V7 Go
V7 Go
V7 Go
Turn your documents and data into AI workflows
Turn your documents and data into AI workflows
Scale your output, not your headcount.
Deploy AI agents across your organization.
6:01
NEW - V7 Go Product Update
Introducing Expert AI Agents
Play video
6:01
NEW - V7 Go Product Update
Introducing Expert AI Agents
Play video
6:01
NEW - V7 Go Product Update
Introducing Expert AI Agents
Play video














AI Agents
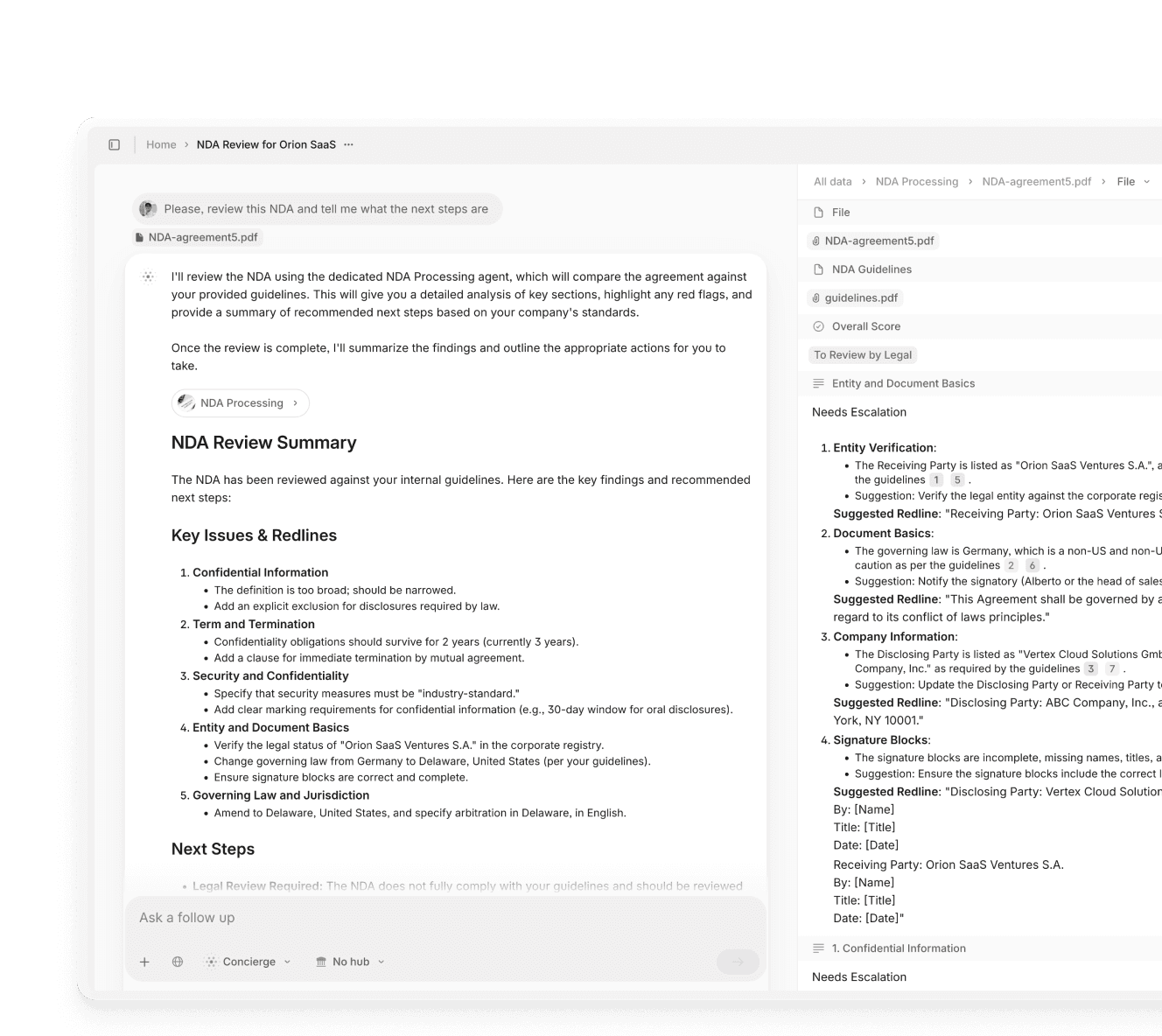
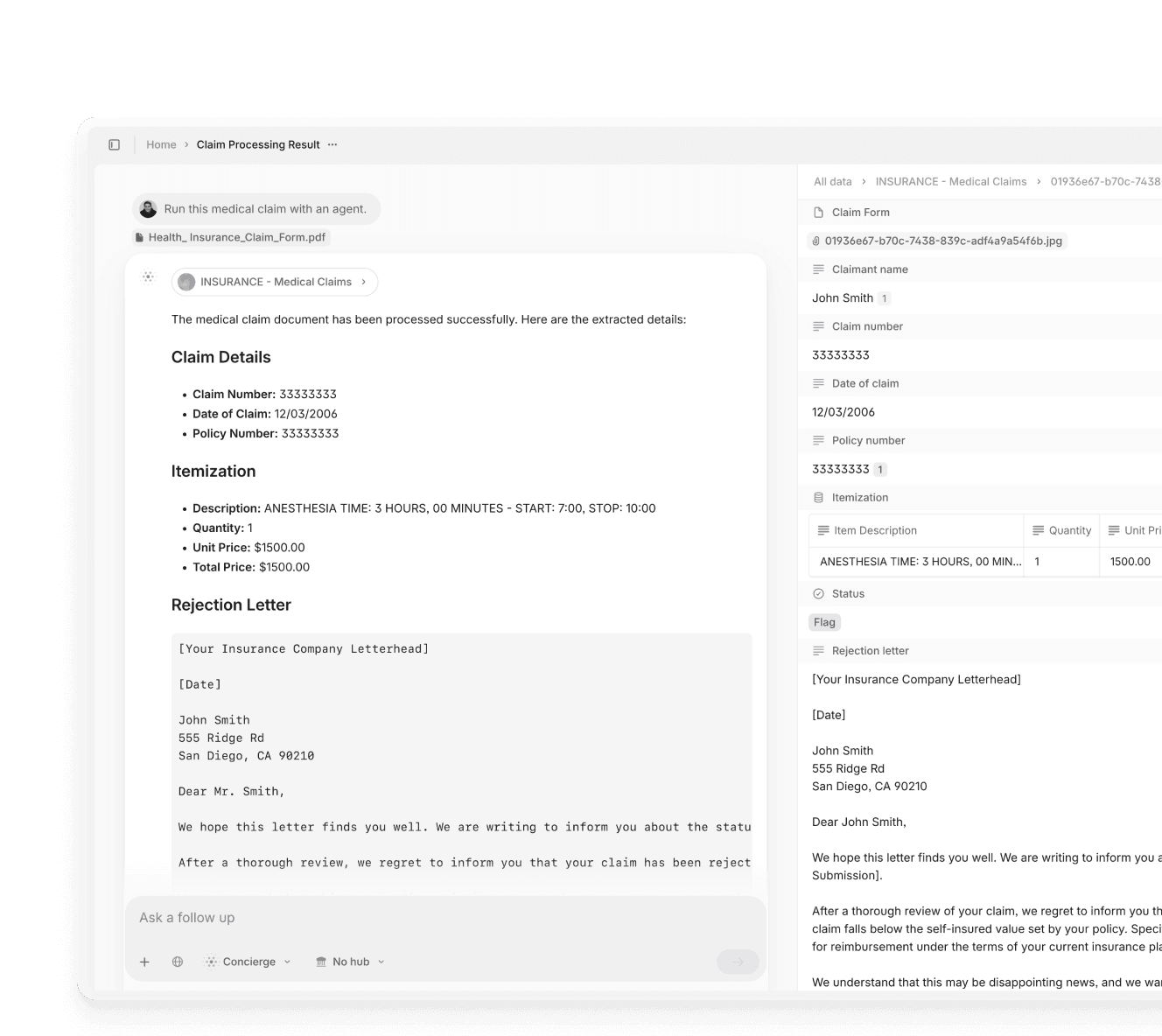
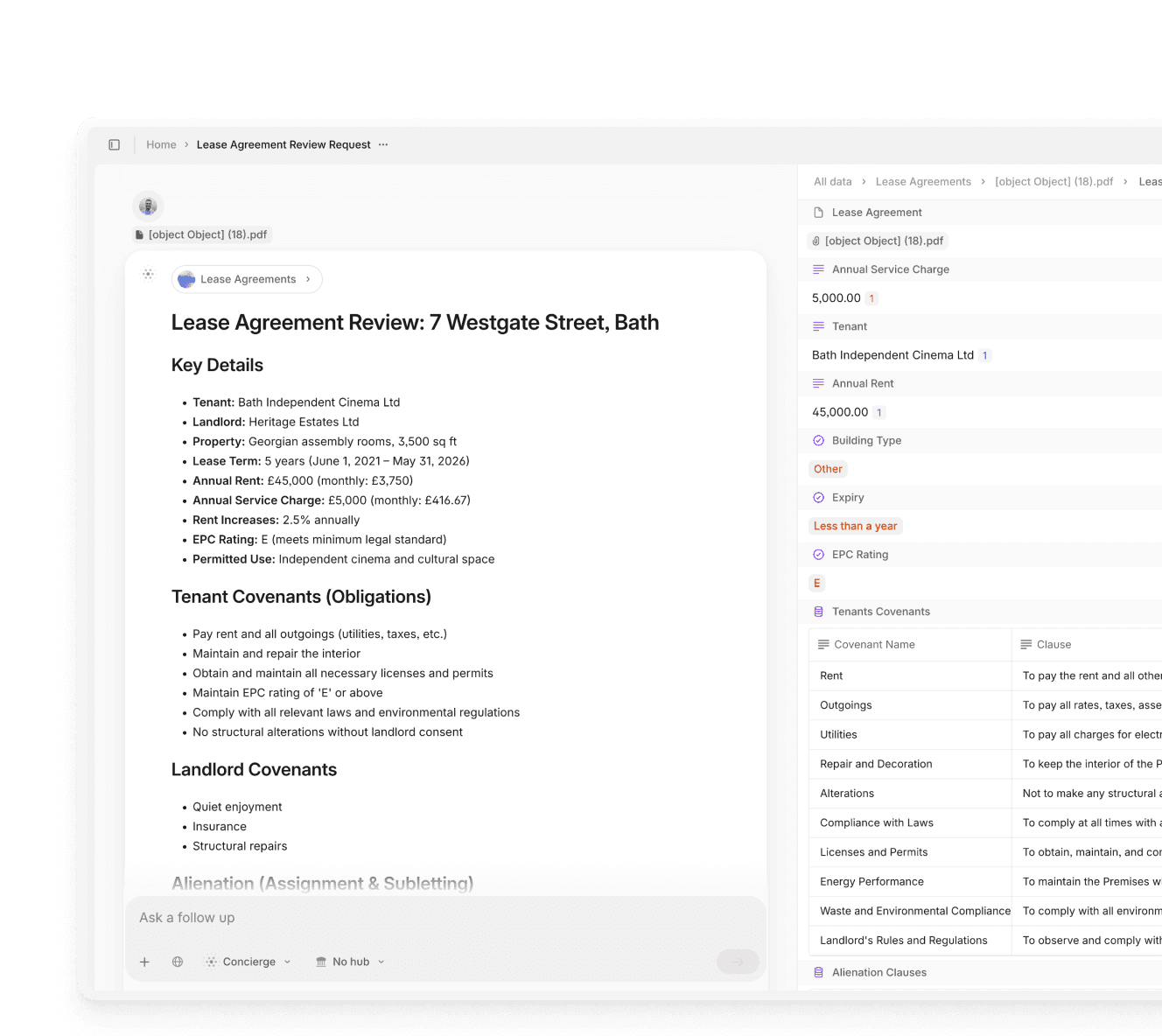
Secure document processing for regulated industries
Secure document processing for regulated industries
Automate high-stakes workflows without compromising compliance or accuracy.
Experience intelligent document processing powered by GenAI. Hit accuracy rates around 99% across complex documents.



Finance
Legal
Insurance
Real Estate
Accounting
Financial services and PE/VC
Turn complex financial data into clear investment intelligence and verifiable risk assessments with specialized agents and AI workflows.
Finance
Legal
Insurance
Real Estate
Accounting
Financial services and PE/VC
Turn complex financial data into clear investment intelligence and verifiable risk assessments with specialized agents and AI workflows.





Finance
Legal
Insurance
Real Estate
Accounting
Financial services and PE/VC
Turn complex financial data into clear investment intelligence and verifiable risk assessments with specialized agents and AI workflows.
01
Deploy AI agents to your entire organization
Share AI agents across teams
Enable everyone to engage with AI agents through simple chat. Ask questions, upload documents, and generate structured outputs.
Turn AI conversations into reports
Easily compile information from your chat interactions into organized reports.
01
Deploy AI agents to your entire organization
Share AI agents across teams
Enable everyone to engage with AI agents through simple chat. Ask questions, upload documents, and generate structured outputs.
Turn AI conversations into reports
Easily compile information from your chat interactions into organized reports.
02
Put AI to work instantly
No API keys or setup required
Apply foundation models to your data with zero setup and maintenance.
Chain models for advanced automation
Connect multiple AI models in sequence to extract data, generate summaries, and perform complex reasoning tasks.
02
Put AI to work instantly
No API keys or setup required
Apply foundation models to your data with zero setup and maintenance.
Chain models for advanced automation
Connect multiple AI models in sequence to extract data, generate summaries, and perform complex reasoning tasks.
03
Automate complex tasks with an advanced AI reasoning engine
Understand any data format
Leverage foundation models to process documents, images, videos, text, and more.
Improve accuracy, get deeper insights
Outperform standard APIs with deeper, context-driven accuracy.
Improve accuracy, get deeper insights

03
Automate complex tasks with an advanced AI reasoning engine
Understand any data format
Leverage foundation models to process documents, images, videos, text, and more.
Improve accuracy, get deeper insights
Outperform standard APIs with deeper, context-driven accuracy.
Improve accuracy, get deeper insights
04
Build flexible AI workflows with human feedback
Choose the best model
Use any foundation model from OpenAI, Anthropic, and Google, or integrate your own fine-tuned models.
Leverage human expertise.
Create human-in-the-loop workflows to validate AI output for your most crucial tasks.
04
Build flexible AI workflows with human feedback
Choose the best model
Use any foundation model from OpenAI, Anthropic, and Google, or integrate your own fine-tuned models.
Leverage human expertise.
Create human-in-the-loop workflows to validate AI output for your most crucial tasks.
01
Deploy AI agents to your entire organization
Share AI agents across teams
Enable everyone to engage with AI agents through simple chat. Ask questions, upload documents, and generate structured outputs.
Turn AI conversations into reports
Easily compile information from your chat interactions into organized reports.
01
Deploy AI agents to your entire organization
Share AI agents across teams
Enable everyone to engage with AI agents through simple chat. Ask questions, upload documents, and generate structured outputs.
Turn AI conversations into reports
Easily compile information from your chat interactions into organized reports.
Features & Design
AI-first architecture meets human-centric design
AI-first architecture meets human-centric design
Powerful features that put you in control.
Experience intelligent document processing powered by GenAI. Hit accuracy rates around 99% across complex documents.
AI citations
Build trust and verify accuracy

Track and validate AI-generated responses with highlighted source excerpts.
AI citations
Build trust and verify accuracy
Track and validate AI-generated responses with highlighted source excerpts.
AI citations
Build trust and verify accuracy
Track and validate AI-generated responses with highlighted source excerpts.
Workflows
Build and automate processes

Create AI workflows with conditional logic to route data and trigger actions.
Workflows
Build and automate processes
Create AI workflows with conditional logic to route data and trigger actions.
Workflows
Build and automate processes
Create AI workflows with conditional logic to route data and trigger actions.
Integrations + API
Connect your tech stack

Integrate via API, connect through Zapier, or build custom solutions with our developer tools.
Integrations + API
Connect your tech stack
Integrate via API, connect through Zapier, or build custom solutions with our developer tools.
Integrations + API
Connect your tech stack
Integrate via API, connect through Zapier, or build custom solutions with our developer tools.
Index Knowledge
Process any document format

Extract structured data from text, tables, charts, and images regardless of size or complexity.
Index Knowledge
Process any document format
Extract structured data from text, tables, charts, and images regardless of size or complexity.
Index Knowledge
Process any document format
Extract structured data from text, tables, charts, and images regardless of size or complexity.
The difference
The difference
It’s that simple.
99.9% accurate AI, deployed by experts
V7 Go achieves 95–99.9% accuracy on 1-shot benchmarks. In comparison:
Leading LLMs: 80–95%
RPA & IDP software: 80–90%
Hyperscalers: 70–80%
Our expert AI engineers help optimize workflows and deploy POCs in under a week. They’ve already saved enterprises 100,000+ hours of work.


The difference
It’s that simple.
99.9% accurate AI, deployed by experts
V7 Go achieves 95–99.9% accuracy on 1-shot benchmarks. In comparison:
Leading LLMs: 80–95%
RPA & IDP software: 80–90%
Hyperscalers: 70–80%
Our expert AI engineers help optimize workflows and deploy POCs in under a week. They’ve already saved enterprises 100,000+ hours of work.
Customer Stories
Customer Stories
Customer Stories
Trusted by leading financial, legal, and insurance teams
Trusted by leading financial, legal, and insurance teams

We bring the complexity. V7 brings the clarity. With solutions delivered in hours, their Solutions Engineers are redefining the pace of innovation for our team.

CEO of Alaris Acquisitions
Read story
→

We use Collections on V7 Go to automate completion of our 20-page safety inspection reports. The system analyzes photos and supporting documentation and returns structured data for each question. It saves us hours on each report.

CEO of Certainty Software

We used V7 Go to automate our diligence process with data extraction and automated analysis. This led to a 35% productivity increase in just the first month of use.

CEO of Centerline
Read story
→

We bring the complexity. V7 brings the clarity. With solutions delivered in hours, their Solutions Engineers are redefining the pace of innovation for our team.
CEO of Alaris Acquisitions
Read story
→
We use Collections on V7 Go to automate completion of our 20-page safety inspection reports. The system analyzes photos and supporting documentation and returns structured data for each question. It saves us hours on each report.
CEO of Certainty Software
We used V7 Go to automate our diligence process with data extraction and automated analysis. This led to a 35% productivity increase in just the first month of use.
CEO of Centerline
Read story
→
We bring the complexity. V7 brings the clarity. With solutions delivered in hours, their Solutions Engineers are redefining the pace of innovation for our team.
CEO of Alaris Acquisitions
Read story
→
We use Collections on V7 Go to automate completion of our 20-page safety inspection reports. The system analyzes photos and supporting documentation and returns structured data for each question. It saves us hours on each report.
CEO of Certainty Software
We used V7 Go to automate our diligence process with data extraction and automated analysis. This led to a 35% productivity increase in just the first month of use.
CEO of Centerline
Read story
→
Security & Safety
Security & Safety
Security & Safety
Enterprise-grade security
without compromise
Enterprise-level security.
Keep your data private.
Enterprise security
Model transparency
Data sovereignty
Access control
Enterprise-grade compliance and scalability with end-to-end encryption and SOC 2 Type II certification.




Enterprise security
Model transparency
Data sovereignty
Access control
Enterprise-grade compliance and scalability with end-to-end encryption and SOC 2 Type II certification.
Enterprise security
Model transparency
Data sovereignty
Access control
Enterprise-grade compliance and scalability with end-to-end encryption and SOC 2 Type II certification.
AI Agent Integration
See V7 Go in action
Schedule a meeting with one of our AI experts. Share sample data in advance for a customized demo.
You’ll hear back in less than 24 hours


AI Agent Integration
See V7 Go in action
Schedule a meeting with one of our AI experts. Share sample data in advance for a customized demo.
You’ll hear back in less than 24 hours
Next steps
See V7 Go in action
Schedule a meeting with one of our AI experts. Share sample data in advance for a customized demo.
Why should I use Go instead of calling a model provider directly?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Is V7 Go part of V7 Darwin?
V7 Darwin is a data labeling platform for annotating videos and medical imaging to train your own model, while V7 Go specializes in applying foundation models to multimodal data, starting with intelligent document processing. In time they will be natively connected.
+
How do the limits of the Professional plan work?
The Professional plan is limited on fields (what you would call ‘cells’ in a spreadsheet) and Go tokens, which are consumed when you use AI models. The field limit does not refresh, while your token allowance resets on the same cadence as your billing cycle. While both fields and tokens are a hard limit, they can be increased by expanding your plan.
+
Does V7 Go support external models?
V7 Go will support external models via API, allowing for a flexible approach to document processing by incorporating both in-house and third-party AI models.
+
Can V7 Go recognize printed and handwritten text?
V7 Go is capable of recognizing both printed and handwritten text, leveraging advanced optical character recognition (OCR) technologies, as well as charts, diagrams and logos.
+
Why should I use Go instead of calling a model provider directly?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Is V7 Go part of V7 Darwin?
V7 Darwin is a data labeling platform for annotating videos and medical imaging to train your own model, while V7 Go specializes in applying foundation models to multimodal data, starting with intelligent document processing. In time they will be natively connected.
+
How do the limits of the Professional plan work?
The Professional plan is limited on fields (what you would call ‘cells’ in a spreadsheet) and Go tokens, which are consumed when you use AI models. The field limit does not refresh, while your token allowance resets on the same cadence as your billing cycle. While both fields and tokens are a hard limit, they can be increased by expanding your plan.
+
Does V7 Go support external models?
V7 Go will support external models via API, allowing for a flexible approach to document processing by incorporating both in-house and third-party AI models.
+
Can V7 Go recognize printed and handwritten text?
V7 Go is capable of recognizing both printed and handwritten text, leveraging advanced optical character recognition (OCR) technologies, as well as charts, diagrams and logos.
+
Why should I use Go instead of calling a model provider directly?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Is V7 Go part of V7 Darwin?
V7 Darwin is a data labeling platform for annotating videos and medical imaging to train your own model, while V7 Go specializes in applying foundation models to multimodal data, starting with intelligent document processing. In time they will be natively connected.
+
How do the limits of the Professional plan work?
The Professional plan is limited on fields (what you would call ‘cells’ in a spreadsheet) and Go tokens, which are consumed when you use AI models. The field limit does not refresh, while your token allowance resets on the same cadence as your billing cycle. While both fields and tokens are a hard limit, they can be increased by expanding your plan.
+
Does V7 Go support external models?
V7 Go will support external models via API, allowing for a flexible approach to document processing by incorporating both in-house and third-party AI models.
+
Can V7 Go recognize printed and handwritten text?
V7 Go is capable of recognizing both printed and handwritten text, leveraging advanced optical character recognition (OCR) technologies, as well as charts, diagrams and logos.
+