Data labeling
21 min read
—


How do you choose the best data labeling tools for your use case? Let’s review 10 key functionalities you should consider while taking a closer look at 6 industry-leading companies in 2024.

Marta Szyndlar
Content Specialist

Data labeling remains at the foundation of building any AI product.
However, high-quality training data isn't enough to develop a truly mature, profitable, and market-ready AI. For this, you need a solid data management infrastructure—with a reliable data labeling tool at its core.
Yet, despite the flourishing market of data labeling and management companies, an IBM report revealed that 24% of global organizations cited “lack of tools or platforms to develop models” and “too much data complexity” as some of the main hindrances to AI adoption.
Fortunately, these obstacles can be overcome by ensuring your data labeling process is part of a centralized, automated MLOps pipeline. With the perfect training data toolkit in place, you should be able to seamlessly integrate with the rest of your tech stack, allowing you to build AI products faster, more cost-efficiently, and with reduced risk.
Despite this, picking third-party data labeling software best suited for your needs is challenging. There’s a wide array of platforms to choose from, while the rapidly shifting standards of the AI landscape make platform evaluation and comparison difficult. On top of that, the time-to-value and cost-to-value ratios differ from use case to use case—a solution that worked perfectly for your competitor may not do the same for you.
To help with your decision, we’ve prepared this buying guide for data labeling tools. We’ll go through the ten factors you need to consider, provide an overview of the six most popular data labeling companies, and share a few extra resources—to help you choose a platform that can become your AI development partner for years to come.

Video annotation
AI video annotation
Get started today
What is data labeling?
Data labeling is the process of tagging raw data with labels containing at least one piece of information about the sample to provide context that machine learning models can learn from. Data labeling is crucial for training computer vision, natural language processing, or speech recognition models.
Choosing a data labeling tool: 10 key functionalities to consider
The main functionality of every data labeling tool is enabling you to annotate data quickly and precisely.
However, a platform worth your money will go far beyond that remit. Factors such as data security, quality of customer support, or QA capabilities are just as important to let you get maximum value out of your training data.
Let’s review the ten most important functionalities a data labeling software should have to support you in building a mature ML pipeline—primed to meet the challenges of even the most demanding projects.
Read more: The Enterprise Guide to Building AI-Powered Products
1. Data and annotation types
It goes without saying—the data labeling tool you choose should support all the data formats and annotation types your project requires.
While it may seem like a factor that’s easy to verify at first glance, it’s important to investigate the capabilities of each tool thoroughly.
Despite assurances from data labeling providers, you’ll want to ensure that your chosen platform actively invests in solutions for your industry. For example, if your goal is to annotate medical data, find a platform that specializes in the field, actively develops new features for the healthcare industry, and employs medical experts who will help you maximize your ROI.
Take advantage of the demos offered by each platform, and use them to ask about your specific data and annotation type needs—especially if you have a lot of edge cases with unique features that may require customization.
2. Security
It’s crucial that your data labeling tool offers enterprise-grade data security. This is the only way to guarantee that you can safely develop and scale your product and serve all kinds of global customers (including government and enterprise-level organizations).
Verify your data labeling tool’s organizational, access, and cloud security, as well as necessary compliance certifications (SOC 2, ISO 27001, GDPR, etc.). Integrations with cloud storage such as S3 can also keep your data secure, and comply with HIPAA and FDA standards. This approach will allow companies operating across the most rigorous verticals, such as healthcare or life sciences, to use external data labeling tools without security concerns.
3. Customer support
While many training data platforms do a great job providing effective data labeling features that streamline the data annotation process, no tool is infallible. You should ensure your chosen tool’s support team reacts rapidly to eliminate downtimes and bottlenecks, ensuring your product remains on track.
Truly stellar customer success and support teams go beyond trouble-shooting and become your partner in developing AI products. They offer industry and software expertise and actively improve your data labeling experience—by introducing you to new technologies, keeping up with your industry’s demands, and actively seeking solutions for your training data challenges and problems. Here are five things you should expect from a solid customer support team:
Rapid response times
In-depth knowledge of your use case (you’re in touch with a team of experts rather than “jacks of all trades”)
Strong AI product and industry knowledge that goes beyond the platform in question
Smooth cooperation between customer support, customer success, and engineering teams
Clear, honest communication
Beyond checking user reviews, the best way to check the quality of a platform’s customer support team is by scheduling demo calls to get to know the team better, ask questions, and gauge if you see them as a potential partner.
4. API, SDK, integrations
A data labeling tool is just one component of your MLOps pipeline, meaning seamless integration with the rest of your tech stack is non-negotiable.
Assess the APIs, SDK, and integration landscape of your data labeling tools to see if they seamlessly fit into your data pipeline. This ensures you can continue driving maximum value from your current tech stack while minimizing the downtime needed for set-up. Make sure your data labeling software integrates with your cloud provider and look into the data import and export capabilities to maintain a smooth and secure data flow.
Additionally, check any tool’s flexibility when it comes to incorporating webhooks or external models into your labeling workflows. Even if you don’t currently use them, choosing a platform that supports customization will guarantee you can effectively scale and refine your processes.
5. Quality assurance
Robust QA capabilities within your training data platform will not only help you ensure training data is in line with the most rigorous standards but will also streamline the annotation process by centralizing reviews and corrections.A worthwhile data labeling platform will allow you to adhere to the most demanding QA standards. For example, one of V7’s customers, IMIDEX, used our platform to set up complete clinical study workflows needed to obtain FDA clearance.
Read more: How Imidex uses V7 to Detect Pulmonary Nodules, Indicative of Lung Cancer
Investigate how a chosen tool’s workflows handle the QA stage and investigate whether the platform supports consensus labeling, sampling, benchmarking, or ease of re-queueing and restarting workflows.
6. Ease of use
An intuitive data labeling interface plays a crucial role in streamlining the annotation process and shortening the delivery times of projects—especially if annotators aren’t machine learning experts or you’re planning to onboard external labelers.
Make use of demos and free trials to take a tool for a test ride to check the ease of use hands on. If you have an in-house labeling team, make them a part of the decision-making process. After all, they’re the ones who will use the annotation interface the most often. You should also investigate the UI beyond just data labeling—check if setting up workflows, managing datasets, or training models is just as intuitive as advertised.
Tip: Check if a data labeling tool offers AI-assisted labeling and models-in-the-loop to accelerate annotation speed and make the labeling experience smoother for the annotators.
7. Labeling workforces
Unless you have a dedicated team of labelers already on board, check a platform’s labeling services. Many tools can assist you with employing industry-trained, expert labelers who deliver high-quality outputs.Using professional labelers provided by data annotation tools minimizes time-to-value since they’re already familiar with the software.
Usually, this solution is highly scalable—for example, at V7, we can add new labelers to your project within a day.
8. Data management and collaboration
Data management is a huge organizational challenge, even for AI industry leaders—so make sure you get it right from the start.
A data labeling platform with smart dataset management options will allow you to only label data that’s most relevant to your models. You’ll be able to lower data volumes while creating more accurate training sets—which, in turn, will minimize annotation costs, decrease time-to-market, and boost the quality of your products.
Ensure you have full visibility of your dataset at every step of the annotation pipeline. Real-time collaboration and the ability to assign tasks and track progress will help you take full control of your project, allowing your team to monitor annotator efficiency and efficacy, while removing bottlenecks before they become an issue.
Explore a data labeling tool’s capabilities regards filtering and querying, class balancing and overview, dataset versioning, and annotator metrics and reporting.
9. Model training and management
Even if you don’t plan to train your models on your chosen platform, look into the model management features of your data labeling tool.
Model-assisted labeling and the ability to integrate your own or open-source models into workflows are necessary if you want your data annotation process to be competitive. A robust platform will also let you efficiently train and fine-tune experimental models that you can later iterate on. With this in mind, look into the speed of model training and how little data you need to train a functioning version of a model.
10. Price
Price is an obvious point of comparison between different platforms and is often the key factor in decision-making.
However, even if you’re operating on a strict budget, we always advise against simply choosing the option with the lowest subscription costs. Evaluate tools based on final value—remember that what you gain with cheaper subscriptions, you can still lose from extending time to delivery or sacrificing product quality and market competitiveness. The ultimate goal is to find a platform that will let you prepare high-quality training data rapidly.
When considering the overall ROI of the platform, pay attention to the costs of:
Outsourcing labeling services
Data labeling—will the labeling platform’s solution significantly reduce the time spent on annotation?
The cost of your ML/DS workforce—can your platform of choice reduce the hours your in-house team currently spends on data labeling tasks?
All the training data workflow elements provided by the tool—can the platform cover most of your needs? Or maybe you require fewer features, for less money?
To help you make an informed decision, we’ve prepared a worksheet for evaluating and comparing training data platforms based on their core functionalities—with a scoring system for different stakeholders based on their typical concerns and metrics that matter to them.
Read more: Training Data Platform Buying Guide





6 best training data platforms—key features and use cases
Now that you know how to evaluate and compare data labeling tools, let’s look closely at six leading data labeling companies.
We’ve taken all 10 functionalities listed above into consideration, listed key features of each platform, and highlighted their most common use cases.
V7 Darwin
V7 Darwin is a powerful training data platform for building trustworthy AI faster. For over five years, V7 has been helping global businesses such as Bayer, Sony, or Abyss, manage their training data ops, datasets, model training, and 'human in the loop' element.
Data annotation
V7 delivers best-in-class annotation tooling, allowing its customers to solve labeling tasks quickly and accurately. The platform lets you annotate data across multiple formats, including videos (V7 boasts the world’s fastest video annotation tool—allowing for up to 100k frames) and medical images (such as DICOM, NIfTI). With a SAM-powered auto-annotation tool, you can minimize manual labeling time while maintaining pixel-perfect quality.
Model management
V7 offers a flexible model management solution that dramatically speeds up the time from data labeling to deployment. With V7-trained models, you can automate annotation tasks and speed up product development by building and testing your models on the job. You can also bring your own models (internal or external—V7 integrates with HuggingFace) and export V7 ones, allowing you total flexibility and ownership over your creations. V7 users report a 33% faster release of models and a 25% reduction in errors on average—within just 6 months of using the platform.
Workflows
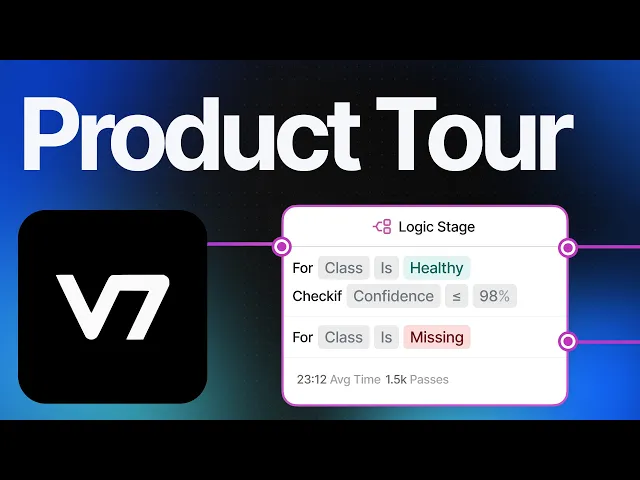
V7’s custom collaborative workflows allow you to build a complete machine learning pipeline—including dataset management, transparent review stages, model-assisted labeling, and quality assurance (take a look at V7’s consensus and logic stages). You can do all that with little to no code—but if you prefer, you can perform actions on your assets via a CLI or SDK.
Other features and services
Additionally, V7 supports AI document processing and offers on-demand labeling services (including highly specialized annotators, such as scientists, medical professionals, and more) to ensure you’re backed on all fronts. V7 is also frequently praised by customers for stellar customer support, resulting in a current G2 score of 9.8 in this category.
V7 adheres to rigid security standards, such as GDPR, ISO 27001, or SOC2, and remains HIPAA and FDA-ready. With multiple integrations, tech partnerships, and a flexible API, you can easily integrate it into your MLOPs pipeline.
Key features
Custom workflows that support multi-stage tasks (easy to set up by non-technical users—but also fully flexible thanks to imports and webhooks)
Industry-leading video labeling features (allowing for up to 100k frames)
Support for all image and video formats, including medical imaging (DICOM and NIfTI)
Support for unique file types (ultra-high-resolution, multi-spectral, microscopy formats, PDF) and frame-perfect video annotation
One-click model training tool for model building and fine-tuning
Pricing
V7 offers a lifetime-free plan for academic teams. For startup, business, and pro plans pricing, you can request a demo. Or, try V7 for free first!
Use if
You’re looking for a tool to power your training data pipeline, and you’re serious about scaling and ML pipeline automation. Also recommended if you’re looking for a highly specialized medical AI or video annotation solution.
Labelbox

Labelbox is a popular AI data engine with a mission to help organizations build cutting-edge Al products.
The platform provides solutions to:
Manage, curate, and analyze unstructured datasets to turn them into quality training data, with both traditional and vector search—powered by active learning
Annotate multiple image formats as well as videos (video segmentation currently in beta stage), audio, text, geospatial, and documents—with the help of workflows or on-demand labeling services
Enrich datasets and perform model-assisted labeling with foundation models added to the workflow. The platform also supports model comparison and testing, fine-tuning, and evaluation—including Large Language Models
Set up simple workflows and team management dashboards—however, some QA features, such as consensus and benchmarking, are limited to images. In case of other formats, they only support certain data types and are unavailable for videos.
Labelbox security and privacy policies are based on “privacy by design” rules and follow industry standards such as SOC 2, ISO 27001, and HIPAA. Labelbox supports a wide integration ecosystem and offers a flexible API and SDK. When it comes to customer support, Labelbox’s current G2 score is 9.2.
Key features
Model Foundry—a hub for foundation models to power up data workflows
Advanced data management and visualization solutions
Vector and similarity searches
Multiple supported data formats and annotation types, including medical and geospatial
Pricing
Labelbox offers a free plan for small teams, as well as starter and enterprise subscription tiers. The plans vary in the amount of data available to use—the pricing page includes a calculator to estimate your starting costs. If your data needs are larger, you need to contact the sales team.
Use if
You’re looking to work with and build LLMs, and the pay-for-what-you-use pricing model makes sense for your expected data volumes.
Scale AI

Scale AI is a well-known data engine, specializing in enterprise-grade AI, especially for government and automotive use cases. The platform allows you to manage your entire AI management cycle, from data preparation to product deployment.
Scale AI’s current focus is their toolkit for generative AI. It lets you compare, test, and deploy foundation models, build generative model applications, fine-tune base models, and use pre-built apps (such as chat or e-commerce solutions).
Scale AI’s specialty when it comes to data annotation is combining AI-based techniques with humans-in-the-loop. They provide their clients with pre-annotated data to minimize the time needed for model deployment. Their platform also offers data management and curation options, as well as workflows and QA processes suitable for industries of all sizes.
Scale AI’s offering is divided into different product tiers:
Scale Rapid for getting your data annotated by Scale AI’s organized workforce
Scale Studio, which allows you to bring your own team on board
Scale Pro, which combines all of the tool’s powers
Scale Nuclear for dataset management.
ScaleAI adheres to rigorous security standards and complies with SOC 2 Type II, HIPAA, and ISO 27001. In terms of customer support, Scale Rapid currently ranks 8.8 on G2.
ScaleAI leans towards generative AI solutions, catering to large enterprises and governments. If you’re a smaller business, and especially if your needs include medical data annotation or document processing, you may want to look elsewhere.
Key features
End-to-end generative AI platform
Scale Donovan: Specialized AI solution for federal level
AFM-1: Scale’s foundation model for automotive
3D LiDAR/RADAR annotation
Pricing
You can try out Scale’s data annotation and data management platform for free—after running out of the free labeling units, Scale Rapid users are charged per task. To learn the prices of the enterprise-grade solutions, Scale Data Engine and Generative AI Platform, you need to book a call with the sales team.
Use if
You’re an enterprise customer looking for a generative AI or autonomous driving platform, and you have a considerable budget.
Dataloop

Dataloop is an end-to-end data operating system for AI, spanning the entire data management cycle.
The platform lets you fine-tune foundation models, as well as optimize and customize LLMs and other generative AI models—powered by continuous learning, RLHF, and their prompt engineering studio.
Dataloop prides itself on data automation pipelines that speed up model deployment—you can build plugins and event-driven automations to tailor any workflow to your needs. The platform offers a visualization panel for all unstructured data, as well as an analytics dashboard.
With an API and Python SDK, you can further customize your workflows, as well as connect the tool to your tech stack. Dataloop also offers a few native integrations with top cloud providers.
The platform lets you label images and videos with the support of auto-annotation and models—you can bring your own or train them from scratch on the platform. Notably, Dataloop supports LiDAR data annotation.
Dataloop adheres to all the necessary security standards (including ISO/IEC/SOC2 certifications and GDPR compliance). Its customer support currently has an 8.3 rating on G2.
Be careful: if you’re looking for a medical data annotation tool, Dataloop is probably not for you. The platform does not support DICOM, ultrasound, or volumetric data formats and isn’t HIPAA-compliant.
Key features
Advanced workflows and data pipelines
Flexible data management options
LiDAR data annotation
Model-assisted labeling
Pricing
Dataloop doesn’t reveal any information on pricing and subscription tiers. To learn the prices and try out the tool, you need to book a demo call.
Use if
You’re looking for an end-to-end training data solution, especially if you’re dealing with aerial imagery and LiDAR and you don’t require complex workflows.
SuperAnnotate

SuperAnnotate, combines an all-in-one AI data infrastructure platform with integrated annotation services.
SuperAnnotate’s annotation platform lets you label images, videos, audio, text, and LiDAR, as well as fine-tune LLMs—with RLHF, instruction fine-tuning, image captioning, and more. Notably, the platform now offers an LLMs & GenAI Playground—a toolkit to try ready-made LLM and generative AI templates or build new ones—that you can use for free.
SuperAnnotate’s data management and curation toolkit lets you build balanced datasets, and it’s powered with features such as similarity search, random and smart sampling, and data generation. For project management, the platform supports automated workflows with review and consensus stages, as well as real-time analytics for better progress visibility and quality control. With SuperAnnotate, you can also train and fine-tune models, as well as connect your own models via an API.
SuperAnnotate follows strict security standards (SOC 2, ISO 27001, HIPAA, GDPR), and their customer support currently scores 9.9 on G2. They also offer a robust labeling workforce marketplace.
Superannotate is very labeling-oriented. If you’re looking to squeeze the most out of workflow automation or you require complex model management software, investigate other options.
Key features
Multiple data format support, including LiDAR, PDF, or different audio formats
Robust labeling services
LLMs & GenAI Playground
Advanced data management features
Pricing
SuperAnnotate offers a free plan for early-stage startups and academics/researchers. To learn the prices of pro and enterprise plans, you need to request a demo.
Use if
You’re looking for a good data labeling tool with a friendly UI and multiple format support, and you’re not interested in building complex project management pipelines or training large models on the platform.
Encord

Encord is an active learning platform for computer vision, focused on specialized data labeling and labeling-as-a-service.
The platform lets you annotate image and video data for most computer vision tasks. It supports the medical DICOM and NIfTI formats, ECG annotation solution, and synthetic-aperture radar (SAR) data, making it a viable choice for healthcare, aerospace, and defense professionals.
The tool also offers various workflow automations that let you auto-find errors, perform intelligent data searches, evaluate and debug models, and build active learning pipelines. Encord’s workflows are enhanced with in-depth ontologies and benchmarking, model-assisted QA, and API/SDK to connect the platform to your existing data pipelines. However, the drag-and-drop workflows don’t support consensus or logic stages.
Encord provides specialized, on-demand labeling services and an Annotator Training Module that lets you train, certify, and evaluate your labelers. Regarding customer support, the platform currently boasts an impressive 10 out of 10 on G2.
Key features
ECG annotation platform
Synthetic-aperture radar (SAR) annotations
Annotator Training Module
Advanced model fine-tuning features
Pricing
Encord offers a free trial. The prices for team and enterprise plans are available upon request.
Use if
You’re looking for a tool that supports ECG or SAR annotations and lets you set up active learning data pipelines—but you’re not planning to train your models on the platform.
Open-source data labeling tools: CVAT, LabelIMG, Labelme
If you’re seeking basic data labeling tools and not an MLOps platform, you can try one of the readily available open-source, free solutions.
There are a few key players on the market that will help you prepare datasets for most computer vision tasks. Check out our guides to learn more about:
If you’re only just starting your AI journey and don’t have huge datasets or complex workflow needs, we recommend you go with one of these free tools first. Test the waters and see what you’re missing the most—this will help you make a more informed decision when picking a paid solution later on.
Special mention: Building a data labeling tool in-house
Many companies, especially those that have dedicated in-house machine learning teams, have opted to build their own in-house data labeling tools. This approach was popular a few years ago when the machine-learning tool landscape was much less robust, and companies with more specialized training data needs were forced to develop their own solutions.
Nowadays, third-party tools have evolved to cater to the most specialized use cases. They can easily fit into existing MLOps pipelines through APIs, offer full data security, enable flexibility and scalability, and help standardize training data processes by creating one centralized data hub.
What’s more, for the price of a subscription, you also buy peace of mind—that the platform’s task-focused engineering team stays on top of technological advancements in AI and continues introducing new solutions. Keeping up with all the changes and implementing them in-house quickly and cost-effectively is either impossible or highly resource-consuming for most organizations.
The many conversations we’ve had with our tech partners and customers clearly point to the superiority of the “buy” approach. Nevertheless, consult your annotation, engineering, data operations teams, and executive stakeholders to learn their exact expectations, goals, and needs. We’ve also prepared a “build vs. buy” guide with a checklist to help you make an informed decision.
Read more: Build Vs. Buy? Tackling Training Data Ops Software
Final words
Picking the right data labeling tool for your needs is a huge challenge.
Before subscribing, ensure a platform fits seamlessly into your MLOps pipeline, and can become your AI development partner for years. Always take advantage of free trials and demos before making the final call, to ask use-case-specific questions, test features, and get to know the people behind the software.
We hope this guide helps you establish your priorities and shortlist your top candidates. And, if you’re still going through a “build vs. buy” dilemma, we always recommend buying—this approach helps most companies achieve much higher ROI.
So, test away, and pick the best data labeling tool for your use case! If you’re ready to start your research, check out V7 case studies to see how we already helped other businesses with their data labeling process. Alternatively, if you’re ready to get started—schedule a demo with the V7 customer team right now.

Marta Szyndlar
Content Specialist at V7
As a former Content Specialist in V7, Marta reported on the advancements in the AI landscape and the achievements of the V7 customers & team.









