21 min read
—

Can AI-generated art resonate with humans? Can we call it "art" at all? Learn about AI-generated art, see some examples, and answer the questions yourself!

Art has always been a staple in human culture, ever since the first cave paintings.
It's a way for us to express ourselves and tell stories.
In recent years, there have been advances in artificial intelligence (AI), and people have been exploring its possible applications in various domains, including art. Yet, comprehension and appreciation of art are widely considered exclusively human capabilities.
In this article, we will explore how bringing AI into the loop can foster not only advances in the fields of digital art and art history but also inspire our perspectives on the future of art itself.
Here’s what we’ll cover:
A brief history of AI-generated art
How AI algorithms are able to create art
Challenges associated with AI-generated art
Examples of best AI art generators and AI artwork

AI for document processing
Put AI agents to work on real business tasks
Get started today

AI-generated abstract landscapes. Source: Robbie Barrat’s art-DCGAN
A brief history of AI-generated art
First off, let’s clear things up a bit. “AI and art” can generally understood in two ways:
AI in the process of analyzing existing art
AI in the process of creating new art
We’re focusing on the second category, where AI agents are the ones generating new artistic creations. Let us look at the evolution of AI-generated art.

Source: Paper
The history of AI-generated art can be traced back to the early days of computer graphics and the invention of the computer.
In the 1950s and 1960s, computer graphics were used to generate simple patterns and shapes. These early examples of AI-generated art were created using basic algorithms to create patterns that were rendered on a computer screen.
For example, a German mathematician and scientist Frieder Nake created a portfolio in 1967 named “Matrix Multiplications,” consisting of twelve images, one of which you can see below.

Untitled (1967), by Frieder Nake. Source
Nake produced a square matrix and filled it with numbers, which were multiplied successively by itself, and the resulting new matrices were translated into images of predetermined intervals.
Each number was assigned a visual sign with a particular form and color. These signs were then placed in a raster according to the values of the matrix. Nake commonly used random number generation in his work of this period, and, likely, his multiplication process was partly automated.
In the 1970s and 1980s, AI-generated art began to be used more extensively in computer-aided design (CAD).
CAD software allows designers to create and manipulate three-dimensional shapes on a computer. This allowed for more complex and realistic images to be created. For example, in 1973, artist Harold Cohen developed a set of algorithms, collectively known as AARON, that allowed a computer to draw with the irregularity of freehand drawing.
AARON was programmed to paint specific objects, and Cohen found that some of his instructions generated forms he had not imagined before. He found that he had set up commands that allowed the machine to make something like artistic decisions.
Initially, AARON created abstract paintings, which grew to be more complex art through the 1980s and 1990s, including (chronologically) drawings of rocks, plants, and humans. One such example is shown below.

Painting made by AARON, developed by Harold Cohen, Source
In the 1990s, AI-generated art began to be used for more than just visual effects. Artists started using AI algorithms to generate music and create new forms of poetry. AI-generated art also began to be used in the field of robotics. Robots were programmed to create paintings and sculptures.
Today, AI-generated art is used in various fields, including advertising, architecture, fashion, and film. AI algorithms are used to create realistic images and animations. AI-generated art is also used to create new forms of music and poetry.
One interesting example of recent AI used for creating art is the “Artificial Natural History” (2020), which is an ongoing project that explores speculative, artificial life through the lens of, what the author Sofia Crespo calls, a “natural history book that never was.”
Crespo essentially formed a distorted series of creatures with imagined features that require entirely new sets of biological classifications. Such art plays with the endless diversity that nature offers, of which we still have limited awareness. Examples of AI-generated specimens in Artificial Natural History are shown below.

AI-generated specimens in Artificial Natural History
How AI is used to create art, including the use of algorithms and neural networks
There are various ways in which AI is used to create art.
AI algorithms can generate images or videos based on a set of parameters or create new images by combining and altering existing images. Neural networks can be used to create images or videos that mimic the style of a particular artist or to create images or videos that are similar to a particular type of art.
The go-to technique for generating new artwork using the style of other existing art is through Generative Adversarial Networks. The method of transferring the style of an art piece to another art, when accomplished using Deep Neural Networks, is called neural style transfer (NST).
The primary idea behind NST, which was first proposed in this paper in 2015, is that to obtain the representation of the style of an input image, a feature space originally designed to capture texture information is used.
This feature space is built on top of the filter responses in each layer of the network. It consists of the correlations between the different filter responses over the spatial extent of the feature maps. By including the feature correlations of multiple layers, the authors obtained a stationary, multi-scale representation of the input image, which captures its texture information but not the global arrangement.

Source: Paper
The authors found out through experiments that the representations of content and style in the CNNs are separable. That is, both representations can be manipulated independently to produce new, perceptually meaningful images. This finding has been the underlying basis for all successive methods proposed in the literature for Neural Style Transfer used in AI-generated art.
Apart from the neural style transfer, there are other algorithms that can create AI art—
One of the most revolutionary algorithms that use AI for creating new art is DALL·E 2 by OpenAI. DALL·E 2 generates images using only a textual prompt given by the user. In a later section, we will discuss the architecture and capabilities of DALL·E 2 in further detail.
GANs
Generative Adversarial Networks (GANs), proposed in 2014 in this paper, are typically composed of two neural networks pitted against one another to make both of them better learners.
Suppose we have to generate new images to augment a dataset for image classification. One of the two networks is called a generator, the deep network that outputs new images. The other network is called a discriminator and its job is to classify whether the image given to it as input is an original or a fake image created by the generator.
In successive iterations, the generator tries to mimic the original images more closely to fool the discriminator, while the discriminator tries better to distinguish the real images from the fake. This adversarial game (minimax problem) trains both networks. Once the training loop is complete, the generator can output realistic images (almost indistinguishable from the original), and the discriminator has become a good classifier model.
Some of the popular applications of GANs are to generate:
Fonts
New engaging (and consistent) fonts can also be generated using GANs for write-ups, like that proposed in this paper.

Examples of generated fonts. Source: Paper
Human faces
For illustrations, movie characters, etc., which alleviates privacy concerns. This website shows images of human faces that don’t actually exist because the images are created using the StyleGAN2 model. An example is shown below.

Source: Website
Cartoon/Anime characters
GANs have also been used to generate cartoon and anime characters. This enables writers to get new ideas on character drawings and even create scenes without drawing each frame (of the video sequence) for their episodes.

Anime faces generated in this paper
Sketches
Generating sketches using GANs has several advantages like augmenting models with multimodal data for style transfer, super-resolution, etc. They can also be used as the base structure for creating more complicated art.

Generated sketches using the SkeGAN model
Benefits and challenges of AI-generated art
Now, let’s have a look at pros and cons of using AI to create art, and address a couple of baffling questions.
Some benefits of AI-generated art include:
Generation of realistic or hyper-realistic data
Images of Videos generated using AI can be used in movies, especially for supernatural scenes which cannot be enacted in real life.
Some of the art may be Impossible for humans to create
AI “thinks” outside the box to generate never-seen-before samples, some of which might even be hard or impossible for humans to think about. Such art can even be an inspiration for more significant projects, i.e., they can help one get new ideas.
Constantly evolving
The art generated by AI is ever-evolving together with the development of AI models and the evolution of the data provided to such models to train on. This allows novel ideas to flow without stagnating at a saturation point.
Some challenges of AI-generated art include:
Lack of human touch
Although AI creates realistic images that will easily fool any human, it lacks the human emotions behind making an artistic piece and the story behind the art. This might be a dealbreaker for many people in accepting AI-generated art.
Art may be repetitive or boring
AI does not generate new art without support. We give it data that we already have for it to train. So, in a way, all the art it produces is derived (but it has derived from so many sources that it technically becomes new art). Thus, a model that has been trained only once and the training process is never updated with newly available data may produce repetitive art that can potentially be uninteresting. However, new techniques like Zero-Shot Learning or Self-Supervised Learning can train existing models with newly available data without retraining the model from scratch.
Lack of control over the final product
We do not have any control over the creative process since, once we train the model, it’ll output products based on its trained weights. We cannot manually fine-tune it during the process.
Ethical concerns
We might have no control over the finished product regarding its distribution, copyrights, use, or misuse. Furthermore, AI-generated art can be used to create realistic images or videos that make people believe something untrue. Thus, it is debatable whether its widespread accessibility is a boon or a curse.
There are two main questions that baffle people when talking about AI-generated art:
Can you sell AI-generated art?
Yes, you can sell the art generated by their AI models. AI-generated art is one of the fastest-growing Non-Fungible Tokens (NFTs). So, anyone can create art using AI and sell it as an NFT on various marketplaces. There are several examples of popular sales of AI-generated art.
For example, the art shown below by an arts-collective “Obvious” titled “Edmond de Belamy” sold for USD 432,000 in October 2018. Although an AI model created the portrait, the money was earned by humans, i.e., the art collective was credited for the painting. This paper studied the entity that should get credit for the art generated by AI algorithms.

Source: Wikipedia
If AI-generated NFTs are your cup of tea, you may want to have a look at AImade.art—a collection of AI-generated NFT artworks.
Should AI-generated art be copyrighted?
This is a tricky question since everyone has different views on it. Some countries have enabled copyright protection for AI-generated art, while others do not approve of the same.
On the one hand, the argument goes that the algorithm is the one doing the work, so it can be easily reproduced by others, thus nullifying copyright claims.
On the other hand, the same AI algorithm will be producing different art based on the training data fed by the artists.
Thus, this question has no “correct” answer yet. Nevertheless, as of now, AI-generated art is copyright free.











Examples of the best AI-generated Art and Generators
In this section, we will have a closer look at some of the available tools for AI-generated art and show examples of how they work.
Many of these tools are open-sourced, so you can potentially train your models or use the existing ones (some are free to use for a limited number of times) to create your art using AI.
Images/Drawings
Most recent AI-generated art approaches have experimented on image data- realistic images and drawings. In this section, we will discuss a few of the most popular AI models currently available for image generation.
DALL·E 2
DALL·E 2 is a recent groundbreaking Deep Learning algorithm that can generate original, realistic images and art from descriptions provided using natural language (text).
It was created and released by OpenAI in January 2021. It is an improved version of the original DALL·E algorithm, which was released in December 2020. DALL·E 2 can also edit existing images and create variations of provided images while retaining their discriminating features.
The DALL·E 2 model, proposed in this paper, combines two notable approaches for the problem of text-conditional image generation—
The CLIP model, which is a successful representation learner for images, and diffusion models, which are generative modeling frameworks that have achieved state-of-the-art performance in image and video generation tasks.
DALL·E 2 consists of a diffusion decoder to invert the CLIP image encoder. The model’s inverter is non-deterministic and can produce multiple images corresponding to a given image embedding.
The presence of an encoder and its approximate inverse (the decoder) allows for capabilities beyond text-to-image translation. The high-level architecture of the DALL·E 2 model is shown below.
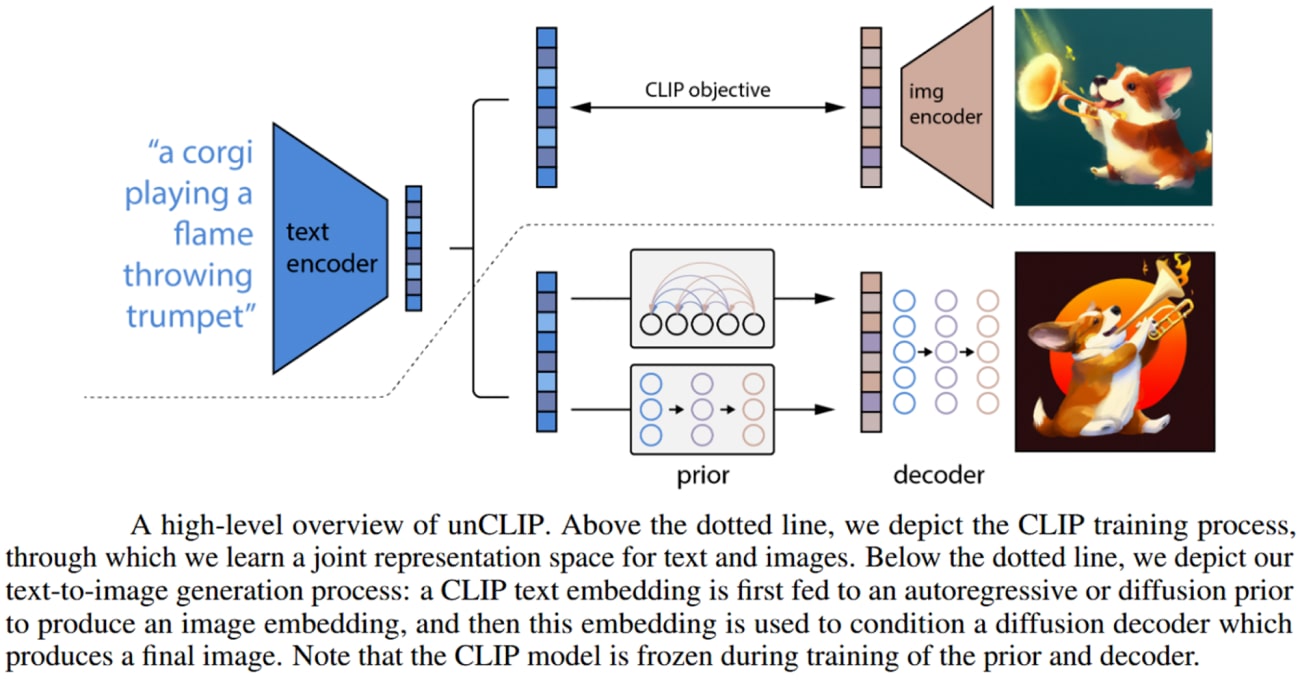
Source: Paper
One notable advantage of using the CLIP latent space is the ability to semantically modify images by moving in the direction of any encoded text vector, whereas discovering these directions in GAN latent space involves luck and diligent manual examination.

Source: Paper
Some potential practical applications of DALL·E 2 include:
Creating photo-realistic 3D renderings
Generating images for advertising or product design
Creating new art or visualizations
Let’s look at some examples of AI-generated art by DALL·E 2 using textual captions:
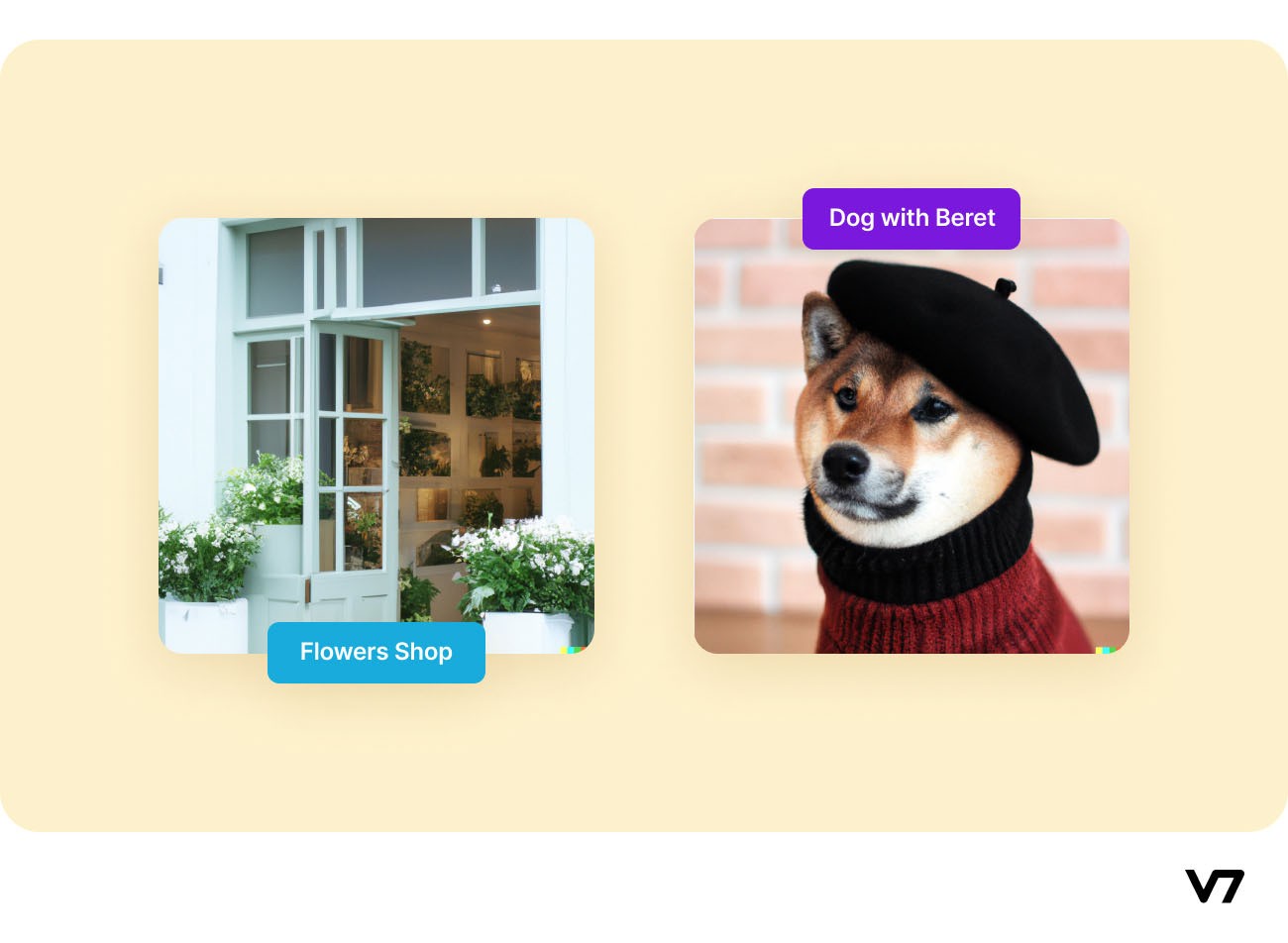
“A photo of a quaint flower shop storefront with a pastel green and clean white facade and open door and big window” on the left and “A Shiba Inu wearing a beret and black turtleneck” on the right
Following are examples of artwork generated by DALL·E 2 using natural text captions:

On the left: “An espresso machine that makes coffee from human souls,” Source: Paper On the right: “A dolphin in an astronaut suit on Saturn,” Source: Paper
DALL·E 2 can also interpolate between input images by inverting interpolations of their image embeddings. DALL·E 2 does this by rotating between the CLIP embeddings of the two images using spherical interpolation, yielding intermediate CLIP representations and decoding using a diffusion model.
The intermediate variations naturally blend the content and style from both input images. Examples of such interpolated images are shown below.


Source: Paper
A key advantage of using CLIP embeddings compared to other models for image representations is that it embeds images and text to the same latent space, thus allowing us to apply language-guided image manipulations.
To modify the image to reflect a new text description, DALL·E 2 first obtains its CLIP text embedding and the CLIP text embedding of a caption describing the current image. Then a text diff vector is computed from these by taking their difference and normalizing it.
Examples of this are shown below.

Source: Paper
A lot more examples of DALL·E 2’s artwork are available on the model’s dedicated Instagram page. YOu can also play around with DALL·E 2’s little brother, DALL·E Mini to create AI-generated art from the text of your own.
And if DALL·E 2 sparked your interest enough to make you wonder if it can replace humans, watch this video:

Stable Diffusion
Stable Diffusion is a revolutionary text-to-image model much like the DALL·E 2 model, with one very significant difference—it is open source (unlike DALL·E 2)—that is, the original source code can be used and redistributed for free, and others can take inspiration from the source code to make their own models.
The framework was made collaboratively by the Machine Vision and Learning Group, Stability AI, and Runway. The entire implementation of Stable Diffusion is available in GitHub, where anyone with the basic knowledge of python can execute the code (full instructions for running the codes have been generously provided by the authors) and generate their own images for free.
Latent Diffusion Model
Stable Diffusion builds on the Latent Diffusion Model (LDM) proposed by the Machine Vision and Learning Group in 2022, which was built for high-resolution image synthesis. The authors’ aim with the LDM was to first find a perceptually equivalent, but computationally more suitable space, in which diffusion models were trained for high-resolution image synthesis. An overview of the LDM framework is shown below.
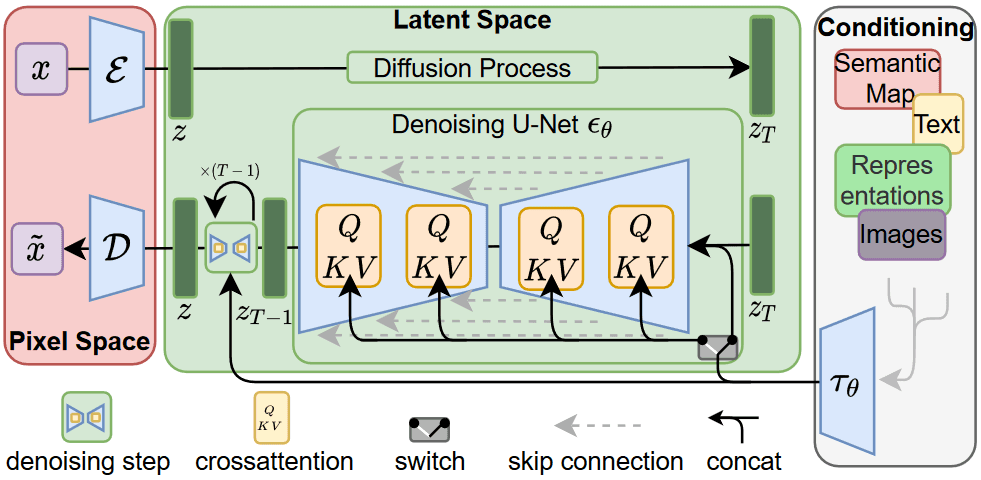
Overview of the Latent Diffusion Model. Source: Paper
A notable advantage of this approach is that we need to train the universal autoencoding stage only once and can therefore reuse it for multiple diffusion models’ training or to explore possibly completely different tasks. This enables efficient exploration of a large number of diffusion models for various image-to-image and text-to-image tasks. For text-to-image tasks, the authors designed an architecture that connects transformers to the diffusion model’s UNet backbone and enables arbitrary types of token-based conditioning mechanisms.
Stable Diffusion Architecture
The Stable Diffusion framework trains a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database. It uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts and a UNet autoencoder. Stable Diffusion is essentially a LDM conditioned on the non-pooled text embeddings of a CLIP ViT-L/14 text encoder.
Dream Studio
DreamStudio is the official team interface and API for Stable Diffusion. Users do not need any knowledge of Python for using Stable Diffusion, thanks to DreamStudio. Entering the textual prompt in the DreamStudio interface generates the images within a few seconds. DreamStudio gives 50 free uses just by signing up with an email address.
Examples of images generated from text prompts using the Stable Diffusion model through the DreamStudio software are shown below.

“Humans approach the black hole”

“Mediaeval time in Anime”

“The earth is on fire, oil on canvas”

“Birdhouse”
Imagen
Imagen is a recently developed text-to-image diffusion model by Google Brain. Imagen comprises a T5-XXL encoder to map input text into a sequence of embeddings and a 64×64 image diffusion model, followed by two super-resolution diffusion models for generating upscaled 256×256 and 1024×1024 images.
All diffusion models are conditioned on the text embedding sequence and use classifier-free guidance. Imagen relies on new sampling techniques to allow usage of large guidance weights without sample quality degradation observed in prior work, resulting in images with higher fidelity and better image-text alignment than previously possible. An overview of the Imagen model is shown below.
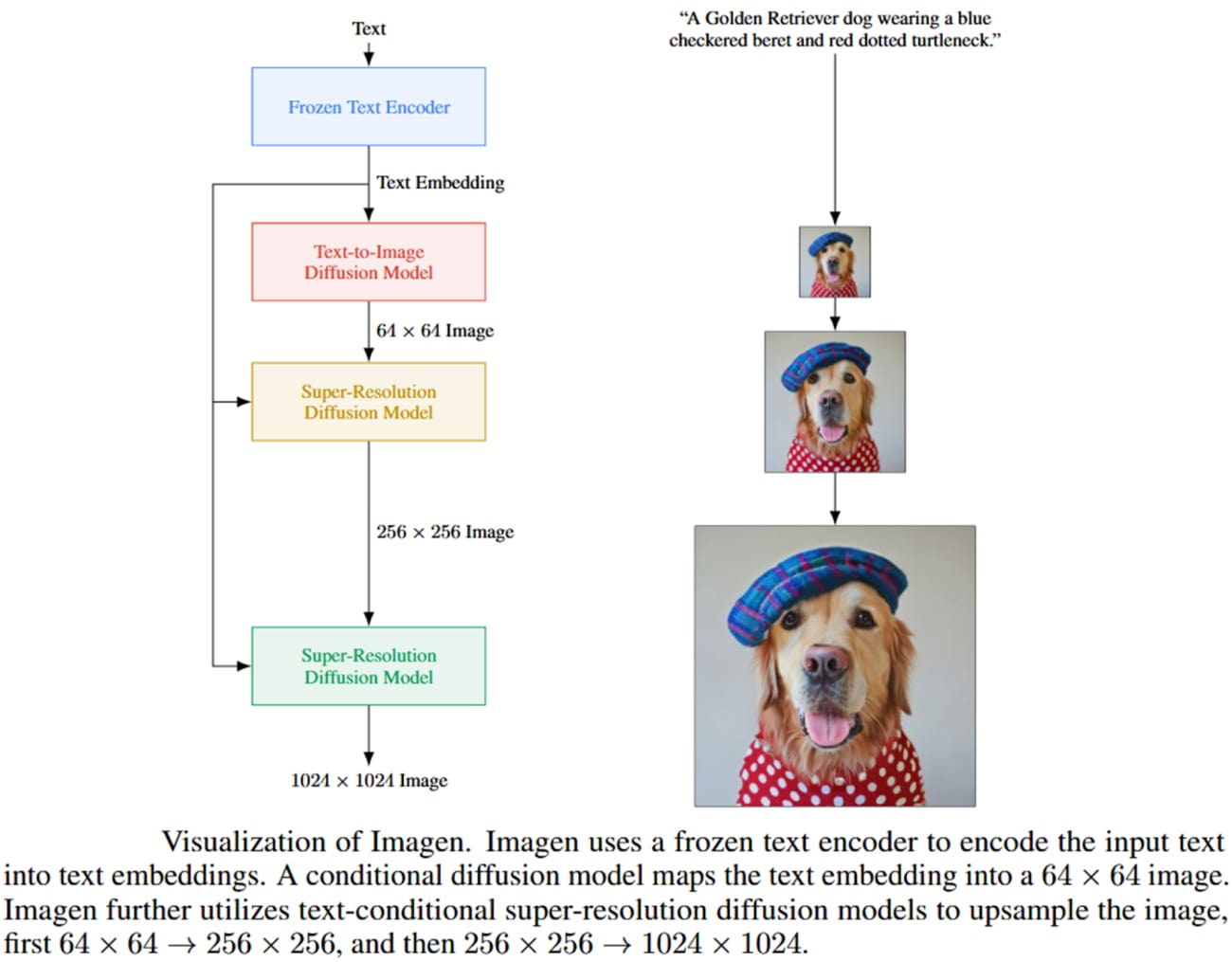
Source: Paper
A few examples of images generated by Imagen are shown below.

From the left 1) “Android Mascot made from bamboo.” Source 2) “A single beam of light enters the room from the ceiling. The beam of light is illuminating an easel. On the easel, there is a Rembrandt painting of a raccoon.” Source 3) “A dog looking curiously in the mirror, seeing a cat.” Source
WOMBO Dream
WOMBO Dream is an AI artwork application where you enter a textual prompt and choose an art style to generate a new artistic image.
It is built upon two AI models- VQGAN and CLIP. VQGAN is a deep learning model used to generate images that look similar to other images (neural style transfer). CLIP is a deep model trained to determine the similarity between a natural text description and an image.
CLIP provides feedback to VQGAN on how best to match the image to the text prompt. VQGAN adjusts the image accordingly and passes it back to CLIP to check how well it fits the text. This iterative process is repeated several times, and the final image is output as a result.
An example of the WOMBO Dream app’s output given a text prompt through the iterations is shown below.
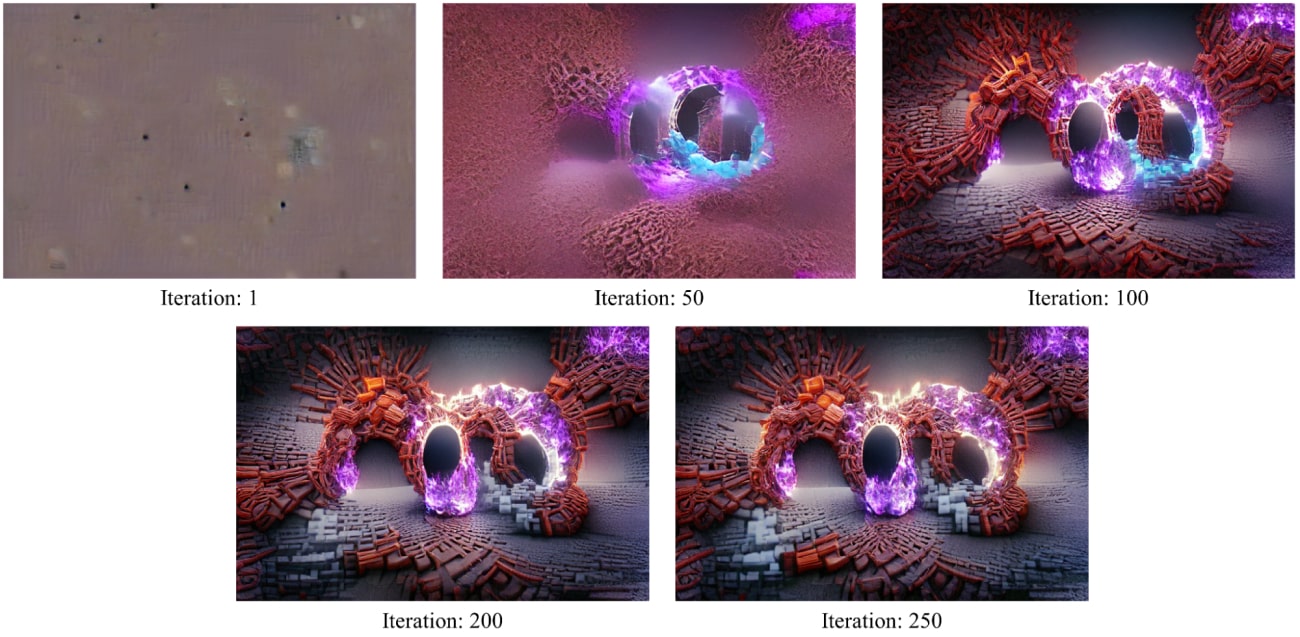
Source: Jen Kleinholz
DeepDream Generator
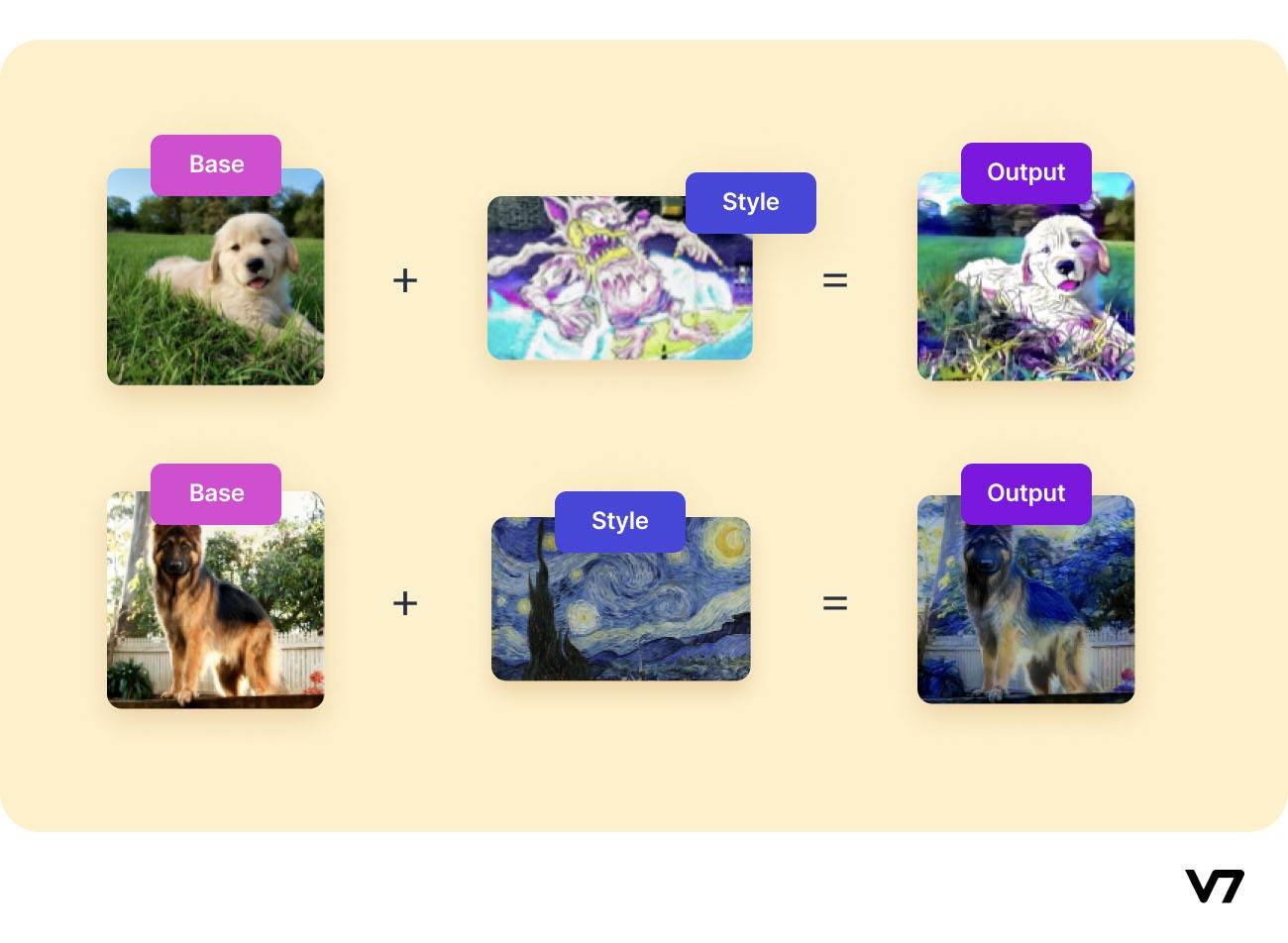
DeepDream Generator is another project of Google that takes in an input image like all other generators we have seen till now and uses different styles to output a dreamy, psychedelic image, which portrays the bizarre things we “dream” about. This is yet another example of Neural Style Transfer.
Examples of images generated using the DeepDream Generator (which has been made public for generating your images) are shown below.
Artbreeder
Artbreeder is a collaborative AI-based website that allows users to generate and modify their portrait and landscape images.
Users can combine multiple images to create new ones effortlessly. At its core, there are two GAN-based models at play- the StyleGAN and BigGAN models.
An example of the capabilities of Artbreeder is shown below:

Music & Sound
The capabilities of AI-generated art range beyond just drawings—
Jukebox
Deep generative models can now produce high-fidelity music. For example, Jukebox by OpenAI is a model that generates music with singing in the raw audio domain with long-range coherence spanning multiple minutes.
Jukebox uses a hierarchical VQ-VAE architecture to compress audio into a discrete space, with a loss function designed to retain the maximum amount of musical information at increasing compression levels. The overview of the Jukebox model is shown below.
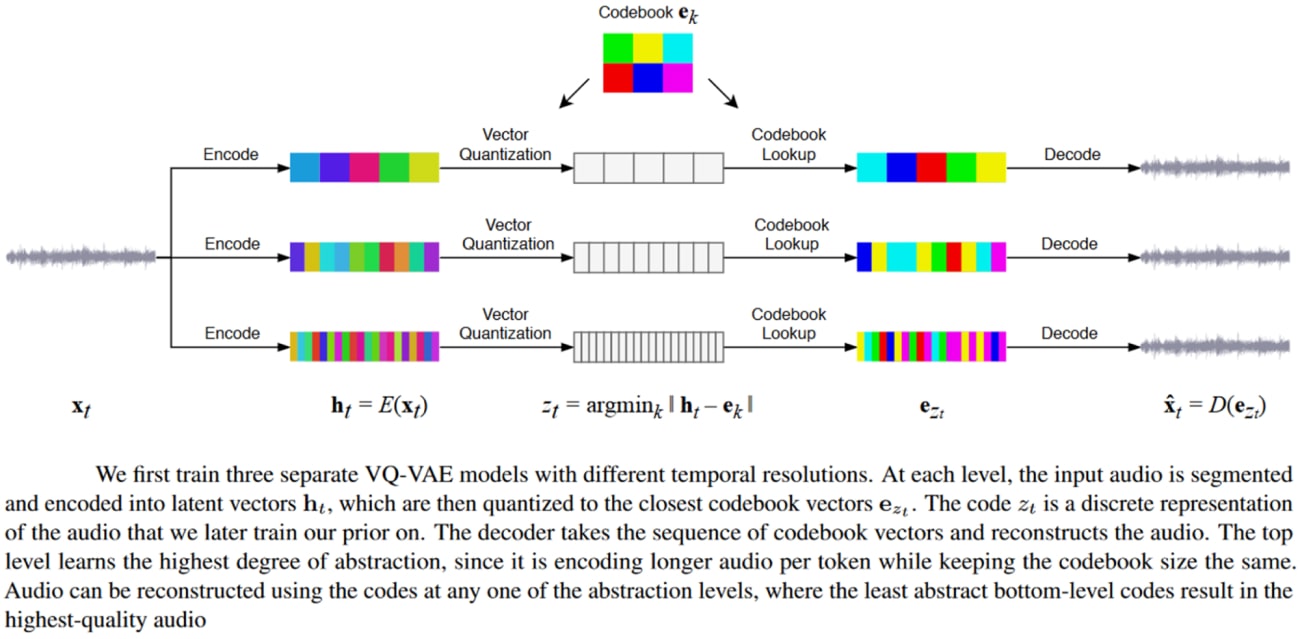
Source: Paper
AIVA
The AIVA application allows users to compose music using AI. There are several famous AI songs, like Bored With This Desire To Get Ripped, Deliverance Rides, and many more. Some of these AI-generated songs even have the voice of famous singers (although they never actually sang them).


Movement & Dance
Dance choreography is an especially difficult endeavor since it is not simplistic to “describe” dance. It is highly dependent on style, emotion, and technique.
Choreography is the purposeful arrangement of sequences of motion. The basic building block is the change of position in a 3D space. Capturing dance data is done by using a technique for Human Pose Estimation, which reduces the dimensionality of the captured data by several folds, allowing AI models to be trained on them with a lesser computational burden.
Check out this Comprehensive Guide to Human Pose Estimation.
However, AI has even been able to generate choreographic pieces, one early example of which is the chor-rnn model developed in 2016. At the core of chor-rnn is a deep recurrent neural network trained on raw motion capture data that can generate new dance sequences for a solo dancer.
Many new techniques have been proposed in the recent literature, including AI-generated 3D choreography.
To learn more about AI and choreography, you can visit: Body, Movement, Language: AI Sketches With Bill T. Jones

Movies
Writing a script for a film can be viewed as a Natural Language Processing (NLP) task. AI can even write entire screenplays. For example, in 2016, a short science fiction film titled “Sunspring,” directed by Oscar Sharp, had its script written entirely by AI.

One of the most revolutionary NLP models is the Generative Pre-trained Transformer-3 (GPT-3) architecture. It is a 175 billion parameter autoregressive language model that can generate human-like text with fantastic coherence.
GPT-3 has been extensively used to write screenplays, poems, etc. In this paper, researchers create an AI model that can produce movie trailers automatically. Their model can create a fitting, emotionally-captivating trailer (video) for any movie without major spoilers.
Stories
Much like images, entire stories can be generated using the AI models we have by supplying a prompt that describes the theme and some high-level information about the story you want the AI model to write.
For example, Tristrum Tuttle has a trained GPT-3 model for writing a story along with its title using the prompt: “Write the beginning to a short, fictional story about a child that is afraid of Artificial Intelligence but then makes friends with a robot.”
You can read the story in full here: The Day I Became Friends with a Robot by Tristrum Tuttle
Summary
The potential of AI as artists has significantly increased in the past few decades—from creating hyper-realistic images to writing movies. Generative models are extensively used to accomplish these tasks, which, when fed with enough training data, can generate novel data.
However, there are concerns regarding the creations of AI-generated art (apart from ethical concerns) like the lack of individualization that generally associates artists with their art. Thus, there is a little fear of losing traditional art created by real humans, though AI-generated art is sold for high prices. On the other hand, with the growth of Electroencephalography (EEG) technology, individuality could be applied even to AI-generated art by capturing an artist's thoughts (i.e., capturing the brain signals).
The future of AI-generated art is still blurry, but the AI technology we have right now is indeed capable of creating images or videos or text that can fool us, humans. Thus, the possibilities of AI art are both exciting and scary.

Rohit Kundu is a Ph.D. student in the Electrical and Computer Engineering department of the University of California, Riverside. He is a researcher in the Vision-Language domain of AI and published several papers in top-tier conferences and notable peer-reviewed journals.

