Data labeling
5 Alternatives to Scale AI [Reviewed 2024]
6 min read
—

Picking the right tool for your training data annotation is not an easy task—that's why knowing all available options is crucial for making the right decision. Take a look at our shortlist of the best Scale AI alternatives.

Tomas Laurinavicius
Guest Author

Machine Learning and Deep Learning projects are in the mainstream.
Yet—
Despite an overwhelmingly high commitment, only a few companies managed to productize their models.
Per Gartner, over 85% of AI projects are at risk of delivering poor results due to bias in data, algorithms, or the teams behind them.
Data quality, in particular, is a weak point in ML/DL since the projects’ success strongly depends on the volumes of high-quality labeled data the team can regularly produce.
Scale AI was among the first to jump on the opportunity to improve and automate data management, annotation, and integration.

Data labeling
Data labeling platform
Get started today
Scale AI Alternatives
Founded four years ago by Alexandr Wang, Scale rapidly rose in the ranks of data labeling services for the lack of good alternatives.
Currently valued at $3.5 billion, Scale is among the first on-demand platforms to offer data augmentation services, delivered as a combination of human labor and intelligent automation (powered by machine learning and statistical checks).
With clients such as Pinterest, Lyft, and SAP among others, Scale is a sound choice for processing tons of training data.
The wrinkle?
It’s also an expensive solution with a minimum contract starting at a steep $50,000.
But it’s not just pricing that prompts data science teams to look for Scale AI alternatives.
The platform delivers highly accurate data labeling services but provides limited capabilities for data management and collaboration.
Scale AI is also more eschewed towards data processing for autonomous driving. And can deliver weaker results for other use cases such as—NLP, medical image processing, and facial recognition to name a few.
For the reasons above, you may want to consider one of the following alternatives to Scale AI.
V7
V7 too is an AI data labeling platform with three core offerings:

V7 Platform Screenshot
Dataset management functionality—a UX-friendly repository for organizing, managing, and collaborating on data prep tasks. You can store images and videos in different formats (including the rare types such as SVS, DICOM), track annotation progress, analyze your data set composition(s) and rebalance them, and keep tabs on all data sets versions for model via integrated version control.
AI-driven data labeling and annotation—V7 offers self-service data labeling services, powered by an Auto-Annotate tool and augmented by human review operations. First, you can parse your data with an entirely neural-network-based segmentation labeling tool (that needs no prior setup or training).
Then dispatch all the data for human verification and receive detailed stats on the speed and performance of different annotators. To boost data quality even further, you can leave comments and notes for the annotators in real-time.
Here’s a quick video, showcasing how V7 model-based labeling works:
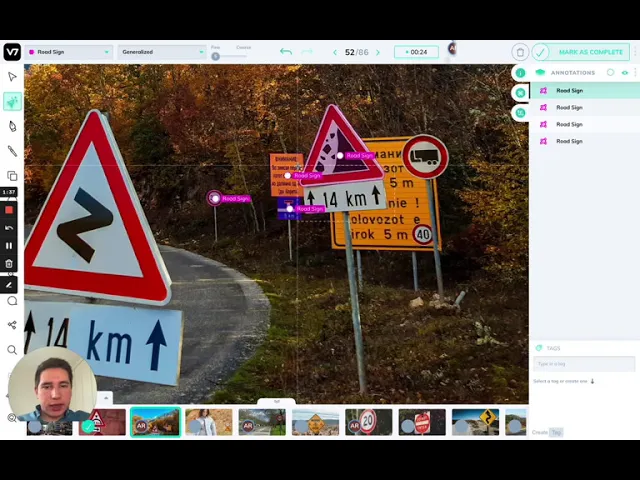
MLOps platform — on top, V7 also offers supporting infrastructure for hosting and running your experiments. You can use V7's GPU orchestration to auto-configure resources provisioning and scaling for training new models.
Then, you can leverage premade training pipelines to improve the training outcomes.
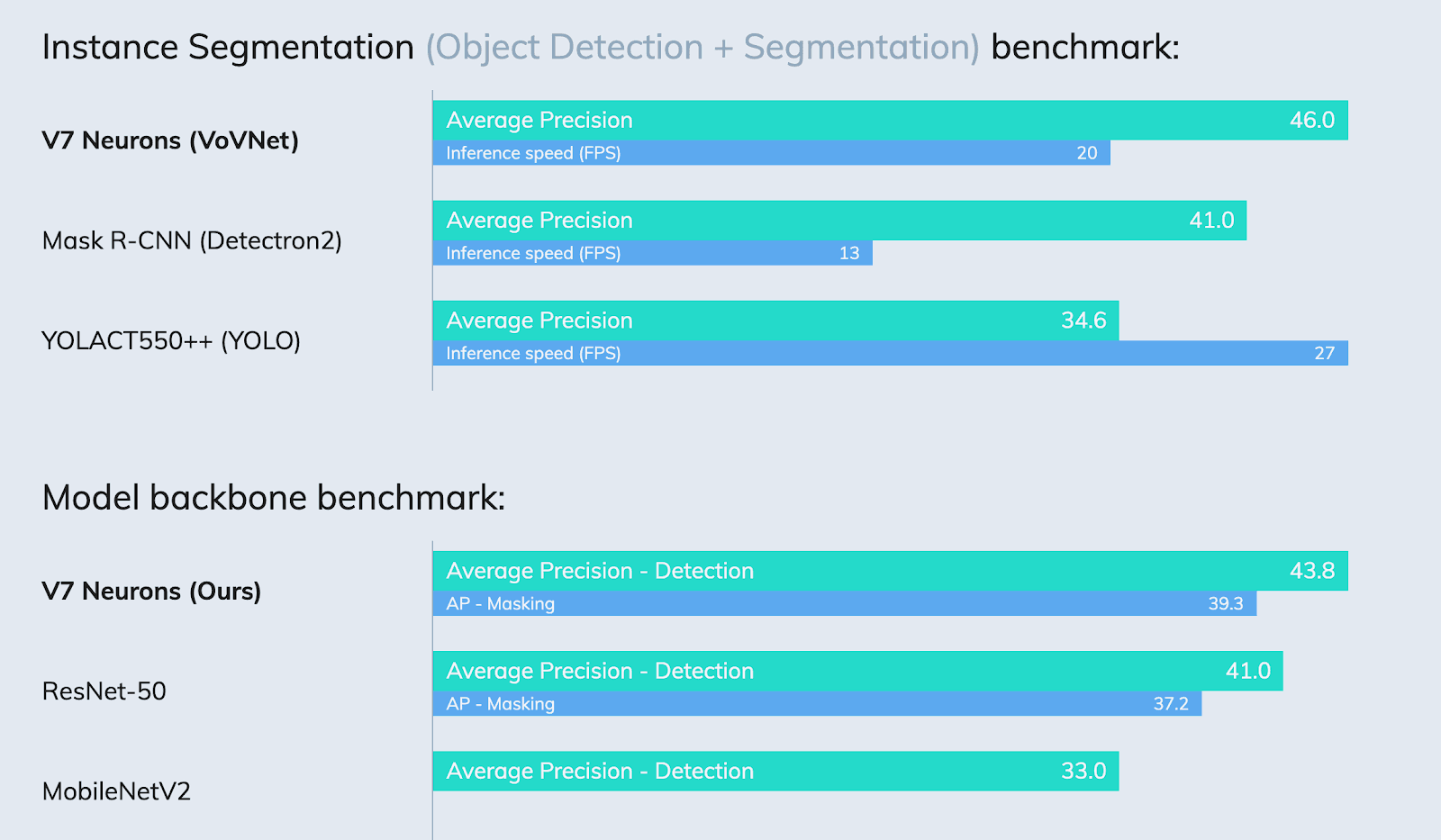
(V7 pre-trained pipelines drive the best results on the market)
Arrived at a good result?
V7 also provides functionality for packaging and deploying new models as REST APIs.
V7 pricing starts at just $150/mo for an unlimited number of users, making V7 data labeling services significantly cheaper than Scale AI.
SuperAnnotate
SuperAnnotate offers end-to-end data management services for computer vision teams.
The platform features an attractive toolkit for labeling data and building simple automation for data management pipelines.
SuperAnnotate specializes in semantic segmentation for still images and videos, powered by superpixels—an image segmentation approach that partitions the full visual into multiple segments. Then every superpixel is assigned with a label for faster, more accurate annotation.
This way, you can automate some of the common tasks such as object detection, emotion recognition, OCR recognition, and human pose estimation among others.
Alternatively, you can also recruit extra human workforce via the integrated marketplace to speed up data prep for a bigger project.
Yet, SuperAnonation doesn’t provide dataset management functionality. But they offer point-and-click automation for setting up new model training and re-training jobs.
Pricing is pretty affordable too, starting at $62/mo per user with a free 14-day trial available.
Labelbox
Labelbox provides data labeling services for enterprise-sized computer vision and NLP projects.
The platform offers a straightforward, modular setup that can be easily customized to meet your pre-existing workflows.
You can use GraphQL and Python APIs to add data to Labelbox and then automate data ingestions to your training dataset environment.
Labelbox supports several scenarios for labeling data:
Simultaneous labeling, done by both internal and external teams, using their editors.
Labeling, performed by an integrated managed data labeling workforce.
Model-assisted labeling—leverage Labelbox Prediction API, training on past predictions, to facilitate labeling of the new batch.
Another neat tool is API-driven labeling queue prioritization—a tool for auto-prioritizing the most important data for labeling first.
By combining the above features, enterprises can greatly streamline the speed and accuracy of data annotation, plus compare the performance of different annotators with integrated analytics and histograms.
While Labelbox data labeling capabilities are stellar, they are somewhat lacking dataset management features. Users have basic storage and organization features for labeling datasets, but no version control or advanced search features.
Labelbox offers a free plan for test-driving the platform (image and video data labeling only) and has on-demand pricing for Pro and Enterprise users.
Managed data labeling services start at $6/labeling hour.
Dataloop
On top of data labeling, Dataloop also provides a good range of supporting tools for controlling data workflows and creating (semi-) automated deployment pipelines for new models. So that your ML team could iterate on the models faster and reduce deployment risks.
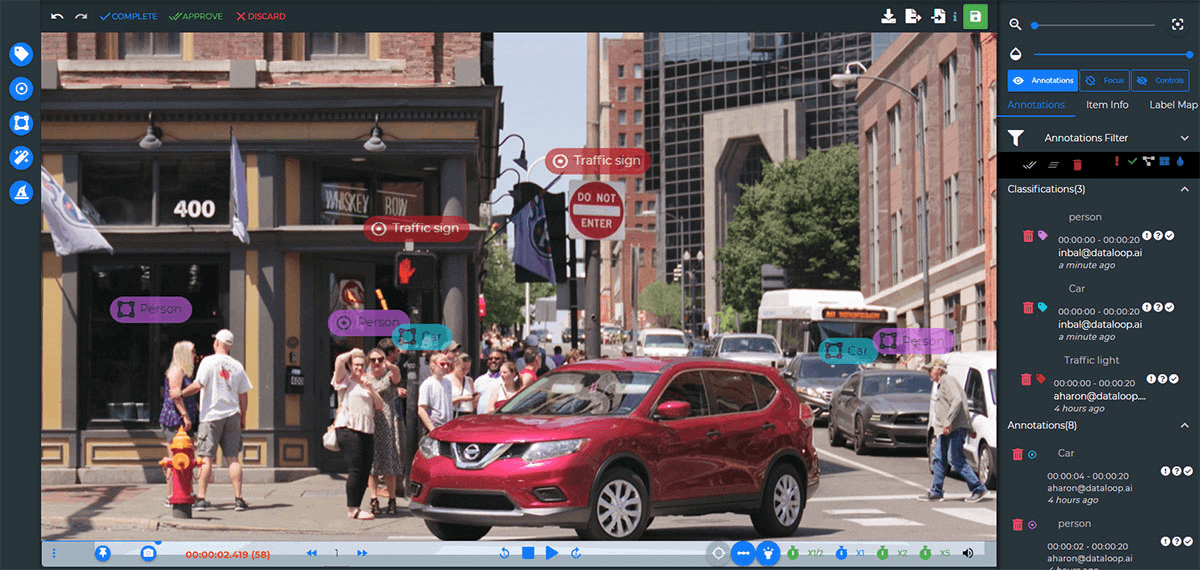
In terms of data labeling, Dataloop supports image and video annotations. The platform provides automation annotation tools too such as:
AI assistant that auto-converts 4 single points into multi-vertices polygons
Model-assisted labeling capabilities (similar to Labelbox)
Smart object tracking—auto-duplicate annotations between video frames and sequenced images.
To speed up data labeling even further, you can also hire extra people from Dataloop’s fully-managed workforce network.
Overall, their data labeling toolkit is robust. But we found that Dataloop doesn't provide interpolation outside of bounding boxes for videos.
Dataloop pricing is on-demand only.
CVAT
Are you budget-conscious?
Then consider the Computer Vision Annotation Tool (CVAT)—an open-source data labeling tool, developed by Intel.

Somewhat spartan, CVAT nonetheless does a great job with image and video annotations in particular. It supports bounding box interpolation and has polygon interpolation in the video too. But its performance is lower than V7's. CVAT also provides basic automatic annotation tools such as setting interpolation between keyframes.
Despite its robustness, CVAT is better suited for small teams or individuals since it has no labeling workforce management tools, performance tracking analytics, or collaborative workspaces.
CVAT is free but self-hosted. Respectively, your AWS bill (unless kept under a tight lid) can cost more than a monthly subscription with another data labeling platform.
TL;DR: Best Alternatives to Scale AI
Best for all computer vision teams and early MLOps adopters: V7.
Best for BPO companies and teams working with satellite imagery: SuperAnnotate.
Best for enterprises who need flexible, rapid access to managed data labeling services: Labelbox.
Best for BPO provides and machine learning teams, focused on image recognition tasks: Dataloop.
Best for academics, ML enthusiasts, and small teams who want to host a solution locally, but don't expect to scale: CVAT















