Computer vision
The Complete Guide to Object Tracking [+V7 Tutorial]
19 min read
—
Nov 16, 2021

What is object tracking and how does it differ from object detection? Learn about the most popular object tracking algorithms and their applications in real-world scenarios.

Nilesh Barla
Guest Author and Founder
Object tracking is one of the most important tasks in computer vision.
It has a multitude of real-life applications, including use cases such as traffic monitoring, robotics, medical imaging, autonomous vehicle tracking, and more.
So much more...
In this article, we'll cover everything you need to know about object tracking. You are also invited to check out our bonus V7 tutorial on building your own object tracking models from scratch.
Here’s what we’ll cover:
What is Object Tracking?
Object Tracking vs. Object Detection
4 stages of the Object Tracking process
Levels of Object Tracking
Object Tracking challenges
Deep Learning-based approaches to Object Tracking
Visual Object Tracking with V7 (Tutorial)

And in case you’d like to jump right into the deep end of the pool and start building your own AI models, check out:
What is Object Tracking?
Object tracking is a deep learning process where the algorithm tracks the movement of an object. In other words, it is the task of estimating or predicting the positions and other relevant information of moving objects in a video.
Object tracking usually involves the process of object detection. Here’s a quick overview of the steps:
Object detection, where the algorithm classifies and detects the object by creating a bounding box around it.
Assigning unique identification for each object (ID).
Tracking the detected object as it moves through frames while storing the relevant information.
Have a look at this video to see how V7 handles object tracking.
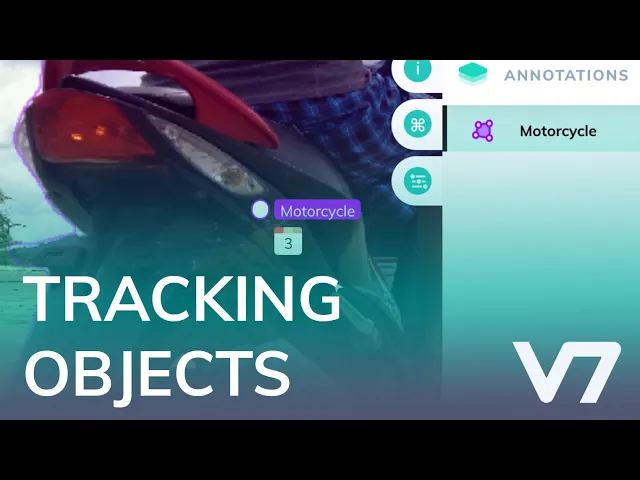
Object Tracking vs. Object detection
Object tracking refers to the ability to estimate or predict the position of a target object in each consecutive frame in a video once the initial position of the target object is defined.
On the other hand, object detection is the process of detecting a target object in an image or a single frame of the video. Object detection will only work if the target image is visible on the given input. If the target object is hidden by any interference it will not be able to detect it.
Object tracking is trained to track the trajectory of the object despite the occlusions.
Pro tip: Read YOLO: Real-Time Object Detection Explained.
Types of Object Tracking
There are two types of object tracking: image tracking and video tracking.
Image tracking
Image tracking is the task of automatically recognizing and tracking the images.
It is mostly applied in the field of augmented reality (AR). For instance, when given a two-dimensional image as an input through a camera, the algorithm detects two-dimensional planar images, which can be then used to superimpose a 3D graphical object.
Once the 3D graphic is superimposed, the user can move the camera without actually losing track of the 2D planar surface and graphic on top of it.
Companies like Apple and Ikea use such technologies to give the customers a virtual experience of how their products will look in their personal settings.

Video tracking
Video tracking is the task of tracking a moving object in a video.
The idea of video tracking is to associate or establish a relationship between target objects as it appears in each video frame. In other words, video tracking is analyzing the video frames sequentially and stitching the past location of the object with the present location by predicting and creating a bounding box around it.
Video tracking is widely used in traffic monitoring, self-driving cars, and security because it can process real-time footage.
4 stages of the Object Tracking process
Now, let’s discuss the object tracking process in more detail.
Target initialization
The first step involves defining the object of interest or targets.
It incorporates the process of drawing a bounding box around it in the initial frame of the video. The tracker must then estimate or predict the object’s position in the remaining frames while simultaneously drawing the bounding box simultaneously.
Pro tip: Looking for the perfect bounding box tool? Check out 9 Essential Features for a Bounding Box Annotation Tool.
Appearance modeling
Appearance modeling deals with modeling the visual appearance of the object. When the targeted object passes through various scenes like the lighting condition, angle, speed, etc., they may change the appearance of the object, and it may lead to misinformation and the algorithm losing track of the object.
Appearance modeling has to be conducted so that modeling algorithms can capture various changes and distortions introduced when the target object moves.

Appearance modeling consists of two components:
Visual representation: it focuses on constructing robust features and representation that can describe the object
Statistical modeling: it uses statistical learning techniques to build mathematical models for object identification effectively.
Motion estimation
Motion estimation usually infers the predictive capability of the model to predict the object’s future position accurately.
Target positioning
Motion estimation approximates the possible region where the object could most likely be present. Once the location of the object is approximated, we can then use a visual model to lock down the exact location of the target.
Levels of Object Tracking
Object tracking can be defined by two levels:
Single Object Tracking(SOT)
Multiple Object Tracking(MOT): it aims to track objects of multiple classes as we see in self-driving cars.
Single Object Tracking
Single Object Tracking (SOT) aims to track an object of a single class instead of multiple objects. It is also sometimes referred to as Visual Object Tracking.
In SOT, the bounding box of the target object is defined in the first frame. The goal of the algorithm is then to locate the same object in the rest of the frames.
SOT belongs to the category of detection-free tracking because one has to manually provide the first bounding box to the tracker. This means that Single Object Trackers should be able to track whatever object they are given, even an object on which no available classification model was trained.
Pro tip: Learn more by reading Image Classification Explained: An Introduction.
Multiple Object Tracking
Multiple Object Tracking (MOT) refers to the approach where the tracking algorithm tracks every single object of interest in the video.
Initially, the tracking algorithm determines the number of objects in each frame, following that it keeps track of each object’s identity from one frame to the next frame until they leave the frame.
Object tracking challenges (and solutions)
There are several challenges that one might face while working on object tracking algorithms.
Firstly, it is easy to track an object on a straight road or in a simple environment.
We have already discussed how important it is to accurately model the target object. In a real-world scenario, the target object will go through deformation, occlusion, background noise, etc.
Let's explore some of the common issues that arise in object tracking.
Occlusion
The occlusion of objects in videos is one of the most common challenges.
It refers to an interference phenomenon where the object is affected by the background or foreground in which the tracking algorithm loses track of the object. In other words, the algorithm gets confused as multiple objects come closer. This leads to the issue where the initially identified object is again (mistakenly) tracked as a new object.
One can implement occlusion sensitivity to prevent it. Occlusion sensitivity allows the user to identify which particular feature of the object is confusing the network. Once identified, similar images can be used to correct the biases and help the network to extract features that differentiate the objects.
Background clutter
In any machine learning or deep learning task, the background of the images fed into the algorithm creates a lot of issues. It is the same with object tracking models.
In theory, the more densely populated the background, the more difficult it is to extract features, detect or even track the object of interest.
A densely populated background introduces redundant information or noise that makes the network less receptive to features that are important; they also make the network slow to learn and optimize.
To prevent background clutter, one can use a well-curated dataset that has a sparse background.
Pro tip: Looking for quality data? Check out 65+ Best Free Datasets for Machine Learning.
Training and Tracking Speed
The modern deep learning algorithms have become much more complex, which means they can extract features and make meaningful correlations; this, in turn, also means that they consume more energy and time.
The tracking algorithm is not a single task algorithm, as we see in image classification and object detection. It is a multitask algorithm that performs object detection, localization, classification and also keeps track of the objects. This type of algorithm is mathematically complex, and it takes a lot of time to train.
We must also keep in mind that the tracking algorithms must perform quickly during the inference time to yield accurate results. Enhancing tracking speed is especially imperative for real-time object tracking models.
To enable faster inference time, the model needs to be carefully designed or chosen. A convolutional neural network, which is the primary architecture for computer vision tasks, can be used in object tracking. These networks are capable enough to perform with great accuracy if designed carefully.
Some of the common algorithms used for tracking objects are Fast R-CNN and Faster R-CNN and their variants. These networks have been proven very efficient in the task of object tracking.
Pro tip: Learn more by reading The Essential Guide to Neural Network Architectures.
Varying spatial scales
One of the issues with object tracking is that the target objects can vary in shape and size; with such a variety of information, the learning algorithm can get confused, leading to generalization error.
Below is the list of techniques that can help to tackle the issue of varying spatial scales:
Anchor Boxes
These are the predefined measurement of the target object. The boxes are meant to acquire the scale and aspect ratios of target objects. These boxes are fed into the network during training, and it allows the network to learn and understand the position and size of the object.
Anchor boxes also allow the network to detect multiple objects if they are overlapping by separately evaluating features and yielding accurate results.

Feature extraction
Features extraction is an important process in all deep learning techniques.
It enables neural networks to understand the data fed into them. The convolutional neural network (CNN) used for object tracking and other computer vision tasks can efficiently extract spatial information.
These networks, however, must be able to extract multi-scale spatial information. At times, when the object is smaller in the given input image, the network may lose too much signal during downsampling or as the signal propagates through the network. As a result, the network will not be able to detect and track smaller objects during the inference.
To tackle such a situation, one should use or develop a network that can preserve the information extracted from each layer so that the network can detect objects within multiple CNN layers, including earlier layers where higher resolution remains.
Pro tip: Check out 12 Types of Neural Network Activation Functions: How to Choose?
Deep Learning-based approaches to Object Tracking
Object tracking has been around for almost 20 years now and a lot of methods and ideas were introduced to improve the accuracy and efficiency of the tracking models.
Some of the methods involved traditional or classical machine learning approaches like k-Nearest Neighbor or Support Vector Machine. These approaches are good in predicting the target object, but they require important and discriminatory features extracted by professionals.
On the other hand, deep learning methods extract these important features and representations by themselves.
Let’s discuss some of the deep learning algorithms that are used in the task of object tracking.
MDNet
Multi-Domain Net is a type of object tracking algorithm which leverages large-scale data for training. Its objective is to learn vast variations and spatial relationships.
MDNet is trained to learn the shared representation of targets from multiple annotated videos, meaning it takes multiple annotated videos belonging to different domains.
MDNet consists of pretraining and online visual tracking:
Pretraining: In pretraining, the network is required to learn multi-domain representation. To achieve this, the algorithm is trained on multiple annotated videos to learn representation and spatial features.
Online visual tracking: Once pre-training is done, the domain-specific layers are remove,d and the network is only left with shared layers, which consist of learned representations. During the inference, a binary classification layer is added, which is trained or fine-tuned online.
This technique saves time as well as it has proven to be an effective online-based tracking algorithm.

GOTURN
Deep Regression Networks are offline training-based models. This algorithm learns a generic relationship between object motion and appearance and can be used to track objects that do not appear in the training set.
Online tracker algorithms are slow and do not perform well in real-time; this is because they cannot take advantage of a large number of videos to improve their performance. Offline tracker algorithms, on the other hand, can be trained to handle rotations, changes in viewpoint, lighting changes, and other complex challenges.
Generic Object Tracking Using Regression Networks or GOTURN uses a regression-based approach to tracking objects. Essentially, they regress directly to locate target objects with just a single feed-forward pass through the network.
The network takes two inputs: a search region from the current frame and a target from the previous frame. The network then compares these images to find the target object in the current image.

ROLO—Recurrent YOLO
ROLO is a combination of recurrent neural networks and YOLO. Generally, LSTM is preferred in combination with CNN.
ROLO combines two types of neural networks: one is CNN which is used to extract spatial information while the other is an LSTM network which is used for finding the trajectory of the target object.
At each time step, spatial information is extracted and sent to the LSTM, which then returns the location of the tracked object.

We can use the above diagram to understand how ROLO works:
The video sequence is fed into the YOLO architecture which is primarily made of CNN, here features are extracted as well as bounding boxes are detected.
The visual features and bounding boxes are then concatenated and fed to the LSTM
The LSTM then predicts the trajectory of the objects.
DeepSORT
DeepSORT is one of the most popular object tracking algorithms. It is an extension to Simple Online Real-time Tracker or SORT, which is an online-based tracking algorithm.
SORT is an algorithm that uses the Kalman filter for estimating the location of the object given the previous location of the same. The Kalman filter is very effective against the occlusions.
SORT comprises of three components:
Detection: Detecting the object of interest in the initial stage i.
Estimation: Predicting the future location i+1 of the object from the initial stage using the Kalman filter. It is worth noting that the Kalman filter just approximates the object’s new location, which needs to be optimized.
Association: As the Kalman filter estimates the future location of the object i+1, it needs to be optimized using the correct position. This is usually done by detecting the position of the object in that position i+1. The problem is solved optimally using the Hungarian algorithm.
With the basics of SORT out of the way, we can incorporate deep learning techniques to enhance the SORT algorithm. Deep neural networks allow SORT to estimate the object’s location with much higher accuracy because these networks can now describe the features of the target image.
Essentially, the CNN classifier is trained on a task-specific dataset until it achieves good accuracy. Once it is achieved, the classifier is stripped, and we are left with only the features extracted from that dataset. This extracted feature is then incorporated with the SORT algorithm to track objects.
SiamMask
SiamMask aims to improve the offline training procedure of the fully-convolutional Siamese network. Siamese networks take in two inputs: a cropped image and a larger search image to obtain a dense spatial feature representation.
The Siamese network yields one output. It measures the similarity of two input images and determines whether or not the same objects exist in the two images. This framework is very efficient for object tracking by augmenting their loss with a binary segmentation task.

SiamMask
Once trained, SiamMask solely relies on a single bounding box initialization and operates online yielding object segmentation masks.
Pro tip: Check out A Gentle Introduction to Image Segmentation for Machine Learning.
JDE (Joint Detection and Embedding)
Joint Detection and Embedding (JDE) is a single-shot detector designed to solve a multi-task learning problem. JDE learns target detection and appearance embedding in a shared model.
JDE uses Darknet-53 as the backbone to obtain feature representation at each layer. These feature representations are then fused using up-sampling and residual connections. The prediction heads are then attached on top of the fused feature representation, which yields a dense prediction map.

JDE architecture
To perform object tracking, JDE yields bounding boxes classes and appearance embedding from the prediction head. These appearance embeddings are compared to embeddings of previously detected objects using an affinity matrix.
Finally, the Hungarian algorithm and the Kalman filter are used for smoothing out the trajectories of the target object and as well as estimating the locations of the same.
Tracktor++
Tracktor++ is an online tracking algorithm. It uses an object detection method to perform tracking by training a neural network only on the task of detection.
It essentially predicts the position of an object in the next frame by calculating the bounding box regression. It doesn't perform any training or optimization on tracking data.
The object detector for Tracktor++ is usually Faster R-CNN with 101-layer ResNet and FPN. It extracts features from the current frame by using the regression branch of Faster R-CNN.
Visual Object Tracking using V7 [Tutorial]
Now, let us briefly walk you through the process of Visual Object Tracking using V7.
If you haven’t done it yet, make sure to request a 14-day free trial before reading further.
Upload data

V7 Datasets tab
Pro tip: Check out Data Cleaning Checklist: How to Prepare Your Machine Learning Data.
Auto-annotate your data
Once your video is uploaded, you can then start annotating the video. You can use V7’s auto-annotation tool to speed up the process.

In this example, we will be tracking the runner with the white shirt. This video is a perfect example of object tracking, as the object tracking camera is very constant and focused on the runner.
Pro tip: Read What is Data Labeling and How to Do It Efficiently [Tutorial].
Select the desired frame in the video to start annotating. You can use the timeline bar at the bottom to navigate yourself to the desired frame.
Once you have selected the desired frame, create a polygon around the object of interest using the auto annotation tool.
Make sure that you select the instance ID as the subtypes. You can activate it by heading to the Classes tab in your dataset, editing or creating one, and adding Instance ID as a Subtype.

Instance ID
You must have noticed that the select object is given an ID number; this is known as instance ID.
Instance ID keeps the track of an object throughout the video. This is very useful if the object changes its orientation; the instance ID can help to classify and detect it as the same object in multiple frames.
Adding and deleting anchor points
V7 allows you to add and delete anchor points to extend and delete the segmentation mask.

As you can see, the auto annotation tool automatically creates a segmentation around the selected object, in this case, our runner.
You will also notice that the segmentation mask is missing in some areas. To rectify this, you can hover to the area where the segmentation mask is missing and extend it to the desired area within the polygon. Click on the areas where the segmentation mask is missing to complete the segmentation.

As you can see from the image above, I have extended the segmentation and have tried to mask the runner’s body.
The green dots indicate the manual extension or addition of the segmentation, while red dots indicate the deletion of segmentation masks from some area. Once done, go to the next frame.
To annotate the same object in the next frame, click on the rerun button on top of the polygon mask around the object. V7 will automatically cover the object with the segmentation mask.
That’s all. You can continue annotating your object in the subsequent frames by copying the instances and adjusting the label to the object until you’ve annotated all the instances.
Pro tip: If you are looking for a free image annotation tool, check out The Complete Guide to CVAT—Pros & Cons.
Object Tracking: Key Takeaways
Finally, here are some of the key takeaways from this article:
1. Object tracking is a technique of tracking single or multiple objects independent of the frames.
2. Object detection depends on the target object on every single frame while object tracking estimates the position of the target object in the next frame.
3. There are two types of object tracking:
Image tracking
Video tracking
4. There are four stages of object tracking:
Target initialization
Appearance modeling
Motion estimation
Target positioning
5. Deep learning techniques such as deep neural networks allow deeper and meaningful extraction of information allowing traditional machine learning algorithms, like SORT, Kalman filters, etc. to work much more efficiently to estimate the position of the objects.
6. You can use data annotation tools like V7 to annotate your objects and train object tracking algorithms in less than an hour.
Got questions? Get in touch with our team to discuss them!
Read more:
A Simple Guide to Data Preprocessing in Machine Learning
The Train, Validation, and Test Sets: How to Split Your Machine Learning Data
Supervised vs. Unsupervised Learning: What’s the Difference?
40+ Data Science Interview Questions and Answers
The Ultimate Guide to Semi-Supervised Learning
Mean Average Precision (mAP) Explained: Everything You Need to Know
The Beginner’s Guide to Contrastive Learning
9 Reinforcement Learning Real-Life Applications

Nilesh Barla is the founder of PerceptronAI, which aims to provide solutions in medical and material science through deep learning algorithms. He studied metallurgical and materials engineering at the National Institute of Technology Trichy, India, and enjoys researching new trends and algorithms in deep learning.