LLMs
15 min read
—
In this article, we will dive deeper into RLHF. Let’s go through its core concepts and techniques and explore its transformative potential for AI applications.

Reinforcement Learning from Human Feedback (RLHF) is transforming the frontier of artificial intelligence.
Its impact is most notably seen in the state-of-the-art large language models such as ChatGPT. This revolutionary method of incorporating human feedback into the reinforcement learning model has improved the efficiency of AI applications while enhancing their alignment with human objectives.
Over the years, a wealth of research has blossomed around this concept, highlighting its versatility and applicability across various domains. The journey of RLHF, from its inception to its current state, is a testament to the innovative strides being made in the field of AI.
In this article, we will dive deeper into RLHF, explaining its core concepts and techniques, and exploring its transformative potential for AI applications. We will examine the RLHF training process and discuss its advantages and challenges.
Whether you're an AI practitioner, an AI enthusiast, or just curious about the latest developments in the field—read on.
Here’s what we’ll cover:
What is Reinforcement Learning From Human Feedback
RLHF and Large Language Models
RLHF training process: a step-by-step breakdown
RLHF in practice: ChatGPT
Benefits and limitations of RLHF
What’s next for RLHF

AI for document processing
Build AI agents that improve from real finance feedback
Get started today
And if you’re ready to jump right into training your own machine learning models, check out:
What is Reinforcement Learning with Human Feedback (RLHF)?
The concept of RLHF is simple: use a pretrained language model, then have humans assess and score the responses it generates. This human-curated ranking acts as a powerful signal to the model, directing it to favor certain outputs over others, encouraging the production of answers that are more dependable, more secure, and more in line with human expectations.
RLHF improves the model's understanding and generation of natural language by incorporating human feedback. Furthermore, it boosts its ability to execute particular jobs with greater precision, such as text classification or language translation.
It is possible to direct the model towards more fair and inclusive language use by incorporating human evaluators into the training loop, addressing biases in the machine's outputs. It is essential to remember, however, that human involvement can be a double-edged sword, as it might introduce biases from the human evaluators themselves.
Let's take a closer look at this groundbreaking method, how it works, and its significance in the ever-changing realm of artificial intelligence.
The roots of Reinforcement Learning (RL)
Before we fully understand RLHF, we must first grasp the fundamentals of Reinforcement Learning (RL).
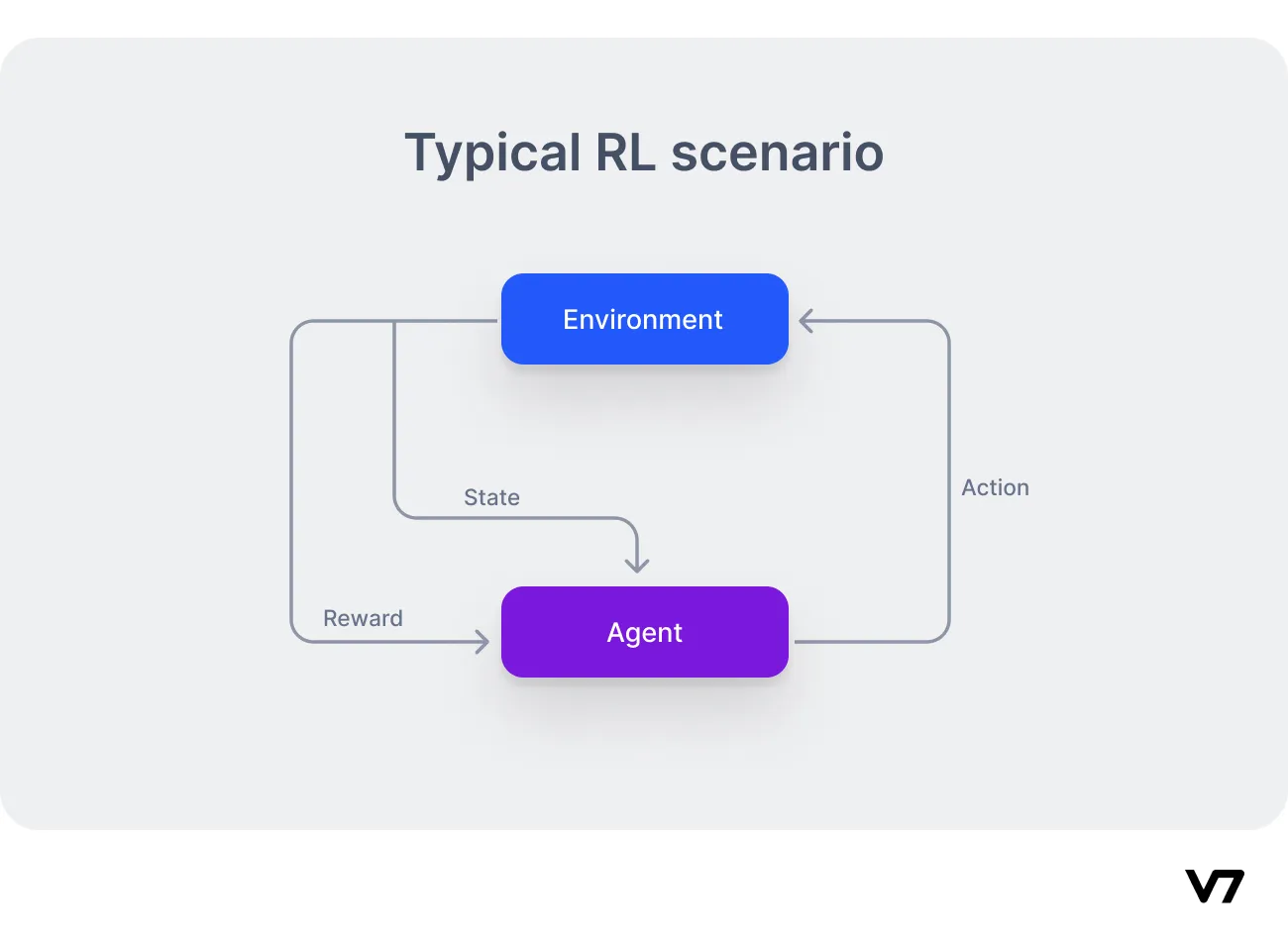
Reinforcement learning is a subset of machine learning where an agent learns to make decisions by interacting with its environment. It performs actions, affecting its environment, which subsequently transitions to a new state and returns a reward. This reward acts as feedback that helps the RL agent adjust its decision-making policy. Over multiple training episodes, the agent refines its policy to maximize its total reward.
Read more: The Beginner's Guide to Deep Reinforcement Learning
However, designing an effective reward system poses a significant challenge in reinforcement learning. In many applications, the reward is delayed, or in some cases, defining it with a mathematical or logical formula is not feasible.
Introducing humans into the equation
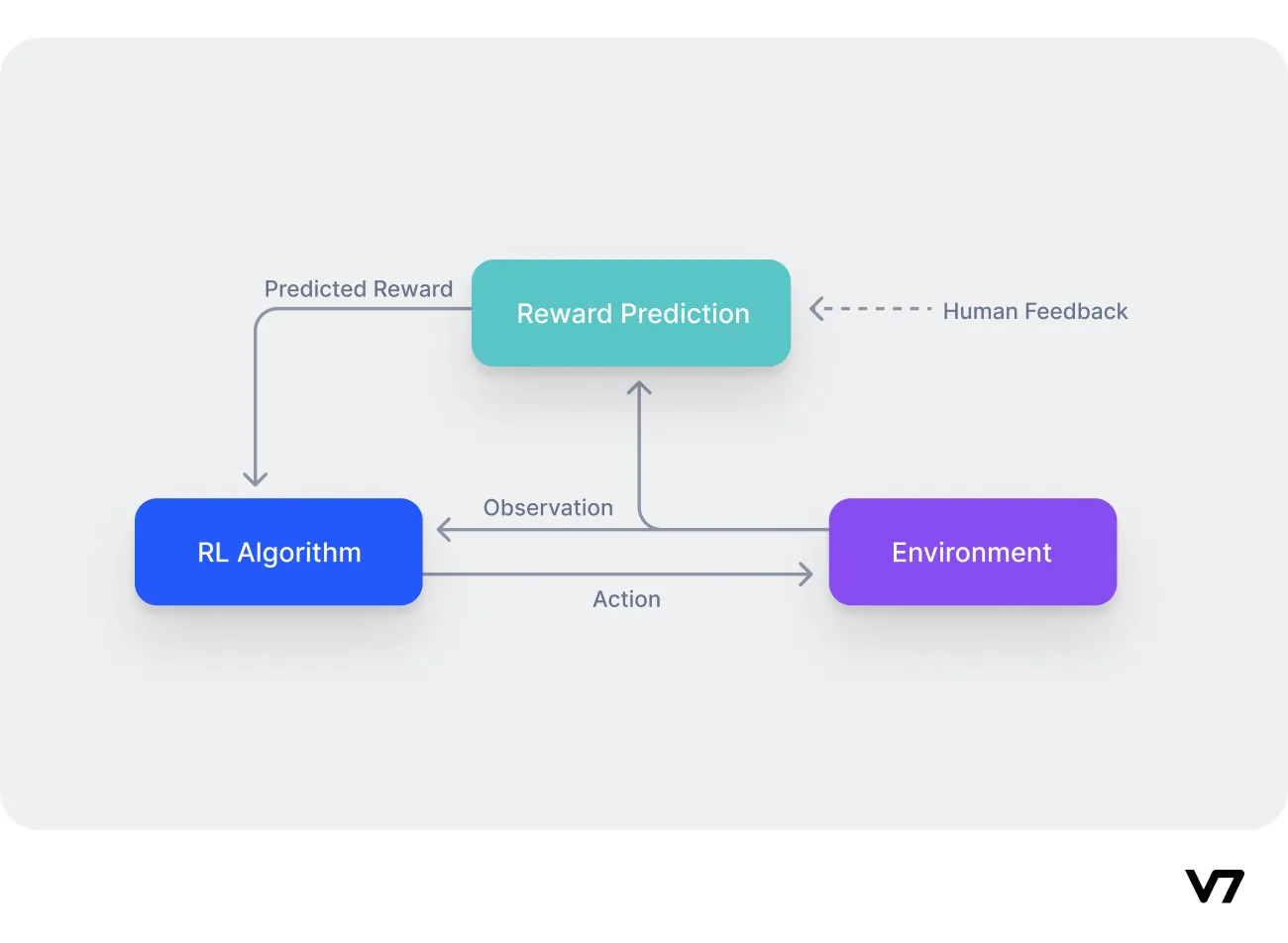
This is where RLHF comes into play. It augments the RL agent's training by including humans in the process, accounting for elements that can't be quantified in the automated reward system. However, scaling RLHF can be challenging as the involvement of humans in the training process can become a bottleneck. To overcome this, most RLHF systems yse a mix of automated and human-provided reward signals.
In an RLHF system, a human supervisor either provides an occasional extra reward/punishment signal or offers the data needed to train a reward model. This hybrid approach offers a balance between the scalability of machine learning and the nuanced understanding of human evaluators.
RLHF and Large Language Models (LLMs)
One area where RLHF has shown significant promise are Large Language Models (LLMs). LLMs, such as GPT-3, are excellent at various tasks, including text summarization, question answering, and more. Yet, they share a fundamental limitation—the inability to align the model with all possible applications it will be used in.
RLHF can help steer LLMs in the right direction by defining language as a reinforcement learning problem:
Agent: The language model acts as the reinforcement learning agent and learns to produce optimal text output.
Action Space: The set of possible language outputs that the LLM can generate.
State Space: Includes the user prompts and the outputs of the LLM.
Reward: Measures the alignment of the LLM's response with the application's context and the user's intent.
However, the reward system in this setup is not well defined. This is where Reinforcement Learning From Human Feedback proves invaluable, allowing the creation of a robust reward system for our language model.
Read more: Large Language Models (LLMs): Challenges, Predictions, Tutorial
RLHF training process: a step-by-step breakdown
As we delve deeper into the intricate mechanisms of the Reinforcement Learning from Human Feedback (RLHF) algorithm, it's important to keep in mind the relation between the algorithm and its foundational component: the pretraining of a Language Model (LM).
Let’s break down each step of the RLHF algorithm.
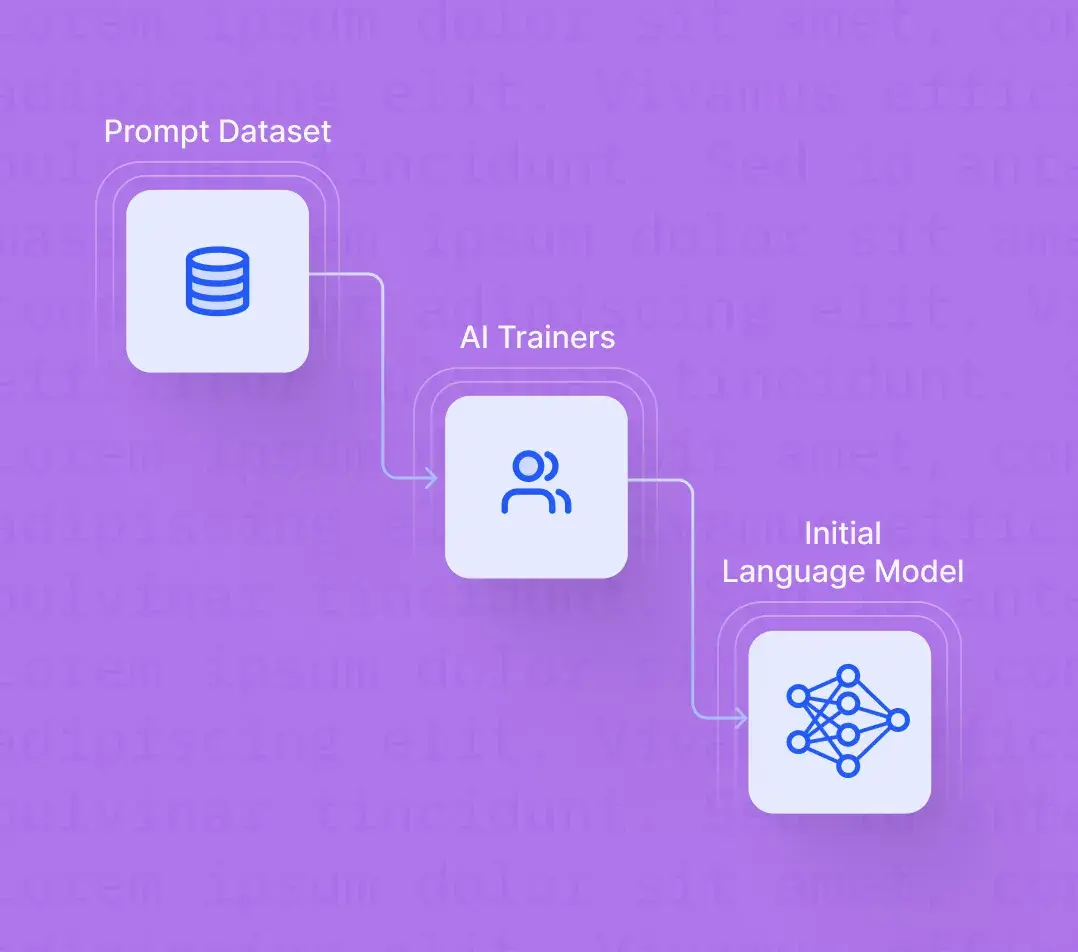
Pretraining a language model (LM)
The pretraining process forms the foundation for RLHF. At this stage, a language model (LM) is trained on a large corpus of text data collected from the internet. This data helps the LM understand various nuances of human language, including syntax, semantics, and even some context-specific information.
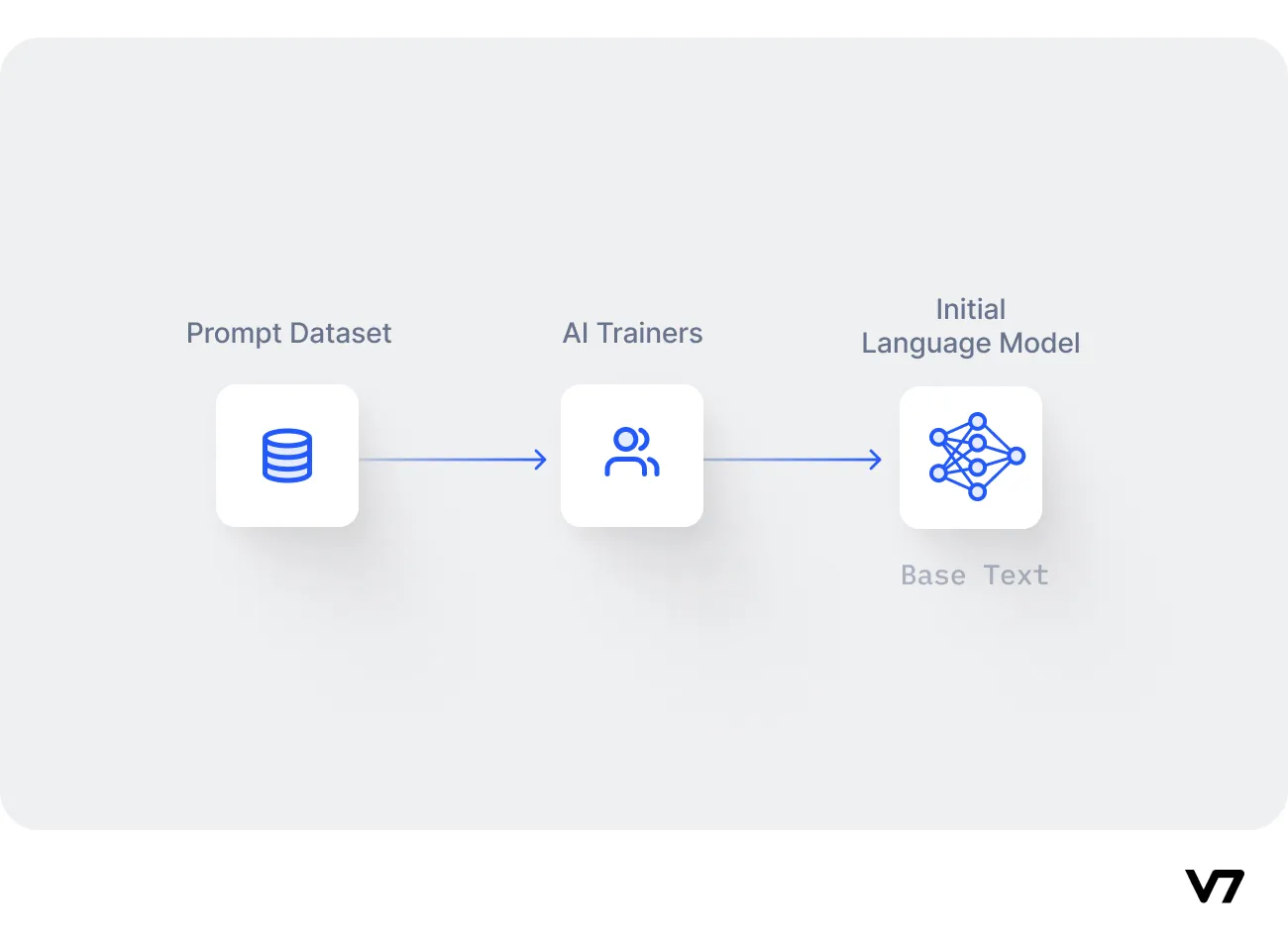
Step 1: Selecting a base language model
The initial selection of a base language model is crucial for the RLHF process. There isn't a universally best model to start with—the choice largely depends on the specific task at hand, available resources, and the unique challenges of the problem space. Industry practices vary greatly, with organizations like OpenAI using a smaller version of GPT-3 for their RLHF model, InstructGPT, and Anthropic and DeepMind opting for models ranging from 10 million to 280 billion parameters.
Step 2: Gathering and preprocessing data
For RLHF, the selected LM is pretrained on an extensive dataset, which typically consists of large quantities of text from the internet. This raw data must be cleaned and preprocessed to be suitable for training, a process that often involves removing unwanted characters, correcting errors, and normalizing textural irregularities.
Read more: A Simple Guide to Data Preprocessing in Machine Learning
Step 3: Training the language model
The LM is then trained on this dataset, learning to predict the next word in a sentence given the preceding words. This stage involves the optimization of model parameters using methods such as stochastic gradient descent. The ultimate goal is to minimize the difference between the model's predictions and the actual data, a measure often calculated using a loss function, such as cross-entropy.
Step 4: Evaluating the model
Post-training, the model is evaluated on a held-out dataset, separate from the one used for training. This step is necessary to ensure that the model can generalize well and hasn't merely memorized the training data. If the evaluation metrics are satisfactory, the model is deemed ready for the next phase of RLHF.
Read more: Top Performance Metrics in Machine Learning: A Comprehensive Guide
Step 5: Preparing for RLHF
While the LM has learned a lot about human language at this point, it still lacks knowledge of human preferences. To incorporate this, additional data is needed. Often, companies pay humans to generate responses to prompts, which are then used to train a reward model. This step can be expensive and time-consuming, but it's vital for steering the model in the direction of human-like preferences.
Note that the pretraining phase doesn't result in a perfect model; the model is expected to make mistakes and generate incorrect outputs. However, it provides a substantial starting point upon which RLHF can build, making the model more accurate, safe, and useful.
Training a reward model
The cornerstone of the RLHF process is the creation and training of a reward model (RM). This model essentially acts as an alignment tool, offering a way to integrate human preferences into the AI's learning process.
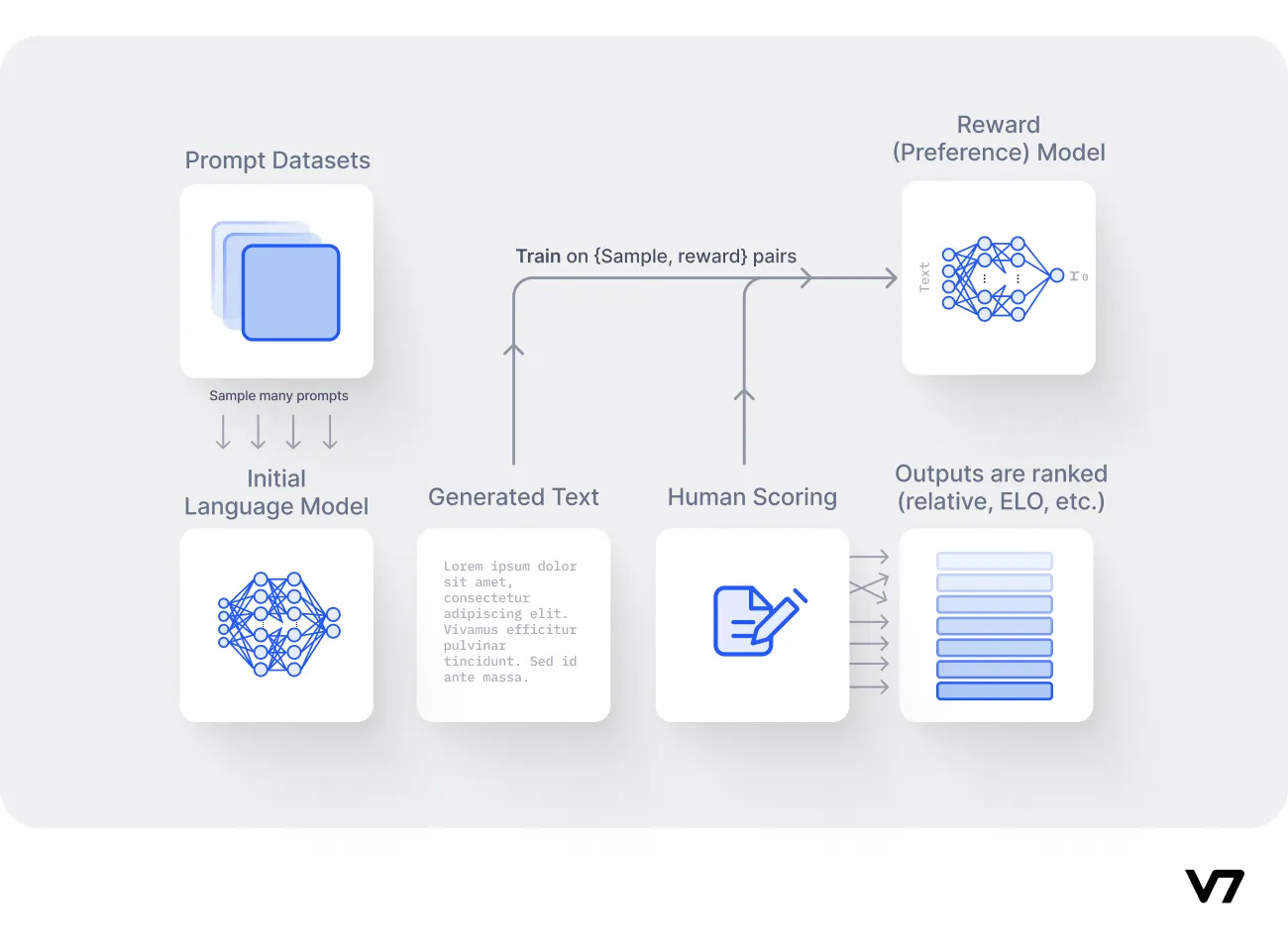
Step 1: Establishing the reward model
The reward model can either be an end-to-end language model or a modular system. Its primary function is to map input text sequences to a scalar reward value, a system that enables reinforcement learning algorithms to optimize over time within their environment.
For instance, if an AI generates two different text responses, the reward model will determine which one aligns more closely with human preferences, essentially 'rewarding' the more appropriate output.
Step 2: Data collection
Training the reward model begins with a specific dataset, distinct from the one used in language model pretraining. This dataset is composed of prompt and reward pairs and is narrower in scope, focusing on the specific use cases.
Each prompt corresponds to an expected output, with associated rewards to indicate the desirability of the output. While this dataset is typically much smaller than the initial pretraining dataset, it is critical in guiding the model to produce user-aligned content.
Step 3: Model training
Using the prompt and reward pairs, the model is trained to associate specific outputs with their respective reward values. This process often leverages large 'teacher' models or ensembles thereof to enhance diversity and mitigate bias. The aim here is to develop a reward model capable of accurately determining the desirability of potential output.
Step 4: Human feedback integration
A key element of training the reward model is the inclusion of human feedback. A perfect example of this is ChatGPT, where users can rank the AI's output using a thumbs-up or thumbs-down system.
This crowdsourced feedback is invaluable in refining the reward model, as it gives direct insight into human preferences. It is through this iterative cycle of model training and human feedback that AI continues to evolve, enhancing its alignment with human preferences.
Fine-tuning the language model with reinforcement learning
Fine-tuning is an essential part of the Reinforcement Learning with Human Feedback process. It facilitates the training of a language model so that it can generate more appropriate responses based on user prompts. This process is accomplished through the use of reinforcement learning techniques, including the utilization of Kullback-Leibler (KL) divergence and Proximal Policy Optimization (PPO).
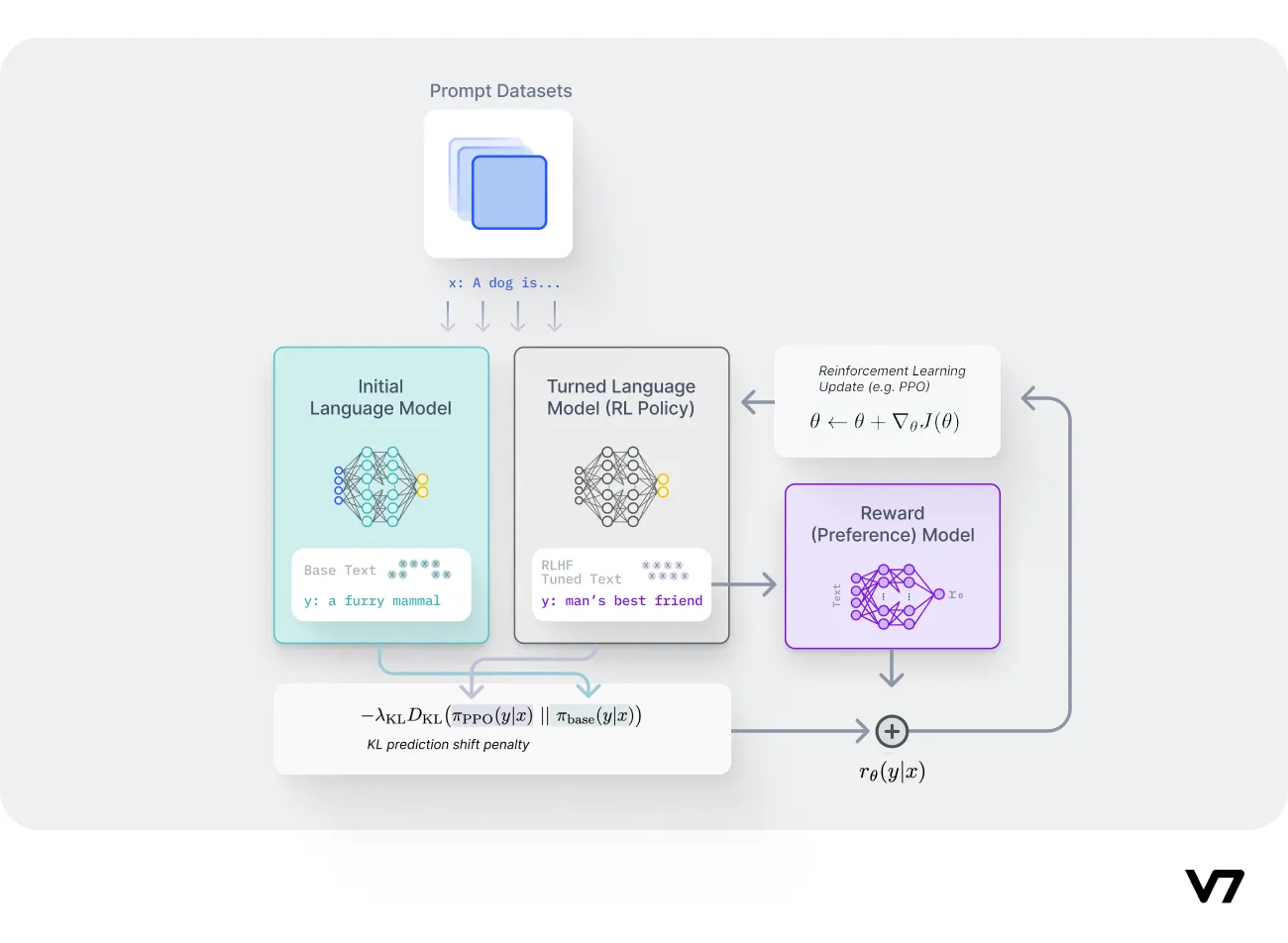
Step 1: Utilizing the reward model
Initially, a user input, or prompt, is sent to the RL policy, essentially a tuned version of the LM. The RL policy generates a response, which, along with the initial LM's output, is assessed by the reward model. This model then generates a scalar reward value corresponding to the quality of the responses.
Step 2: Introducing the feedback loop
This process is iterated in a feedback loop where the reward model assigns rewards to as many samples as resources permit. Over time, the responses that receive higher rewards will guide the RL policy, helping it to generate more human-aligned responses.
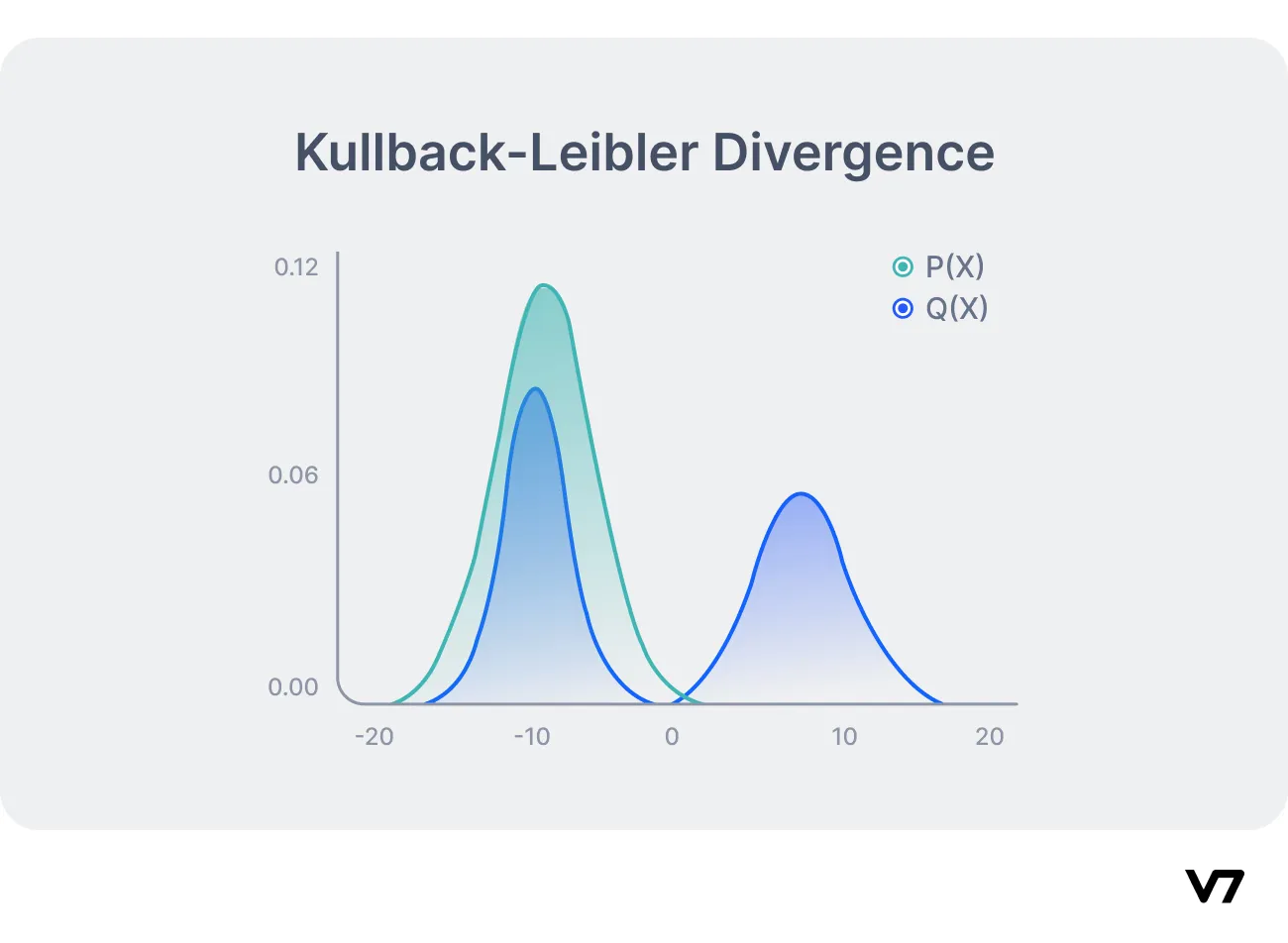
Step 3: Measuring differences with KL Divergence
Kullback-Leibler (KL) Divergence, a statistical method used to measure the difference between two probability distributions, plays a vital role here. In RLHF, KL Divergence is utilized to compare the probability distribution of the RL policy's current responses with a reference distribution that represents the ideal, or most human-aligned, responses.
Step 4: Fine-tuning with Proximal Policy Optimization
A significant part of the fine-tuning process involves Proximal Policy Optimization (PPO). PPO is a renowned reinforcement learning algorithm known for its effectiveness in optimizing policies in complex environments with high-dimensional state and action spaces. PPO is particularly useful in the RLHF fine-tuning process as it effectively balances exploration and exploitation during training. This balance is essential for RLHF agents, as they need to learn from both human feedback and trial-and-error exploration. As a result, the integration of PPO can lead to faster and more robust learning.
Step 5: Discouraging inappropriate responses
The fine-tuning process helps deters the language model from producing inappropriate or nonsensical outputs. As responses with low rewards are less likely to be repeated, the language model is driven to produce outputs that align more closely with human expectations.











RLHF in practice: ChatGPT
OpenAI's ChatGPT provides a compelling example of RLHF in action. It employs the RLHF framework (with a few modifications) to train a language model how to generate more human-like and context-appropriate responses
The process includes supervised fine-tuning, creating a reward model using human annotators, and applying Proximal Policy Optimization (PPO) to train the main LLM.
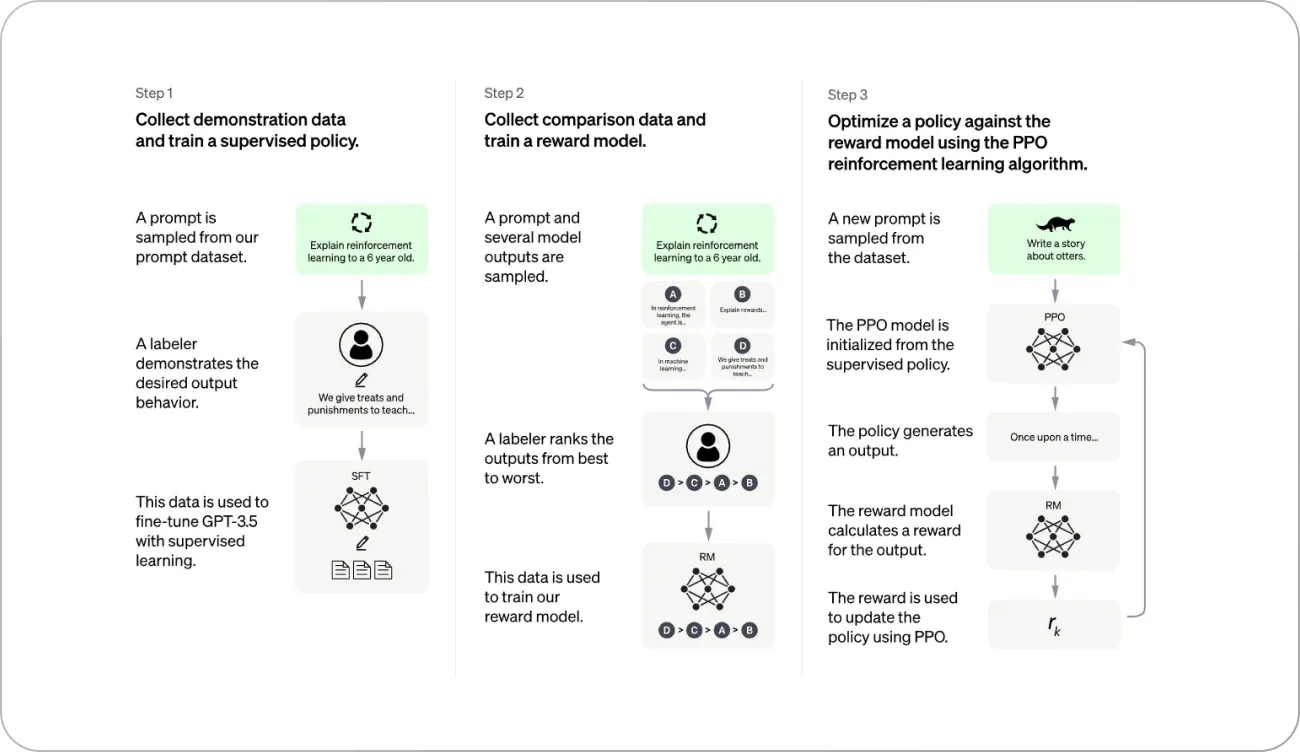
Let's delve deeper into how Reinforcement Learning from Human Feedback is implemented in practice using OpenAI's ChatGPT as an example.
Supervised fine-tuning
The first step in the process is to fine-tune the initial language model using supervised learning.
This involves creating a dataset of conversations where AI trainers play both sides—the user and the AI assistant. AI trainers can access model-written suggestions to help them compose their responses. By doing this, the dataset generated is a mix of human-generated text and model-written text, capturing a variety of diverse and relevant responses.
Creating a reward model
Once the supervised fine-tuning is complete, the next step is to create a reward model that reflects human preferences. To achieve this, human annotators are given the task of ranking multiple model-generated responses based on their quality and appropriateness. These rankings are used to train a second machine learning model, known as the reward model, which can predict how well a given response aligns with human preferences.
Proximal Policy Optimization (PPO)
With the reward model in place, it's time to improve the main language model using reinforcement learning. Proximal Policy Optimization helps the LLM learn to generate responses that score higher according to the reward model.
This entire process constitutes an RL loop, with the LLM acting as the agent and its responses as the actions. The state space consists of user prompts and LLM outputs, while the reward is determined based on the alignment of the LLM's response with the application's context and the user's intent.
Iterative process
The RLHF process in ChatGPT is iterative, involving multiple rounds of supervised fine-tuning, reward model creation, and reinforcement learning using PPO. Each iteration contributes to improving the model's alignment with human preferences, producing more accurate and context-aware responses.
Challenges and considerations
While employing RLHF in ChatGPT has shown promising results, there are still a few challenges it faces:
Human involvement: Human labor for data labeling can be slow, expensive, and a bottleneck in the process.
Varying human preferences: It's difficult to create a reward model that satisfies every user's preference, as human preferences can be diverse and complex.
Language consistency: Care must be taken to ensure that the LLM doesn't deviate too far from the original model while still improving its responses.
Despite these challenges, RLHF in ChatGPT has successfully demonstrated that this approach to training AI models maymore context-aware, user-aligned, and better at addressing specific applications.
Benefits and limitations of RLHF
Reinforcement Learning from Human Feedback (RLHF) offers a powerful methodology for refining AI systems. Yet, just like any other approach, it comes with both distinct advantages and potential challenges.
Let’s analyze the benefits and limitations of RLHF, factoring in the important consideration of bias and its potential mitigation strategies.
RLHF benefits
Adaptability. RLHF is a dynamic learning strategy that adapts to the feedback it receives. This adaptability makes it an excellent fit for a variety of tasks and enables it to adjust its behavior based on real-time interactions and feedback.
Reduced biases. In theory, RLHF can contribute to reducing model biases. With carefully selected and diverse human feedback, these models can learn from a broader, more representative perspective, minimizing overgeneralization or biases inherent in the initial training data.
Continuous improvement. RLHF models have the capacity to improve continuously. As these models interact with users and receive further feedback, they can learn and adapt, leading to enhancements in performance and user experience over time.
Safety. RLHF can play a critical role in enhancing the safety of AI systems. Through human feedback, these systems can be guided away from potentially harmful or inappropriate behavior, making them safer for interaction and use.
RLHF challenges and limitations
Scalability. Scalability remains a significant challenge for RLHF. As these models depend on human feedback for learning, scaling them to cater to larger or more complex tasks can be both resource-intensive and time-consuming.
Reliance on the human factor. RLHF models are heavily dependent on the quality of human feedback. Ineffective or inadequate feedback can lead to less-than-optimal performance or even unintentionally foster harmful behavior in the models.
Human bias. The potential for bias introduction is a critical concern with RLHF. The feedback provided by human evaluators can carry inherent biases, leading to skewed learning. These biases can take various forms, including selection bias, confirmation bias, inter-rater variability, and limited feedback.
However, it's important to note that there are effective strategies for mitigating these biases. Diverse evaluator selection, consensus evaluation, calibration of evaluators, regular evaluation of both the feedback process and the agent's performance, and balancing the feedback with other sources can all contribute to reducing the impact of bias in RLHF.
These strategies emphasize the importance of a thoughtful and systematic approach to RLHF, highlighting the need for continuous evaluation and adjustment in the process.
What’s next for RLHF
Reinforcement Learning with Human Feedback (RLHF) has a promising future and the potential to have a big impact on a variety of fields, including healthcare, education, and more. It promises a more humanized AI, leading to tailored user experiences and reduced training costs. However, there are challenges to carefully manage biases and address ambiguous inputs to prevent undesirable consequences.
As we continue to advance in AI, RLHF provides a promising avenue to ingrain human preferences into AI models. The emphasis will be on striking a balance between ethical issues and AI capabilities, assuring the ethical development of AI that fully comprehends and is compatible with our complex human environment.

Deval is a senior software engineer at Eagle Eye Networks and a computer vision enthusiast. He writes about complex topics related to machine learning and deep learning.

