AI implementation
13 min read
—

The next generation of machines is here—and they can learn autonomously how to perform human tasks. Read this guide to understand the most important machine learning concepts.

The world is filled with data—
Images, videos, spreadsheets, audio, and text generated by people and computers are flooding the Internet and drowning us in the sea of information.
Traditionally, humans analyzed data to make more informed decisions and managed to adapt systems to control the changes in the data patterns. However—
As the volume of incoming information surpasses, our ability to make sense of it decreases, leaving us with the following challenge:
How can we use all this data to derive meaning in an automated rather than manual way?
Well, that’s precisely where machine learning enters the picture.
Machine learning offers us the tools and algorithms to analyze and process data to make accurate predictions.
These predictions are made by the machine that learns patterns from a set of data termed as “training data”, and they can propel further technological developments that improve the lives of millions of people across the globe.
Here’s what we’ll cover:
What is machine learning?
Key elements of machine learning algorithms
How does machine learning work?
4 types of machine learning methods
Real-world machine learning applications
Challenges and limitations of machine learning

Knowledge work automation
AI for knowledge work
Get started today
Ready to streamline AI product deployment right away? Check out:
What is machine learning?
Machine learning is a concept that allows computers to learn from examples and experiences automatically and imitate humans in decision-making without being explicitly programmed.
It is a branch of Artificial Intelligence that uses algorithms and statistical techniques to learn from data and draw patterns and hidden insights from them.
Now, let's dive deeper and explore the ins and outs of machine learning.
Key elements of machine learning algorithms
There are tens of thousands of algorithms in machine learning that can be grouped based on the style of learning or by the nature of the problem it solves. But—
Every machine learning algorithm consists of the following key components:
Training data - Refers to the text, images, video, or time series information that the machine-learning system must learn from. Training data is often labeled to show the ML system what the “correct answer” is, such as a bounding box around a face in a face detector, or future stock performance in a stock predictor.
Representation—It refers to the encoded representations of objects in the training data, such as a face being represented by features such as “eyes”. Encoding some models is easier than others, and that’s what drives the selection of the model. For example, neural networks form one type of representation while support vector machines form another. Most modern approaches use neural networks.
Evaluation—It’s about how we judge or prefer one model over another. We often call it a utility function, loss function, or scoring function. Mean squared error (model’s output vs. the data output) or likelihood (the estimated probability of a model given the observed data) are examples of different evaluation functions.s
Optimization—This refers to how we search the space of represented models or improve the labels in the training data to obtain better evaluations. Optimization means updating the model parameters to minimize the value of loss function. It helps the model to improve its accuracy at a faster pace.
Here’s a great breakdown of the four components of machine learning algorithms.
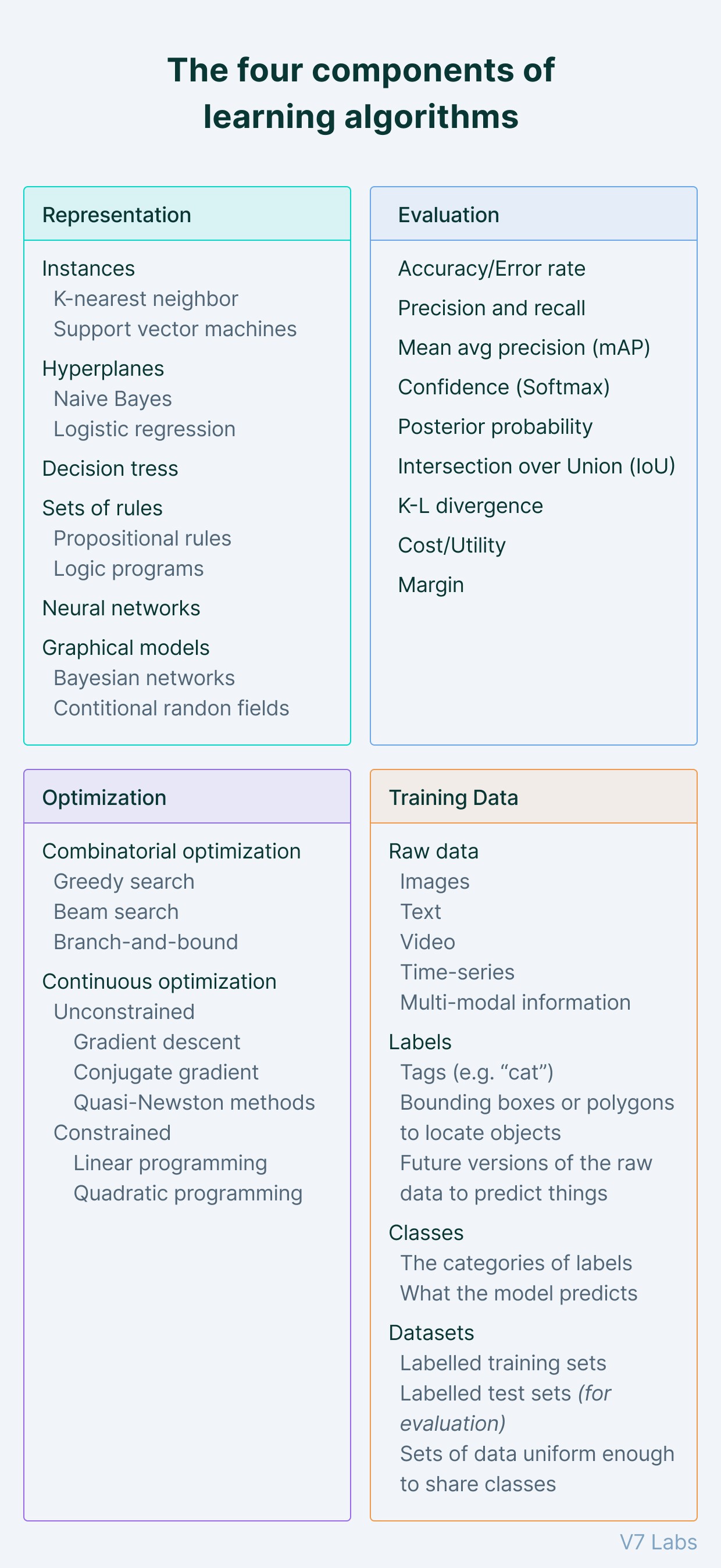
Functions of machine learning systems
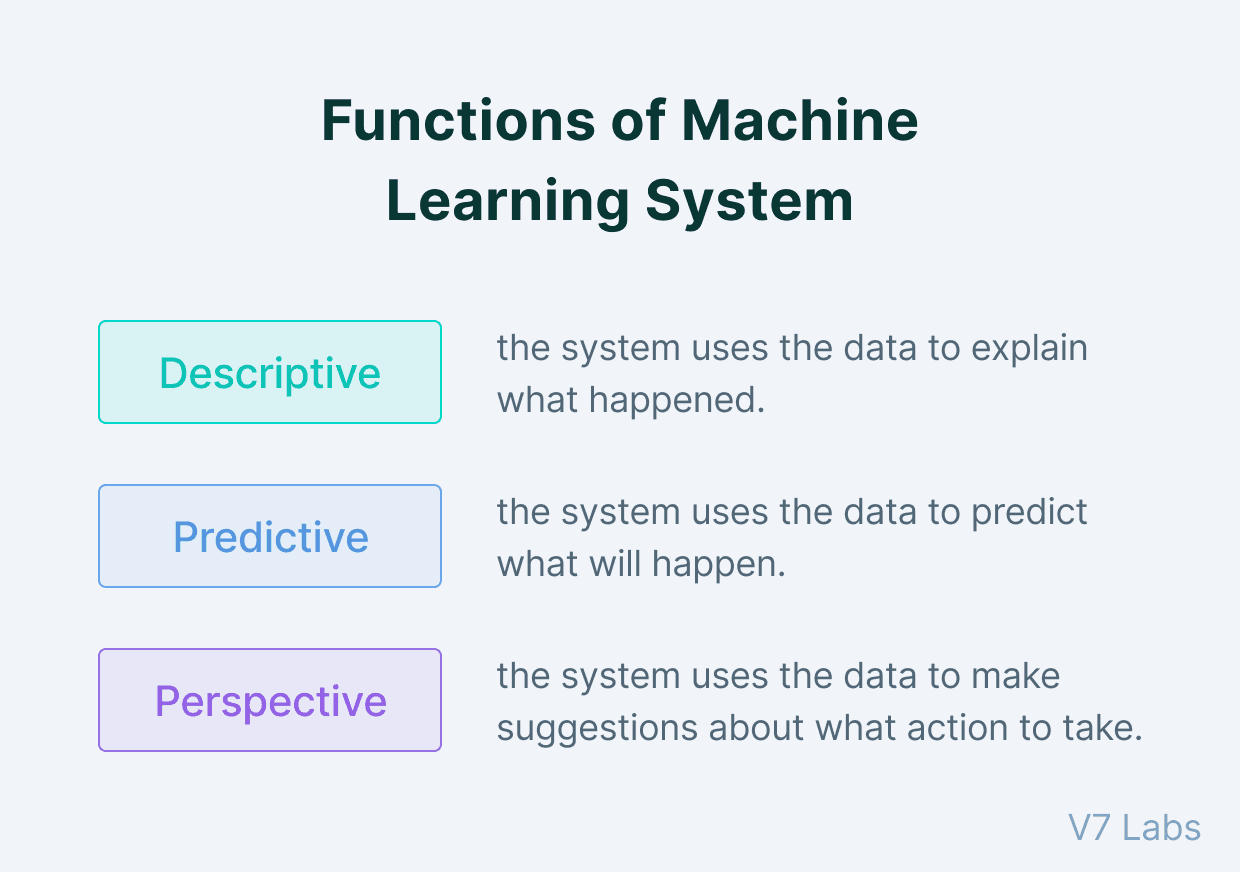
Descriptive: The system collects historical data, organizes it, and later presents it in an understandable way.
The main focus is to grasp what already happened in a business and not draw inferences or predictions from its findings. Descriptive analytics uses simple maths and statistical tools, such as arithmetic, averages, and percentages, rather than the complex calculations necessary for predictive and prescriptive analytics.
Predictive: While descriptive analytics focuses on analyzing historical data and deriving inferences from them, predictive analytics focuses on predicting and understanding what could happen in the future.
Analyzing past data patterns and trends by looking at historical data can predict what might happen going forward.
Prescriptive: Descriptive analytics tells us what has happened in the past, and predictive analytics tells us what could happen in the future by learning from the past. But what should be done once we have insights into what can happen?
There is what prescriptive analysis comes into the picture. It helps the system to use past knowledge to make multiple suggestions on the actions one can take. Prescriptive analytics can model a scenario and present a route to achieving the desired outcome.
Have a look at how different functions compare to one another here:
Now, let’s break down the processes behind machine learning itself.
How does machine learning work
The learning of ML algorithm can be divided into three main parts.
A Decision Process
Machine learning models aim to learn patterns from data and apply this knowledge to make predictions. The question is: How does the model make predictions?
The good news is that this process is quite basic—Finding the pattern from input data (labeled or unlabelled) and applying it to derive results.
An Error Function
The machine learning model aims to compare the predictions made by itself to the ground truth. The goal is to know whether it is learning in the right direction or not. This determines how accurate the model is and implies how we can improve the training of the model.
A Model Optimization Process
The ultimate objective of the model is to improve the predictions, which implies reducing the discrepancy between the known result and the corresponding model estimate.
The model needs to fit better to the training data samples by constantly updating the weights. The algorithm works in a loop, evaluating and optimizing the results, updating the weights until a maximum is obtained regarding the model’s accuracy.
Types of machine learning methods
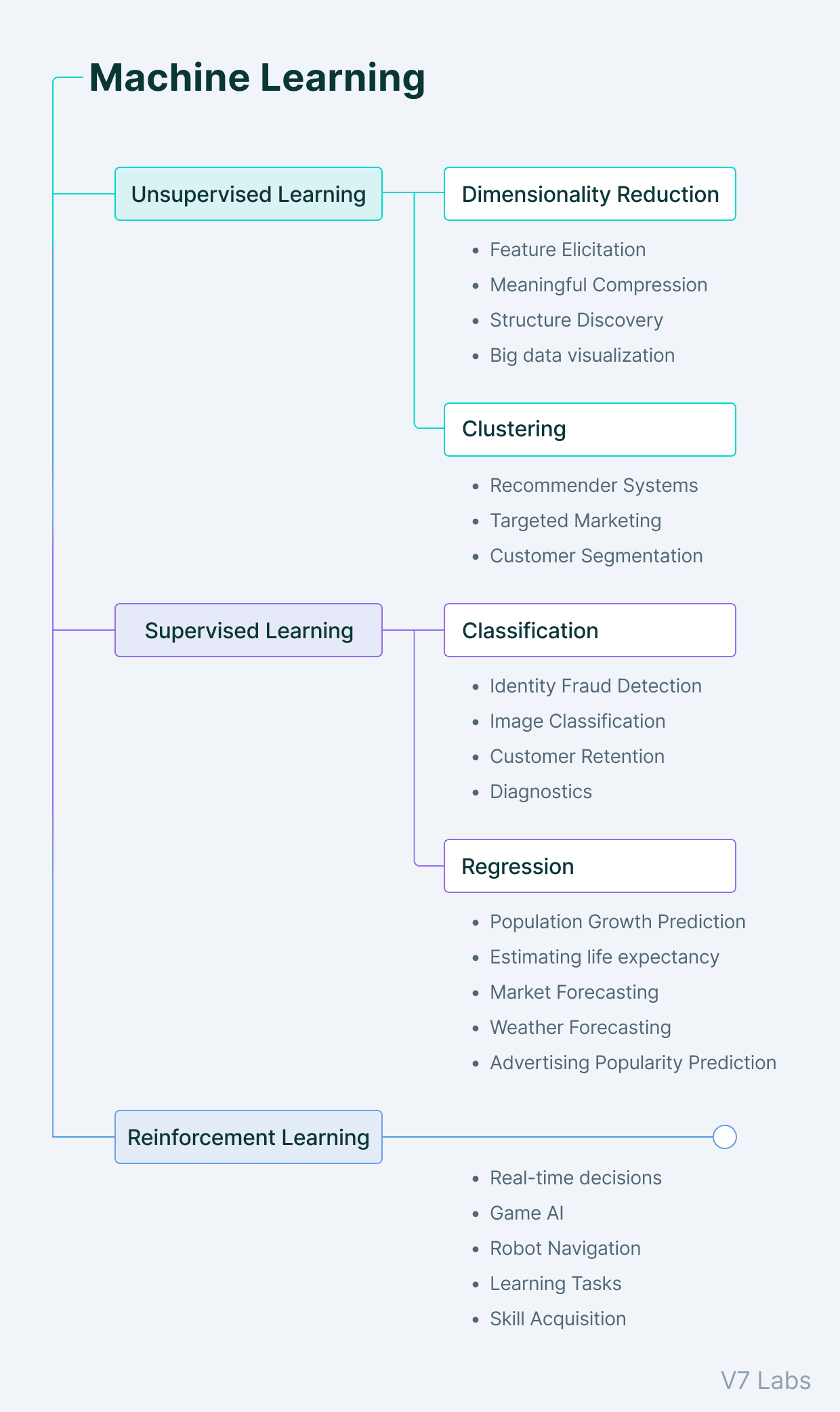
Machine learning consists primarily of four types.
1. Supervised machine learning
In supervised learning, as the name suggests, the machine learns under guidance.
This is done by feeding the computer a set of labeled data to make the machine understand what the input looks like and what the output should be. Here, the human acts as the guide that provides the model with labeled training data (input-output pair) from which the machine learns patterns.
Once relationships between the input and output have been learned from the previous data sets, the machine can easily predict the output values for new data.
Pro tip: You can auto-annotate your images or videos with V7 and then train your model using your labeled dataset.

Where can we use supervised learning?
The short answer is: In situations where we know what to look at in the input data and what we want as output.
The main types of supervised learning problems include regression and classification problems.
2. Unsupervised machine learning
Unsupervised learning works quite the opposite of how supervised learning does.
It uses unlabeled data—machines have to understand the data, find hidden patterns and make predictions accordingly.
Here, the machine gives us new findings after deriving hidden patterns from the data independently, without a human specifying what to look for.
The main types of unsupervised learning problems include clustering and association rules analysis.
3. Reinforcement learning
Reinforcement Learning involves an agent that learns to behave in an environment by performing the actions.
Based on the results of those actions, it provides feedback and adjusts its future course—
For each good action, the agent gets positive feedback, and for each bad action, the agent gets negative feedback or a penalty.
Reinforcement learning involves learning without any labeled data. Since there is no labeled data, the agent is bound to learn by its own experience only.
4. Semi-supervised Learning
Semi-supervised is a medium between supervised and unsupervised learning.
It takes the positive aspect from each of the learnings i.e. it uses a smaller labeled data set to guide classification and performs unsupervised feature extraction from a larger, unlabeled data set.
The main advantage of using semi-supervised learning is its ability to solve problems when there is not enough labeled data present to train a model, or when data simply cannot be labeled because humans don’t know exactly what to look for in it.
Pro tip: Check out Supervised vs. Unsupervised Learning: What’s the Difference?











6 real-world machine learning applications
Nowadays, machine learning is the core of almost all tech companies, including giants like Google or Youtube search engines.
Below, we’ve put together a few examples of real-life applications of machine learning you might be familiar with:
Self-driving cars
Vehicles can come across a varied number of situations on the road.
For self-driving cars to perform better than humans, they need to learn and adapt to the ever-changing road conditions and other vehicles’ behavior.
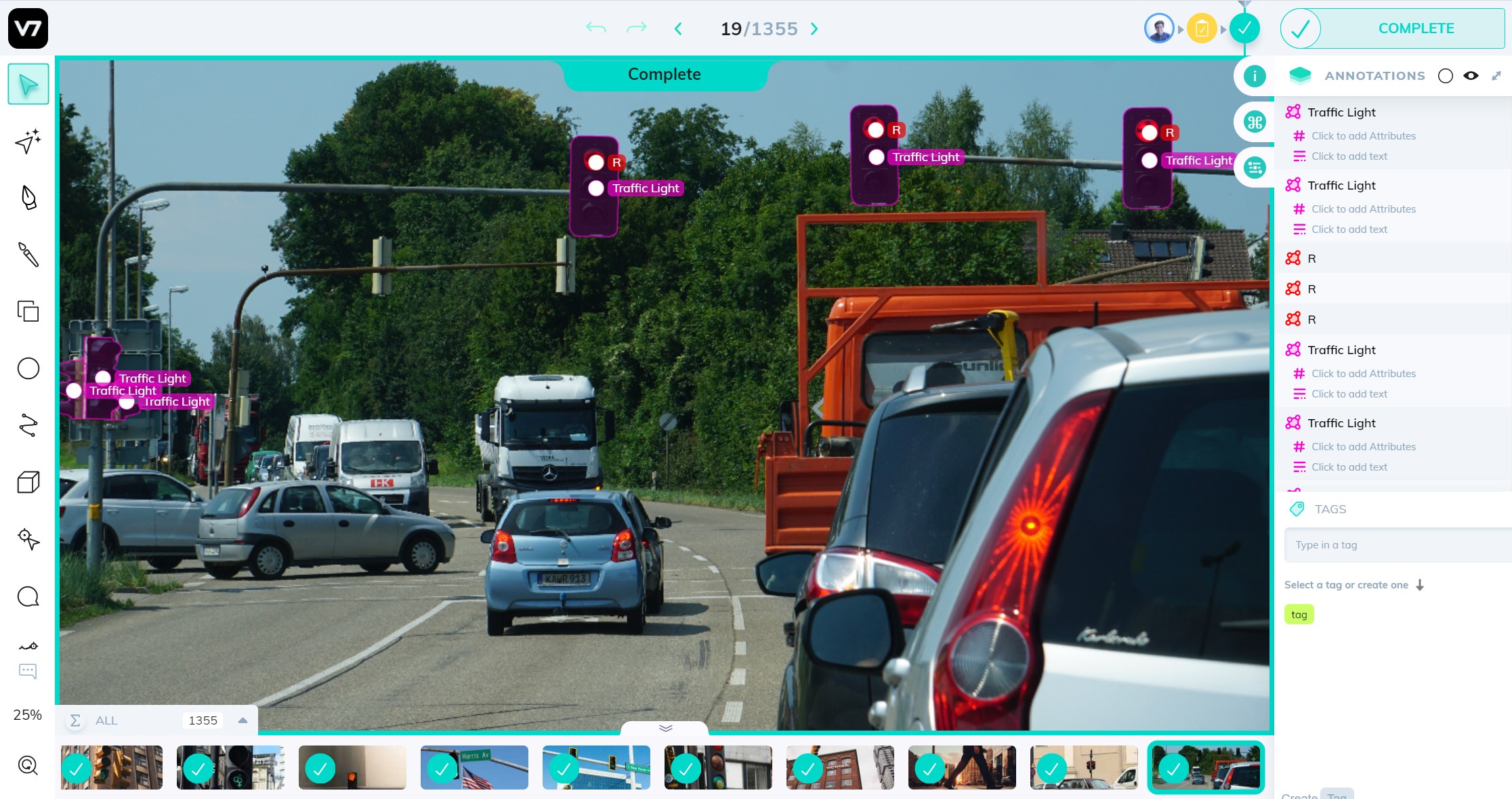
An autonomous car collects data on its surroundings from sensors and cameras to later interpret it and respond accordingly. It identifies surrounding objects using supervised learning, recognizes patterns of other vehicles using unsupervised learning, and eventually takes a corresponding action with the help of reinforcement algorithms.
Image analysis and object detection
Image analysis is used to extract different information from images.
It finds application in fields like inspecting defects in manufacturing, analyzing car traffic in smart cities, or visual search engines like Google lens.
The main idea is to perform feature extraction from images using deep learning techniques and then apply those features for object detection.
Customer service chatbots
Nowadays, it’s very common to see companies implementing AI chatbots for customer support and sales. And for a good reason—
AI chatbots help businesses deal with a large volume of customer queries by providing 24/7 support, thus cutting down support costs and bringing in additional revenue and happy customers.
AI bots technology uses natural language processing (NLP) to process the text, extract query keywords, and respond accordingly.
Medical imaging and diagnostics
Here’s the fact: Medical imaging data is both the richest source of information and one of the most complex ones out there.
Manually analyzing thousands of medical images is a tedious task and a waste of precious time that pathologists could use more efficiently.
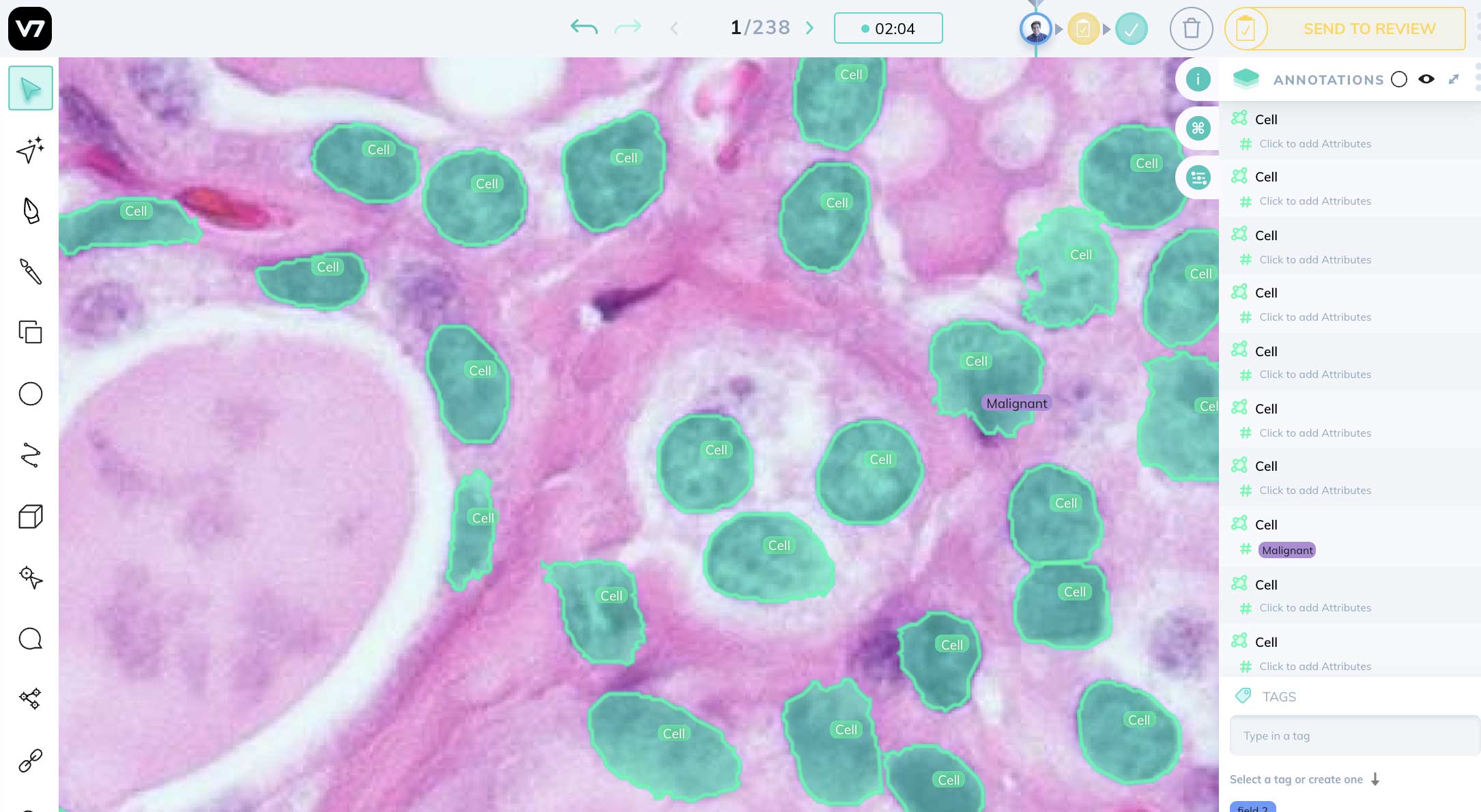
But it’s not only about saved time—
Small features like artifacts or nodules may not be visible by the naked eye, resulting in delayed disease diagnosis and false predictions. That’s why using deep learning techniques involving neural networks, which can be used for feature extraction from images, has so much potential.
Pro tip: Check out Medical Image Annotation with V7.
Fraud detection
With the expansion of the e-commerce sector, we can observe the growing number of online transactions and a wider variety of available payment methods.
Unfortunately, some people take advantage of this situation.
Fraudsters in today's world are very skilled and can adopt new techniques quite rapidly.
That’s why we need a system that can analyze patterns in data, make accurate predictions, and respond to online cybersecurity threats like fake login attempts or phishing attacks.
For example, based on where you made your past purchases, or at what time you are active online, fraud-prevention systems can discover whether a purchase is legitimate. Similarly, they can detect whether someone is trying to impersonate you online or on the phone.
Recommendation algorithms
This relevancy of recommendation algorithms is based on the study of historical data and depends on several factors, including user preference and interest.
Companies like Netflix or Amazon use recommender systems to curate and showcase relevant content or products for the users/buyers.
Pro tip: Check out AI in Healthcare and AI in Insurance to learn more about the real-world applications of artificial intelligence.
Challenges and limitations of machine learning
Underfitting & Overfitting
In most scenarios, the cause of the poor performance of any machine learning algorithm is due to underfitting and overfitting.
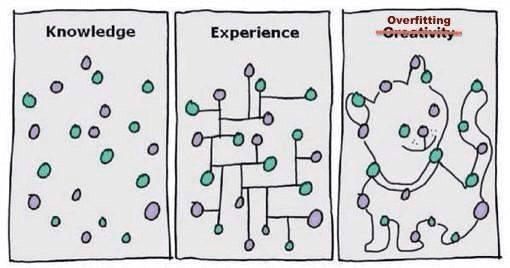
Let's break down these terms in the context of training machine learning models.
Underfitting is a scenario where the machine learning model can neither learn the relationship between variables in the data nor predict a new data point correctly. In other words, the machine learning system hasn’t found a trend across the data points.
Overfitting occurs when the machine learning model learns from the training data a little too much, paying attention to points of data that are otherwise noise or irrelevant to the dataset’s scope. It is attempting to fit every point on the curve and, as a result, memorizes the data patterns.
As the model has very little flexibility, it fails to predict new data points. In other words, it narrowed its focus too much on the examples given, making it unable to see the bigger picture.
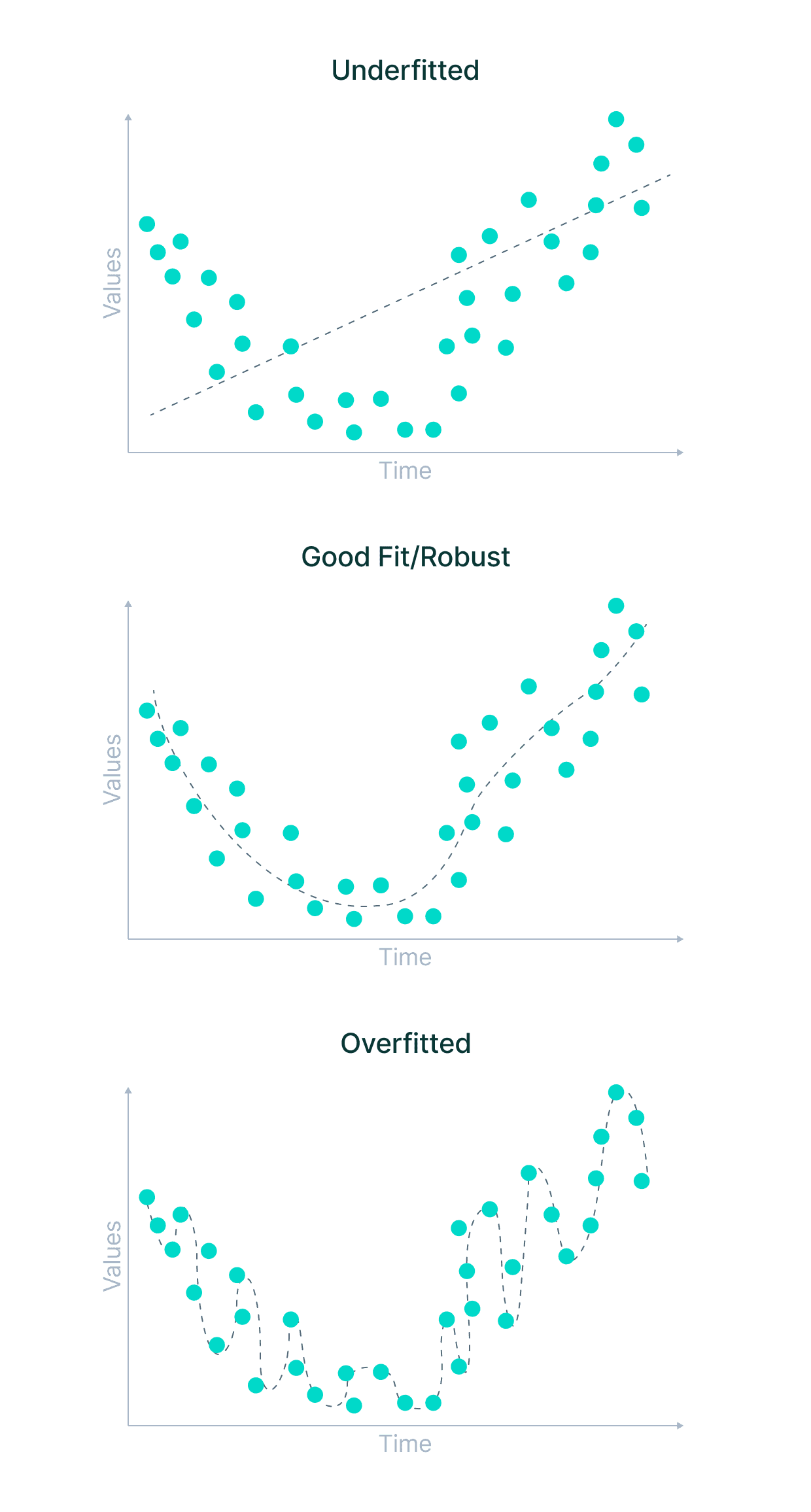
But—
What are the reasons for underfitting and overfitting?
The more generic ones include situations where data used for training is not clean and contains a lot of noise or garbage values, or the size of it is simply too small. However, there are a few more specific reasons, too.
Let's have a look at those.
Underfitting can occur because:
The model was trained using the wrong parameters and under-observed the training data
The model is too simple and can’t remember enough features
The training data is too varied or complex
Overfitting can occur when:
The model was trained using the wrong parameters and over-observed the training data
The model is too complex and was not pre-trained on more varied data.
The training data’s labels are too restrictive or the raw data is too uniform and doesn’t represent a realistic distribution.

Dimensionality
The accuracy of any machine learning model is directly proportional to the dimension of the dataset. But—
It holds true only up to a certain threshold.
The dimension of a dataset refers to the number of attributes/features that exist in the dataset. Increasing the dimensionality exponentially leads to the addition of non-required attributes that confuse the model and, therefore, reduce the machine learning model’s accuracy.
We refer to these difficulties related to training machine learning models due to high dimensional as the ‘Curse of Dimensionality.’
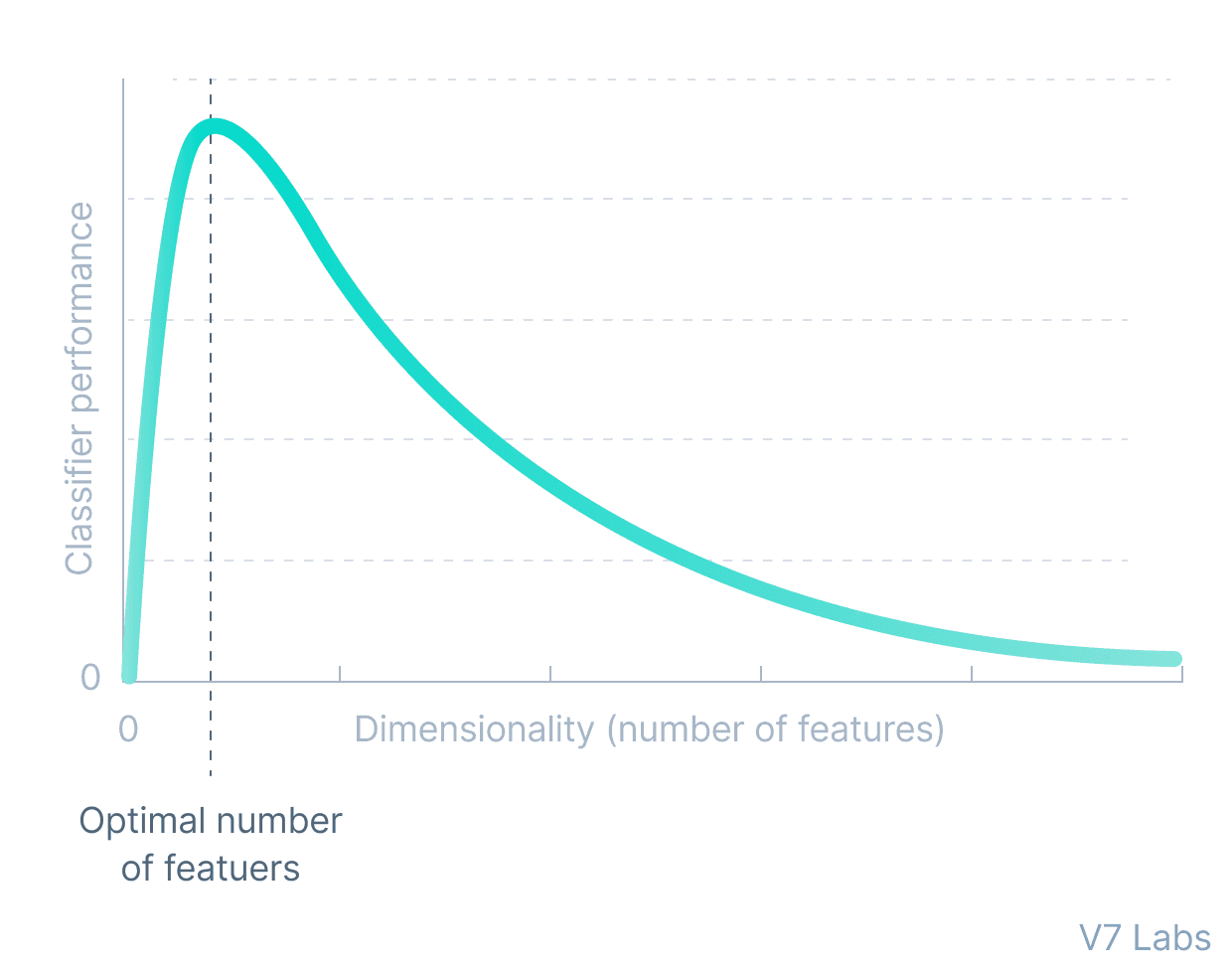
Access to quality data
Machine learning algorithms are sensitive to low-quality training data.
Data quality may get hampered either due to incorrect data or missing values leading to noise in the data. Even relatively small errors in the training data can lead to large-scale errors in the system’s output.
When algorithms don’t perform well, it is often due to data quality problems like insufficient amounts/skewed/noise data or insufficient features describing the data.
Therefore, one often needs to perform data cleaning to get high-quality data before training machine learning models.
Pro Tip: Looking for quality training data? Check out 65+ Free Machine Learning Datasets to find the right dataset for your data science projects.
Key takeaways: Machine Learning basics
Wrapping up things, let's take some time to look at the main highlights of this article:
Machine learning is a concept that allows computers to automatically learn and improve from their experience without being explicitly programmed.
Machine learning works by a simple approach of “find the pattern, apply the pattern”.
Machine Learning consists of Supervised, Unsupervised, Reinforcement, and Semi-Supervised Learning.
Supervised learning is useful if you have a purely labeled dataset and knows exactly what “output” should look like
Unsupervised Learning generally gives better performance for large data sets as finding the hidden pattern becomes easy.
A machine learning model is underfitted when it fails to capture the relationship between the input and output.
If a machine learning model shows better performance on the training set than on the test set, then it is likely overfitting. This is because the model is memorizing the data it has seen and is unable to generalize to unseen examples.
Large numbers of input features can cause poor performance for machine learning algorithms.
We are all already using machine learning in our daily life even without knowing it, for example while Google Maps, Google sAsistant, Alexa, YouTube, Netflix or Amazon.
Read next:
Computer Vision: Everything You Need to Know
An Introduction to Autoencoders
YOLO: Real-Time Object Detection Explained
Optical Character Recognition: What is It and How Does it Work [Guide]
The Beginner’s Guide to Contrastive Learning
9 Reinforcement Learning Real-Life Applications
Mean Average Precision (mAP) Explained: Everything You Need to Know
A Step-by-Step Guide to Text Annotation [+Free OCR Tool]
The Essential Guide to Data Augmentation in Deep Learning

Pragati is a software developer at Microsoft, and a deep learning enthusiast. She writes about the fundamental mathematics behind deep neural networks.

