8 min read
—

From handwritten content to printed text and image-only digital documents—learn how to use Optical Character Recognition to convert any kind of image containing written text into machine-readable text data.

With the growing presence of digital media in the 21st century, there has been an inherent boost in the requirement of digitized documents.
Digitally stored documents have tremendous advantages over their “real world” counterparts, specifically regarding the physical space they occupy and the security that comes with their use.
As a result, Document Analysis with AI for digitizing documents forms an integral part of computer vision and has become a rapidly developing field of research.
Optical character recognition, or OCR, is a key element of document digitization.
Here’s what we’ll cover:
What is Optical Character Recognition?
How does Optical Character Recognition work?
OCR tutorial using V7
Optical Character Recognition applications
Benefits of Optical Character Recognition for businesses
Let’s start with some basics.

AI for document processing
Go beyond OCR and extract structured financial data
Get started today
What is Optical Character Recognition?
Optical Character Recognition (OCR) is the process of detecting and reading text in images through computer vision.
Detection of text from document images enables Natural Language Processing algorithms to decipher the text and make sense of what the document conveys.
Furthermore, the text can be easily translated into multiple languages, making it easily interpretable to anyone.
OCR, however, is not limited to the detection of text from document images only.
Novel OCR algorithms make use of Computer Vision and NLP to recognize text from supermarket product names, traffic signs, and even from billboards, making them an effective translator and interpreter.
OCR used in the wild is often termed as scene text recognition, while the term “OCR” is generally reserved for document images only.
Moving forward, we will explore both document text extraction and scene text recognition under the banner of OCR.
How does Optical Character Recognition work?
Optical Character Recognition algorithms can be based on traditional image processing and machine learning-based approaches or deep learning-based methods.
Traditional OCR
While traditional machine learning-based approaches are fast to develop, they take significantly more time to run and are easily outstripped by deep learning algorithms both in accuracy and inference speed.
Traditional Approaches to OCR go through a series of pre-processing steps where the inspected document is cleaned and made noise-free. Following this, the document is binarized for subsequent contour detection to aid in the detection of lines and columns.
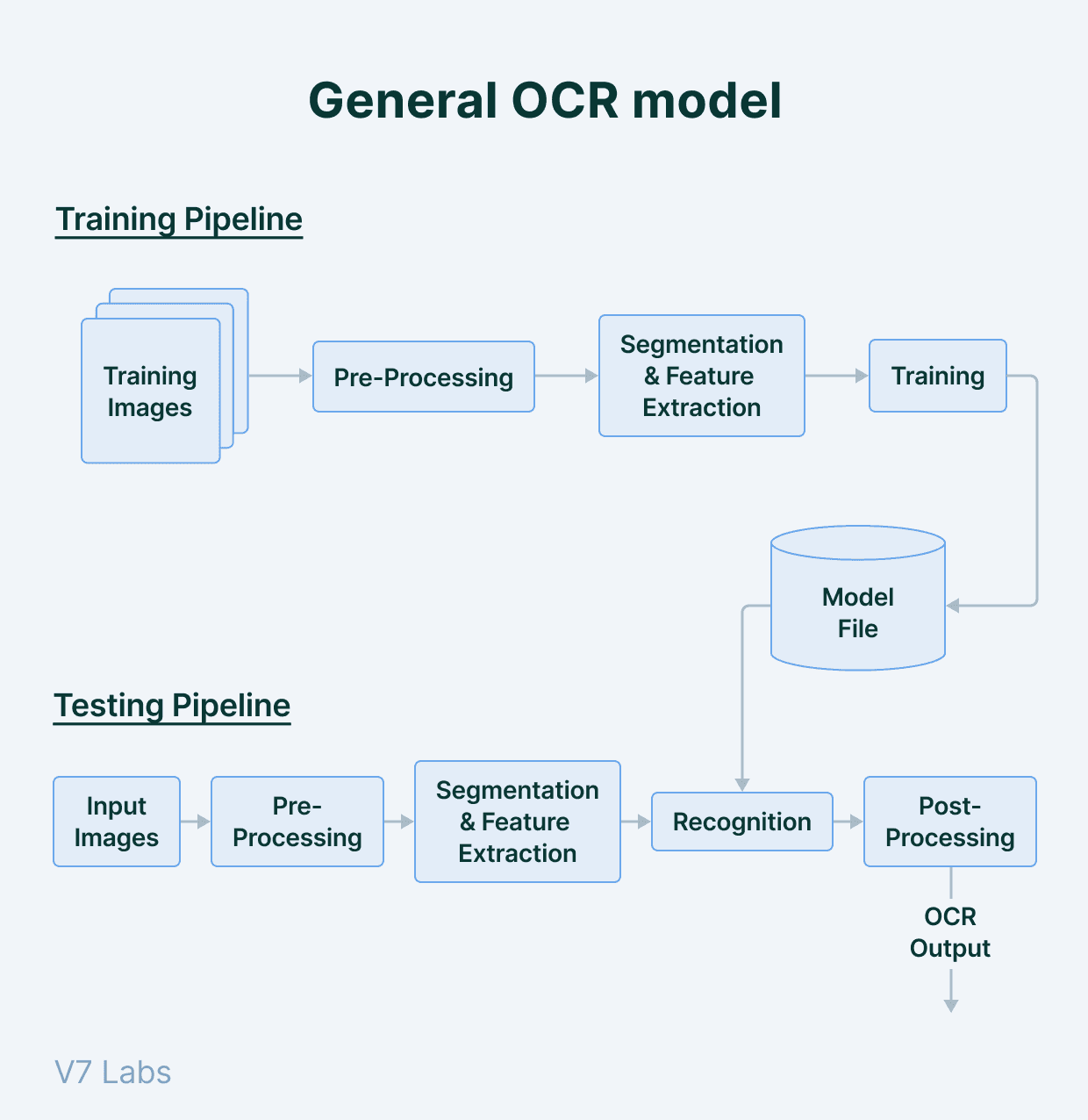
Finally, characters building the lines are extracted, segmented, and identified via various machine learning algorithms like K-nearest neighbors and support vector machines.
While these work great on simple OCR datasets like easily distinguishable printed data and handwritten MNIST data, they miss out on many features, making them fail when working on complex datasets.
Pro tip: Looking for the perfect OCR dataset? Check out 65+ Best Free Datasets for Machine Learning.
OCR with Deep Learning
Deep learning-based methods can efficiently extract a large number of features, making them superior to their machine learning counterparts.
Algorithms that combine Vision and NLP-based approaches have been particularly successful in providing superior results for text recognition and detection in the wild.
Furthermore, these methods provide an end-to-end detection pipeline that frees them from long-drawn pre-processing steps.
Generally, OCR methods include vision-based approaches used to extract textual regions and predict bounding box coordinates for the same.
The bounding box data and image features are then passed onto Language Processing algorithms that use RNNs, LSTMs, and Transformers to decode the feature-based information into textual data.
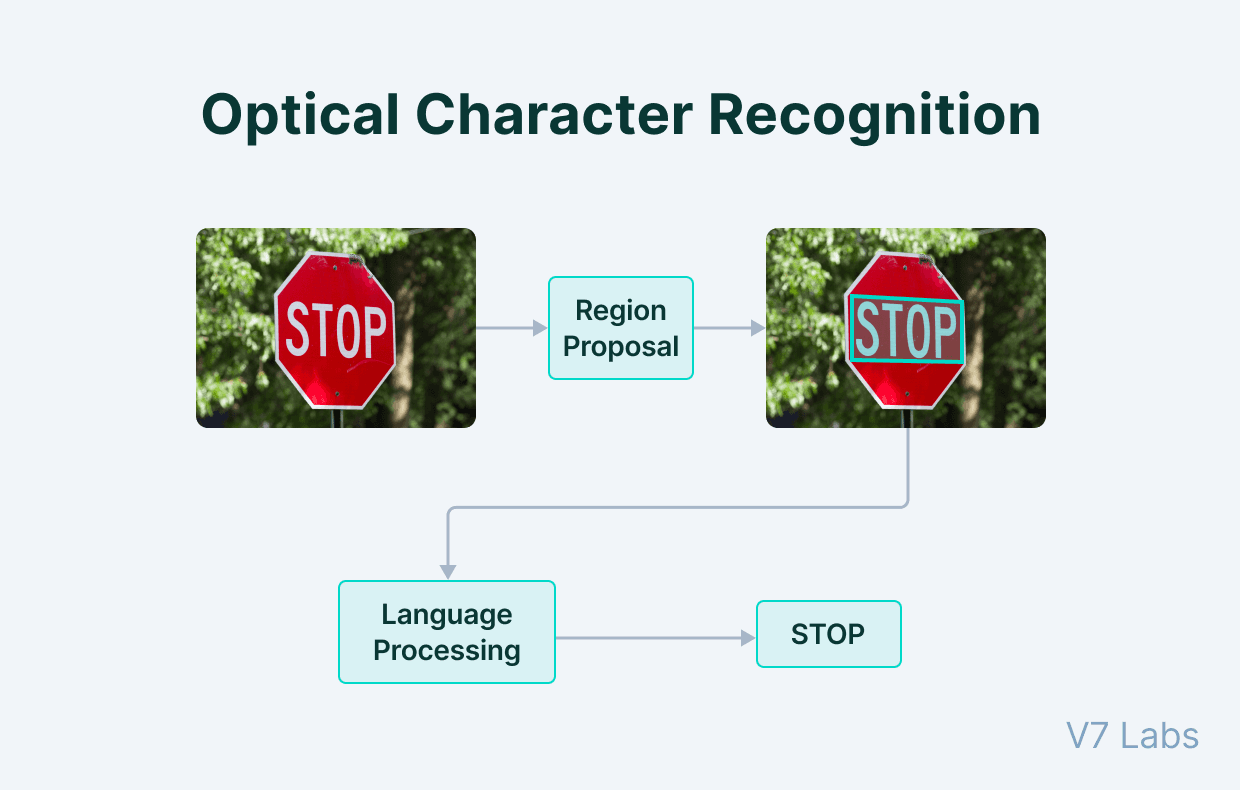
Deep learning-based OCR algorithms have two stages—the region proposal stage and the language processing stage.
Region Proposal: The first stage for OCR involves the detection of textual regions from the image. This is achieved by using convolutional models that detect segments of text and enclose them in bounding boxes.
The task of the network here is similar to the Region Proposal Network in object detection algorithms like Fast-RCNN, where possible regions of interest are marked and extracted. These regions are used as attention maps and fed to language processing algorithms along with features extracted from the image.
Language Processing: NLP-based networks like RNNs and Transformers work to extract information captured in these regions and construct meaningful sentences based on features fed from the CNN layers.
Fully CNN-based algorithms that recognize characters directly without going through this step have been successfully explored in recent works and are especially useful to detect text that has limited temporal information to convey, like signboards or vehicle registration plates.
What makes OCR work well?
Modern OCR methods make use of text detection algorithms as a starting point.
State-of-the-art neural networks have become exceptionally good at spotting text in documents and images, even if it is slanted, rotated, or skewed.
Increasing OCR accuracy is possible when you follow these two practices:
Denoise Input data: Data fed to the model should be properly denoised to prevent non-textual regions from being proposed as text. Denoising can be done in several ways, with Gaussian blurring being the most popular. Additive white noise can also be removed with the help of an auxiliary autoencoder network.
Improve Image contrast: Image contrast plays a great role in helping the neural network discern textual regions from non-textual ones. Increasing contrast differences between text and background helps the OCR model perform much better.
Scanning Text with V7
Finally, let’s go over a simple tutorial on how you can perform OCR using V7 Text Scanner.
Sample Text Scanner
We've added a public Text Scanner model to our Neural Networks page to help you detect and read text in your images automatically.
And here are step-by-step instructions for setting up your own text scanner.
Getting started
Before we can start effortlessly pulling text from images and documents, we'll need to get three quick setup steps out of the way:
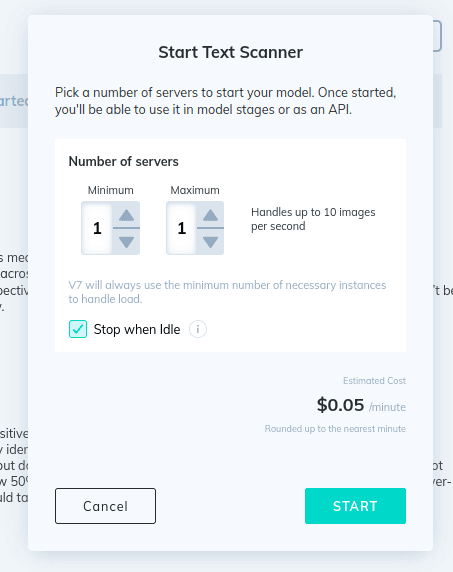
1. Turn on the public Text Scanner model in the Neural Networks page.
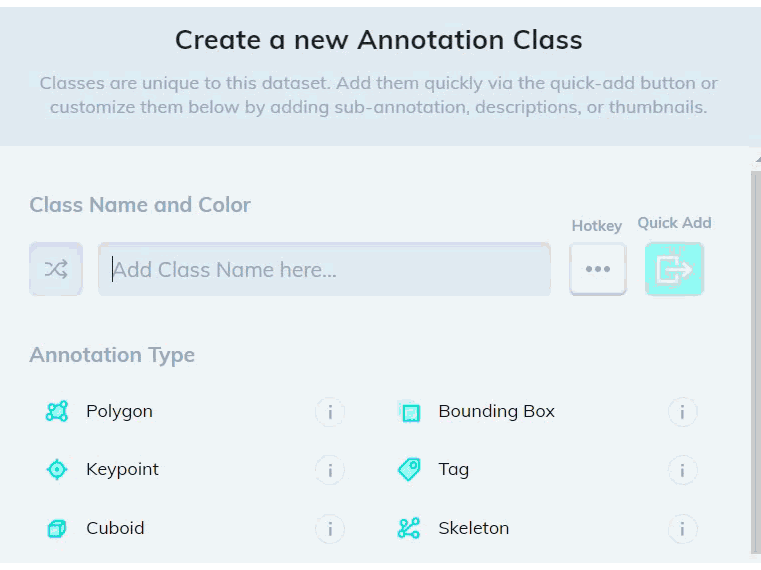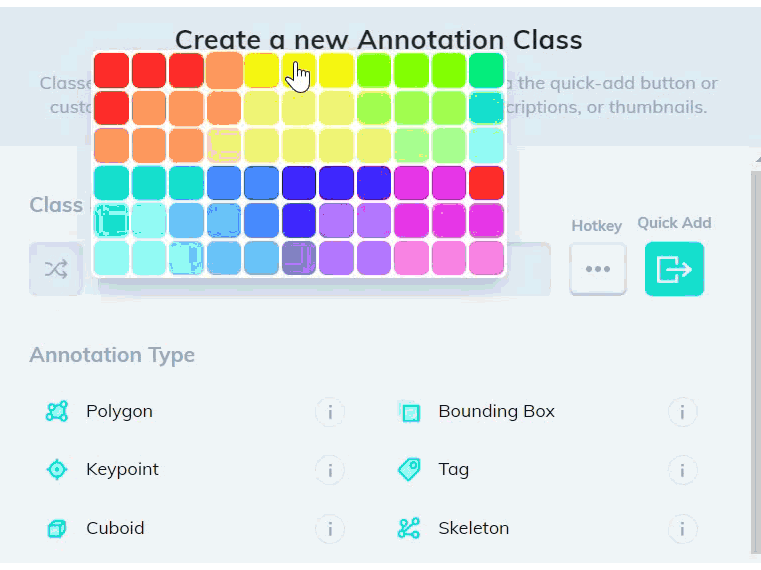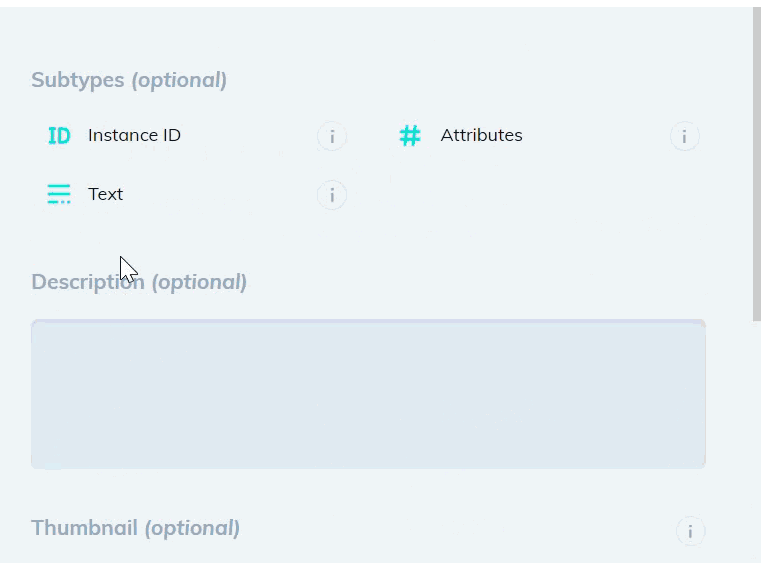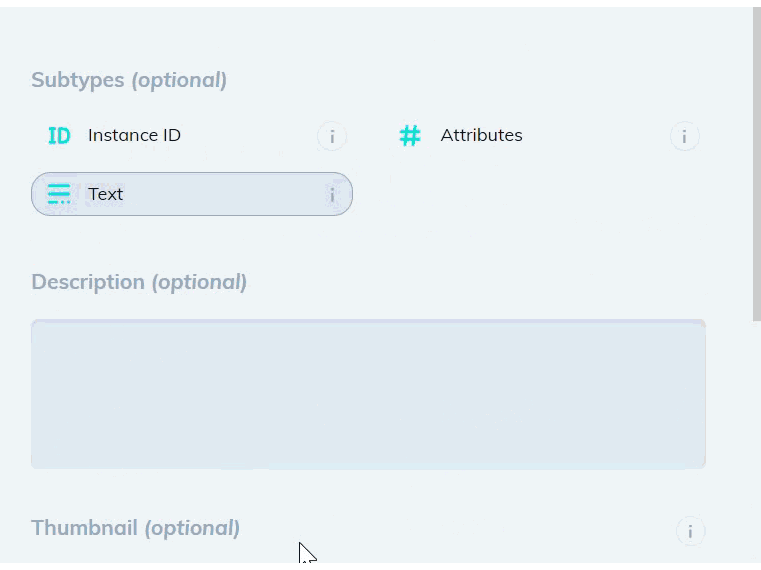
2. Create a new bounding box class that contains the Text subtype in the Classes page of your dataset. You can optionally add an Attributes subtype to distinguish between different types of text.
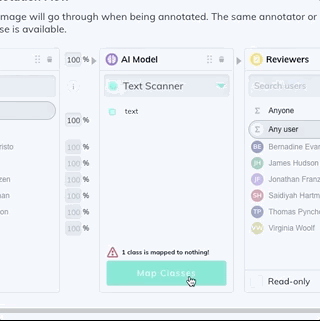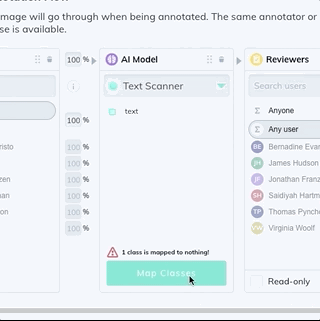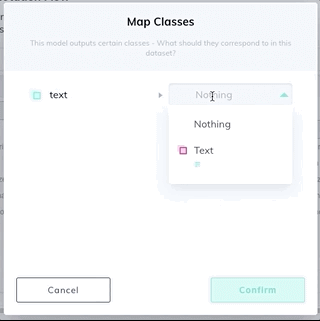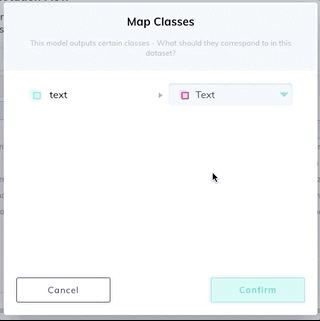
3. Add a model stage to your workflow under the Settings page of your dataset. Select Text Scanner model from the dropdown list, and map your new text class. If the model stage is the first stage in your workflow, select Auto-Start to send all new images through the model automatically.
Text scanner works on all text, including text that is:
Rotated
Diagonally slanted
Curved
Extremely low resolution (it will try and guess if the letters don’t have enough pixels)
In any language
It also works on the following alphabets:
Latin
Cyrillic
Chinese simplified (Mandarin)
Japanese
Once the model has started, upload images for the model to scan and identify.
Here are a few examples of scanned and annotated text.













Optical Character Recognition Applications
OCR has found applications across many industries, including banking, legal, and healthcare.
Here are a few examples of Optical Character Recognition use cases.
Document identification: Document identification forms an important use case of OCR, with the detected text being used to classify documents into groups, making access infinitely easier and faster.
Data entry automation: With OCR, data can be efficiently captured from documents and tables, making manual data entry redundant. Automation of data entry with OCR reduces anomalies in the data due to typing issues. Furthermore, the extraction of data becomes super fast and extremely cheap.
Archives and digital libraries creation: OCR helps create digital libraries by recognizing classes into which a book or a document belongs. These classes (or genres) can be used to look up a particular category of books, helping the reader seamlessly navigate through the list. Correspondingly, OCR helps in digitizing old documents, thereby making preservation extremely easy and secure.
Text translation: Text translation forms an important part of OCR, particularly for scene text recognition and evaluation. Translation modules stacked onto the output from an OCR system can help international tourists understand documents and billboards in different languages.
Sheet music recognition: Text detection systems can be trained to detect sheet music from notations, enabling a machine to play music directly from textual information. This allows machines to provide lessons to budding musicians and can also be used for ear training exercises.
Marketing campaigns: OCR systems have been used successfully in marketing campaigns by FMCGs by attaching a scannable text section on their products. When scanned by a mobile camera or capturing device, this text section can be converted to a textual code to redeem promo codes.
Pro tip: Learn more on the practical uses of OCR technology in our guide to handwriting recognition
Benefits of Optical Character Recognition for businesses
It’s no doubt that we will see more and more businesses taking advantage of the OCR in the years to come.
Here are some of the benefits of this technology for businesses.
Elimination of manual data entry
OCR eliminates manual data entry by enabling the identification of data directly from document images. As a result, it reduces data entry time and scales down errors in the data processing.
Better accessibility and searchability
OCR scanned documents can be indexed easily, making them searchable amongst a plethora of other documents. They can be indexed by their content, titles, or even by specific keywords, making them readily accessible as compared to their physical or photographic counterparts.
More storage space
OCR helps in digitizing documents, thereby boosting storage space. Documents do not have to be stored in a physical or image form —they can be stored in text form, which is much smaller.
Optical Character Recognition: Key Takeaways
Optical character recognition today plays a key role in the digital transformation process for many businesses, helping them store their data securely and retrieve information more easily.
Marketing agencies further use OCR algorithms to increase customer engagement and boost sales providing a seamless buyer experience.
Apart from benefiting businesses, OCR helps the environment by reducing repeated hard copies of important documents, thus saving paper.
Last but not least, OCR helps translate written text to a plethora of languages, which increases the accessibility to documents and helps bridge the language gap.
Read more:
Image Classification Explained: An Introduction
The Beginner’s Guide to Semantic Segmentation
The Beginner's Guide to Deep Reinforcement Learning
9 Essential Features for a Bounding Box Annotation Tool
The Ultimate Guide to Semi-Supervised Learning
Optical Character Recognition: What is It and How Does it Work [Guide]

Hmrishav Bandyopadhyay studies Electronics and Telecommunication Engineering at Jadavpur University. He previously worked as a researcher at the University of California, Irvine, and Carnegie Mellon Univeristy. His deep learning research revolves around unsupervised image de-warping and segmentation.

