13 min read
—

Learn what is text annotation and how to annotate text data efficiently. Get access to a free OCR tool or build your own text recognition model on V7.

AI systems use huge amounts of annotated data to train highly accurate and target-specific models. During the annotation process, a metadata tag is used to define the characteristics of a dataset.
In-text annotation, that metadata includes tags that highlight attributes such as phrases, keywords, or sentences. The quality of text annotations is crucial to building high precision models. This article will focus on different aspects of text annotation and its use cases.
Here’s what we’ll cover:
What is Text Annotation
Types of Text Annotation
Text Annotation use cases
And in case you are here searching for a kick-ass text annotation tool—we got you covered!
You can easily annotate text data on V7 and train your own model, or... use a public V7 Text Scanner model to detect and read text in your images in any language and alphabet, including handwritten text.
Looks cool? Try it out!

AI for document processing
Automate finance knowledge work beyond basic text annotation
Get started today
Don't forget to also check out our Open Datasets repository to find quality data for training your models!
Now, let's dive in!
What is Text Annotation
Text Annotation for machine learning consists of associating labels to digital text files and their content. Text annotation converts a text into a dataset that can be used to train machine learning and deep learning models for a variety of Natural Language Processing and Computer Vision applications.
In simple terminology, Text Annotation is appending notes to the text with different criteria based on the requirement and the use case. Annotation can be annotating words, phrases, sentences, etc., and assigning a label to them like proper names, sentiment, intention, etc.
Text Recognition vs. Document Processing
Text Recognition is the process of converting printed and handwritten texts into machine-readable text. We refer to it as Optical Character Recognition (OCR), which recognizes the texts from any document in pdf, doc, or image in jpg, png, jpeg, or similar.
Automated document processing, which is also known as IDP (Intelligent Document Processing) not only recognizes the text but also understands the semantics of it. IDP leverages text recognition and understands the meaning of the recognized text using text annotation. Those kind of models require annotated data.
Text Recognition and Document Processing are different concepts where Text Recognition can be thought of as the subtask in Document Processing. Modern AI data extraction tools build on both OCR and IDP to transform raw text into structured, actionable data.
Now, let's discuss different types of text annotation!
Types of Text Annotation
Text Annotation is categorized into multiple types based on what part of the text is annotated and what that portion of text signifies.
Sentiment Annotation
Sentiment Annotation is the annotation of the sentences with the corresponding sentiment of the sentence. It is difficult to determine the emotion of the sentences over a text or handwritten message, but it's not impossible. For sentiment analysis, we require annotated data using sentiment annotation pictured below.

As you can see, the sentences have the corresponding sentiments attached tothem. However, these are pretty much clear sentences without ambiguity. But in the case of complex sentences, precise sentiment annotation is required, especially for the use cases that are not generalized and have particular sentiment for a specific kind of text.
E-Commerce applications such as Flipkart or Amazon use this kind of annotation to understand the customer's feedback from their comments about the products. Likewise, sentiment annotation is leveraged for preparing the dataset for training sentiment analysis models that categorize the texts into various labels such as happy, sad, angry, positive, negative, neutral, etc.
Intent Annotation
Intent Annotation annotates the sentences to detect the intent that matches the correct context of the sentences. This kind of annotation technique is widely used in virtual assistants and chatbots.
In these cases, the response is given based on the intent detected from the previous message received by the end-user.
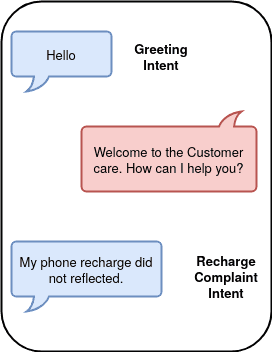
As shown above, when the user replies, the intent of the message is detected, and processing that message, the chatbot then delivers the response.
The responses are designed in such a way that a particular set of answers will be delivered when a specific intent is triggered. In the example, the "Hello" message by the user detected "Greetings Intent" and the designed Welcome message is sent for the response. The subsequent reply from the user detects "Recharge Complaint Intent". Likewise, the cycle continues, and the chatbot replies with appropriately designed messages for particular intents.
Here, the need arises for intent annotation to train the assistants to detect correct intents with high precision because it might be annoying for the user if the chatbot is unable to reply with the right message.
Siri, Alexa, and Cortana are well-known virtual assistants that show promising performance concerning accuracy. These assistants are intelligent as they are trained on large amounts of intent annotated data. For example, “Hi”, “Hello”, “Hola”, “Hey”, etc. detects the intent greeting and the response will be based on this intent which will revert to something like “Hello, how can I help you?” These categorize into intents like to request, command, assertion, negation, etc., or more specific to the use case "Recharge Complaint Intent" as in the above example.
Entity Annotation
Entity Annotation annotates the key phrases, named entities, or parts of speech of the sentences. Entity annotation helps drive attention to the crucial details of the long text. This annotation also helps prepare the dataset for models that extract different kinds of entities from a huge amount of text. It is widely used in most NLP-related tasks.
Entity recognition is a natural language processing technique that can automatically scan entire articles and pull out some fundamental entities in a text and classify them into predefined categories.
For example, given the sentence "Paris is the capital of France", the idea is to determine that "Paris" refers to the city of Paris and not to Paris Hilton or any other entity that could be referred to as "Paris"

As shown in the image, entities such as DATE, EVENT, GPE (Geo-Political Entity), etc. is annotated. This enables machines to understand the text in a much better way.
The entities can be any of the following:
1. Keyword phrase: Example- healing is difficult, the decision from the mayor, etc.
2. Parts of speech: Adjectives, Nouns, Verbs, etc. Example- reading, dead, suspicious, etc.
3. Named Entity: Location, person name, organization name, date, event, etc.
For example, we can extract detailed numerical information from medical reports or extract entities such as organization, person name, location, law sections, etc. from the legal documents. Moreover, a document like a thesis or a research paper is difficult to read due to the micro-level details and the volume of the text.
In these types of cases, entity annotation helps read the necessary information at a glance with ease.
Text Classification
Text Classification as the name suggests categorizes the documents or the group of sentences under a particular label. This annotation helps segregate a large volume of texts or documents into the appropriate categories such as document classification, product categorization, and sentiment annotation.

Above given are some tweets which are classified in some particular labels shown like Education, politics, and entertainment. The contents are annotated in the same way to prepare a dataset for the machine learning classification models.
Check out Image Classification Explained: An Introduction [+V7 Tutorial].
In E-Commerce, the products are categorized based on the content and the details of the product. Likewise, the tweets on Twitter, the news are categorized based on the text and we can have different categories such as education, research, politics, entertainment, etc.
Linguistic Annotation
Linguistic Annotation refers to the annotation of the language-related details of the text or speech such as semantics, and phonetics. This annotation helps understand the phonetics and the discourse of the content. In addition, this also includes identifying the intonation, stress, pauses, etc.
Linguistic Annotation can be further divided into the following three categories of annotation:
Discourse Annotation: The linking of anaphors, and cataphors to their antecedent or descendent subjects.
Example: Mike is kind to his colleagues. He often helps them with their queries.
Here, Mike is referred to by "He" and his colleagues are referred to by "them". A human understands this reference but the machine requires annotation to learn this kind of linking of the sentences.
Semantic Annotation: The labeling of the metadata of the original text.
Example: OTT Platforms are trendy.
Here, OTT is the jargon that can be annotated with the full form "Over The Top" and the examples like "Netflix", "Amazon Prime Videos", etc.
Phonetic Annotation: The annotation of the stress, tone, and pauses.
Chatbots, virtual assistants, etc. leverages linguistic annotation to understand the linguistic details of the replies from end-user to respond to them with better clarity.
The annotation techniques are cohesive—sentiment and intent annotation can be viewed as the sub-type of text classification and linguistics annotation can be considered similar to entity annotation.











How to annotate text on V7 [Tutorial]
One can annotate text on V7 if needed but V7’s public Text Scanner model might be a better choice because it saves time and it is highly accurate to pseudo annotate labels.
V7 has added a public Text Scanner model to its Neural Networks page to help you detect and read the text in your images automatically. In this tutorial, we'll take a quick video tour of how to use the feature, followed by step-by-step instructions for setting up your own text scanner.
Before we can start effortlessly pulling text from images and documents, we'll need to get three quick setup steps out of the way:
Turn on the public Text Scanner model on the Neural Networks page.
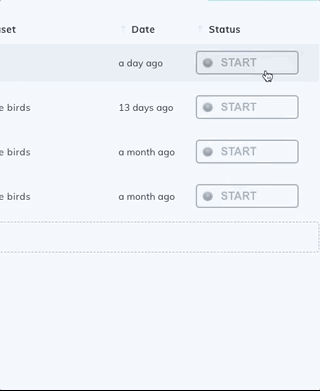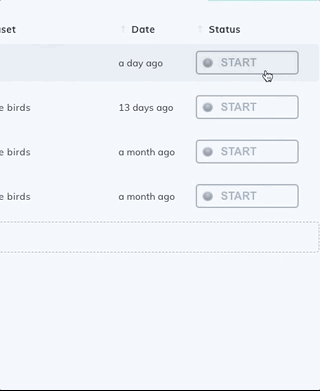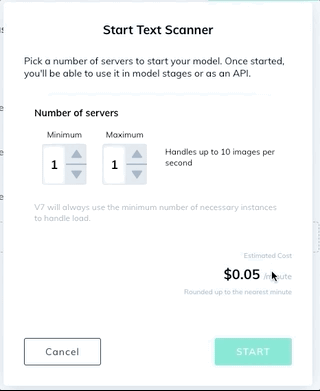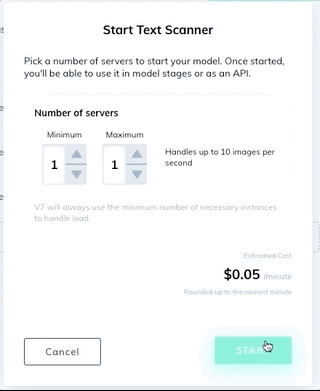
Create a new bounding box or polygon class that contains the Text subtype in the Classes page of your dataset. You can optionally add an Attributes subtype to distinguish between different types of text.
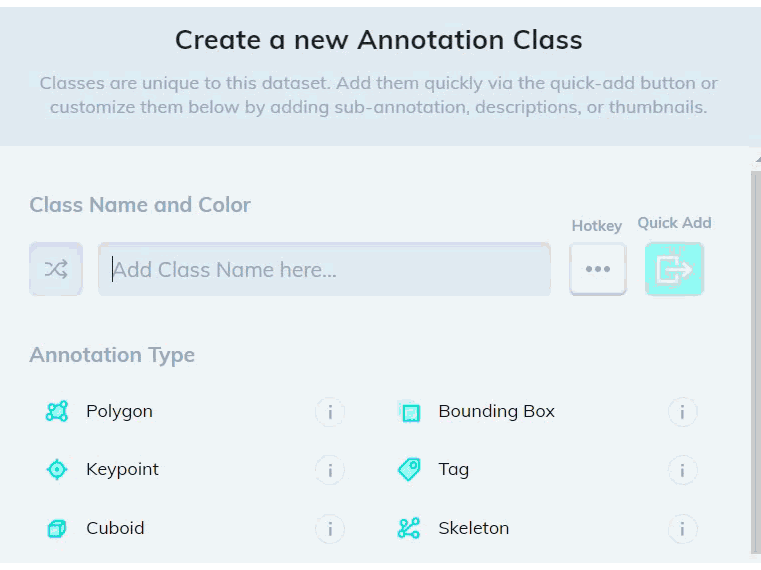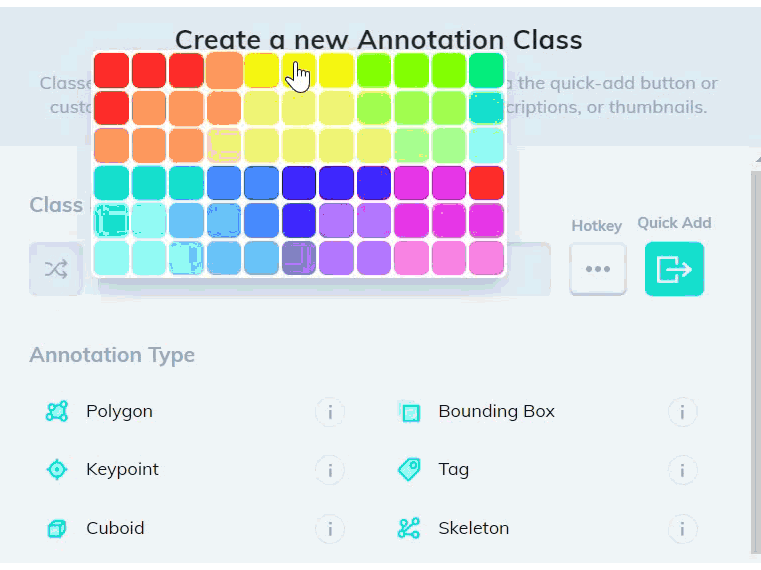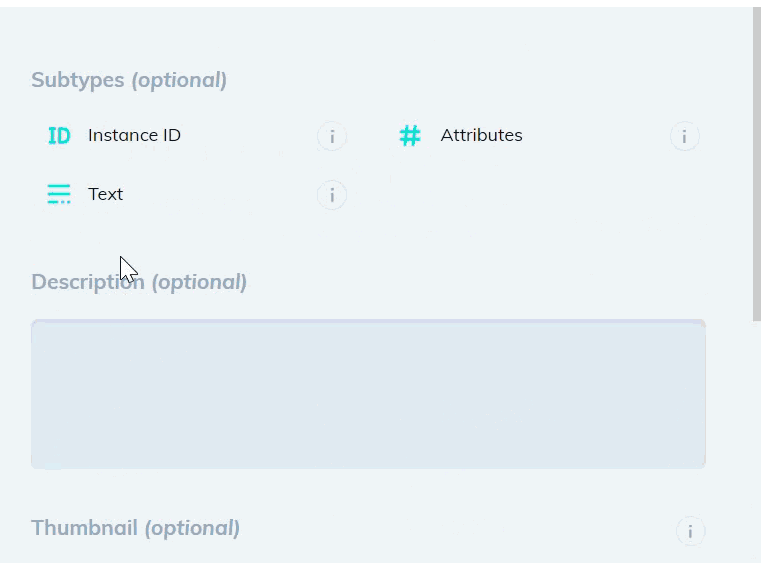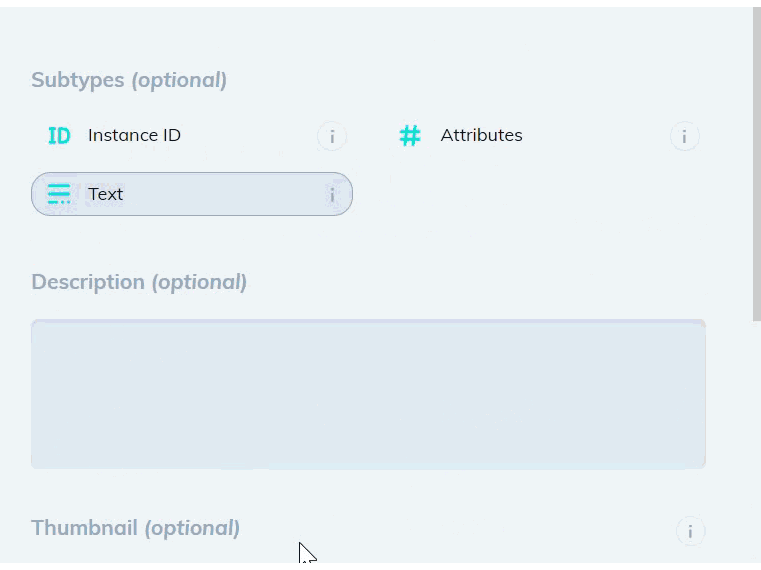
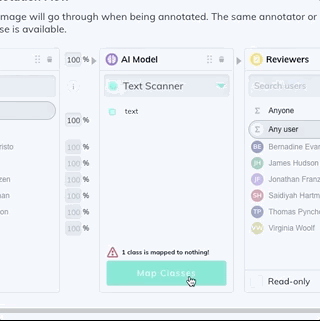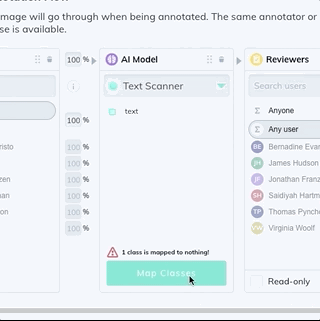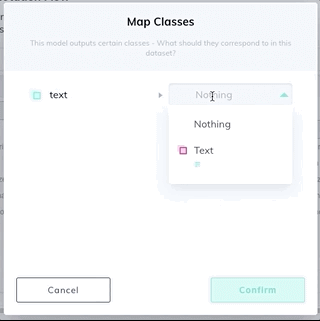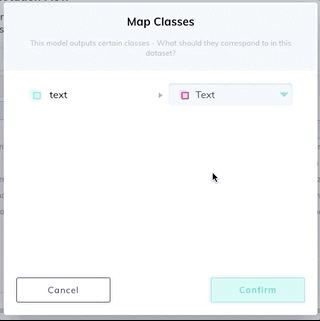
Add a model stage to your workflow under the Settings page of your dataset. Select the Text Scanner model from the dropdown list, and map your new text class. If the model stage is the first stage in your workflow, select Auto-Start to send all new images through the model automatically.
That's it! Now you're ready to sit back and let the model detect and read text automatically instead of you making efforts to annotate manually.
V7 text scanner will detect and read text on any kind of image, whether it's a document, photo, or video. As it is extensively pre-trained, it will be able to read characters that humans may find difficult to interpret.

Looking for the perfect OCR dataset? Check out 20+ Open Source Computer Vision Datasets. You can also explore our ranking of the best OCR platforms powered by AI.
Text Annotation use cases
Finally, here are some of the most prominent applications of text annotation.
Healthcare
Text data Annotation plays a vital role in the healthcare domain, especially today when we deal with AI-based services in the medical field such as patients records management, online medical consultancy healthcare chatbots, etc.
For a domain like healthcare, we can not take any risks regarding data accuracy, as it is concerned with the patient’s life, and, therefore, a large amount of quality annotated data is required.
Here are some of the healthcare use cases where text annotation plays an important role:
Entity Annotation for extracting details in the medical reports such as the numerical data (example: blood pressure level, hemoglobin, etc.) or some useful keyphrases
Entity Annotation for annotating medicines, dose, time for taking medicine, etc. from the prescription given by the doctor.
Intent Annotation and linguistics annotation for research and study purpose which annotates details and crux of the context making it easier to go through the large volume of the content.
Sentiment Annotation for the feedback purpose in any hospital, laboratory, or healthcare applications.
Intent Annotation, Linguistics Annotation, and Semantic Annotation for the customer service in the healthcare applications as well as the chatbots.
Check out 21+ Best Healthcare Datasets for Computer Vision and learn How to Annotate Medical Images.
Banking
Banking also has quite an extensive range of use cases as nowadays, we use online banking that includes interacting with the applications and websites for transactions and other services given by the bank
Some use cases for data labeling in banking include:
Text Classification helps customer churn prediction.
Intent, sentiment, and linguistic annotation are used for customer services and chatbots.
Entity Annotation is utilized for extracting entities such as name, amount, bank account no., IFSC code, etc. from various types of forms.
Logistics
The logistics and Supply Chain industry is expanding at an astonishing rate and so is the use of technology in it. From billing and invoice labeling to virtual assistants, there is a surplus data generated every single day.
Customer Care Virtual Assistant detect intent by identifying a particular entity from the user message.
When the customer approaches for a rate inquiry, the virtual assistant asks a few questions and immediately provides the approximate rate. The entities and the useful information are extracted from the responses, processed further and the rates are provided.
Data Annotation in logistics is also used as follows:
Entity annotation for recognition of the names, amounts, order no, items, etc. from the bills and invoices, for example for AI data extraction from shipping labels
Sentiment and Entity Annotation for the customer feedback.
Speed up your labeling 10x by using V7 auto annotation tool.
Government
The use of annotation in the government sector is a little bit similar to banking but has a broad spectrum than banks. The government sector includes the education department, research, food and drugs, legal, income tax department, forensics, etc.
The use of annotation in this domain encapsulates:
The intent, entity, and linguistic annotation for all the above-discussed sector’s customer service, chatbots, and virtual assistants.
Text classification for categorizing legal cases in criminal, civil, etc. based on the content of the cases.
Linguistic Annotation for police and crime branch for detecting tones, semantics, etc. of the criminal and various cases and reports.
Entity Annotation for all the government documents annotating the entities such as names, department, location, and key phrases.
Media and News
Media and News is another sector having a lot of textual content where the Annotation can be widely used to understand the content.
Data Annotation in media and news are in the following use cases:
Entity annotation for annotation of various entities such as names, location, key phrases, numbers, etc. from various articles.
Text Classification for categorizing the content into various labels for news such as sports, education, government, domestic, international, entertainment, etc.
Linguistic Annotation and Semantic Annotation for annotation of the phonetics, semantics, and discourse for the articles and news reports.
Apart from the use cases mentioned above, there are various other subdomains such as Research, Education, Entertainment, E-Commerce, Multimedia, etc.
Text Annotation: Key takeaways
Text Annotation plays an important role today as we want a large amount of data for training various Machine Learning and Deep Learning models.
Well annotated data improves the quality of data that further enhances the accuracy of the AI models. So, for an AI model to attain higher accuracy and precision, the first step of the pipeline is to prepare well-annotated data, which demands the use of Text Annotation in the case of Natural Language Processing.

Deval is a senior software engineer at Eagle Eye Networks and a computer vision enthusiast. He writes about complex topics related to machine learning and deep learning.

