Computer vision
What is Synthetic Data in Machine Learning and How to Generate It
10 min read
—

Learn what synthetic data is and how to generate and use it for training your machine learning models. Explore popular datasets and synthetic data generators to build better AI faster.

State-of-the-art machine learning models need quantitative and qualitative labeled datasets for better performance. However, It is time-consuming and expensive to annotate large amounts of data with millions of attributes per data point.
Synthetic data helps in addressing the problems associated with data collection, data annotation, and data quality assurance.
Here’s what we’ll cover:
What is synthetic data
How to generate synthetic data
Synthetic data applications in computer vision
Synthetic data challenges
Popular synthetic datasets
Synthetic data generators
And in case you are looking to get hands-on experience labeling data and training your models right away, check out our Open Machine Learning Datasets Repository and the following resources:

AI for document processing
Generate and label financial training data at scale
Get started today
Now, let's begin!
What is synthetic data?
Synthetic data is a form of data that mimics the real-world patterns generated through machine learning algorithms. Many sources identify synthetic data for different purposes, and types of data include:
Text
Images and videos
Tabular
Synthetic data for computer vision can be RGB images, segmentation maps, depth images, stereo-pairs, LiDAR, or Infrared images. Synthetic data for images and videos are typically created using a generative model resembling the latent space of the real-world data. The generative models mainly used for synthetic data generation include:
Generative Adversarial Networks (GANs)
Variational Autoencoders (VAEs)
Autoregressive models
Pro tip: Read An Introduction to Autoencoders: Everything You Need to Know to learn more about Variational Autoencoders.
The importance & benefits of synthetic data
Engineers often require highly quantitative accurate, and diverse datasets to train and build accurate ML models. Synthetic data helps in reducing the costs of data collection and data labeling. In addition to lowering costs, synthetic raw data helps address privacy issues associated with sensitive real-world data.
Furthermore, it reduces bias compared to real data as the developer controls the distribution of synthetic data. It can provide higher diversity by including anomalies that are difficult to source from authentic data.
Here are some of the key benefits:
Faster and cheaper datasets creation
Can circumvent or mitigate problems regarding bias, privacy, and licensing
Supports rich ground-truth annotations
Offers complete control over data
Pro tip: Need to label large datasets? Check out V7's Data Annotation Services to get your data labeled by professional labelers.
Synthetic data vs Augmented and Anonymized data
Developers know about the technique of data augmentation.
The images can be rotated in an already painted way to produce a completely new image in another way. The removal and use of raw data in databases are now increasingly popular. Data anonymization is used for text, which is primarily used by industries such as finance and healthcare.

Data Augmentation variations on an image
On the contrary, synthetic data is new data generated from a reference distribution of the real data.
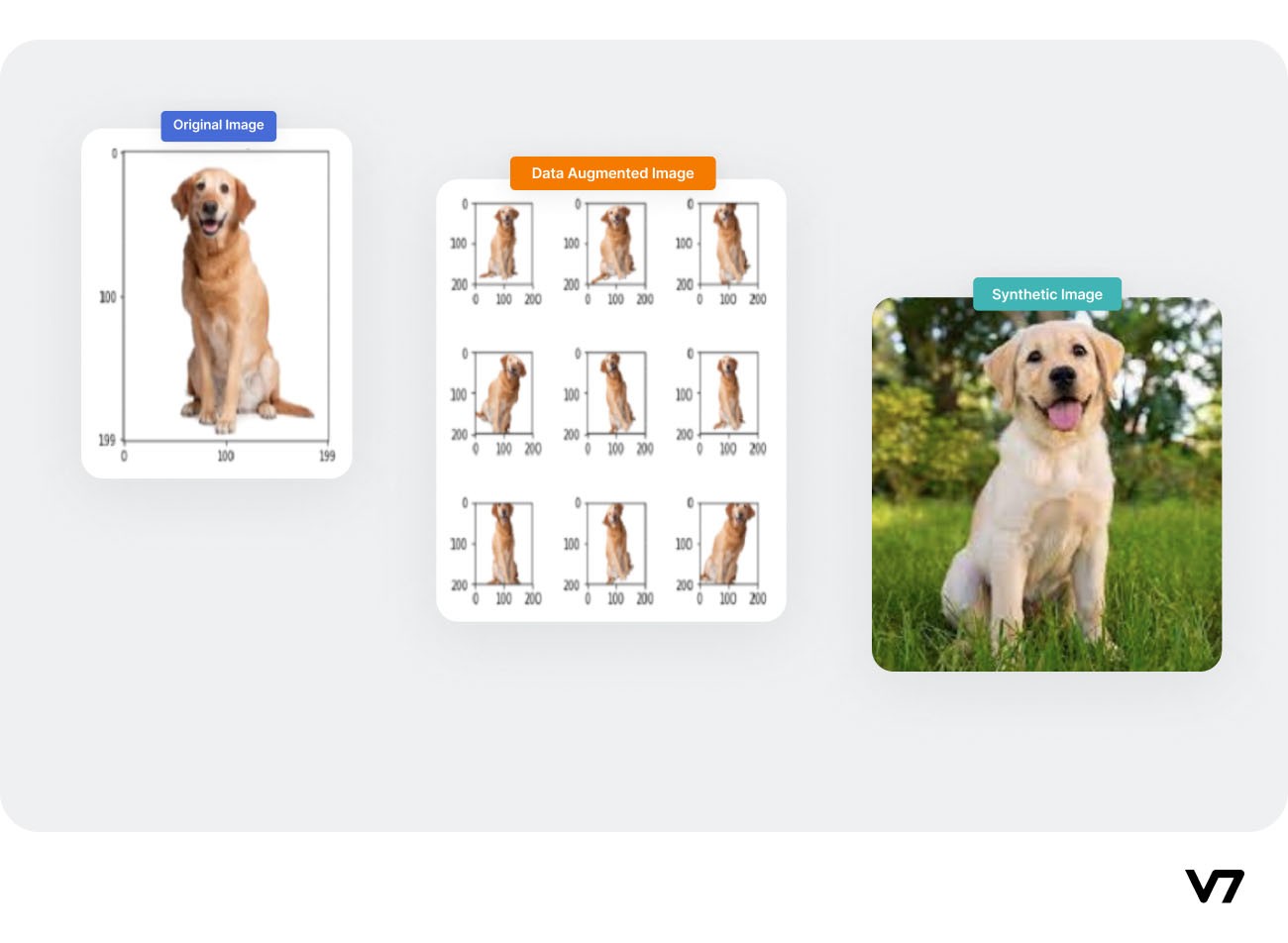
Data augmentation vs. synthetic data
Using the augmentation techniques on the original image, we can achieve transformations on the original image (rotation, flipping, etc.) whereas using a synthetic image generation technique, we can tweak the distribution to create a new data.
How to generate synthetic data
There are two ways to generate synthetic data for computer vision.
1. Deep learning-based methods
a) Using Generative Adversarial Networks (GANs)
Essentially, GANs consist of two neural network agents/models (called generator and discriminator) that compete in a zero-sum game, where one agent's gain is another agent's loss.
The intuition behind the objective function of GANs is to generate data points that mimic data from the training set and fool the discriminator into distinguishing between real and generated samples.
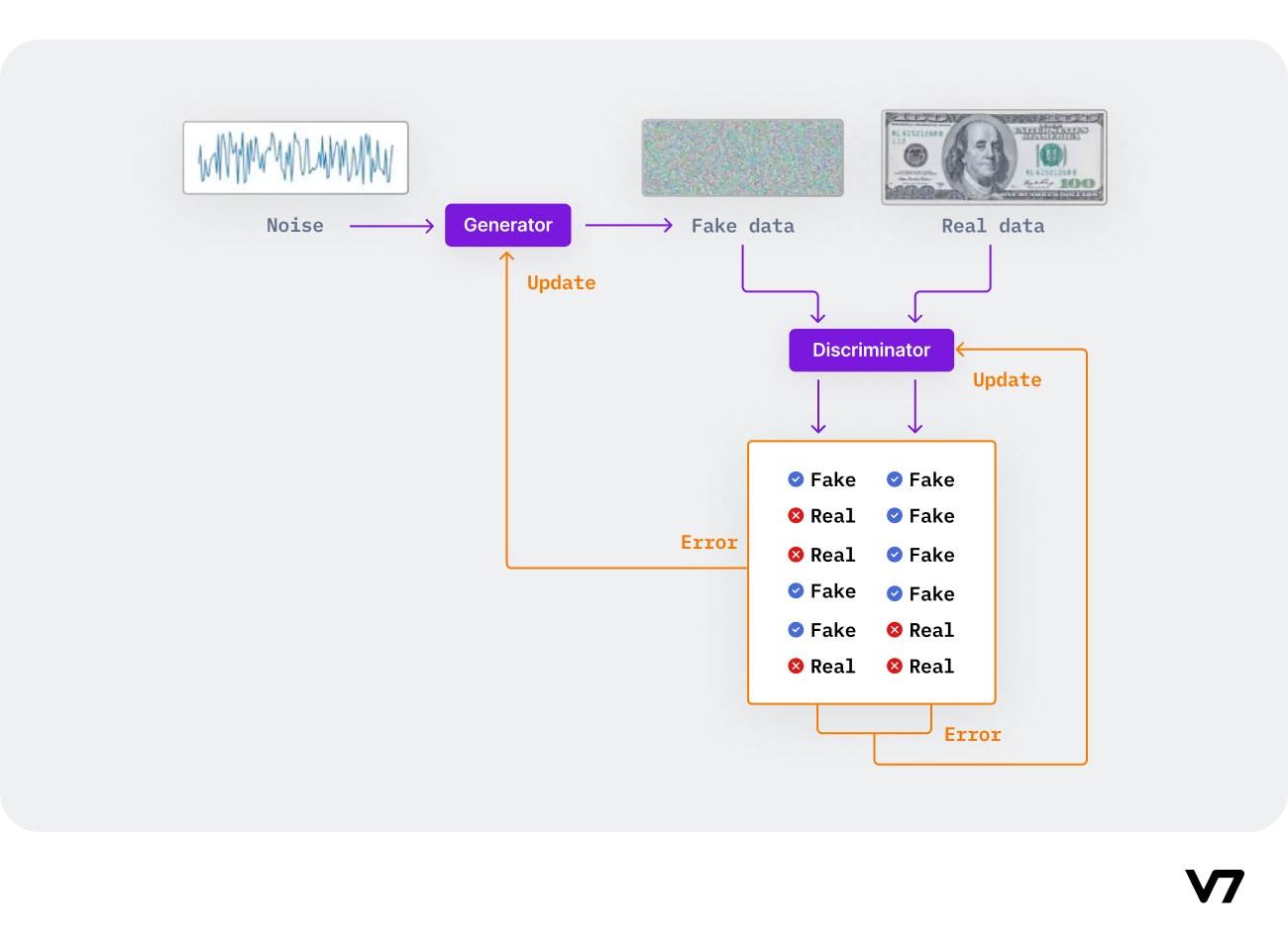
How GANs game the networks into creating high-quality synthetic data
Algorithm using GANs to generate synthetic data
Input: A random noise to the generator module
The generator produces a fake data sample and passes it to the discriminator for evaluation against real world data
The discriminator evaluates the generated data sample and assigns it a real or fake label
The model training continues until the discriminators cannot distinguish between real and fake data samples
Over the years, many architectural variations and improvements over the original GAN idea have been proposed in the literature. Today, most GANs are loosely based on the DCGAN (Deep Convolutional Generative Adversarial Networks) architecture, formalized by Alec Radford, Luke Metz, and Soumith Chintala in their 2015 paper.
Pro tip: Learn more about Neural Network Architectures.
DCGAN, LAPGAN, and PGAN are widely used for unsupervised image synthesis.
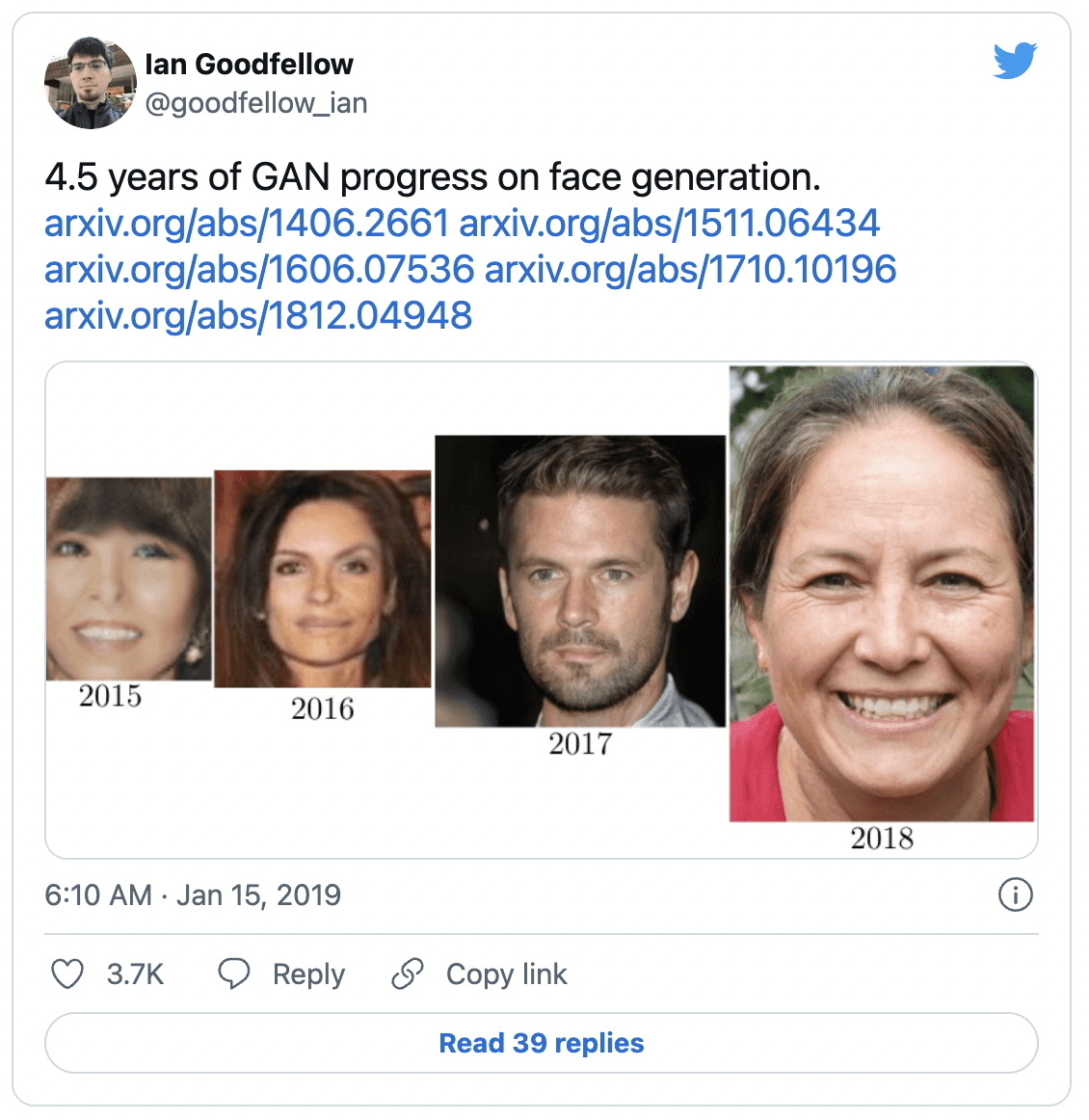
Famous tweet by GANs author Ian Goodfellow on the evolution of synthetic data generated by GANs
b) Using Variational Autoencoder
In the VAE model, the encoder compresses the real dataset into a compact form and transmits it to the decoder. The decoder then generates an output which is a representation of the real dataset. The system is trained by optimizing the correlation between input and output data.
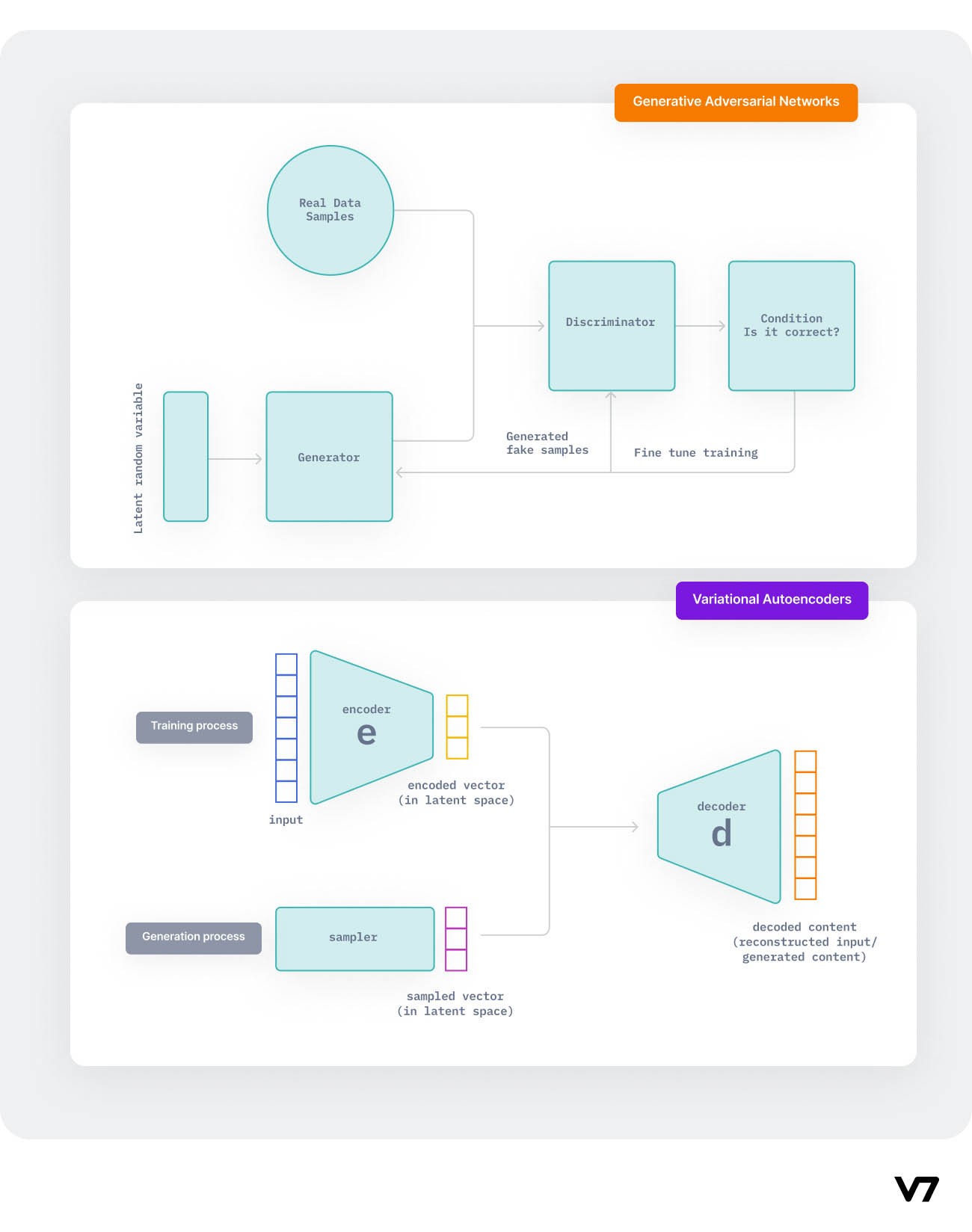
Synthetic data generation using Variational AutoEncoders(VAE)
Algorithm to generate synthetic data using VAE
Input: Real data to the encoder module
The encoder encodes the real data and creates a latent space distribution
The encoded output (a lower dimension and noisy representation of real data) is passed to the decoder.
The decoder reconstructs the input data
2. 3D Rendering-based methods
Here is the basic workflow for 3D Rendering-based SD generation:
Prepare and procedurally generate 3D models of objects, place them in a simulated scene, set up the environment (camera viewpoint, lighting, etc.), and render synthetic images for model training.
Creating a photorealistic virtual world and extracting images of them.
After you have 3D rendered synthetic data, the 3D renderer will also automatically do the data annotation.
Many companies avoid using GANs for generating synthetic data due to following reasons
It is hard to optimize GANs objective function.
GANs have an issue of mode collapse that can lead to loss divergence.
On 07 Mar 2022, Google researchers Klaus Greff, Francois Belletti, and Lucas Beyer released their research paper on Kubric: A scalable dataset generator. It is an open-source Python framework that allows you to create photo-realistic synthetic data.











Four synthetic data applications in computer vision
Now, let's have a look at some of the most popular applications for synthetic data in computer vision.
Self-driving vehicles
Self-driving autonomous technology can dramatically reduce collision rates resulting from distracted driving. Automakers and autonomous vehicle (AV) manufacturers use real world data to train, test, and validate roadway driver safety monitoring systems.
While a handful of companies may be able to afford the process of producing and testing millions of vehicles in various geographical environments, most OEMs do not have sufficient resources or vehicles with the capability to provide such datasets.
Synthetic data combines techniques from the movie and gaming industries (simulation, CGI) with generative deep neural networks (GANs, VAEs), allowing car manufacturers to engineer realistic datasets and simulated environments at scale without driving in the real world.

Source: Synthetic data can help power AI applications at a fraction of the time and cost
Healthcare
Sharing data safely is one of the biggest challenges in the healthcare industry today. Synthetic data, or data that is artificially manufactured rather than generated by real-world events, is a promising technology for helping healthcare organizations to share knowledge while protecting individual privacy.
Researchers at Gretel.ai and Illumina built state of an art framework to generate high-quality synthetic datasets for genomics using Artificial Intelligence. The synthetic datasets created based on real world data offers enhanced privacy guarantees that enable life science researchers, to quickly test ideas through open access to data without compromising patient privacy.
Do check out their in-depth research work on genomic data generation and image synthesis python notebooks for reproducing their research.
Pro tip: Explore V7 for Medical Image Annotation and 21+ Best Healthcare Datasets for Computer Vision.
Retail
Caper - a startup making intelligent shopping carts that enable customers to shop without waiting in the checkout line. Caper used synthetic images of store items that captured different angles and trained the deep learning algorithm. The company states that its shopping carts have 99% recognition accuracy.

Caper combines image recognition and a weight sensor to identify items without a barcode scan
Pro tip: Check out AI in Retail to learn more about AI applications in Computer Vision.
Robotics
Nvidia created a robotics simulation application and synthetic data generation tool Isaac Sim to develop, test, and manage Artificial intelligence-based robots working in the real world, e.g., in manufacturing plants.
Nvidia Issac Sim Workflow
Improving performance for challenging AI-based computer vision applications requires large and diverse datasets that replicate the inherent distribution of the target domain. There are many other scenarios where you can apply this process and use synthetic data to increase the robot’s understanding of its environment and how it should behave.
Pro tip: Need more quality data? See 20+ Open Source Computer Vision Datasets.
Synthetic data challenges
Researchers believe that synthetic data is essential for the further development of deep learning and will play an increasingly important role in the future. According to a Gartner report, by 2030, synthetic data will completely overtake real data in the AI model development process.
However, the report also highlights there are challenges to synthetic data adoption:
Lack of outliers: It can be hard to program rare events in the data distribution.
Variable data quality: Depends on the input data and requires tight quality control to avoid faulty samples.
Synthetic data replicates specific statistical properties of the source data. So it can miss some random behavior of real-world data.
Popular synthetic datasets
Here are a couple of widely used high-quality synthetic datasets.
SVIRO Dataset
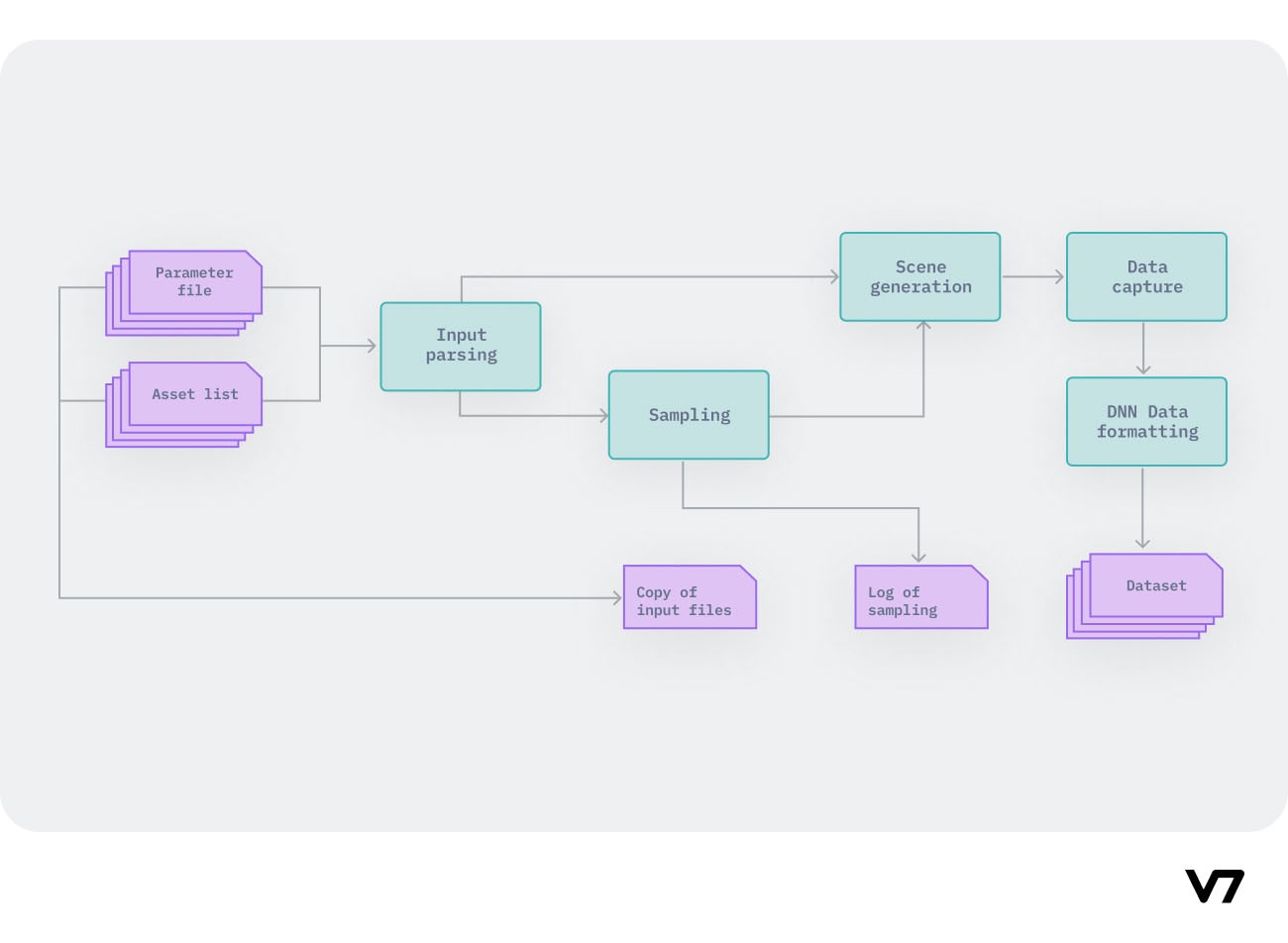
SVIRO is a Synthetic dataset for Vehicle Interior Rear seat Occupancy detection and classification. The dataset consists of 25.000 sceneries across ten different vehicles and we provide several simulated sensor inputs and ground truth data.
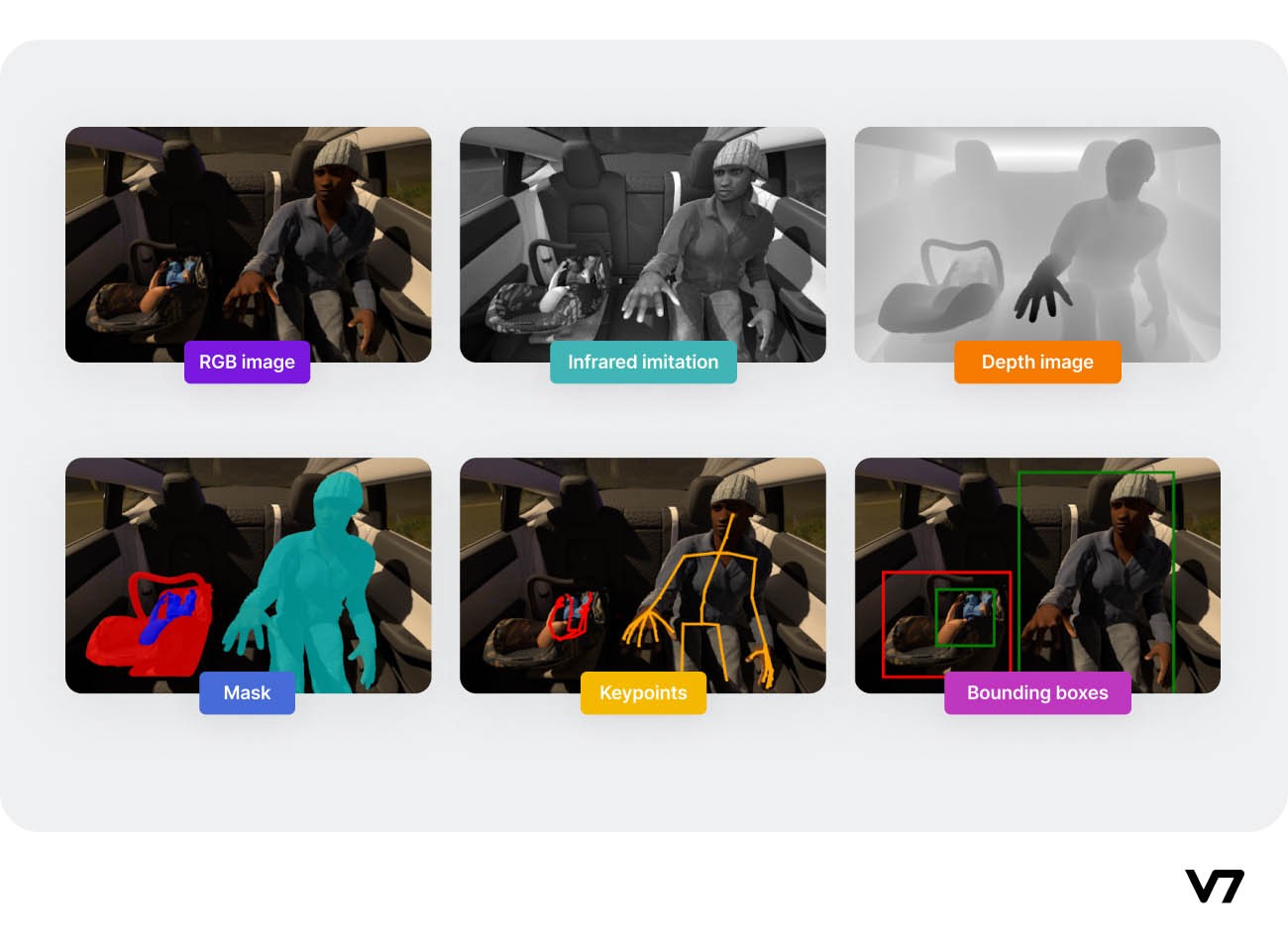
SVIRO Data sample labels
SIDOD: A Synthetic Image Dataset for 3D Object Pose Recognition with Distractors
An image dataset generated by the NVIDIA Deep Learning Data Synthesizer intended for use in object detection, pose estimation, and tracking applications.
This dataset contains 144k stereo image pairs generated from 18 camera viewpoints of three photorealistic virtual environments with up to 10 objects (chosen randomly from the 21 object models of the YCB dataset) and flying distractors.

Synthetic data samples from the SIDOD dataset
Pro tip: Read YOLO: Real-Time Object Detection Explained.
5 synthetic data generators
Want to generate synthetic data to train your computer vision models?
Have a look at this cherry-picked list of the best synthetic data generation tools:
1. Chooch AI
The Chooch AI platform can automatically generate synthetic images and corresponding bounding box annotations using the OBJ 3D geometry files and the associated.MTL texture file in a matter of seconds.
2. Datagen
The Datagen solution is a fully customizable sandbox for exposing systems to dynamic environments of 3D spaces, people, and objects.
3. Parallel Domain
Parallel Domain's synthetic data platform provides utilities to generate high-quality data. They specialize in synthetic data generation for ADAS systems.
4. Neurolabs
Neurolabs is a vendor of a synthetic data generation platform for Computer Vision. They specialize in retail SKU data.
5. Synthesis AI
Synthesis AI is a vendor of a synthetic data generation platform for computer vision.
Synthetic data in Machine Learning: Key Takeaways
Here’s a recap of everything we’ve covered:
Data acquisition and data annotation for building highly accurate ML agents is a time-consuming and expensive task. Hence, synthetic data generation provides a viable option to mitigate these issues.
Synthetic data has enormous potential to mimic natural data distribution and complement real datasets compared to augmented data.
GANs, VAE, and 3D rendering models are programmable techniques that can be used to generate synthetic data without much human intervention.
Synthetic data has applications in many fields such as autonomous driving, healthcare, retail, and more.
Popular synthetic datasets are available for public use. Moreover, synthetic data generators as a Paas(Platform as a Service) have made synthetic data generation more convenient.
Read next:
Optical Character Recognition: What is It and How Does it Work [Guide]
An Introductory Guide to Quality Training Data for Machine Learning
The Beginner's Guide to Deep Reinforcement Learning
The Ultimate Guide to Semi-Supervised Learning
9 Reinforcement Learning Real-Life Applications
Mean Average Precision (mAP) Explained: Everything You Need to Know
The Beginner’s Guide to Contrastive Learning
Data Cleaning Checklist: How to Prepare Your Machine Learning Data
The Complete Guide to Ensemble Learning
13 Best Image Annotation Tools

Deval is a senior software engineer at Eagle Eye Networks and a computer vision enthusiast. He writes about complex topics related to machine learning and deep learning.

