AI implementation
Top Performance Metrics in Machine Learning: A Comprehensive Guide
17 min read
—

Performance metrics are a key part of ensuring models are reliable. But which metric is the right one for your use case? Find out in our comprehensive guide.

Performance metrics in machine learning are essential for assessing the effectiveness and reliability of models. They’re a key element of every machine learning pipeline, allowing developers to fine-tune their algorithms and drive improvements.
The metrics can be broadly categorized into two main types: regression and classification metrics.
Deciding on the right performance metric for your project might be challenging, but ensuring it’s evaluated as fairly and accurately as possible is crucial. Fortunately, this guide will break down the top performance metrics in machine learning to help you decide the best metrics for your use case.
Here’s what we’ll cover:
Top regression metrics
Top classification metrics
Other important metrics
How to choose the right metric for your project
And if you’re ready to start training your machine learning models right now, you can check out:

AI for document processing
Ship reliable AI agents for your finance workflows
Get started today
Top regression metrics
First up, regression metrics. Regression metrics are used to evaluate the performance of algorithms that predict continuous numerical values. Let’s go through the most important regression metrics.
Mean Absolute Error (MAE)
Mean Absolute Error (MAE) is a popular metric used to evaluate the performance of regression models in machine learning and statistics. It measures the average magnitude of errors between predicted and actual values without considering their direction. MAE is especially useful in applications that aim to minimize the average error and is less sensitive to outliers than other metrics like Mean Squared Error (MSE).
Given a dataset with n observations, where $y_i$ is the actual value and $ŷ_i$ is the predicted value for the i-th data point in the dataset, the Mean Absolute Error (MAE) can be calculated using the following formula:
$$\mathrm{MAE} = \frac{1}{{\mathrm{n}}}\sum_{}{\mathrm{y}} - {\mathrm{ŷ}}$$
Here, the absolute difference between each actual value $(y)$ and its corresponding predicted value $(ŷ)$ is calculated, and the sum of these absolute differences is divided by the total number of observations $(n)$ to obtain the average error.
The strength of MAE lies in its ability to provide an intuitive and easily interpretable measure of model performance. A lower MAE indicates a better model fit, showing that the model's predictions are, on average, closer to the true values. It is beneficial when comparing different models on the same dataset, as it can help identify the model with the most accurate predictions.
What it shows
MAE measures the average magnitude of errors in the predictions made by the model (without considering their direction).
When to use
Use MAE when you want a simple, interpretable metric to evaluate the performance of your regression model.
When to avoid
Avoid using MAE to emphasize the impact of larger errors, as it does not penalize them heavily.
Code implementation for Mean Absolute Error (MAE)
Mean Squared Error (MSE)
Mean Squared Error (MSE) is another widely used metric for assessing the performance of regression models in machine learning and statistics. It measures the average squared difference between the predicted and actual values, thus emphasizing larger errors. MSE is particularly useful in applications where the goal is to minimize the impact of outliers or when the error distribution is assumed to be Gaussian.
Gaussian distribution, is a probability distribution that is symmetric about the mean, showing that data near the mean are more frequent in occurrence than data far from the mean
Given a dataset with n observations, where y_i is the actual value and ŷ_i is the predicted value for the i-th observation, the Mean Squared Error (MSE) can be calculated using the following formula:
$$\mathrm{MSE} = \frac{1}{{\mathrm{n}}}\sum_{{\mathrm{i}} = 1}^{{\mathrm{n}}}({\mathrm{Y}}{{\mathrm{i}}} - \widehat{{\mathrm{Y}}}{{\mathrm{i}}})^2$$
Here, the squared difference between each actual value $(y_i)$ and its corresponding predicted value $(ŷ_i)$ is calculated, and the sum of these squared differences is divided by the total number of observations $(n)$ to obtain the average squared error.
MSE provides a measure of model performance that penalizes larger errors more severely than smaller ones. A lower MSE indicates a better model fit, demonstrating that the model's predictions are, on average, closer to the true values. It is commonly used when comparing different models on the same dataset, as it can help identify the model with the most accurate predictions.
What it shows
MSE measures the average squared difference between the actual and predicted values, penalizing larger errors more heavily than smaller ones.
When to use
Use MSE when you want to place a higher emphasis on larger errors.
When not to use
Avoid using MSE if you need an easily interpretable metric or if your dataset has a lot of outliers, as it can be sensitive to them.
Code implementation for Mean Squared Error (MSE)
Root Mean Squared Error (RMSE)
The Mean Squared Error (MSE) square root measures the average squared difference between the predicted and actual values. Root Mean Squared Error (RMSE) has the same unit as the target variable, making it more interpretable and easier to relate to the problem context than MSE.
Given a dataset with n observations, where $y_i$ is the actual value, and $ŷ_i$ is the predicted value for the i-th observation, the Root Mean Squared Error (RMSE) can be calculated using the following formula:
$$\mathrm{RMSE} = \sqrt{\frac{\sum_{{\mathrm{i}} = 1}^{{\mathrm{N}}}{\mathrm{y}}({\mathrm{i}}) - {\mathrm{ŷ}}({\mathrm{i}})^2}{{\mathrm{n}}}}$$
Here, the squared difference between each actual value (y_i) and its corresponding predicted value (ŷ_i) is calculated, and the sum of these squared differences is divided by the total number of observations (n) to obtain the average squared error. The square root of this value is then taken to compute the RMSE.
RMSE can provide a measure of model performance that balances the emphasis on larger errors (as in MSE) with interpretability (since it has the same unit as the target variable). A lower RMSE indicates a better model fit, showing that the model's predictions are, on average, closer to the true values. It is commonly used when comparing different models on the same dataset, as it can help identify the model with the most accurate predictions.
When to use
Use RMSE to penalize larger errors and obtain a metric with the same unit as the target variable.
When not to use
Avoid using RMSE if you need an interpretable metric or if your dataset has a lot of outliers.
Code implementation for Root Mean Squared Error (RMSE)
R-Squared
R Squared $(R^2)$, also known as the coefficient of determination, measures the proportion of the total variation in the target variable explained by the model's predictions.$(R^2)$ ranges from 0 to 1, with higher values indicating a better model fit.The significance of $(R^2)$ lies in its ability to provide an intuitive and easily interpretable measure of how well the model captures the underlying structure of the data.It tells us the percentage of the variation in the target variable that the model's predictors can explain. $(R^2)$ is particularly useful when comparing different models on the same dataset, as it can help identify the model that best explains the variation in the target variable.Given a dataset with n observations, where $y_i$ is the actual value, and $ŷ_i$ is the predicted value for the i-th observation, the R Squared can be calculated using the following formula:
$${\mathrm{r}} = \frac{{\mathrm{n}}(\sum_{}\mathrm{xy}) - (\sum_{}{\mathrm{x}})(\sum_{}{\mathrm{y}})}{\sqrt{{\mathrm{n}}\sum_{}{\mathrm{x}}^2 - (\sum_{}{\mathrm{x}})^2{\mathrm{n}}\sum_{}{\mathrm{y}}^2 - (\sum_{}{\mathrm{y}})^2}}$$
In this formula, the numerator represents the sum of the squared errors between the actual and predicted values (also known as the residual sum of squares). At the same time, the denominator represents the sum of the squared differences between the actual values and their mean (also known as the total sum of squares). These two quantities' ratios are subtracted from 1 to obtain the R-squared value.
What it shows
R-squared measures the proportion of the variance in the dependent variable that the model's independent variables can explain.
When to use
Use R-squared when you want to understand how well your model is explaining the variation in the target variable compared to a simple average.
When not to use
Avoid using it if your model has a large number of independent variables or if it is sensitive to outliers.
Code implementation for R-Squared











Classification metrics
Classification metrics assess the performance of machine learning models for classification tasks. They aim to assign an input data point to one of several predefined categories.
Let’s go through the most commonly used classification metrics.
Pro tip: Already building your classification model? Check out our guides on image classification and video classification.
Accuracy
Accuracy is a fundamental evaluation metric for assessing the overall performance of a classification model. It is the ratio of the correctly predicted instances to the total instances in the dataset. The formula for calculating accuracy is:
$$\mathrm{Accuracy} = \frac{\mathrm{TP} + \mathrm{TN}}{\mathrm{TP} + \mathrm{FP} + \mathrm{TN} + \mathrm{FN}}$$
What it shows
Accuracy measures the proportion of correct predictions made by the model out of all predictions.
When to use
Accuracy is useful when the class distribution is balanced, and false positives and negatives have equal importance.
When not to use
If the dataset is imbalanced or the cost of false positives and negatives differs, accuracy may not be an appropriate metric.
Confusion Matrix
A confusion matrix, also known as an error matrix, is a tool used to evaluate the performance of classification models in machine learning and statistics. It presents a summary of the predictions made by a classifier compared to the actual class labels, allowing for a detailed analysis of the classifier's performance across different classes.
The confusion matrix provides a comprehensive view of the model's performance, including each class's correct and incorrect predictions.
It helps identify misclassification patterns and calculate various evaluation metrics such as precision, recall, F1-score, and accuracy. By analyzing the confusion matrix, you can diagnose the model's strengths and weaknesses and improve its performance.
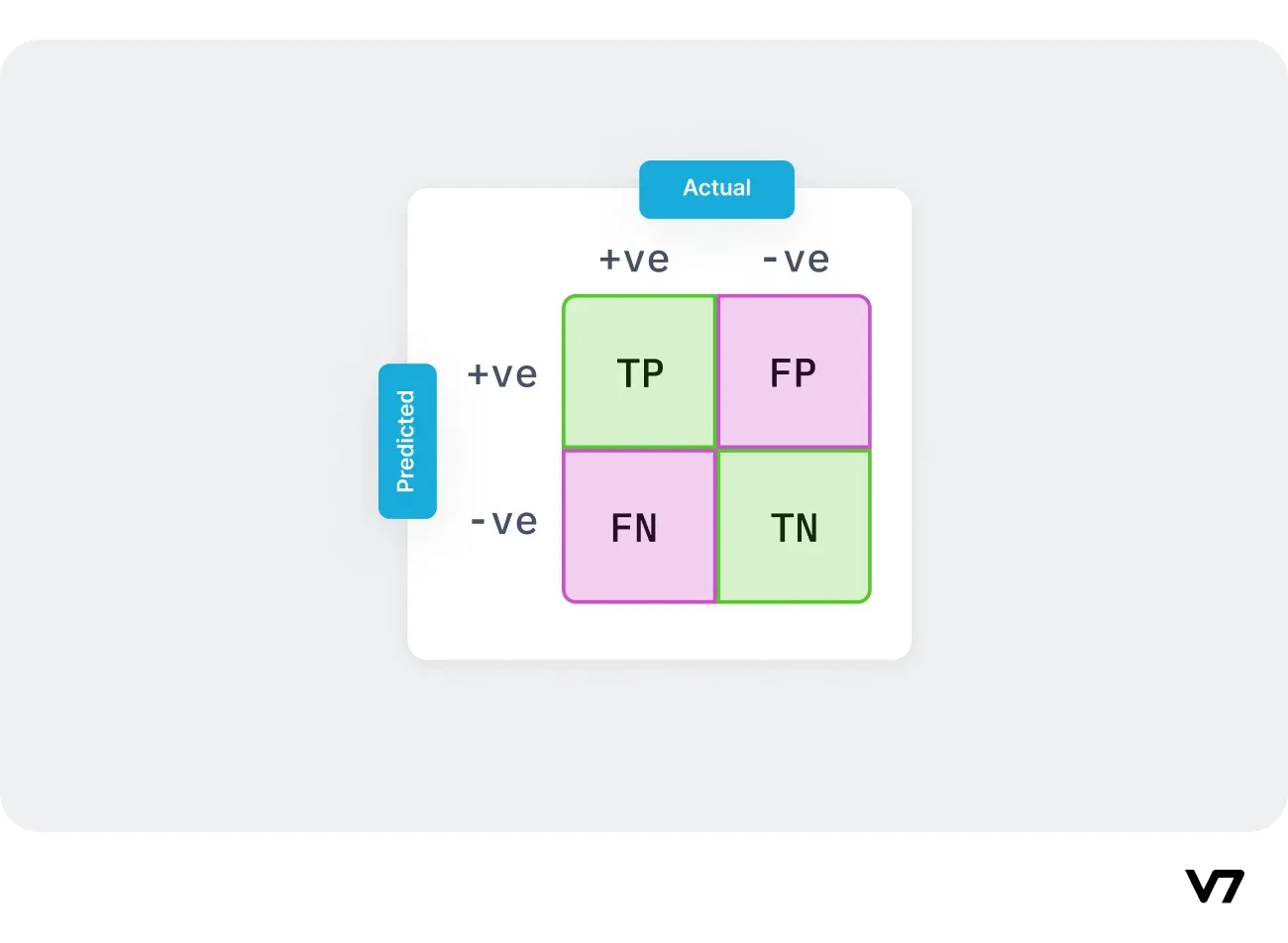
Let's start with an example confusion matrix for a binary classifier (though it can easily be extended to the case of more than two classes):
Two possible predicted classes are "yes" and "no." If we were predicting the presence of a disease in a patient, for example, "yes" would mean they have the disease, and "no" would mean they don't. The classifier made a total of 165 predictions (e.g., 165 patients were being tested for the presence of that disease). Of those 165 cases, the classifier predicted "yes" 110 times and "no" 55 times. In reality, 105 patients in the sample have the disease, and 60 patients do not.
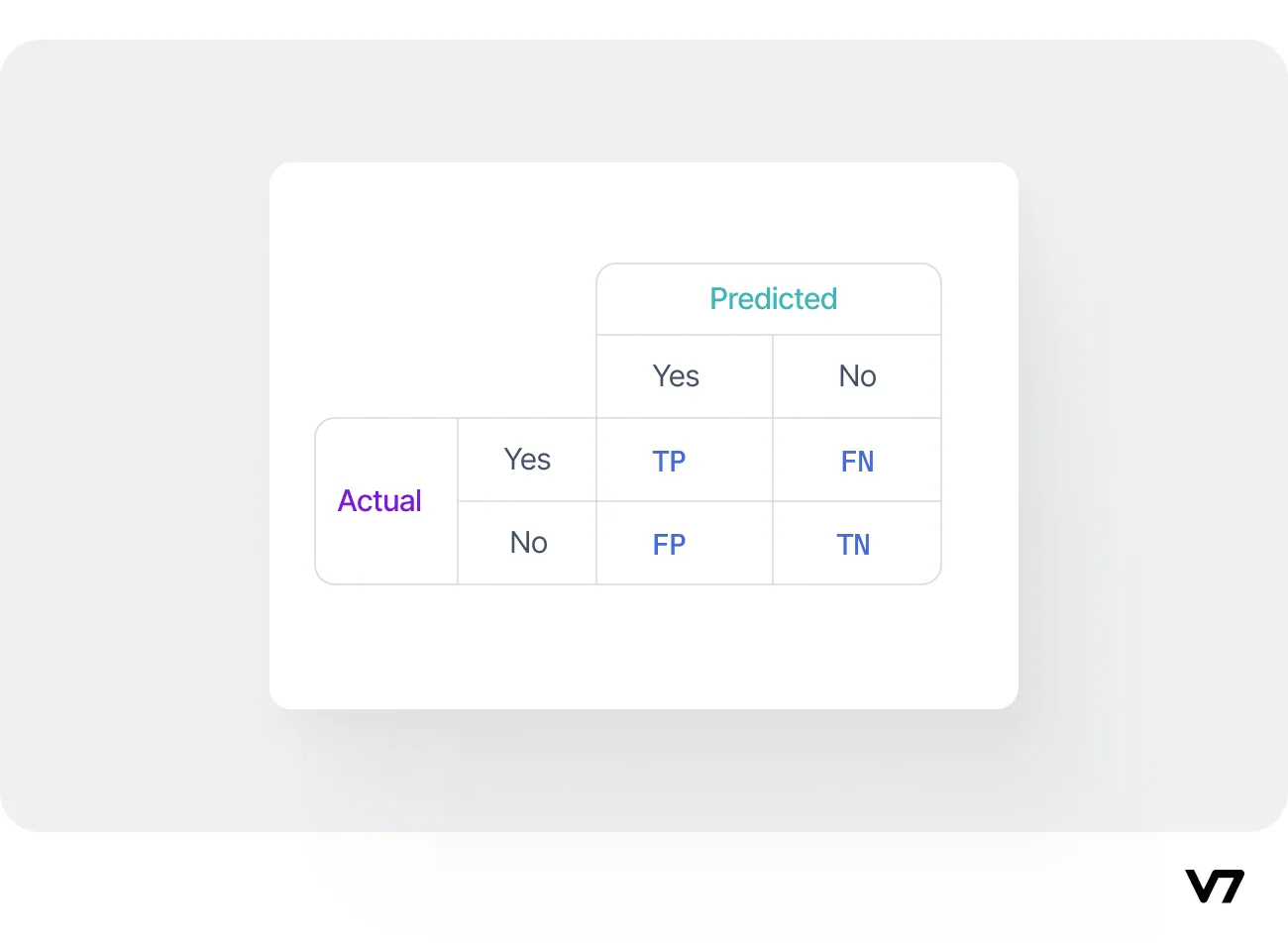
Let's create a confusion matrix in the given disease classification case and interpret it.
Here's the confusion matrix:
TP: True Positives - The number of patients with the disease correctly predicted as "yes."
TN: True Negatives - The number of patients without the disease was correctly predicted as "no."
FP: False Positives - The number of patients who don't have the disease but were incorrectly predicted as "yes."
FN: False Negatives - The number of patients who have the disease but were incorrectly predicted as "no."
From the given information:
Total predictions = 165
Predicted "yes" = 110
Predicted "no" = 55
Actual "yes" = 105
Actual "no" = 60
To fill in the confusion matrix, we need to find the values of TP, TN, FP, and FN. We can't determine these values from the information given, so let's assume we have those values:
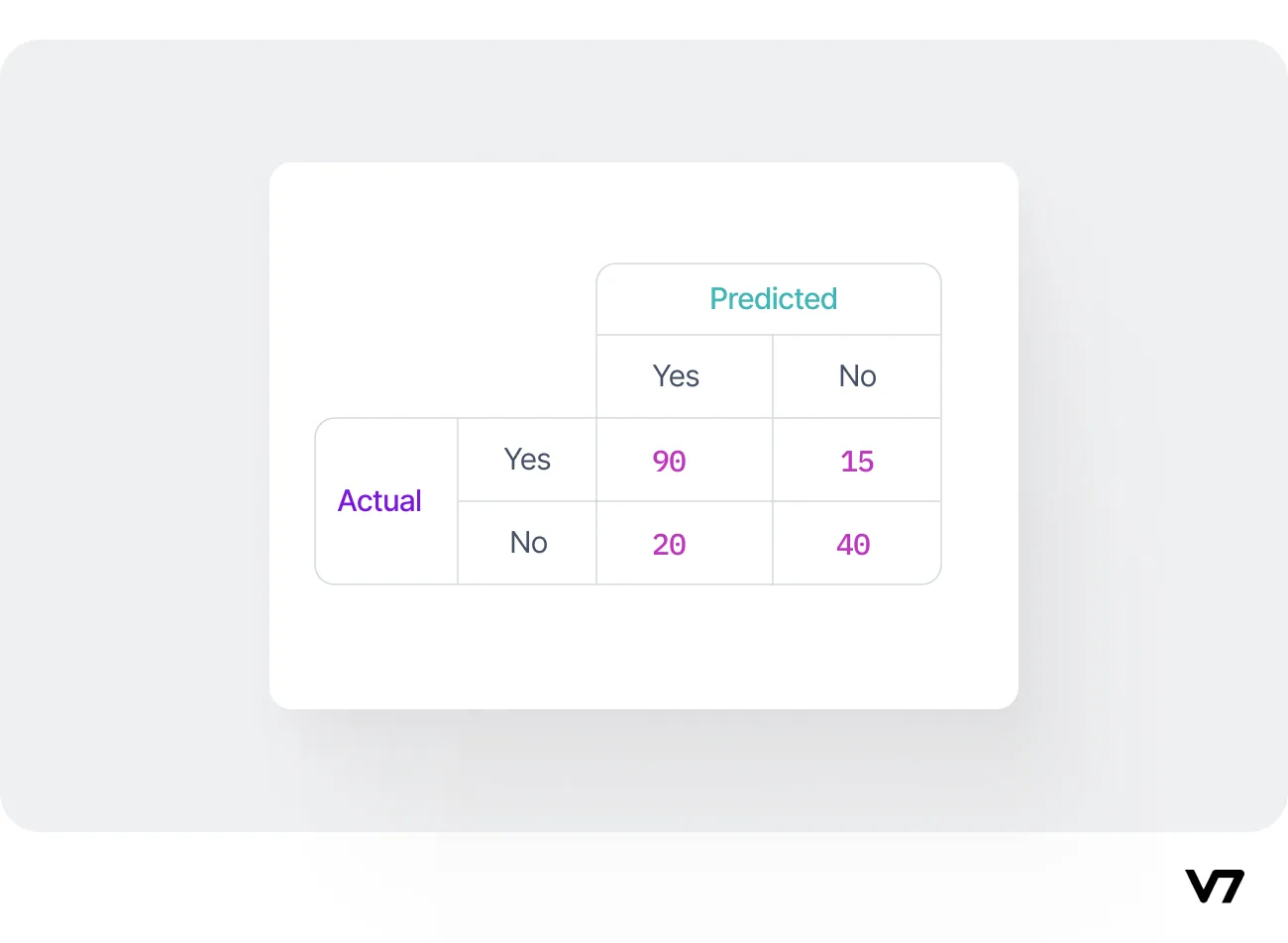
From this confusion matrix, we can interpret the following:
TP (90): Out of 105 patients with the disease, the model correctly predicted "yes" for 90 patients.
FN (15): The model incorrectly predicted "no" for 15 patients with the disease.
FP (20): Out of 60 patients without the disease, the model incorrectly predicted "yes" for 20 patients.
TN (40): The model correctly predicted "no" for 40 patients who don't have the disease.
What it shows
The confusion matrix provides a detailed breakdown of the model's performance, allowing us to identify specific types of errors.
When to use
Use a confusion matrix when you want to visualize the performance of a classification model and analyze the types of errors it makes.
Code implementation for Confusion Matrix
Pro tip: Check out this in-depth guide about the confusion matrix
Precision and Recall
Precision and recall are essential evaluation metrics in machine learning for understanding the trade-off between false positives and false negatives.
$$\mathrm{\Pr ecision} = \frac{\mathrm{TP}}{\mathrm{TP} + \mathrm{FP}}$$
$$\mathrm{Recall} = \frac{\mathrm{TP}}{\mathrm{TP} + \mathrm{FN}}$$
Precision (P) is the proportion of true positive predictions among all positive pedictions. It is a measure of how accurate the positive predictions are.
Recall (R), also known as sensitivity or true positive rate (TPR), is the proportion of true positive predictions among all actual positive instances. It measures the classifier's ability to identify positive instances correctly.
A high precision means the model has fewer false positives, while a high recall means fewer false negatives. Depending on the specific problem you're trying to solve, you might prioritize one of these metrics over the other.
Imagine you're a detective trying to solve a crime in a city. Your task is to identify criminals from a list of suspects. You have to find the real criminals and minimize false accusations.
Let's think of your investigation in terms of machine learning. Your detective model makes predictions by classifying suspects as criminals or innocent. The model's performance can be measured by two key metrics: Precision and Recall.
Precision measures how well your detective model correctly identifies criminals without falsely accusing innocent people.
Let's say you've identified ten suspects as criminals. If seven are actual criminals, and three are innocent, your precision is 70% (7/10). High precision indicates that you're great at avoiding false accusations.
Now, let's talk about the recall.
The recall measures how well your detective model captures all the criminals in the city. It's like casting a wide net to ensure no criminals slip through the cracks.
Let's say there are a total of 20 criminals in the city. If you've identified seven, your recall is 35% (7/20). A high recall means you're excellent at catching criminals, even if some innocent people might get caught in the net.
In a perfect world, you would want to have both high precision and high recall, ensuring that you're accurate in your accusations and comprehensive in capturing all criminals. However, there's often a trade-off between the two metrics in practice: improving one may come at the cost of the other.

Precision/recall breakdown for a traffic light and sign detection model in V7
What they show
Precision measures the proportion of true positive predictions among all positive predictions, while recall measures the proportion of true positive predictions among all actual positive instances.
When to use
Precision and recall are useful when the class distribution is imbalanced or when the cost of false positives and false negatives is different.
When not to use
Accuracy might be more appropriate if the dataset is balanced and the costs of false positives and negatives are equal.
Code implementation (PyTorch) for Precision and Recall
Pro tip: Check out this comprehensive guide on Precision and Recall
F1-score
The F1-score is the harmonic mean of precision and recall, providing a metric that balances both measures. It is beneficial when dealing with imbalanced datasets, where one class is significantly more frequent than the other. The formula for the F1 score is:
$${\mathrm{F}}1\mathrm{Score} = \frac{2}{\frac{1}{\mathrm{\Pr ecision}} + \frac{1}{\mathrm{Recall}}} = \frac{2{\mathrm{x}}\mathrm{\Pr ecision}{\mathrm{x}}\mathrm{Recall}}{\mathrm{\Pr ecision} + \mathrm{Recall}}$$
The significance of the F1 score lies in its ability to provide a harmonized assessment of a model's performance when both precision and recall are important. Unlike accuracy, which can be misleading in cases of class imbalance, the F1 score considers the balance between false positives and false negatives.
A high F1 score indicates that the model has a high precision (low false positives) and high recall (low false negatives), which is often desirable in various applications.
What it shows
The F1-score is the harmonic mean of precision and recall, providing a metric that considers false positives and false negatives.
When to use
The F1-score is useful when the class distribution is imbalanced or when the cost of false positives and false negatives is different.
When not to use
Accuracy might be more appropriate if the dataset is balanced and the costs of false positives and negatives are equal.
Code implementation (PyTorch) for F1 Score
Pro tip: Check out this guide on F1 Score and its fundamentals.
Area Under the Receiver Operating Characteristic Curve (AU-ROC)
The AU-ROC is a popular evaluation metric for binary classification problems. It measures the model's ability to distinguish between positive and negative classes. The ROC curve plots the true positive rate (recall) against the false positive rate (1 - specificity) at various classification thresholds. The AU-ROC represents the area under the ROC curve, and a higher value indicates better model performance.
The significance of the AU-ROC lies in its ability to provide a comprehensive view of a model's performance across all possible classification thresholds. It considers the trade-off between true positive rate (TPR) and false positive rate (FPR) and quantifies the classifier's ability to differentiate between the two classes.
A higher AU-ROC value indicates better performance, with a perfect classifier having an AU-ROC of 1 and a random classifier having an AU-ROC of 0.5.
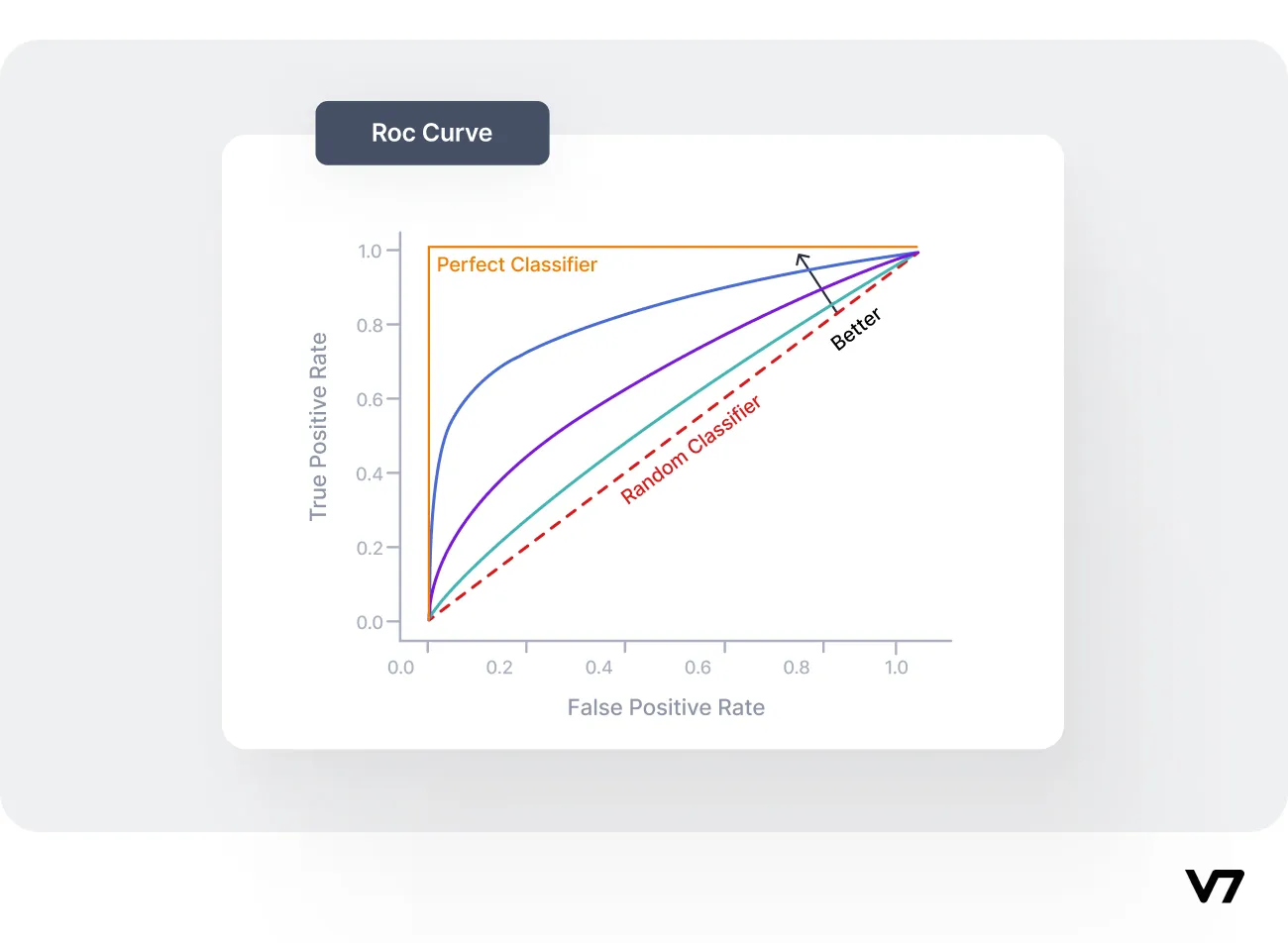
Source: ROC Curve
What it shows
AU-ROC represents the model's ability to discriminate between positive and negative classes. A higher AU-ROC value indicates better classification performance.
When to use
Use AU-ROC to compare the performance of different classification models, especially when the class distribution is imbalanced.
When not to use
Accuracy might be more appropriate if the dataset is balanced and the costs of false positives and negatives are equal.
Code implementation (PyTorch) for AU-ROC
In this example, we first convert the PyTorch tensors y_true and y_pred into NumPy arrays. Then, we use the roc_auc_score function from scikit-learn to calculate the AU-ROC score. Note that y_true should contain binary labels (0 or 1), and y_pred should contain the predicted probabilities for the positive class.
Other important metrics
Let’s discuss other important metrics widely used in object detection and segmentation tasks. Intersection over Union (IoU) and mean Average Precision (mAP) help assess the performance of models that identify and localize multiple objects within images.
Intersection over Union (IoU)
Intersection over Union (IoU) is a popular evaluation metric in object detection and segmentation tasks. It measures the overlap between the predicted bounding box and the ground truth bounding box, providing an understanding of how well the model detects objects in images. The IoU is calculated as the ratio of the intersection area to the union area of the two bounding boxes:
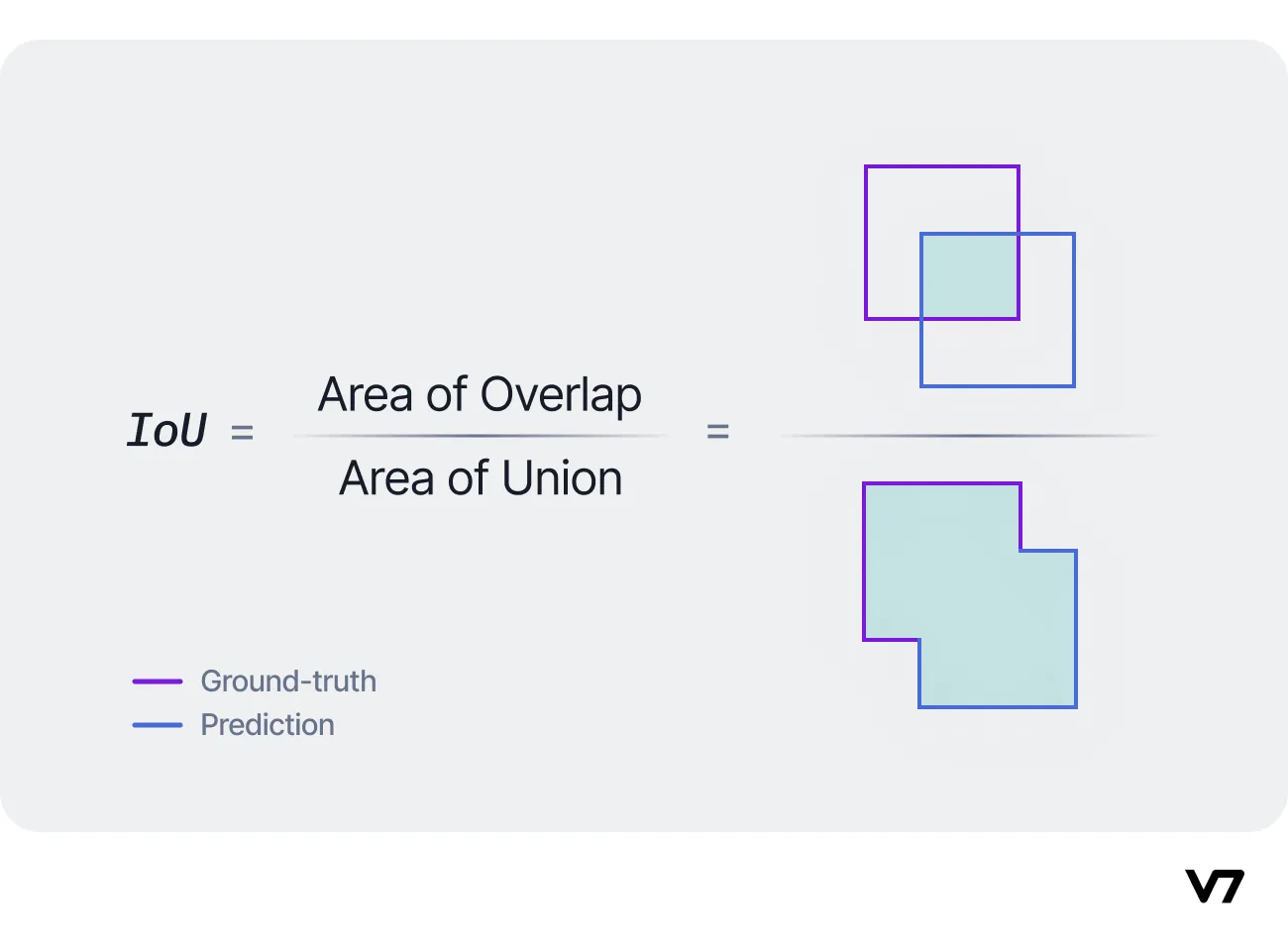
A higher IoU value indicates a better model performance, with 1.0 being the perfect score.
What it shows
IoU quantifies how well the model's predictions align with the ground truth bounding boxes.
When to use
Use IoU for object detection and segmentation tasks.
When not to use
IoU is irrelevant for classification or regression.
Code implementation of the IoU Score in PyTorch
Mean Average Precision (mAP)
Mean Average Precision (mAP) is another widely used performance metric in object detection and segmentation tasks. It is the average of the precision values calculated at different recall levels, providing a single value that captures the overall effectiveness of the model. The mAP can be computed using the following steps:
1. Calculate each class's average precision (AP) using the precision-recall curve. Average Precision is the area under the PR curve for a single query or class. It can be calculated using the following steps:
Interpolate the precision values: For each recall level, find the highest precision value with recall equal to or greater than the current recall level. This step ensures that the precision values are monotonically decreasing from left to right.
Calculate AP: Compute the area under the interpolated PR curve by summing the product of the change in recall and interpolated precision at each recall level: AP = Sum(P(i) * (R(i) - R(i-1)))
2. Calculate the mean of the AP values across all classes:
$$\mathrm{mAP} = \frac{1}{{\mathrm{n}}}\sum_{{\mathrm{k}} = 1}^{{\mathrm{k}} = {\mathrm{n}}}AP_{{\mathrm{k}}}$$
Where $AP_k$ is the average precision for the k-th query or class, and $N$ is the total number of queries or classes.
What it shows
Mean Average Precision (mAP) is a metric that computes the average precision (AP) for multiple object classes. It combines precision and recall, considering the presence of false positives and false negatives and their distribution across different confidence thresholds. The mAP score ranges from 0 (worst performance) to 1 (best performance).
When to use
Use mAP in object detection and segmentation tasks to evaluate the model's overall performance across all object classes—when there are multiple object classes, and you want a single metric to assess the model's performance across all classes.
When not to use
Avoid using mAP when you need a detailed analysis of the model's performance in specific classes, as it averages the performance across all classes. In such cases, analyze class-wise AP instead.
Code implementation of the mAP Score in PyTorch

Deval is a senior software engineer at Eagle Eye Networks and a computer vision enthusiast. He writes about complex topics related to machine learning and deep learning.

