Computer vision
Supervised and Unsupervised Learning [Differences & Examples]
9 min read
—

Have a look at this side-by-side comparison between supervised and unsupervised learning and find out which approach is better for your use case.

In 2023, Machine Learning and AI are on everyone's lips.
Just have a look around you—we are using face detection algorithms to unlock phones and Youtube or Netflix recommender systems to suggest us content that's most likely to engage us (and make us binge-watch it).
Pro tip: check out all the real world applications of our AI tool V7 Go
But how do these systems work?
Well, I'm glad you asked because this article will help you understand key differences between two primary Machine Learning approaches that are the backbone of those systems: Supervised and Unsupervised Learning.
On the most basic level, the answer is simple—one of them uses labeled data to predict outcomes, while the other does not.
However—
There's a bunch of nuances that you should know about because they determine which approach is more suitable for your use case.
Here’s what we’ll cover:
What is Supervised Learning?
What is Unsupervised Learning?
Supervised Learning vs. Unsupervised Learning
What is Semi-Supervised Learning?

AI for document processing
Label financial training data at scale with AI assistance
Get started today
Ready to streamline AI product deployment right away? Check out:
What is Supervised Learning?
Supervised Learning is the machine learning approach defined by its use of labeled datasets to train algorithms to classify data and predict outcomes.
The labeled dataset has output tagged corresponding to input data for the machine to understand what to search for in the unseen data.
Here's how it looks in practice.
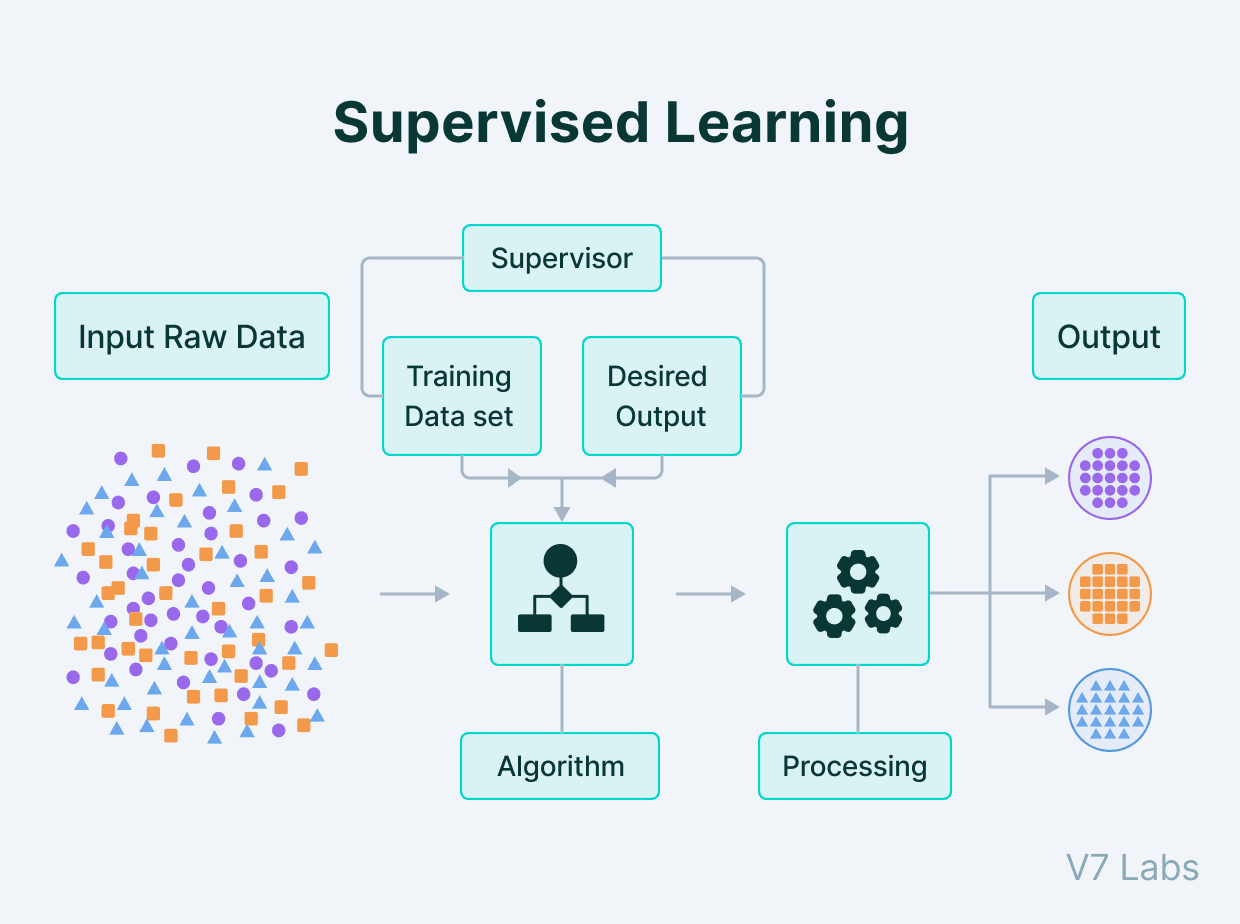
Supervised Learning process
Pro tip: Check out Data Annotation Guide to learn more about labeling data.
Supervised Machine Learning Methods
There are two main areas where supervised machine learning comes in handy: classification problems and regression problems.
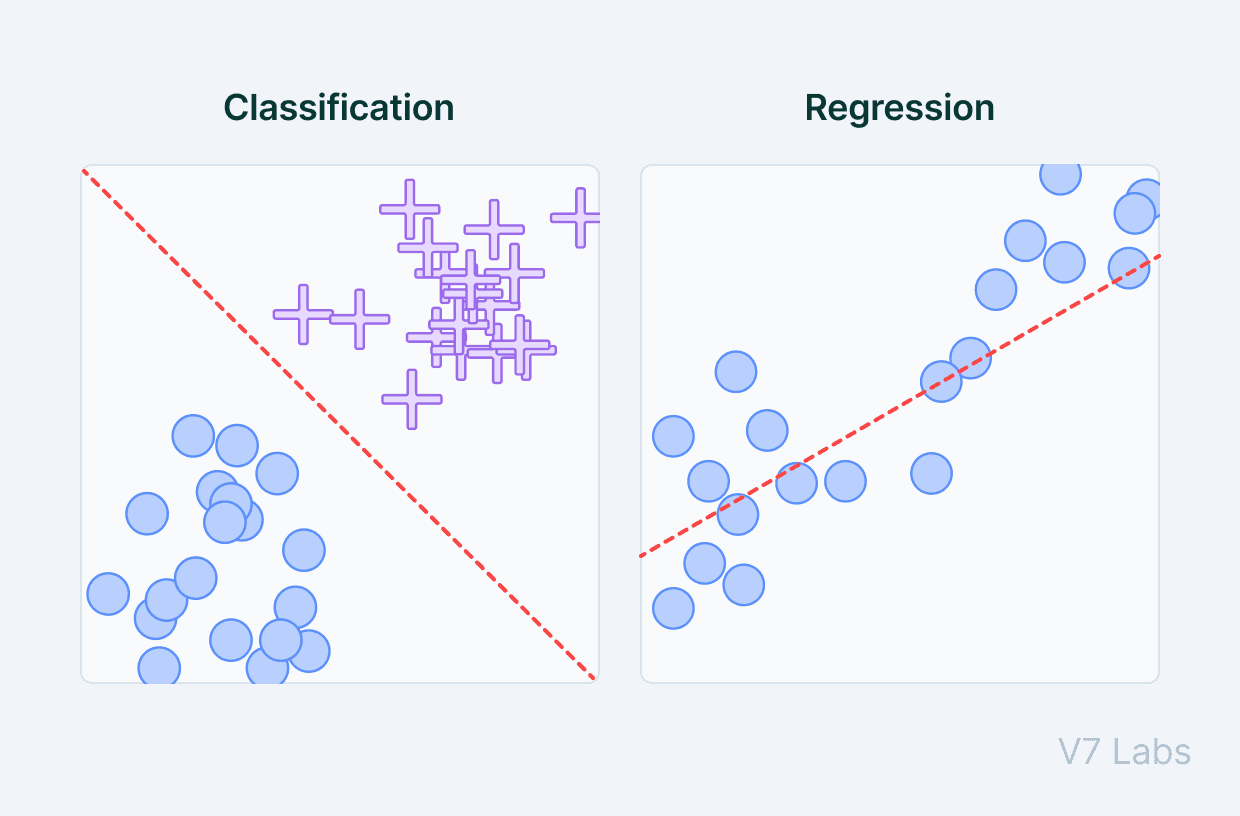
Classification
Classification refers to taking an input value and mapping it to a discrete value. In classification problems, our output typically consists of classes or categories. This could be things like trying to predict what objects are present in an image (a cat/ a dog) or whether it is going to rain today or not.
Pro Tip: Read this introductory Guide to Image Classification and start building your own classifiers with V7.
Regression
Regression is related to continuous data (value functions). In Regression, the predicted output values are real numbers. It deals with problems such as predicting the price of a house or the trend in the stock price at a given time, etc.
Some of the most common algorithms in Supervised Learning include Support Vector Machines (SVM), Logistic Regression, Naive Bayes, Neural Networks, K-nearest neighbor (KNN), and Random Forest.
Supervised Machine Learning Applications
Now, let's have a look at some of the popular applications of Supervised Learning:
Predictive analytics (house prices, stock exchange prices, etc.)
Spam detection
Customer sentiment analysis
Object detection (e.g. face detection)
Pro tip: Refresh your knowledge by revisiting The Ultimate Guide to Object Detection.
What is Unsupervised Learning?
Unsupervised Learning is a type of machine learning in which the algorithms are provided with data that does not contain any labels or explicit instructions on what to do with it. The goal is for the learning algorithm to find structure in the input data on its own.
To put it simply—Unsupervised Learning is a kind of self-learning where the algorithm can find previously hidden patterns in the unlabeled datasets and give the required output without any interference.
Identifying these hidden patterns helps in clustering, association, and detection of anomalies and errors in data.
Unsupervised Machine Learning Methods
Unsupervised Learning models can perform more complex tasks than Supervised Learning models, but they are also more unpredictable. Here are the main tasks that utilize this approach.
Clustering
Clustering is the type of Unsupervised Learning where we find hidden patterns in the data based on their similarities or differences. These patterns can relate to the shape, size, or color and are used to group data items or create clusters.
There are several types of clustering algorithms, such as exclusive, overlapping, hierarchical, and probabilistic.
Association
Association is the kind of Unsupervised Learning where we can find the relationship of one data item to another data item. We can then use those dependencies and map them in a way that benefits us—e.g., understanding consumers' habits regarding our products can help us develop better cross-selling strategies.
The association rule is used to find the probability of co-occurrence of items in a collection. These techniques are often utilized in customer behavior analysis in e-commerce websites and OTT platforms.
Dimensionality reduction
As the name suggests, the algorithm works to reduce the dimensions of the data. It is used for feature extraction.
Extracting the important features from the dataset is an essential aspect of machine learning algorithms. This helps reduce the number of random variables in the dataset by filtering irrelevant features.
Finally, here's a nice visual recap of everything we've covered so far (plus the Reinforcement Learning).
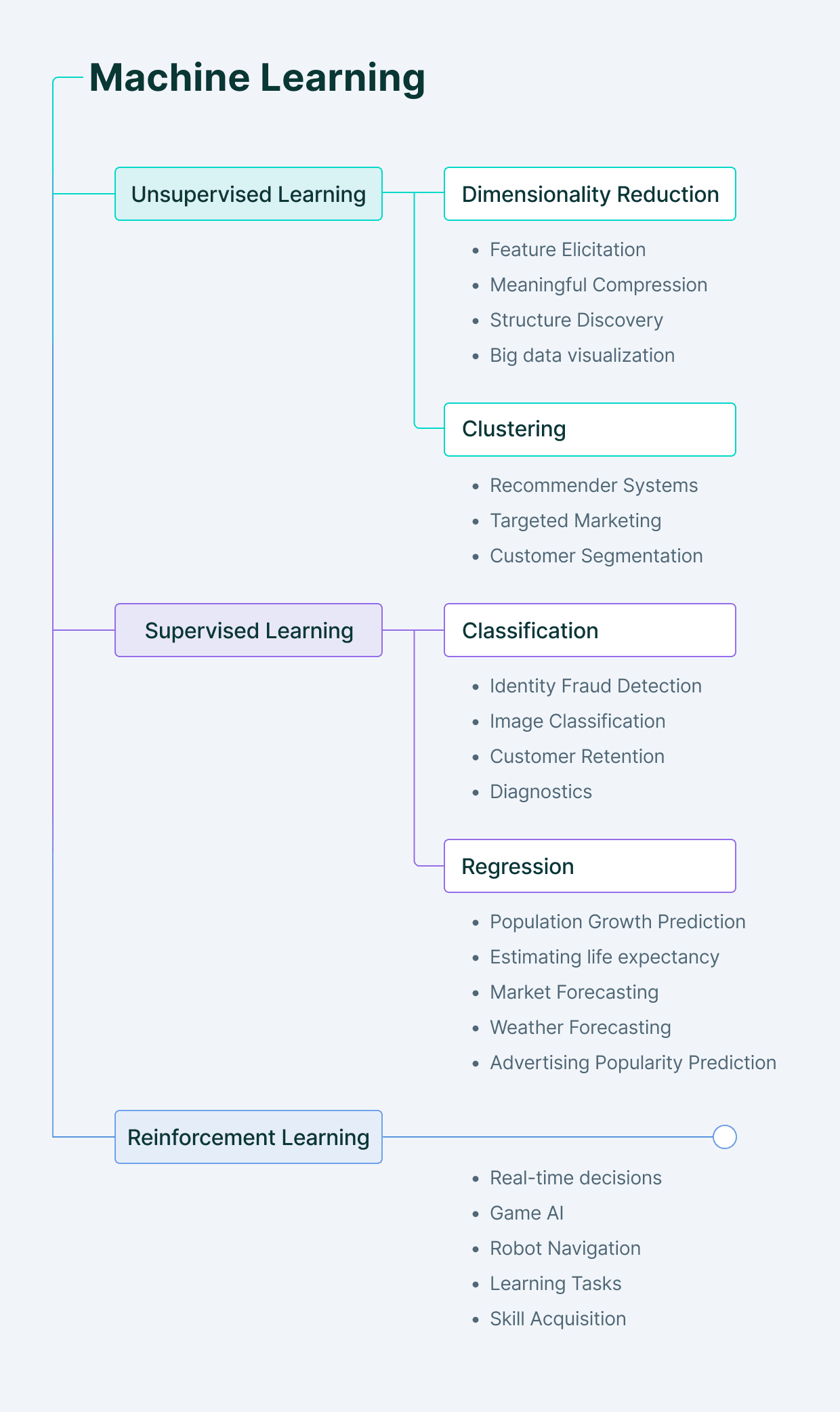
Types of learning in Machine Learning











Supervised Learning vs. Unsupervised Learning: Key differences
In essence, what differentiates supervised learning vs unsupervised learning is the type of required input data. Supervised machine learning calls for labelled training data while unsupervised learning relies on unlabelled, raw data.
But there are more differences, and we'll look at them in more detail.
Data
Supervised Learning learns from the training dataset by iteratively making predictions on the data and adjusting for the correct answer. Supervised techniques deal with labeled data where the output data patterns are known to the system.
This makes Supervised Learning models more accurate than unsupervised learning models, as the expected output is known beforehand.
Unsupervised Learning models work on their own to discover the inherent structure of unlabeled data. The unsupervised learning algorithm works with unlabeled data, in which the output is based solely on the collection of perceptions.
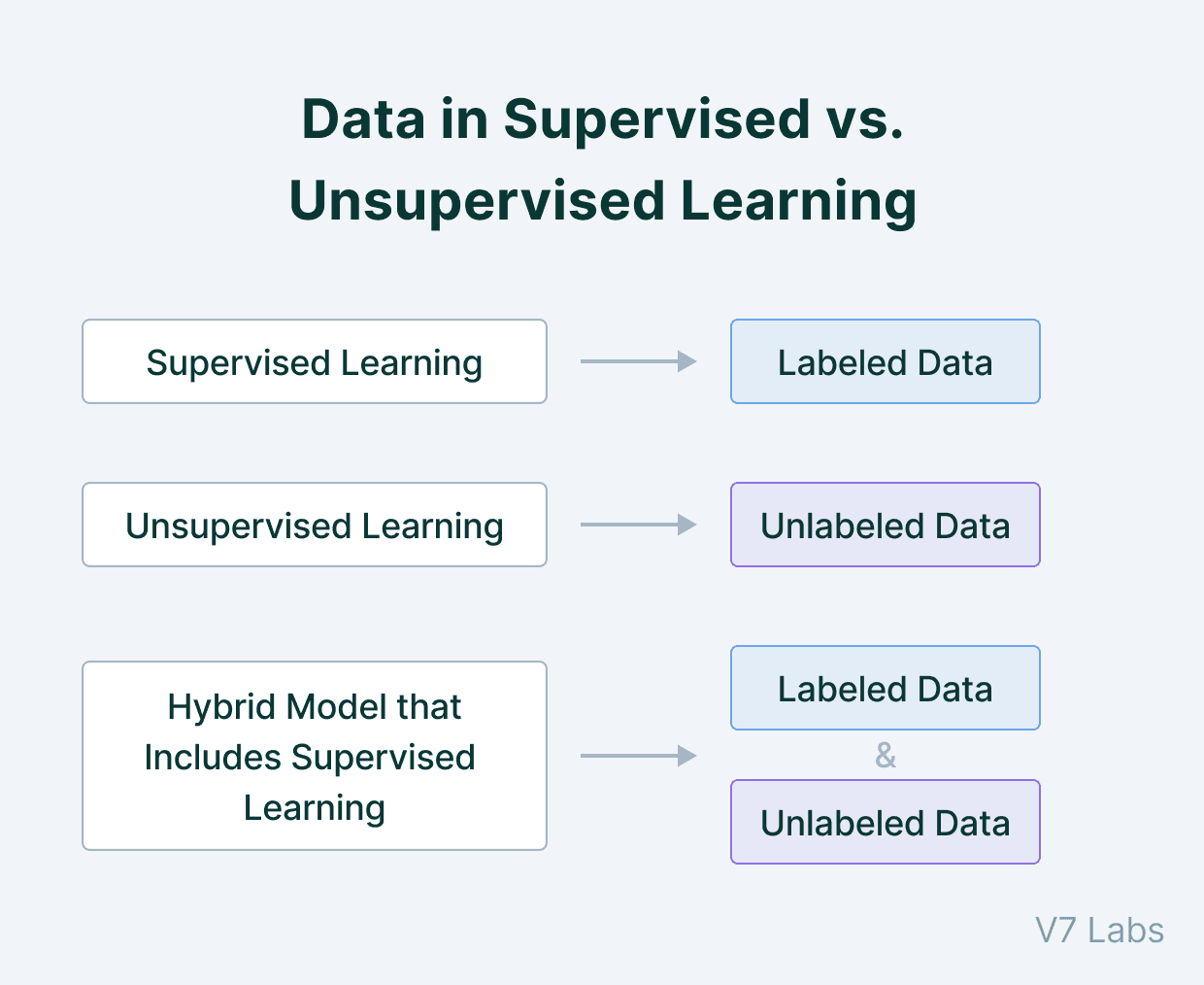
Data in Supervised and Unsupervised Learning
If you are searching for quality data for training your machine learning models, check out:
Goals
The goal of Supervised Learning is well known before the training starts.
The type of output the model is expecting is already known; we just need to predict it for unseen new data.
With an unsupervised learning algorithm, the goal is to get insights from large volumes of new data. There is no particular output value we are expecting to be predicted, which makes the whole training procedure more complex.
Applications
Supervised Learning models are ideal for classification and regression in labeled datasets. Spam detection, image classification, weather forecasting, price prediction are among their most common applications.
Unsupervised Learning fits perfectly for clustering and association of data points, used for anomaly detection, customer behavior prediction, recommendation engines, noise removal from the dataset, etc.
Pro tip: See our Data Cleaning Checklist to learn how to prepare your machine learning data for training.
Complexity
Supervised Learning is comparatively less complex than Unsupervised Learning because the output is already known, making the training procedure much more straightforward.
In Unsupervised Learning, on the other hand, we need to work with large unclassified datasets and identify the hidden patterns in the data. The output that we are looking for is not known, which makes the training harder.
Have a look at this comparison table.
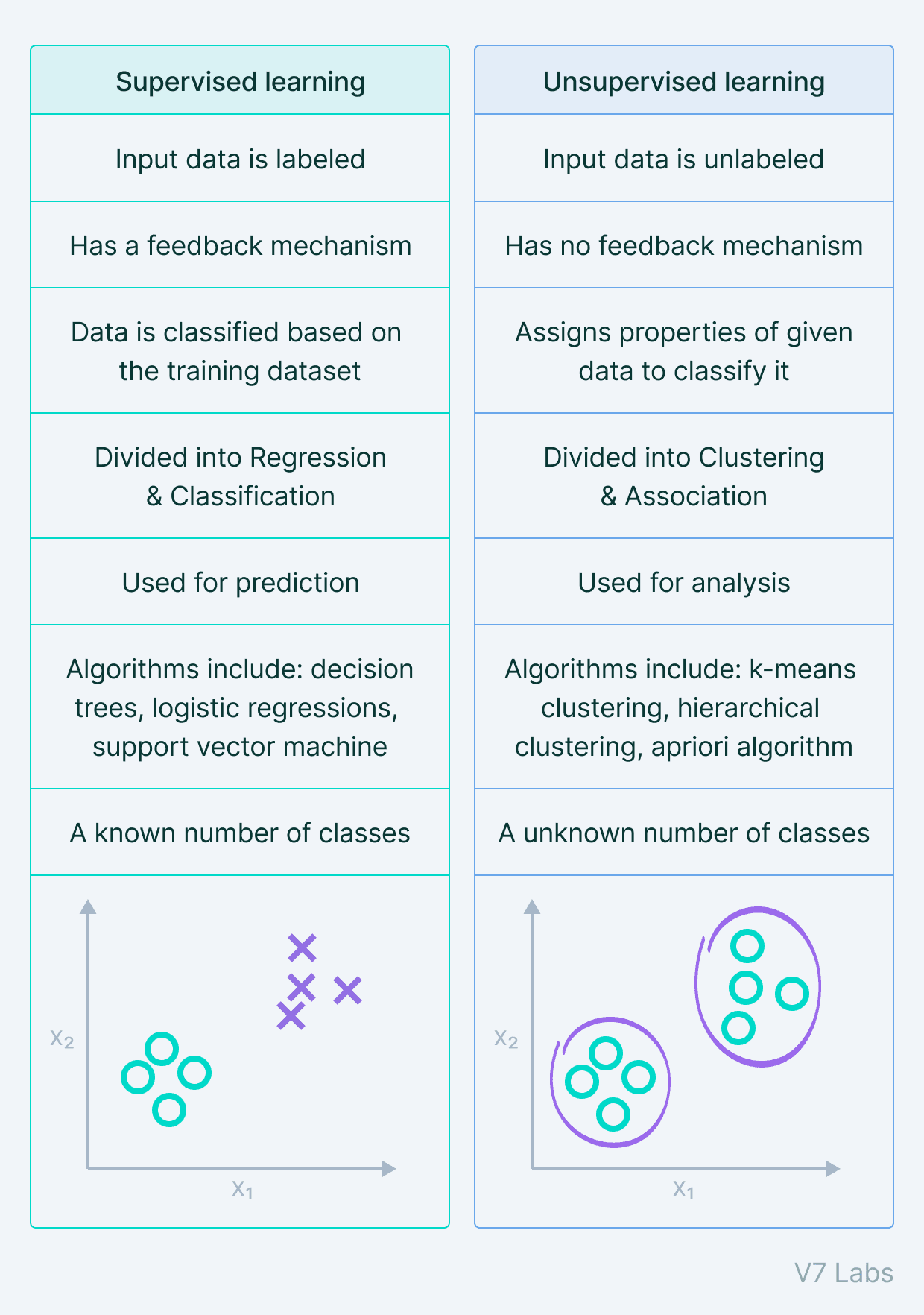
Supervised Learning vs. Unsupervised Learning
Pro Tip: Would you like to start building your models? Here are 3 Signs You Are Ready to Annotate Data for Machine Learning.
What is Semi-supervised Learning?
Lastly, let's quickly discuss the approach that combines both Supervised Learning and Unsupervised Learning.
It's called...
*drum rolls*
Semi-Supervised Learning.
It uses a combination of labeled and unlabeled datasets. Here's an example of how it works—
Let's say that we have access to a large unlabeled dataset that we want to train our model on. Doing it manually ourselves is just not practical.
So, what should we do?
One of our options is to have a manually labeled set of datasets that we can use for training. We don't need to label all of it.
And that's the whole idea of Semi-Supervised Learning—it is used in scenarios where we have access to large amounts of data, and only a small portion of that is labeled. The more (relevant) data we use for training, the more robust our model becomes.
Semi-Supervised Learning works by initially training the model using the labeled dataset, just like Supervised Learning. Once we get the model performing well, we use it to predict the remaining unlabeled data points and label them with the corresponding predictions.
This is followed by training the model on the full dataset, which comprises the truly labeled and "pseudo labeled" datasets.
Pro Tip: If you are looking for the perfect data labeling tool, check out the 13 Best Image Annotation Tools.
Supervised vs. Unsupervised Learning: Key takeaways
Finally, here's a short recap of everything we've covered in this piece:
Supervised Learning works with the help of a well-labeled dataset, in which the target output is well known.
Supervised Learning has a feedback mechanism.
Supervised Learning can be further divided into Classification problems and Regression problems. In Classification, the output variable is categorical, whereas, for Regression, the output variable is a real or continuous value.
For example, if a machine predicts whether an employee will get a salary raise or not, we deal with Classification, but if it answers how much is the salary raise, that is Regression.
Supervised Learning is used in areas of risk assessment, image classification, fraud detection, visual recognition, etc.
In Unsupervised Learning, the algorithm is trained using data that is unlabeled. The machine tries to identify the hidden patterns and give the response.
Unsupervised Learning can be further grouped into Clustering and Association.
Unsupervised Learning areas of application include market basket analysis, semantic clustering, recommender systems, etc.
The most commonly used Supervised Learning algorithms are decision tree, logistic regression, linear regression, support vector machine.
The most commonly used Unsupervised Learning algorithms are k-means clustering, hierarchical clustering, and apriori algorithm.
Read more:
Computer Vision: Everything You Need to Know
A Simple Guide to Autoencoders—the ELI5 Way
YOLO: Real-Time Object Detection Explained
The Ultimate Guide to Semi-Supervised Learning
The Beginner’s Guide to Contrastive Learning
9 Reinforcement Learning Real-Life Applications
Mean Average Precision (mAP) Explained: Everything You Need to Know
A Step-by-Step Guide to Text Annotation [+Free OCR Tool]
The Essential Guide to Data Augmentation in Deep Learning
Domain Adaptation in Computer Vision: Everything You Need to Know

Pragati is a software developer at Microsoft, and a deep learning enthusiast. She writes about the fundamental mathematics behind deep neural networks.

