16 min read
—
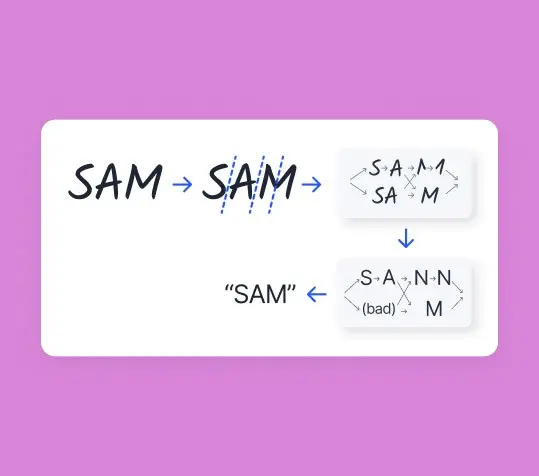
Handwriting recognition (HWR) technology is an active area of artificial intelligence research. Let’s take a closer look at its current state and applications.

Optical character recognition (OCR) technology that converts printed and physical documents into machine-readable texts has already spread across many industries.
But there’s still a huge challenge ahead—human handwriting.
Handwriting recognition (HWR) technology is an active area of artificial intelligence research. Its growing popularity drives its development. Various reports predict market demand and the number of use cases will increase, spanning areas such as enterprise, field services, and healthcare.
New advances in machine learning are constantly improving the accuracy of handwriting recognition. In this article, we’ll take a closer look at the current state of this technology.
Here’s what we’ll cover:
What handwriting recognition is
Benefits and challenges of handwriting recognition
Supporting methods and architectures
Let’s dive in.

AI for document processing
Extract data from handwritten financial documents automatically
Get started today
What is handwriting recognition?
Handwriting Recognition (HWR) is the capability of computers and mobile devices to receive and interpret handwritten inputs. The inputs might be offline (scanned from paper documents, images, etc.) or online (sensed from the movement of pens on a special digitizer, for example).
A handwriting recognition system also includes formatting, segmentation into individual characters, and training a language model that learns to frame meaningful words and sentences.
The most popular technique for handwriting recognition is Optical Character Recognition (OCR). It allows us to scan handwritten documents and then convert them into basic text through computer vision.
Check out our guide on the best OCR tools here!
Benefits of handwriting recognition
The many everyday use cases of handwriting recognition make it helpful across multiple industries. Let’s go through a few benefits of adopting this technology.
Better data storage
Handwriting recognition paves the path for optimal data storage.
Many files, contracts, and personal records include handwritten information, such as original signatures or notes, that can be converted into electronic text with handwritten text recognition technologies.
Electronic data requires less physical space and resources than storing physical files. It’s cost-effective and eliminates the need to sort, organize, and find information in paper documents manually.
Multiple industries have already started adopting this technology:
Insurance and banking sectors digitalize forms, tax receipts, and transaction history in the form of e-pdfs and signature verification
Retail industry stores the bills and customer transaction history
Healthcare facilities implement digital data strategies, such as electronic health records (EHR), to reduce mistakes caused by illegible scripts
Logistic companies use HWR technologies to scan the bill of lading documents and detect tags on parcels to sort them. See our guide to freight invoice automation here.
Looking for examples of other AI applications cross industries? Check out our article on AI in finance.
Faster information retrieval
Thanks to handwriting recognition and electronic data storage, we can retrieve data much faster than from physical copies.
We can quickly find stored electronic information by using a file search and specifying what we're looking for.
This is similar to what the IT industry does for Search Engine Optimization. Indexing Internet resources made it easy to find information based on keywords in the sea of content.
Improved accessibility
Handwriting recognition’s ability to identify text from images and videos and store it in text form can also contribute to greater accessibility.
Optical Character Recognition technology is used for converting text into speech, which helps blind and visually impaired individuals. Envision introduced AI-powered smart glasses with optical character recognition capability to read any text from any source.
In ed-tech, OCR can help take notes or convert mathematical equations, which makes studying much easier. For example, Microsoft Math makes it possible to take a snapshot of a handwritten math problem and have the system provide explanations, examples, solutions, relevant educational materials, etc.
Better customer service
Handwriting recognition can help improve business processes and make their functioning more convenient and secure for their customers.
Different organizations can easily digitalize handwritten forms provided by their clients for easier access and more cost-effective storage. Moreover, banks, medical units, and insurance companies that deal with personal data can keep the documents secure in cloud storage. The scanned data requires proper authentication to access, which lowers the risk of security breaches compared to storing hard copies.
Challenges of handwriting recognition
As any emerging technology, handwriting recognition comes with its challenges. Let’s take a look at a few most pressing ones.
Varied language models
Due to a large set of manuscripts caused by the variety of languages and scripts that differ from region to region, the scope of handwriting recognition is limited and requires a complete review of the converted text to preserve the original manuscript in the electronic format.
Great variability
Handwriting changes from person to person. The strokes, irregularities, spacing of letters and characters, and block or cursive handwriting make it hard for handwriting recognition technologies to achieve accuracy.
Poor image quality
The quality and accuracy of converted text depend on the quality of the image and the noise present, making it harder to process older documents that degrade with time.
Looking for a text scanner that makes document identification easier? Check out V7’s document processing tool.
Methods of handwriting recognition
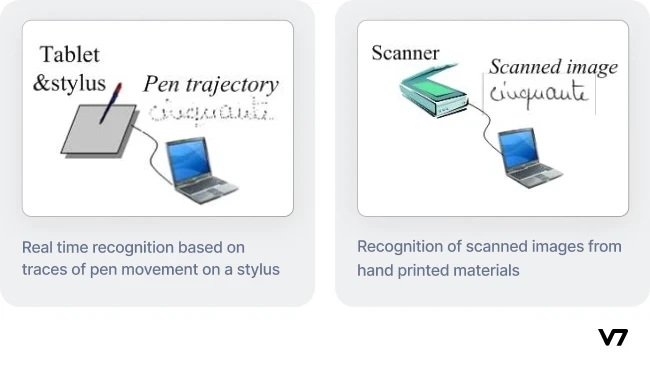
Online vs Offline Handwriting recognition system [source]
There are two types of handwriting recognition depending on when the identification takes place.
Online handwriting recognition
Online handwriting recognition involves the automatic conversion of text as it is written on a unique digitizer or digital pad with a sensor that picks up the pen tip movements and uses this dynamic data to evaluate the character and words as they’re being written.
The main features that make the online handwriting recognition system predict the text are:
a) line quality
b) speed of writing/word
c) execution of letters
Offline handwriting recognition
Offline handwriting recognition involves the automatic conversion of an image of text into letter codes usable within computers and text processing applications. The data obtained in this form is a static snapshot of the handwriting.
Without information on pen pressure, stroke direction, etc., it’s more difficult to achieve accuracy with offline recognition. However, it’s still highly in demand, especially considering the need for digitizing existing historical and archival documents.











Handwriting recognition techniques and supporting architectures
There are several methods of recognizing human handwriting with machine learning, and new technologies are bound to emerge.
Here, we’ll summarize the most prominent handwriting recognition approaches and algorithms.
CapsNets
Capsule networks are one of the newest and most advanced architectures in neural networks and are seen as an improvement over the existing machine learning technologies.
The pooling layer in a convolutional block is used for reducing data dimension and achieving spatial invariance, which means that it identifies and classifies the object regardless of where it is placed in the image.
One of the main disadvantages is that while pooling, a lot of spatial information about the object's rotation, location, scale, and other positional attributes are lost.
Another shortcoming is that if the object's position is slightly changed, the activation does not appear to change with its proportion. This results in good accuracy in image classification but poor performance if you want to locate the object exactly where it is in the image.
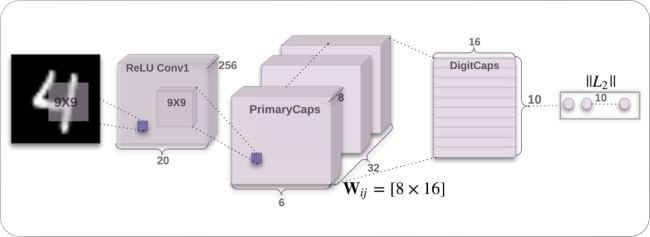
Dynamic routing between capsules [source]
A capsule is a block of neurons that stores a different set of information (about its position, rotation, scale, etc.) about the object it is trying to identify in a given image in a high-dimensional vector space, with each dimension representing something special about the object.
Kernels that generate the feature maps and extract visual features work with dynamic routing by combining individual opinions of multiple groups called capsules. This results in equivariance among kernels and improves performance compared to CNNs.
The image above depicts how CapsNets work, where input is reshaped and squashed after passing through two convolutional blocks to form 32 primary capsules with 6 x 6 x 8 capsules each. These primary capsules are fed into higher layer capsules, a total of ten capsules with 16 dimensions each, and margin loss is calculated on these higher layer capsules to determine class probability.
CNNs will recognize handwritten text better if the training data is significant, as the model needs to learn a large amount of variance to accommodate different handwriting styles. CapsNets help reduce the amount of data required while still maintaining high accuracy.
Multidimensional Recurrent Neural Networks (MDRNNs)
RNN/LSTM (Long-Short Term Memory) deal with sequential data but are limited to performing with 1-D data, such as text. Therefore, they cannot be directly extended to images.
Multidimensional Recurrent Neural Networks can be used to replace a single recurrent connection in a standard Recurrent Neural Network (RNN) with as many recurrent units as there are dimensions in the data.
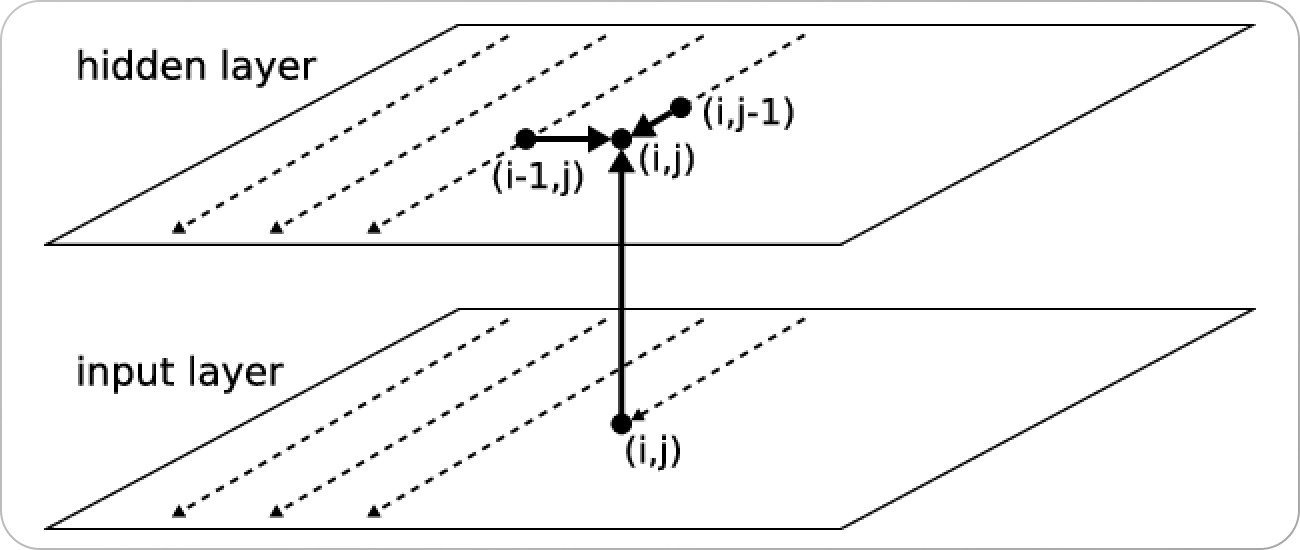
Two-dimensional MDRNN [source]
During the forward pass, at each point in the data sequence, the network's hidden layer receives both an external input and its own activations from one step back along all dimensions.
The main problem in the recognition system is transforming two-dimensional images into one-dimensional label sequences. This is done by passing the input data through a hierarchy of MDRNN layers, with blocks of activation functions in between after each layer of RNN.
The heights of the blocks are chosen to incrementally collapse the 2D images onto 1D sequences, which the output layer can then label.
Refer to this paper on offline handwriting recognition with MDRNN for more details on how it works.
Multidimensional Recurrent Neural Networks aim to make the language model robust to local distortions across every combination of input dimensions (such as image rotations and shears, the ambiguity of strokes, and different handwriting styles) and allow them to flexibly model multidimensional context.
Connectionist Temporal Classification (CTC)
Connectionist Temporal Classification (CTC) is an algorithm that deals with tasks such as speech recognition, handwriting recognition, etc., where the entire input data is mapped to the output class/text.
Handwritten text recognition involves the mapping of images to the corresponding text. However, we don’t know how the patch of the image is aligned with the characters. Without this information, traditional approaches don’t work.
Connectionist Temporal Classification (CTC) is a way to get around without the knowledge of how a particular part of speech audio or images of handwriting is aligned to a specific character. Simple heuristics, such as giving each character the same area, won't work since the amount of space each character takes varies in handwriting.

Sequence Modeling with CTC [source]
The input to this algorithm is a vector representation of the image of handwritten text. There is no direct alignment between the image pixel representation and the sequence of characters. CTC aims to find this mapping by summing over the probability of all possible alignments between them.
Models trained with CTC typically use a Recurrent Neural Network (RNN) to estimate the per time-step probabilities as RNN accounts for context in the input. It outputs character scores for each sequence element, represented by a matrix.
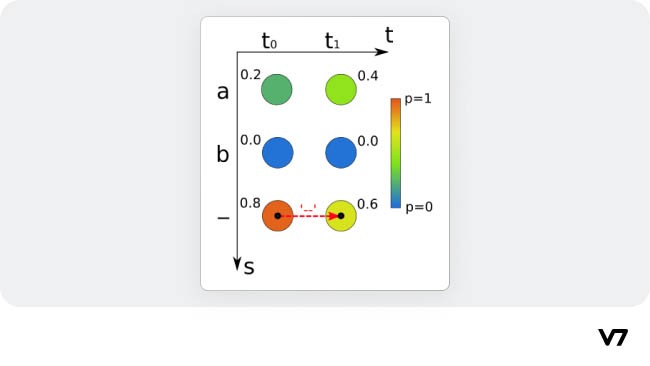
Best path decoding strategy to find the most probable text [source]
For decoding, we can use:
Best path decoding that involves predicting the sentence by concatenating the most probable character per time stamp to form the complete word, which yields the best path. In the next iteration of training, duplicate characters and blanks are removed to decode the text better.
Beam search decoder, where multiple output paths are suggested with the highest probabilities. The paths having lesser probabilities are dropped to keep the beam size constant. The results obtained through this approach are more accurate and are often combined with language models to give meaningful results.
Check out Autoencoders in Deep Learning: Tutorial & Use Cases
Transformer models
RNNs are a perfect fit to model textual data as they can capture their temporal aspect. But they also come with the cost of training, as the sequential pipelines prevent parallelization and memory limitation when processing longer sequence lengths. Transformer models apply a different strategy, using self-attention to memorize the whole sequence.
A non-recurrent approach to handwriting can be achieved with transformer models.
Pay attention to what you read
Transformer model, in combination with a multi-head self-attention layer both at the visual and textual layer, can learn the language model-related dependencies of the character sequences to be decoded.
The language knowledge is embedded into the model itself, so there is no need for any additional post-processing steps using a language model. It’s also well-suited to predict outputs that are not part of the vocabulary.
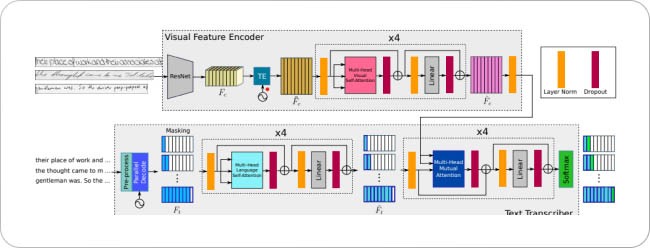
Overview of the architecture of Pay attention to what you read model [source]
The Pay attention to what you read architecture has two parts to it:
Text transcriber devoted to the output of the decoded characters by mutually attending to visual and language-related features
Visual feature encoder aimed to extract relevant information from handwritten text images by focusing on the various character positions and their contextual information
If you want to dive deeper into the working of this non-recurrent handwriting recognition model, look at this paper on Pay attention to what you read.
Encoder-Decoder and Attention Networks
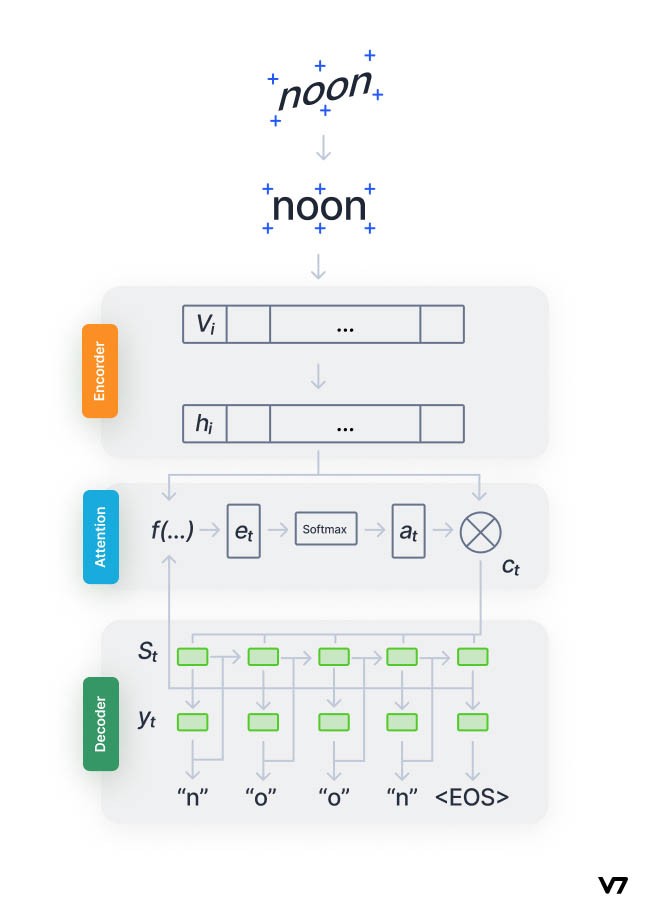
Architecture of encoder-decoder model coupled with attention network [source]
The training handwriting recognition systems always suffers from the scarcity of training data, as it’s impossible to create a set with all combinations of languages, stroke patterns, etc.
To solve the problem, this method leverages the pre-trained feature vectors of text as a starting point. State-of-art models hint towards using an attention mechanism in combination with RNN to focus on the useful features at each time stamp.
The complete model architecture can be divided into four stages:
1. Transformation
A CNN network is trained for localization. It takes an input image and learns the coordinates of fiducial points used to capture the shape of the text. Since handwritten words can be tilted, skewed, curved, or irregular, the input word images are normalized by applying some transformations.
2. Feature extraction
Features in the handwritten text include stroke angles, series of tilts, etc., for which a ResNet-type of architecture can be used to encode the normalized input image into a 2D visual feature map.
3. Sequence modeling
The features extracted in the previous step are used as a sequential frame (just like text from left to right). It is decoded using a Bidirectional LSTM for sequential modeling to retain the contextual information within a sequence from both sides and recognize each character independently while taking into account the higher-level abstractions.
4. Prediction
The output vectors containing the contextual information from the last decoder are transformed into words. First, the output vector needs to be fed into a fully-connected linear layer to get a vector of the size of the vocabulary, which is used to train the model. Then, the softmax function as an activation function is applied to this vector in order to get a probability score for each word in the vocabulary.
Looking for a starting point to train your own handwriting recognition model? Check out this code example.
Scan, Attend and Read
Scan, Attend and Read is a method proposed for end-to-end handwriting recognition using an attention mechanism. It scans the entire page in one go. Therefore, it doesn’t depend on the prior segmentation of an entire word into characters or lines.
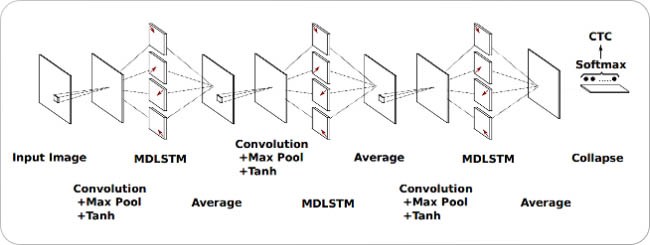
Scan-As-You-Read algorithm for handwriting recognition, alternating LSTM layers in a multi-dimensional fashion [source]
This method uses a multi-dimensional LSTM (MDLSTM) architecture as the feature extractor similar to the one described above. The only difference is the final layer, where the extracted feature maps are collapsed vertically, and a softmax activation function is applied to recognize the corresponding text.
Refer to this paper on Scan, Attend and Read for more details.
The attention model used here is a hybrid combination of content-based attention and location-based attention. The decoder LSTM modules take the previous state and attention map as well as the encoder features to generate the final output character and the state vector for the next prediction.
Convolve, Attend and Spell
Handwriting recognition is connected with pattern recognition in many ways.
Sequential neural networks backed with attention mechanism can become a state-of-art technique for handwriting recognition, as highlighted in this paper on Convolve, Attend and Spell model.
Convolve, Attend and Spell is a sequence-to-sequence model for handwritten word recognition based on an attention mechanism. The architecture has three main parts:
an encoder, consisting of a CNN and a bi-directional GRU
an attention mechanism focusing on the pertinent features
a decoder formed by a one-directional GRU, able to spell the corresponding word, character by character
Recurrent Neural Networks (RNN) are best suited for the temporal nature of the text. When paired with such recurrent architectures, attention mechanisms play a crucial role in focusing on the right features at each time step.
Sequence-to-sequence (seq2seq) models follow an encoder-decoder paradigm.
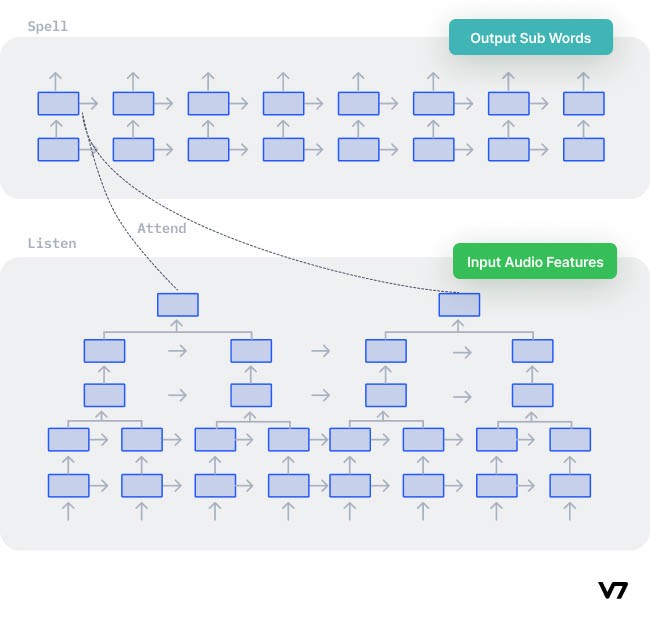
Working of Listen, Attend and Spell for handwriting recognition [source]
The encoder consists of a Convolutional Neural Network (CNN) that extracts the visual features from the written text, sequentially encoded by an RNN. The decoder is another RNN that decodes one character at a time, thus constructing the whole word and spelling it out.
An attention mechanism bridges the encoder and the decoder to provide a high-correlated context vector that focuses on each character’s features at every decoding time step.
Encoder-decoder or any other seq2seq recognition performance degrades if the text input is long due to limitations such as long-range dependency, etc. Attention units help search for a set of positions in the encoder's hidden states where the most relevant information is available.
Handwriting Text Generation
Synthetic handwriting generation is the task of generating real-looking handwritten text. It can be used to boost existing datasets.
Deep learning models require a lot of data to train, and obtaining a vast corpus of annotated handwriting images for different languages is a cumbersome task.
We can use Generative Adversarial Networks to generate training data to solve this problem.
ScrabbleGAN
Handwritten text recognition has a limited scope in training data as each person has a unique writing style. Gathering a varied set of datasets is very costly and annotating the text is even more challenging.
To minimize this need for data collection and annotation of handwritten data, semi-supervised learning is a good fit. It uses a combination of labeled and unlabeled data samples to improve the performance of the models. Compared to fully supervised models, it learns to identify better features and adapt to unseen images better.
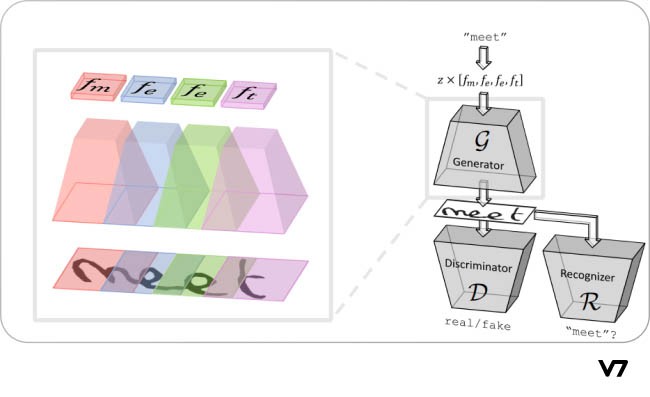
Generative Adversial networks for text data generation [source]
ScrabbleGAN is a semi-supervised approach to synthesizing handwritten text images. It relies on a generative model which can generate images of words with an arbitrary length using a fully convolutional network.
Furthermore, the generator is intelligent enough to manipulate the resulting text style and strokes. In addition to the discriminator D, the resulting image is also evaluated by a text recognition network R. While D promotes realistic-looking handwriting styles, R encourages the result to be readable and true to the input text.
To learn how to use synthetic data for training your machine learning models, read What is Synthetic Data in Machine Learning and How to Generate It
Key takeaway
Handwriting recognition technology is at the forefront of AI research.
It’s useful across multiple industries, allowing for better data storage, quicker information retrieval, accessibility, and more effective business processes.
New methods are emerging to tackle its challenges, such as unpredictability, variability, or image quality.
A few of the most prominent architectures include:
CapsNets
Multidimensional Recurrent Neural Networks
Connectionists Temporal Classification
Transformer models
Encoder-decoder and attention networks
Generative adversarial networks

Pragati is a software developer at Microsoft, and a deep learning enthusiast. She writes about the fundamental mathematics behind deep neural networks.

