19 min read
—

In this blog post, we will explain why LLMs are the future of AI as we know it—and take a look at the challenges they’re facing.

If the first thing you think about when you hear Large Language Models (LLMs) is ChatGPT—you’re not wrong.
ChatGPT is getting all the fame because of its accessibility—anyone can use the pre-trained model through OpenAI’s easy-to-use interface—more so than the algorithm behind it. But LLMs have been around for quite some time.
LLMs are computer programs that use sophisticated algorithms to analyze vast amounts of human language data and learn patterns in language structure and usage. They then use this knowledge to generate human-like language responses to queries or prompts.
The impact of LLMs on AI has been profound. The models are making it possible for machines to perform tasks that were once thought to be the exclusive domain of human beings. From chatbots and virtual assistants to language translation and content creation, LLMs are used across multiple industries.
In this blog post, we will explain why LLMs are the future of AI as we know it—and take a look at the challenges they’re facing.
In this article, we’ll cover:
What is a Large Language Model?
LLMs use cases
LLMs examples
Limitations of LLMs
Tutorial: Training Large Language Models
The future of Large Language Models
Let’s roll!

AI for document processing
Give AI agents your most time-consuming finance tasks
Get started today
Ready to start building your own AI models right away? Take a look at:
What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a “transformer” architecture that processes and generates human-like language. It is a machine learning algorithm that uses massive amounts of text data to learn how to understand and generate language.
Transformers are a neural network architecture (developed in 2017) that was proposed to replace recurrent neural networks in processing sequential natural language data. Transformers are computationally less expensive and can capture contextual relations between the words in a sentence.
The key to an LLM is its ability to analyze vast quantities of text and recognize patterns in language use, grammar, and syntax. This process, known as training, involves feeding the model millions or even billions of sentences or paragraphs of text. The LLM then uses this data to learn how to predict the next word in a sentence, complete a phrase, or answer a question.
Self-supervised learning has revolutionized the field of large language models (LLMs) by enabling the training of models on massive amounts of unlabeled text data without the need for human annotation. By leveraging self-supervised learning techniques, such as masked language modeling, LLMs can effectively capture the underlying patterns, semantic relationships, and contextual understanding of language. This approach has drastically expanded the scale and scope of training data available for LLMs, allowing them to learn from the vast and diverse information available on the internet.
Large Language Model use cases
LLMs have rapidly transformed numerous industries and domains, offering various applications and use cases. Their remarkable ability to comprehend and generate human-like text has opened up new possibilities and revolutionized traditional workflows. In this section, let us dive into the fields where LLMs have made a significant impact.
Content creation
Large Language Models have emerged as powerful tools for content creation, changing how we generate written material across various domains. LLMs excel at understanding context, syntax, and language nuances, allowing them to produce human-like text in a wide range of styles and genres.
Content creation is a broad field encompassing areas such as writing articles, blog posts, marketing copy, product descriptions, and more. Content creation typically involves extensive research, outlining, drafting, and editing by human writers. LLMs can aid greatly in that process, assisting human writers in these tasks.
One of the key advantages of LLMs for content creation is their ability to generate coherent and contextually relevant text. By training on massive amounts of data, LLMs develop a deep understanding of language patterns, enabling them to produce high-quality content that is grammatically correct and semantically meaningful. They can even mimic the style and tone of specific authors or adapt to different target audiences.
Dramatron (2023) is an LLM model for writing long-form screenplays complete with titles, characters, story beats, location descriptions, and dialogue. It generates scripts and screenplays hierarchically to build structural context via prompt chaining. Prompt engineering is a common way that users control or influence LLMs. Each prompt has a few examples of desirable outputs. The overview of Dramatron is shown below.
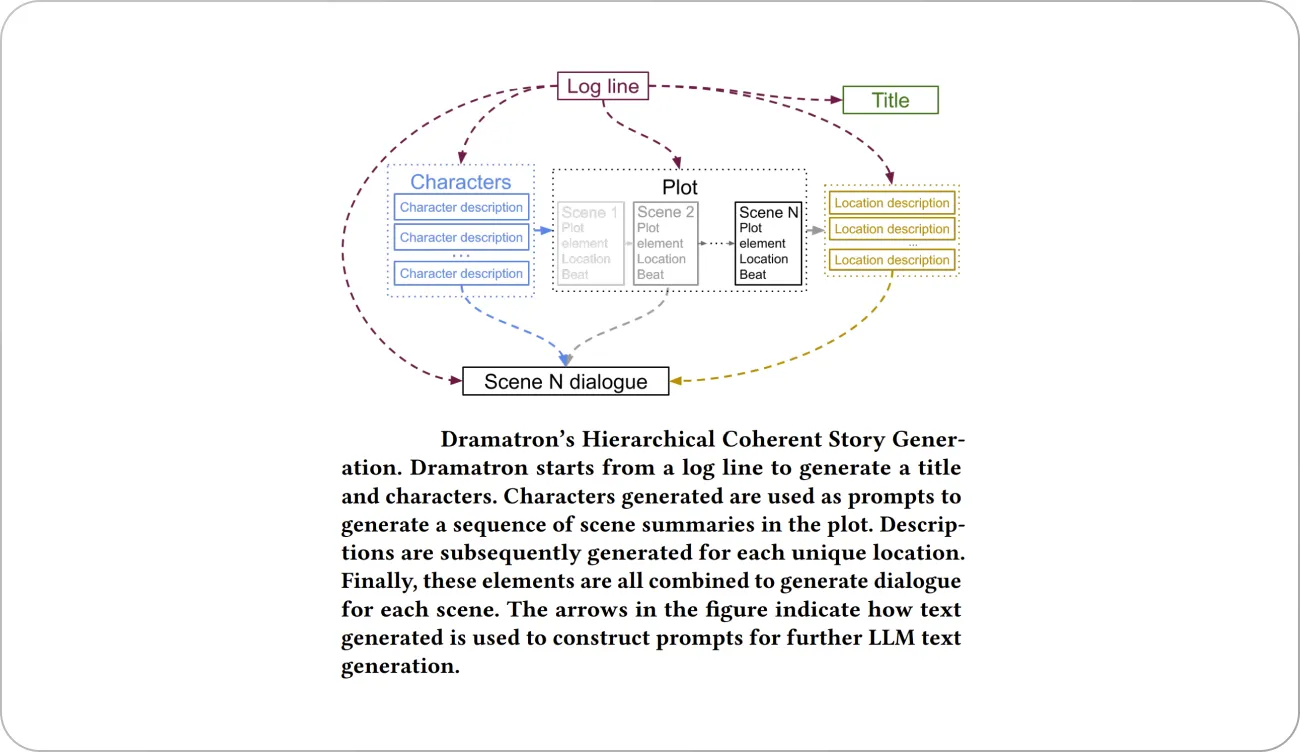
Scientific research
LLMs offer significant assistance in research by supporting literature reviews, idea generation, data analysis, writing, domain-specific knowledge, and collaboration. They can efficiently analyze the vast number of research papers, saving time and providing a comprehensive understanding of existing work. LLMs can generate prompts and explore new research angles, inspiring innovative ideas and hypotheses.
However, LLMs lack the logic that humans have while navigating in the real world. They might provide wrong facts that researchers should critically evaluate. (This paper discusses both the benefits and the ethical issues related to using LLMs for academic research.)
For example, this paper used an ensemble of deep language models (in a supervised learning setup) to classify COVID-19 research publications to assist professionals with up-to-date and trustworthy health information.
Copilot assistants
LLMs can be powerful copilot assistants across various domains, including legal, coding, and design tasks. In these contexts, LLMs can offer valuable support and enhance productivity.
In legal settings, LLMs can assist law practitioners by analyzing and summarizing legal documents, conducting legal research, and providing insights into case law or relevant regulations. They can help draft legal documents, contracts, and briefs, offering suggestions based on their understanding of legal language and precedents.
LLMs can serve as programming assistants, providing code completion suggestions, detecting errors, and offering solutions to coding challenges. They can assist in generating code snippets, improving code readability, and providing documentation on programming languages or libraries.
Chat2VIS (2023) is a design assistant that generates data visualizations using natural language. For this, the authors investigated pre-trained ChatGPT and two types of GPT-3 models. Engineered prompts were fed to the models to get desirable outputs at test time. The overview of Chat2VIS is shown below.
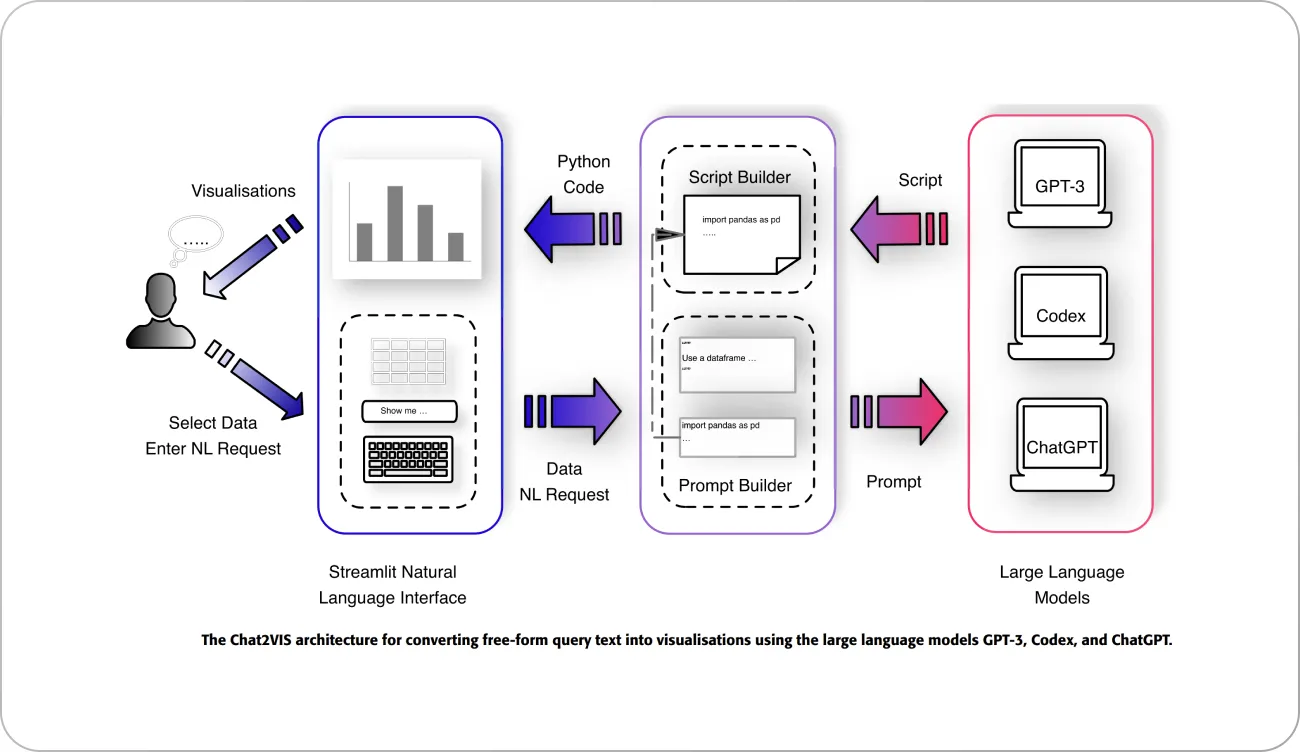
Large Language Models examples
In this section, we will explore some prominent examples of large language models (LLMs) that have significantly contributed to the field of artificial intelligence. These LLMs have captivated researchers and practitioners with their unique language understanding and generation capabilities. From OpenAI's ChatGPT to Google's BERT and other notable models, we will delve into their key features, architectures, and real-world applications.
ChatGPT/OpenAI
ChatGPT (2022) is an advanced conversational AI model developed by OpenAI. It is based on the GPT (Generative Pre-trained Transformer) architecture, which utilizes a deep neural network to generate human-like responses in natural language. ChatGPT is currently one of the most robust networks that can serve as a coding/design copilot, a content co-creator, and a research assistant.
ChatGPT works by leveraging a vast amount of pre-existing textual data from the internet to learn patterns and generate coherent and contextually relevant responses. The model is trained in a two-step process: pre-training and fine-tuning. During pre-training, it learns to predict the next word in a sentence by analyzing large-scale text data. In the fine-tuning stage, the model is refined on specific datasets with human feedback to align its responses with desired behavior and improve its overall performance.
ChatGPT gets a lot of attention mostly due to impressive language generation capabilities. It has garnered attention for its ability to engage in open-ended conversations, provide informative answers, and exhibit a certain level of contextual understanding. It has demonstrated proficiency in various domains, including general knowledge, creative writing, customer support, and more.
However, it is important to note that ChatGPT also has limitations. The model may occasionally generate incorrect or nonsensical responses, be sensitive to input phrasing, exhibit biases in the training data, and struggle with handling ambiguous queries.
OpenAI has made efforts to mitigate these issues, but challenges in fine-tuning such large language models persist.
BERT/Google
Bidirectional Encoder Representations from Transformers or BERT (2018) is a highly influential language model developed by Google. It revolutionized natural language processing by introducing a bidirectional approach, allowing it to consider both preceding and following words when understanding context.
BERT alleviates the unidirectionality constraint by using a “masked language model” (MLM) pre-training objective, which randomly masks some of the tokens from the input, and the objective is to predict the original vocabulary ID of the masked word based only on its context.
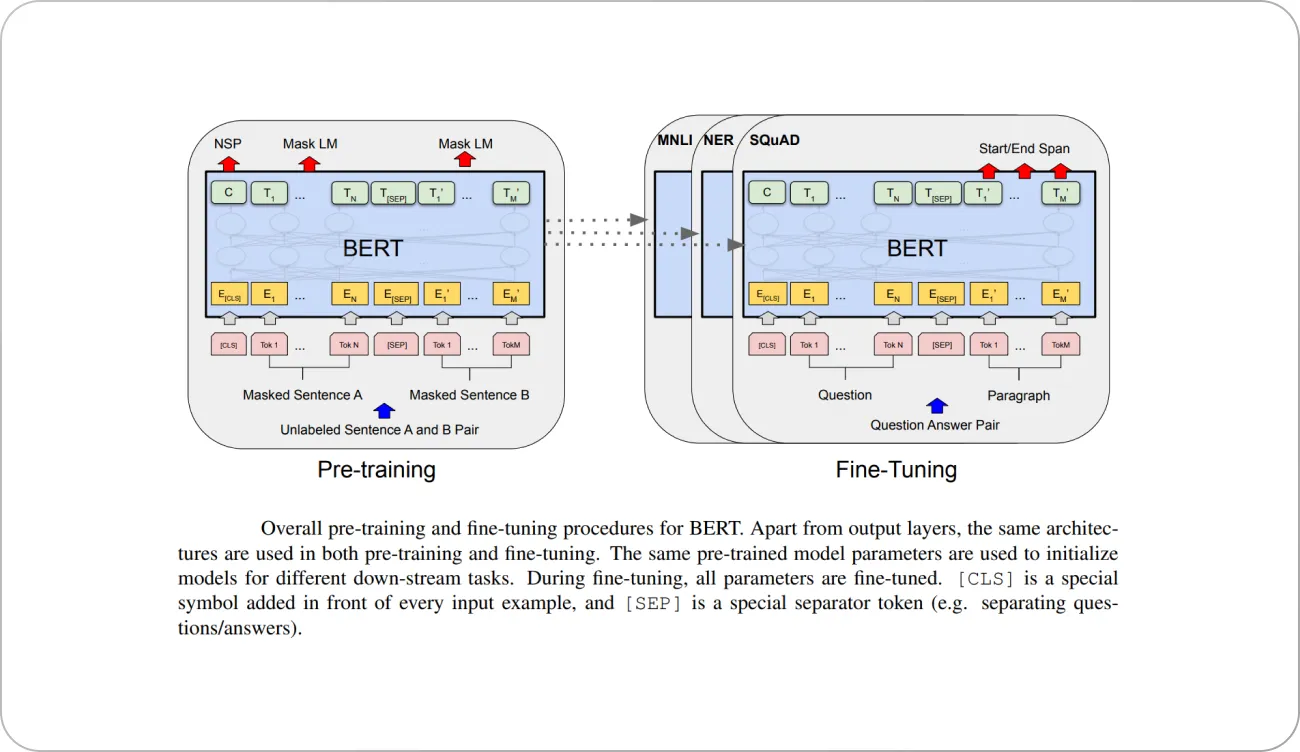
During pre-training, the model is trained on unlabeled data over different pre-training tasks. For finetuning, the BERT model is first initialized with the pre-trained parameters, and all of the parameters are finetuned using labeled data from the downstream tasks. Each downstream task has separate finetuned models, even though they are initialized with the same pre-trained parameters.
BERT can serve as a valuable tool in several applications, but its specific use cases differ from other language models like GPT-3 or ChatGPT. While BERT excels in understanding context and capturing semantic meaning, it has limitations in generating coherent and fluent text.
One of the primary applications of BERT is in natural language understanding tasks, such as sentiment analysis, named entity recognition, text classification, and question answering. It can effectively comprehend and interpret the meaning of the text in these contexts.
Harvey (Legal CoPilot)
Harvey, developed by Ross Intelligence, is a prominent legal co-pilot that supports legal professionals in their research and analysis endeavors. Based on OpenAI's GPT models, Harvey has undergone additional training using comprehensive legal data, encompassing case law and reference materials. This specialized training empowers Harvey with an extensive understanding of the legal domain, enabling it to provide valuable insights and assistance in legal research.
With Harvey's support, legal professionals can streamline contract review processes, enhance the accuracy of due diligence procedures, gain deeper insights into potential litigation outcomes, and ensure regulatory compliance. This enables lawyers to optimize their workflow, allocate their time and resources more efficiently, and deliver timely and comprehensive solutions to their clients.
Harvey, like other legal co-pilots, represents the growing adoption of AI in everyday life, aiming to augment human capabilities and improve the efficiency of legal processes. However, it is important to note that while Harvey can provide valuable insights and suggestions, it does not replace the expertise and judgment of a human lawyer. Legal professionals still play a crucial role in interpreting and applying the information provided by the AI system.
Galileo AI
Galileo AI is an interface design co-pilot that instantly generates UI designs from a text prompt. Interface design co-pilot tools aim to streamline and enhance the design workflow by providing automated suggestions, generating design elements, and offering insights based on best practices and user data.
By working alongside designers, interface design co-pilots help expedite the design process, increase efficiency, and reduce manual iterations. They offer a fresh perspective, creative ideas, and a knowledge base of design principles, allowing designers to make informed decisions while maintaining their creative control.
Runway AI
Runway AI is a platform and toolkit that empowers artists, designers, and creative professionals to explore and utilize artificial intelligence (AI) in their creative projects. It provides a user-friendly interface and a collection of AI models and tools that enable individuals with various levels of technical expertise to harness the power of AI in their creative workflows.
With Runway AI, users can experiment with AI-generated art, create interactive installations, generate music, design immersive experiences, and explore new possibilities across different artistic disciplines. The platform offers diverse AI models, including image and video generation, style transfer, natural language processing, and more.
Runway AI simplifies working with AI models by providing a visual interface, code editing capabilities, and a real-time results preview.
Large language models prompts
Prompting in LLMs, or large language models, refers to giving the model a specific input or instruction to guide its text generation. It involves providing a starting point or context, typically in the form of a written prompt or example sentences. Think of it as giving the model a specific question or topic to focus on before it generates a response.

Example of chain-of-thought prompt reasoning
Prompts help shape the output by influencing the generated text's content, style, and direction. By providing a prompt, users can guide the LLM to generate text that aligns with their desired purpose or intention.
Zero shot reasoning
Zero-shot reasoning in the prompting of LLMs refers to the ability of the model to generate responses or perform tasks without explicit training on that specific prompt or task. It enables the model to generalize its knowledge and apply it to new or unseen scenarios. The model leverages its understanding of language and its broad knowledge base to make educated guesses or generate relevant responses.

Example of zero-shot reasoning
An example of such a prompt is shown above. The LLM is not necessarily trained on this exact prompt, but using its existing knowledge of the English and French languages, it could translate the sentence perfectly.
Img2LLM is a plug-and-play module that enables off-the-shelf LLMs to perform zero-shot Visual Question Answering. The central insight of Img2LLM is that a vision-language model can be utilized along with a question-generation model to translate the image content into synthetic question-answer (QA) pairs, which are fed to the LLM as part of the prompt. These exemplar QA pairs tackle the modality disconnect by describing the image content verbally and tackle the task disconnect by demonstrating the QA task to the LLM.
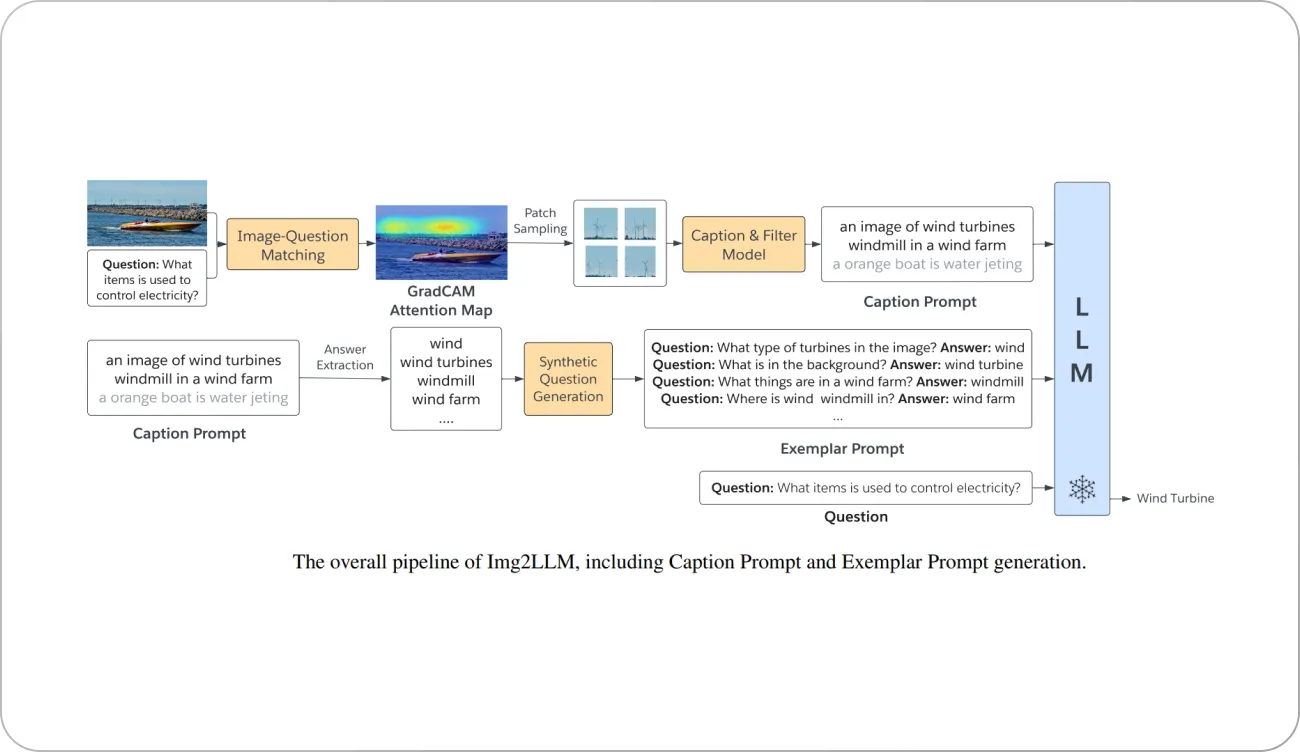
Few shot reasoning
Few-shot reasoning in prompting LLMs refers to the ability of the model to generate responses or perform tasks with minimal training examples or prompts. Unlike zero-shot reasoning, which involves generating responses without explicit training on a specific prompt, few-shot reasoning allows the model to learn from a few examples or prompts.
Pro tip: Read our step-by-step guide to few-shot learning to learn more.
With few-shot reasoning, the LLM can generalize from limited training data and apply that knowledge to new prompts or tasks. By exposing the model to a few relevant examples, it can learn to make informed predictions or generate contextually appropriate responses.
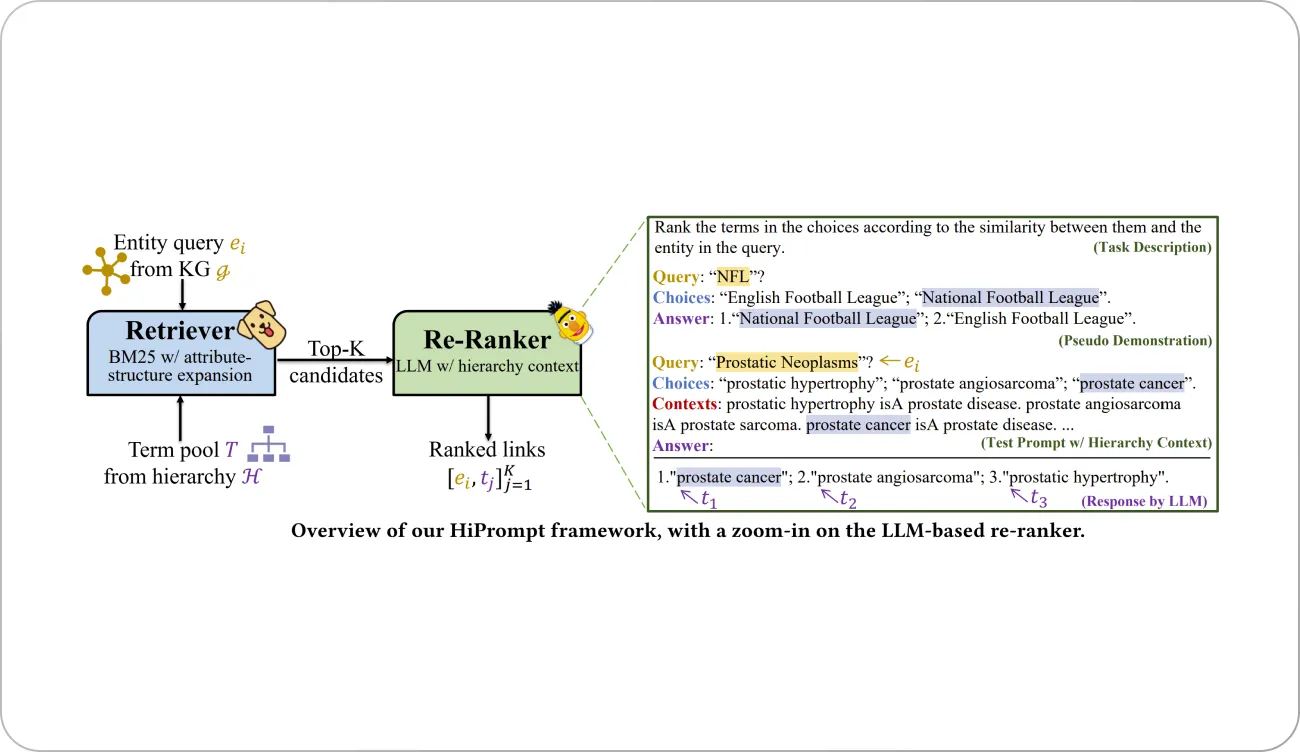
HiPrompt is an interesting model that employs the few-shot reasoning capabilities of LLMs to develop a supervision-efficient biomedical knowledge fusion (BKF) framework via Hierarchy-Oriented Prompting. The key insight of HiPrompt is that LLMs can be rapidly adapted to an unseen task via gradient-free prompt-based learning, removing the dependencies on task-specific supervision.
Pro tip: Learn how AI is revolutionizing digital pathology and radiology applications.
HiPrompt applies prompt-based learning with a curated task description for the BKF task and a few demonstrations generated from the few-shot samples. This mimics the procedure of how humans accomplish a new task by learning from previous experiences and generalizing them to a new context. Moreover, the hierarchical context added to the prompts further improves the performance of HiPrompt.
Chain of thought prompting
Chain-of-thought reasoning involves providing a sequence of prompts to guide the LLM’s text generation. The prompts are typically related and build upon each other, allowing the model to exhibit a coherent and logical progression of thoughts or ideas. Each subsequent prompt relies on the generated text from the previous step, creating a chain of interconnected reasoning.

Example of chain-of-thought reasoning prompt
In the example shown above, each subsequent prompt builds upon the previous one, creating a chain of interconnected prompts that guide the LLM in generating a coherent and logical narrative. The prompts follow the sequence of events in a detective story, starting from the initial encounter with the crime scene, progressing through evidence gathering and investigation, and ending with the mystery's resolution.
This paper developed a Zero-Shot Chain of Thought (CoT) pipeline that differs from the original chain of thought prompting as it does not require step-by-step few-shot examples. The core idea of the method is to add “Let’s think step by step” or a similar text to extract step-by-step reasoning. The Zero-shot-CoT method uses prompting twice to extract both reasoning and answer, as shown in the schematic below.












Limitations of Large Language Models
While LLMs have achieved remarkable milestones, it is crucial to acknowledge their limitations, boundaries, and potential risks. Understanding these limitations empowers us to make informed decisions about the responsible deployment of LLMs, facilitating the development of AI that aligns with ethical standards. We will explore constraints such as context windows, issues of bias, accuracy, and outdated training data that impact LLMs' performance and usability. We will also explore data risks and ethical considerations associated with their use.
Context windows
Context windows in LLMs limit the amount of previous text the model considers when generating the next token. This limitation hampers the model's ability to capture long-term dependencies, comprehend the broader context, and maintain coherence in the text. Important information beyond the context window may be excluded, leading to incomplete understanding and potentially inaccurate or contextually inappropriate responses.
The restricted view of the text limits the model's capacity to grasp nuanced relationships and syntactic structures, hindering its overall comprehension and generation capabilities.
Cost
Training and running LLMs require substantial computational power, including specialized hardware and extensive time for training and inference. These resources come with associated costs, making LLMs inaccessible to individuals or organizations with limited resources.
Additionally, fine-tuning or customizing LLMs for specific tasks can require significant data annotation efforts, further adding to the cost. The high computational and financial requirements can pose barriers to entry and restrict the widespread adoption and usage of LLMs, particularly for smaller-scale projects or applications with limited budgets.
Accuracy
Accuracy is a limitation for LLMs, including ChatGPT, as they can occasionally produce incorrect or unreliable outputs. Despite their impressive performance, LLMs are prone to errors due to biases in the training data, lack of common sense reasoning, and the model's reliance on statistical patterns. They may generate plausible but false information or struggle to comprehend complex or nuanced prompts.
The limitations in contextual understanding and the potential for misinformation pose challenges in achieving consistently accurate results. Ongoing research and advancements are necessary to improve the accuracy of LLMs and mitigate these limitations for more reliable and trustworthy output.
Outdated training data
The reliance of LLMs on training data poses the risk of potentially outdated information. For example, ChatGPT cannot accurately answer questions that require knowledge of the world post-2021.
LLMs are typically trained on vast datasets collected from the internet, which may include information that becomes obsolete over time. As a result, the models may generate responses or recommendations that are no longer accurate or relevant. This limitation is particularly significant for rapidly evolving domains, such as technology or current events.
Keeping LLMs up to date requires regular retraining or fine-tuning with the latest data, which can be extremely resource-intensive. Failure to address the issue of outdated training data may lead to misleading or incorrect information being generated by the models.
Data risks
Data risks represent a limitation for LLMs due to potential challenges associated with data quality, privacy, and bias. LLMs heavily rely on large training datasets, which can introduce biases present in the data. Biased training data can lead to biased or unfair responses generated by the models.
Additionally, using sensitive or personal data in training LLMs raises privacy concerns. Such data must be handled and stored carefully to ensure compliance with privacy regulations and protect user information. Furthermore, the vast amount of data required for training LLMs can contribute to environmental concerns, such as increased energy consumption and carbon emissions. Managing and mitigating these data-related risks is crucial for LLMs' responsible and ethical deployment.
Tutorial: Training Large Language Models
From data collection and preprocessing to model configuration and fine-tuning, let us explore the essential stages of LLM training.
Whether you are an aspiring researcher or a developer seeking to harness the power of LLMs, this tutorial will provide a step-by-step guide to train your language model.
Data collection and datasets
LLM training involves gathering a diverse and extensive range of data from various sources. This includes text documents, websites, books, articles, and other relevant textual resources. The data collection process aims to compile a comprehensive and representative dataset that covers different domains and topics.
High-quality and diverse datasets are essential to training LLMs effectively, as they enable the model to learn patterns, relationships, and linguistic nuances to generate coherent and contextually appropriate responses. Data preprocessing techniques, such as cleaning, formatting, and tokenization, are typically applied to ensure the data is in a suitable format for training the LLM.
Model configuration
This stage involves defining the architecture and parameters of the model. This includes selecting the appropriate model architecture, such as transformer-based architectures like GPT or BERT, and determining the model size, number of layers, and attention mechanisms.
The model configuration step aims to optimize the model's architecture and parameters to achieve the desired performance and efficiency. Additionally, hyperparameters such as learning rate, batch size, and regularization techniques are set during this stage. Experimentation and fine-tuning of these configurations are often carried out to find the optimal balance between model complexity and computational requirements. The chosen model configuration significantly influences the LLM's ability to learn and generate high-quality outputs during subsequent training phases.
Model training
Like any other deep learning model, the curated dataset is fed into the configured LLM, and its parameters are iteratively updated to improve performance. During training, the model learns to predict the next word or sequence of words based on the input it receives. This process involves forward and backward propagation of gradients to adjust the model's weights, leveraging optimization techniques like stochastic gradient descent.
Training is typically performed on powerful hardware infrastructure for extended periods to ensure convergence and capture the patterns and relationships present in the data. The model training stage is crucial for refining the LLM's language understanding and generation capabilities.
Fine-tuning of Large Language Models
This stage involves customizing a pre-trained LLM on a specific task or domain by training it on a smaller, task-specific dataset. This process enhances the model's performance and adaptability to the target task. Fine-tuning typically involves training the LLM with a lower learning rate and fewer training steps to prevent overfitting.
By exposing the LLM to domain-specific data, it learns to generate more accurate and relevant responses. Fine-tuning allows LLMs to be applied to various specialized tasks while leveraging the general language understanding and generation capabilities acquired during pre-training.
Future of Large Language Models
Although ChatGPT is revolutionary, I would not recommend asking it for medical advice. But how long before AI can help us achieve even that? How much more accurate do LLMs need to be? These are the questions that researchers are trying to answer right now.
As large language models (LLMs) continue to advance, the future holds immense possibilities for their development and application. Improved contextual understanding, enhanced reasoning abilities, and reduced biases are some of the key areas of focus for the ongoing research and innovation of future LLMs.
Additionally, efforts are being made to address LLMs' ethical implications and challenges, such as data privacy, fairness, and transparency. Collaborative efforts between researchers, developers, and policymakers will shape the future of LLMs, ensuring their responsible and beneficial integration into various domains, including healthcare, education, customer service, and creative content generation.

Rohit Kundu is a Ph.D. student in the Electrical and Computer Engineering department of the University of California, Riverside. He is a researcher in the Vision-Language domain of AI and published several papers in top-tier conferences and notable peer-reviewed journals.

