LLMs
17 min read
—

Let’s learn about generative AI from the ground up, look at its current ecosystem, and think about what’s next in store for the current GenAI hype.

Generative AI has emerged as a groundbreaking technology, transforming our approach to artificial intelligence.
From audio and code to images, text, simulations, and videos, generative AI algorithms can create new content that revolutionizes various industries.
In 2023, the world witnessed several breakthroughs in generative AI, pushing the boundaries of what was previously thought possible. One such innovation is the latest version of ChatGPT, developed by OpenAI. Released for testing to the general public in November 2022, the tool saw over a million people signing up to use it in just five days—and its popularity has been riding high ever since.
Generative AI is not just a technological phenomenon—it's a tool with immense practical applications. It creates new product designs, optimizes business processes, and generates entire virtual worlds. The impact of generative AI on the world of AI is profound and far-reaching, and we are just beginning to scratch the surface of its potential.
In this article, we’ll cover all the basics of generative AI and overview its current ecosystem. Here’s what you’ll find below:
What is generative AI?
Generative AI techniques
Generative AI use cases and applications
Top generative AI tools
Generative AI challenges and limitations
What’s next for generative AI?

AI for document processing
Put AI agents to work on real finance tasks
Get started today
What is generative AI?
Generative AI, a rapidly evolving subset of artificial intelligence, transforms how we create and interact with digital content. This technology leverages machine learning models, particularly unsupervised and semi-supervised algorithms, to generate new content based on existing data.
Generative AI understands the underlying patterns in the input data, enabling it to produce novel outputs that resemble the original data. This process is facilitated by neural networks, which can create a wide range of content, from images and videos to text and audio.
Generative Adversarial Networks (GANs) and transformer-based models such as Generative Pre-Trained (GPT) language models are two of the most widely used generative AI models. GANs can create visual and multimedia artifacts from imagery and textual input data, while transformer-based models can generate textual content, leveraging information from the internet.
Generative AI has a broad spectrum of applications, including (but not limited to) creating AI-generated art, enhancing data augmentation in computer vision, generating synthetic data for training other machine learning models, and even in natural language processing, where it powers LLMs (Large Language Models) such as GPT.
Read more: Impact of Large Language Models on Enterprise: Benefits, Risks & Tools
Generative AI holds many benefits but also presents challenges. The technology is complex and requires substantial computational resources and training data. Moreover, ethical considerations are related to the potential misuse of generative AI, such as creating deepfakes or other misinformation.
Generative AI techniques
Generative AI, a rapidly evolving field of artificial intelligence, transforms how we interact with technology. This section will delve into four key generative AI techniques:
Generative Adversarial Networks (GANs)
Transformers
Variational Autoencoders
Generative Adversarial Networks (GANs)
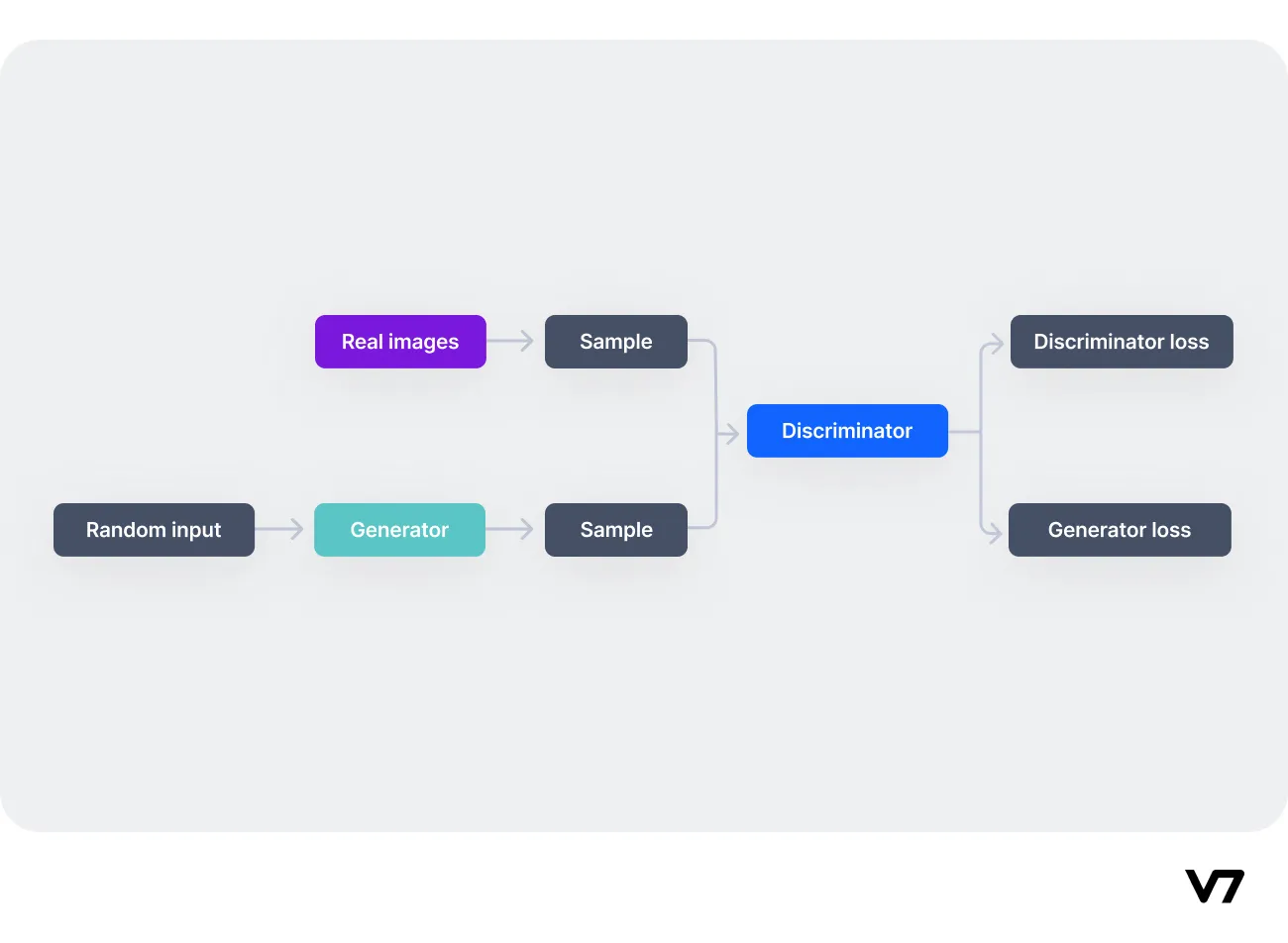
GANs are a class of AI algorithms used in unsupervised machine learning, introduced by Ian Goodfellow and his colleagues in 2014. They consist of two parts: a generator, which creates images, and a discriminator, which tries to distinguish between real and generated images. The competition between these two networks generates new, synthetic images almost indistinguishable from real ones. GANs have found applications in various fields, including art, advertising, and even healthcare, where they can convert MRI images into CT scans.
GANs have been used in various applications, including:
image synthesis
semantic image editing
style transfer
image super-resolution
classification
However, they also have their limitations and challenges. For instance, they can be difficult to train—because of problems such as mode collapse, where the generator produces limited varieties of samples, or vanishing gradients, where the discriminator becomes too good, making it hard for the generator to improve.
Generative AI models combine various AI algorithms to represent and process content. Techniques such as GANs and variational autoencoders (VAEs) are suitable for generating realistic human faces, synthetic data for AI training, or even facsimiles of particular humans.
Read more: The Complete Guide to Generative Adversarial Networks (GANs)
Transformers
Transformers have revolutionized the field of natural language processing (NLP) and have been instrumental in developing large language models like GPT-3 and GPT-4.
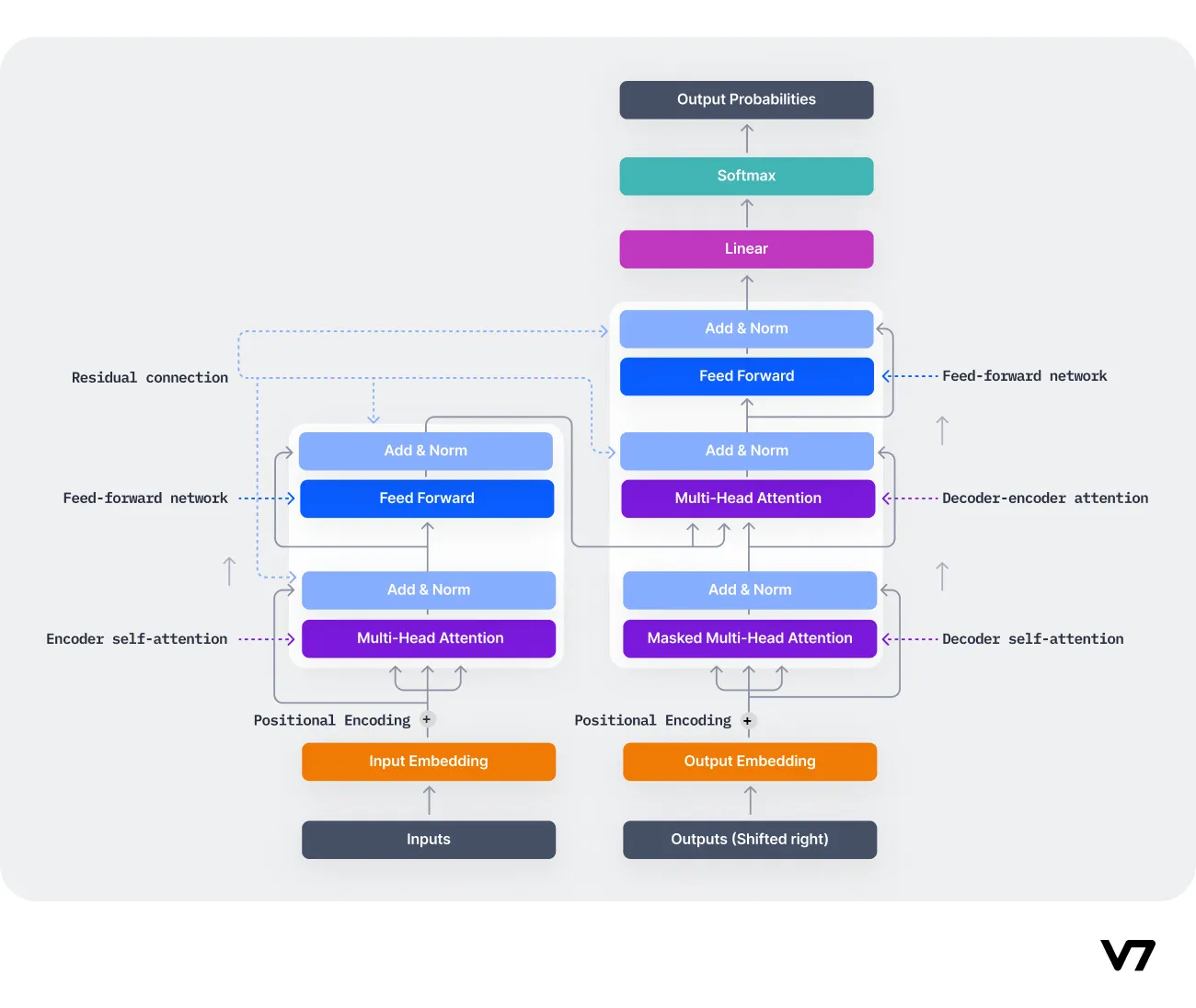
The original Transformer model was introduced in a paper titled "Attention is All You Need" by Vaswani et al. in 2017. The paper proposed a novel architecture that relies solely on self-attention mechanisms, discarding the need for recurrence and convolutions, which were the mainstays of previous sequence transduction models.
The Transformer model introduced several novel ideas. The most significant of these is the self-attention mechanism, which allows the model to weigh the relevance of a word in a sentence to other words when generating an output. This mechanism allows the model to handle long-range dependencies in text more effectively than previous models. The Transformer model also introduced the concept of positional encoding, which allows the model to consider the position of words in a sentence.
In recent years, Transformer models have been at the forefront of state-of-the-art NLP research. In 2023, Google Research highlighted the progress made with larger and more powerful language models, many based on the Transformer architecture. For instance, Google's large language model, LaMDA, and the 540 billion parameter model, PaLM, are built on the Transformer architecture and have significantly improved natural language, translation, and coding tasks.
The Transformer model has also been instrumental in the development of generative AI. For example, GPT-3 and GPT-4, two of the most powerful generative AI models, are based on the Transformer architecture. These models have been used to generate human-like text, translate languages, assist with coding tasks, and answer questions in a helpful and informative way.
The transformer model has been a game-changer in generative AI. Its ability to handle long-range dependencies in text and its scalability has made it the model of choice for developing state-of-the-art generative AI models.
Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are generative models that have gained significant attention in machine learning and AI. Introduced by Kingma and Welling in their seminal 2013 paper "Auto-Encoding Variational Bayes," VAEs brought a novel approach to generative modeling by combining deep learning and probabilistic graphical modeling.
The key idea behind VAEs is introducing a latent variable model with a continuous latent space and an approximate inference mechanism based on neural networks. The model is trained to maximize the lower bound of the log-likelihood of the data, which can be efficiently computed using stochastic gradient descent methods. This approach allows efficient learning and inference in complex, high-dimensional datasets.
VAEs have a unique architecture comprising two main components: an encoder and a decoder. The encoder takes input data and encodes it into a latent space, capturing the underlying data distribution. The decoder then takes these latent variables and reconstructs the original input data. This architecture allows VAEs to generate new data that resemble the training data, making them a powerful tool for generative tasks.
In the context of generative AI, VAEs play a crucial role. They provide a robust and flexible framework for learning complex data distributions, which is essential for generating realistic and diverse data. Moreover, the probabilistic nature of VAEs allows for a measure of uncertainty in the generated data, which can be crucial in many applications.
Read more: Autoencoders in Deep Learning: Tutorial & Use Cases
Large Language Models (LLMs)
Large Language Models (LLMs) are rooted in the transformer architecture. The novel idea in the original transformer was the attention mechanism, which allowed models to focus on different parts of the input sequence when producing output, enabling them to handle long-range dependencies in data.
In 2023, the state-of-the-art generative AI has been marked by rapid advances in LLMs, with models containing billions or even parameters. These models can generate high-quality text, create photorealistic images, and even produce entertaining content on the fly. Innovations in multimodal AI have enabled content generation across multiple media types, including text, graphics, and video. This has given rise to tools like DALL-E, which can create images from a text description or generate text captions from images.
LLMs hold significant importance in the context of generative networks. They have opened a new era where AI models can generate engaging and coherent content, making them a hot commodity in various industries. They have the potential to fundamentally change businesses by assisting in tasks like writing code, designing new drugs, developing products, redesigning business processes, and transforming supply chains.
In 2023, the research on Large Language Models (LLMs) has taken some fascinating turns. One of the most intriguing ideas is the GIMLET, a unified graph-text model for instruction-based molecule zero-shot learning. This model addresses the challenge of label insufficiency in molecule property prediction, which is often caused by expensive lab experiments. GIMLET unifies language models for graph and text data, allowing it to encode graph structures and instruction text without additional graph encoding modules. This model has shown significant performance improvements in instruction-based zero-shot learning, even achieving results comparable to supervised Graph Neural Network (GNN) models.
Another noteworthy research is developing a re-weighted sampling strategy for offline Reinforcement Learning (RL) algorithms. This strategy addresses the issue of state-of-the-art offline RL algorithms being overly restrained by low-return trajectories and failing to exploit high-performing trajectories to the fullest. The re-weighted sampling strategy can be combined with any offline RL algorithm, and it has been shown to exploit the dataset fully, achieving significant policy improvement.
These research developments highlight LLMs' ongoing evolution and increasing versatility in tackling complex tasks. However, it's important to note that we are still in the early days of using generative AI. Early implementations have had issues with accuracy and bias, and there are ongoing concerns about the ethical implications of these models.
Read more: Impact of Large Language Models on Enterprise: Benefits, Risks & Tools
Generative AI use cases and applications
Generative AI is already disrupting business in almost every sector. Let’s go through a few of the most significant use cases.
Generating content: images, videos, music
Generative AI models, such as GANs (Generative Adversarial Networks), can create new content, including images, videos, and music. The success of tools such as the well-known Dall-E, Stable Diffusion, or Midjourney proves that visual content generation is one of generative AI’s most popular use cases.
There is a growing interest in improving the quality and diversity of generated content. Researchers are exploring ways to generate 3D scenes from static 2D images using AI. For instance, NVIDIA's Picasso service is a cloud-based generative AI model that creates high-resolution, photorealistic images, videos, and 3D content.
In the real world, AI-generated art has made its way to the Museum of Modern Art in New York City. Artist Refik Anadol used a sophisticated machine-learning model to interpret MoMA's collection's publicly available visual and informational data.
Automated custom software engineering
Generative AI can also be used in software engineering to automate the creation of custom software. GPT-3, for example, can generate code based on natural language descriptions.
The latest research focuses on improving code generation accuracy and efficiency. For instance, researchers are developing AI models to better understand the code's context and generate more accurate and efficient code.
Companies such as GitHub are using AI to assist developers in writing code. Their tool, Copilot, uses GPT-3 to suggest code snippets to developers.
Writing assistance
Generative AI models such as GPT-3 and GPT-4 assist in writing tasks. These models can generate human-like text, making them helpful in drafting emails, writing articles, and more. Content-writing and marketing co-pilots, such as Jasper, keep gaining traction.
Current research focuses on improving the generated text's coherence and relevance.
Text-to-speech solutions
Generative AI models can be used to convert text into speech. These models can generate human-like speech, making them useful for tasks such as creating voice assistants, reading out text, and more.
Research areas focus on improving the generated speech's naturalness and expressiveness.
In practice, companies like Google are using AI to power their text-to-speech solutions. Google's Text-to-Speech service uses AI to convert text into natural-sounding speech in over 200 voices across 40+ languages.
Product design and development
Generative AI models can be used in product design and development to generate new design ideas. These models can learn from existing designs and generate new ones, speeding up the design process.
Research in this area focuses on improving the generated designs' quality and diversity. For example, researchers are working on models to generate designs that look good and meet functional requirements. In the real world, companies such as Autodesk use AI to assist in product design. Their tool, Dreamcatcher, uses AI to generate design options based on the designer's requirements.
Personalized user experiences
Generative AI models can be used to create personalized user experiences. These models can learn from user behavior and generate personalized content, recommendations, and more.
Researchers are working on models that can understand user preferences better and generate more accurate personalizations. Companies like Netflix are already using AI to personalize user experiences—e.g., to generate personalized movie and TV show recommendations based on the user's viewing history.
Gaming solutions
Generative AI models can be used in gaming to create new game elements, such as levels, characters, and more. These models can learn from existing game elements and generate new ones, adding variety and novelty to the game.
Researchers are working on models that can generate game levels that are visually appealing and provide a good balance of challenge and enjoyment. Companies like Ubisoft use AI to assist in game development. Ubisoft's tool, Commit Assistant, uses AI to predict and fix bugs in the game code.
Healthcare solutions
Generative AI models can be used in healthcare to generate new drug molecules, predict disease progression, and more. These models can learn from existing medical data and generate new insights, speeding up the research and treatment process.
Research in this area is focused on improving the accuracy and relevance of the generated medical insights. For example, researchers are working on models to predict disease progression more accurately and generate more effective drug molecules. Companies like DeepMind are using AI to assist in healthcare research. DeepMind's tool, AlphaFold, uses AI to predict the 3D structure of proteins, which is crucial for understanding diseases and developing new drugs.
Read more: 7 Life-Saving AI Use Cases in Healthcare











Top generative AI tools in 2023
Let’s go through a few of the top players in the current fast-changing GenAI ecosystem.
ChatGPT
ChatGPT, developed by OpenAI, is a state-of-the-art generative AI tool that leverages the power of large language models for natural language processing tasks. It’s built on the GPT-4 architecture, a transformer-based model with 175 billion parameters. ChatGPT is widely used for various applications, including drafting emails, writing code, creating written content, tutoring, translation, and even simulating characters for video games. The tool's ability to generate human-like text has made it valuable in many industries.
Stable Diffusion
Stable Diffusion is a tool designed to generate high-quality images. It uses a generative model trained with a diffusion process, gradually transforming a random noise into a data sample. The model is trained to reverse this process, starting from a data sample and applying a reverse diffusion process to recreate the original noise. This allows Stable Diffusion to generate new samples by running the reverse process starting from new noise samples. The tool has applications in various fields, including art, design, and entertainment.

Midjourney
Midjourney is a generative AI tool that creates high-quality digital art. The tool uses advanced generative models to create unique and visually stunning art pieces. While specific details about the underlying architecture are not publicly available, the quality of the generated art suggests the use of sophisticated generative models, possibly including variants of GANs or VAEs. Midjourney's creations have been used in digital art exhibitions and as visual elements in digital media.

DALL-E
DALL-E is a generative AI tool developed by OpenAI that creates images from text descriptions. DALL-E has diverse capabilities, including creating anthropomorphized versions of animals and objects, combining unrelated concepts in plausible ways, rendering text, and applying transformations to existing images. It has been used in various applications, including content creation, design, and education.
Generative AI challenges and limitations
Generative AI, like any emerging technology, has its challenges and limitations. These challenges range from technical to ethical, and understanding them is crucial for the effective and responsible deployment of generative AI technologies.
Copyright issues
Generative AI models can generate content that closely mimics human-created content. This raises concerns about copyright infringement, as these models could generate content too similar to copyrighted material. For instance, AI art generated by neural networks could infringe on original artists' copyrights.
Inaccurate results and “deep fakes”
Generative AI models can sometimes produce inaccurate or misleading results. This is particularly concerning in "deep fakes," where generative AI creates realistic but false images or videos. These deep fakes can be used to spread misinformation or propaganda, posing significant societal challenges.
Machine learning bias
Like all machine learning models, generative AI models are susceptible to bias in their training data. If the training data contains biases, the generative AI model will likely reproduce and amplify these biases. This can lead to unfair or discriminatory outcomes.
Large training data needs
Generative AI models typically require large training data to produce high-quality outputs. Gathering and storing this data can be resource-intensive.
How to build a generative AI model?
Building a generative AI model involves steps from data collection to model deployment. This process is a complex task and requires a deep understanding of machine learning models, particularly generative models. Let’s go through a high-level overview of the process.
Data collection: The first step in building a generative AI model is to collect a large amount of data in the domain of interest. This could be images, sentences, sounds, etc. The quality and diversity of this data can significantly impact the model's performance.
Preprocessing: The collected data is then preprocessed to make it suitable for training the model. This could involve resizing images, tokenizing text, or normalizing audio signals.
Model selection: It’s time to choose a suitable generative model. Depending on the application, this could be a Generative Adversarial Network (GAN), Variational Autoencoder (VAE), or an autoregressive model such as PixelRNN.
Model training: The chosen model is then trained on the preprocessed filtered data. The training process involves adjusting the model's parameters to generate data similar to the collected data. This is often an iterative process that requires significant computational resources.
Model evaluation: After training, the model is evaluated to ensure it generates data that closely resembles the original data. This could involve visual inspection for image data or more quantitative measures for other data types.
Model deployment: Once the model is satisfactorily trained and evaluated, it can be used in applications. This could involve integrating the model into an existing system or building a new application.
What’s next for generative AI?
As we delve deeper into generative AI, it's clear that we're only scratching the surface of its potential. The future of generative AI is poised to be transformative, with its influence permeating various sectors and reshaping the market dynamics.
Generative AI is already demonstrating its potential to revolutionize industries, with models like Stable Diffusion and ChatGPT setting historical records for user growth. The market is witnessing an influx of startups developing foundation models, AI-native apps, and infrastructure.
However, the question remains: Where in this market will value accrue? The companies creating the most value—i.e., training generative AI models and applying them in new apps—haven't captured most of it. The future will likely see a shift in this dynamic, with value accruing in areas of the stack that are differentiated and defensible.
The generative AI market is expected to see a rise in infrastructure vendors, capturing the majority of dollars flowing through the stack. As generative AI continues to evolve, we can anticipate a surge in the development of AI applications, with a focus on improving retention, product differentiation, and gross margins.
The future of generative AI also holds potential pitfalls. While impressive, the rapid growth of generative AI applications is not enough to build durable software companies. The challenge lies in ensuring that growth is profitable and that users generate profits once they sign up and stick around for a long time.
In conclusion, the future of generative AI is promising, but it's not without its challenges. As we continue to explore its potential, we must also address the issues of value accrual, profitability, and retention. The journey ahead is exciting, and the impact of generative AI on our lives and the market is bound to be profound.

Deval is a senior software engineer at Eagle Eye Networks and a computer vision enthusiast. He writes about complex topics related to machine learning and deep learning.

