typos or class name ambiguities.

Object classes in V7
4. Annotate with the right tools
After the class labels have been determined, you can proceed with annotating your image data.
The corresponding object region can be annotated or image tags can be added depending on the computer vision task the annotation is being done for. Following the demarcation step, you should provide class labels for each of these regions of interest. Make sure that complex annotations like bounding boxes, segment maps, and polygons are as tight as possible.
5. Version your dataset and export it
Data can be exported in various formats depending upon the way it is to be used. Popular export methods include JSON, XML, and pickle.
For training deep learning algorithms, however, there are other formats of export like COCO, Pascal VOC which came into use through deep learning algorithms designed to fit them. Exporting a dataset in the COCO format can help us to plug it directly into a model that accepts that format without the additional hassle of accommodating the dataset to the model inputs.
V7 supports all of these export methods and additionally allows us to train a neural network on the dataset we create.
Pro tip: Check out V7 Dataset Management.
How long does Image Annotation take?
Annotation times are largely dependent on the amount of data required and the complexity of the corresponding annotation. Simple annotations which have a limited number of objects to work on are faster than annotations containing objects from thousands of classes.
Similarly, annotations that require the image to be tagged are much faster to complete than annotations involving multiple keypoints and objects to be pinpointed.
Tasks that need annotated data
Now, let's have a look at the list of computer vision tasks that require annotated image data.
Image classification
Image classification refers to the task of assigning a label or tag to an image. Typically supervised deep learning algorithms are used for Image Classification tasks and are trained on images annotated with a label chosen from a fixed set of predefined labels.
Annotations required for image classification come in the form of simple text labels, class numbers, or one-hot encodings where a zero list containing all possible unique IDs is formed—and a particular element from the list based on the class label is set to one.
Often other forms of annotations are converted into one-hot form or class ID form before the labels are used in corresponding loss functions.
Object detection & recognition
Object detection (sometimes referred to as object recognition) is the task of detecting objects from an image.
The annotations for these tasks are in the form of bounding boxes and class names where the extreme coordinates of the bounding boxes and the class ID are set as the ground truth.
This detection comes in the form of bounding boxes where the network detects the bounding box coordinates of each object and its corresponding class labels.

Image classification vs. Object detection
Image segmentation
Image segmentation refers to the task of segmenting regions in the image as belonging to a particular class or label.
This can be thought of as an advanced form of object detection where instead of approximating the outline of an object in a bounding box, we are required to specify the exact object boundary and surface.
Image segmentation annotations come in the form of segment masks, or binary masks of the same shape as the image where the object segments from the image mapped onto the binary mask are marked by the corresponding class ID, and the rest of the region is marked as zero. Annotations for image segmentation often require the highest precision for algorithms to work well.
Semantic segmentation
Semantic Segmentation is a specific form of image segmentation where the algorithm tries to divide the image into pixel regions based on categories.
For example, an algorithm performing semantic segmentation would group together a group of people under a common category person, creating a single mask for each category. Since the differentiation between different instances or objects of the same category is not done, this form of segmentation is often known as the simplest segmentation task.

Instance segmentation
Instance segmentation refers to the form of segmentation where the task is to separate and segment object instances from the image. Instead of singling out the categories from the image, instance segmentation algorithms work to identify and separate similar objects from groups.
Panoptic segmentation
Panoptic segmentation can be referred to as the conjunction of both semantic and instance segmentation where the algorithm has to segment out both object categories while paying attention to instance level segments.
This ensures that each category, as well as the object instance, gets a segment map for itself. Needless to say, this segmentation task is often the hardest amongst the three as the amount of information to be regressed by the network is quite large.

Semantic Segmentation vs. Instance Segmentation vs. Panoptic Segmentation
Types of image annotation shapes
Different tasks require data to be annotated in different forms so that the processed data can be used directly for training.
While simple tasks like classification require the data to be annotated only with simple tags, complex tasks like segmentation and object detection require the data to have pixel map annotations and bounding box annotations respectively.
We've listed below a compilation of the different forms of annotation used for these tasks.
Bounding box
Bounding box annotations, as the name suggests, are annotations that require specific objects in an image to be covered by a bounding box. These annotations are generally needed for object detection algorithms where the box denotes the object boundaries.
They are generally not as precise as segmentation or polygonal annotations but meet the precision needed in detector use cases. These annotations are often used for training algorithms for self-driving cars and in intelligent video analytics mechanisms.

Polygon
Polygon masks are generally more precise as compared to bounding boxes. Similar to bounding boxes, polygon masks try to cover an object in an image with the help of a polygon.
The increased precision comes from the increased corners that a polygon can have as compared to the restricted four vertex mask in bounding boxes. Polygonal masks do not occupy much space and can be vectorized easily, thus creating a balance between space and accuracy.
These masks are used to train object detection and semantic segmentation algorithms. Polygon masks find their use in annotations for medical imaging data and n natural data involving scene text for scene text recognition and localization.

Polygon annotation using V7
3D cuboid
Cuboidal annotations are an extension of object detection masks in the three-dimensional plane. These annotations are essential when detection tasks are performed on 3-dimensional data, generally observable in medical domains in the form of scans.
These annotations might also find use in training algorithms for the motion of robots and cars and in the usage of robotic arms in a three-dimensional environment.

Semantic segmentation
Semantic annotations form one of the most precise forms of annotation, where the annotation comes in the form of a segmented mask of the same dimension as the input, with pixel values concerning the objects in the input.
These masks find wide-scale applicability in various forms of segmentation and can also be extended to train object detection algorithms. Semantic masks come in both two-dimensional and three-dimensional forms and are developed in correspondence with the algorithm they are required for.
Semantic segmentation finds a wide range of use in computer vision for self-driving cars and medical imaging. In medical imaging, segmentation helps in the identification and localization of cells, enabling the formulation of an understanding of their shape features like circularity, area, and size.
Pro tip: Check out 7 Life-Saving AI Use Cases in Healthcare.
In self-driving cars, segmentation helps to single out pedestrians and obstacles in the road, reducing road accidents considerably.
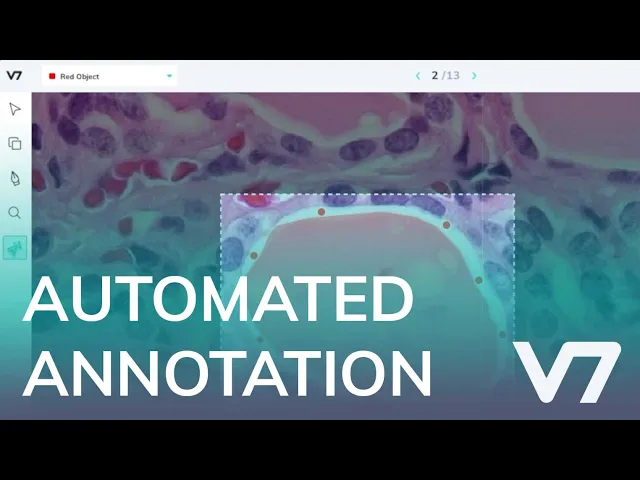
V7 allows us to perform fast and easy segmentation annotation with the help of the auto-annotate tool.
While the creation of segment masks requires a huge amount of time, auto annotate works by creating a segmented mask automatically on a specified region of interest.

V7 polygon mask auto-annotation
Polyline
Polyline annotations come in the form of a set of lines drawn across the input image called polylines. These Polylines are used to annotate boundaries of objects and find use cases primarily in tasks like lane detection which require the algorithm to predict lines as compared to classes.
High precision polyline annotations can help train algorithms for self-driving cars to choose lanes accurately and ascertain “drivable regions” to safely navigate through roads.

Polyline annotation in V7
Keypoint/Landmark
Keypoint or landmark annotations come in the form of coordinates that pinpoint the location of a particular feature or object in an image. Landmark annotations are mainly used to train algorithms that scrutinize facial data to find features like eyes, nose, and lips, and correlate them to predict human posture and activity.
Apart from finding use in facial datasets, landmarks are also used in gesture recognition, human pose recognition, and counting objects of a similar nature in an image. V7 allows you to pre-shape skeleton backbones that can be used to construct landmarks in no time by overlaying the corresponding shape on an image.
For more information, check out the tutorial on skeletal annotations here:

How to find quality image data
High-quality annotated data is not easy to obtain.
If data of a particular nature is not available in the public domain, annotations have to be constructed from raw collected data. This often includes a multitude of tests to ensure that the processed data is free from noise and is completely accurate.
Here are a few ways to obtain quality image data.
Open datasets
Open datasets are the easiest source of high-quality annotated data. Large-scale datasets like Places365, ImageNet, and COCO are released as a byproduct of research and are maintained by the authors of the corresponding articles. These datasets, however, are used mainly by academic researchers working on a better algorithm as commercial usage is typically restricted.
Pro tip: Check out 20+ Open Source Computer Vision Datasets.
Self annotated data
As an alternative to open datasets, you can collect and annotate raw data.
While raw data can be in the form of captured images with the help of a camera, it can also be obtained from open source webpages like CreativeCommons, Wikimedia, and Unsplash. Open source images form an excellent source of raw data and reduce the workload of dataset creation immensely.
Captured image data can also be in the form of medical scans, satellite imagery, or drone photographs.
Pro tip: Read Data Annotation Tutorial: Definition, Tools, Datasets.
Scrape web data
Web scraping refers to scourging the internet for obtaining images of a particular nature with the help of a script that runs searches repeatedly and saves the relevant images.
While scraping web data is an easy and fast method of obtaining data, this data is almost always in a very raw form and has to be cleaned thoroughly before any algorithm or annotation can be performed. Since scraping can help us gather images based on the query we set it up with, the images are already known to belong to a certain class or topic.
This makes annotation much easier, particularly for tasks like classification which require only a single tag for each image.





Image annotation using V7
V7 provides a lot of tools that are useful for image annotation. All of the tools discussed in this post are covered by V7 as part of their data annotation services.
Here’s a quick guide on getting started with image annotation using V7.
1. Collect, prepare, and upload your image data
Upload your data using the data upload feature on the webpage or use the command-line interface (CLI) facilitated by Darwin.

Data import in V7
V7 offers advanced dataset management features that allow you to easily organize and manage your data from one place.
2. Choose the annotation type/class label
Choose the annotation type for a specific class from the list of available annotations. You can change this or add new classes anytime by going to the “Classes” tab located on the left side of the interface. You can also add a short description of the annotation type and class to help other annotators understand your work.

Annotation class creation on V7
3. Start annotating
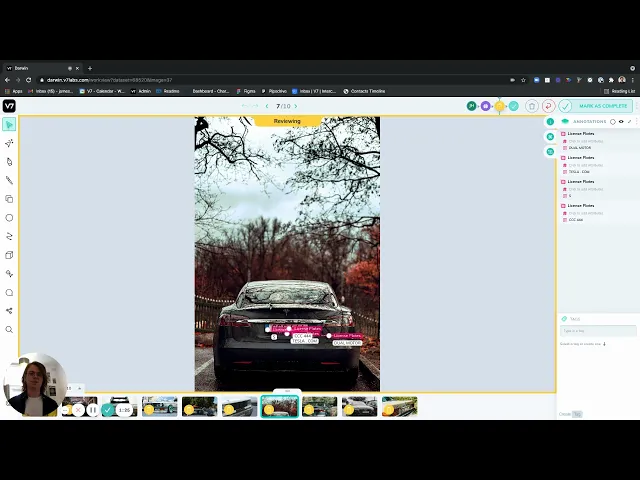
Finally, start annotating your data either manually or using V7's auto-annotation tool.
V7 offers a real-time collaborative experience so that you can get your whole team on the same page and speed up your annotation process. To describe your image in greater detail, you can add sub annotations such as:
Instance ID
Attributes
Text
Direction Vector
You can also add comments and tag your fellow teammates. And hey—don’t forget the hotkeys.
V7 comes equipped with several built-in power user shortcuts to speed up your annotation process and avoid fatigue.
Apart from that, you can also perform OCR by using V7's built-in public Text Scanner model.
Got questions?
Feel free to get in touch with our team to discuss your project.
Key takeaways
Data collection and annotation is one of the most cumbersome parts of working with data.
Yet it forms the baseline for training algorithms and must be performed with the highest precision possible. Proper annotation often saves a lot of time in the later stages of the pipeline when the model is being developed.
Curious to learn more? Check out:

Hmrishav Bandyopadhyay
Hmrishav Bandyopadhyay studies Electronics and Telecommunication Engineering at Jadavpur University. He previously worked as a researcher at the University of California, Irvine, and Carnegie Mellon Univeristy. His deep learning research revolves around unsupervised image de-warping and segmentation.









