AI implementation
15 min read
—

Vector databases have had a huge impact on AI products involving Large Language Models and semantic search. Let’s take a closer look at them—and see if they’re the right choice for your project.

A vector database is a unique database designed specifically for storing and retrieving vector embeddings. These numerical arrays represent various characteristics of an object and are the distilled representations of training data in machine learning models. Unlike traditional relational databases or newer NoSQL databases, vector databases are purpose-built to manage this specific data type.
The raising significance of vector databases in AI and machine learning cannot be overstated. They power next-generation search engines and production recommender systems, improving accuracy and usability by leveraging machine learning to infer user intent. Moreover, vector databases have found a significant role in deploying chatbots and other applications based on Large Language Models.
In this article, we’ll cover:
What are vector databases?
The mechanics of vector databases
Top vector databases
Use cases of vector databases
Vector databases and LLMs
Is vector db the right choice for your project?

AI for document processing
Extract structured data from any document automatically
Get started today
Understanding vector databases
Understanding vector databases is vital for anyone working in AI and machine learning. Whether developing proprietary Large Language Models or leveraging pre-trained models via APIs, vector databases can provide the long-term memory and retrieval capabilities necessary for your projects.
What is a vector database?
A vector database is a specialized database designed to store and retrieve vector embeddings, which are numerical arrays representing various characteristics of an object. These embeddings are the distilled representations of the training data in machine learning processes, serving as the filter through which new data is run during the inference part of the machine learning process. Vector databases are becoming increasingly popular in AI and machine learning, finding use in applications ranging from next-generation search engines to Large Language Models.
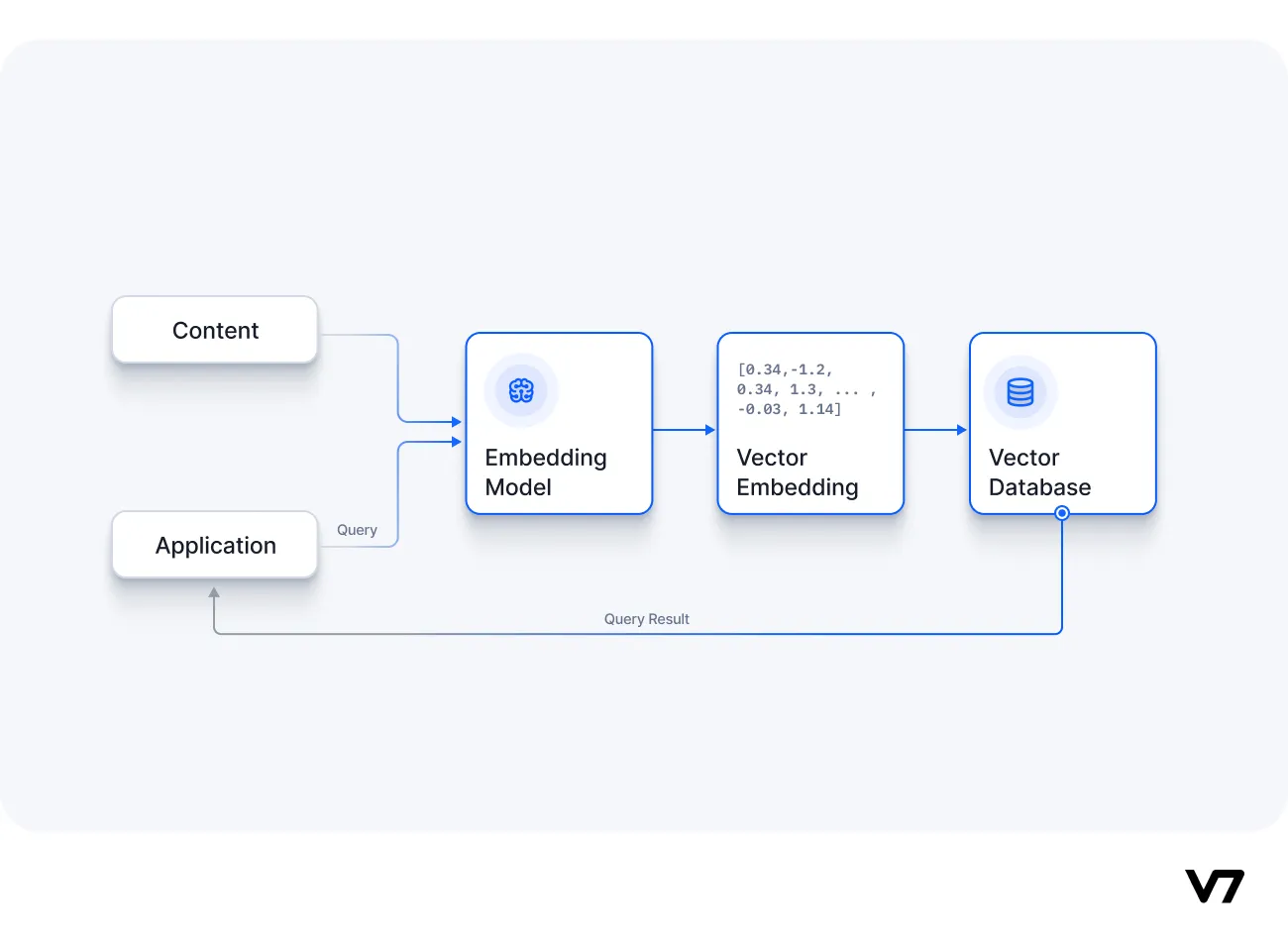
How vector databases differ from traditional databases
Vector databases differ from traditional scalar-based databases in their ability to handle the complexity and scale of vector embeddings.
Using traditional databases might make extracting insights and performing real-time analysis difficult. Vector databases, however, are intentionally designed to handle this data type and guarantee higher performance, scalability, and flexibility.
Unlike traditional relational databases such as PostgreSQL, which stores tabular data in rows and columns, or NoSQL databases like MongoDB, which store data in JSON documents, vector databases are designed to handle one specific type of data: vector embeddings. This unique design offers vector databases certain advantages, such as the ability to perform similarity searches that find the best match between a user's prompt and a particular vector embedding. This capability is particularly useful in deploying Large Language Models, where vector databases can store billions of vector embeddings representing extensive training.

Here are some key differences and advantages:
Data type: Unlike traditional relational databases such as PostgreSQL, which stores tabular data in rows and columns, or NoSQL databases like MongoDB, which store data in JSON documents, vector databases are designed to handle one specific type of data: vector embeddings.
Similarity search: Vector databases have the ability to perform similarity searches that find the best match between a user's prompt and a particular vector embedding. This capability is particularly useful in deploying Large Language Models, where vector databases can store billions of vector embeddings representing extensive training.
Scalability: Vector databases are designed to handle large-scale data. They can store and search billions of high-dimensional vectors, making them suitable for large-scale machine-learning applications.
Performance: Vector databases provide high-speed search performance. They use advanced indexing techniques to ensure fast retrieval of similar vectors, even in large-scale databases.
Flexibility: Vector databases support flexible data models. They can handle structured and unstructured data, making them suitable for various applications, from text and image searches to recommendation systems.
Efficiency: Vector databases are efficient in handling high-dimensional data. They use dimensionality reduction techniques to compress high-dimensional vectors into lower-dimensional spaces without losing significant information. This makes them efficient in storage and computation.
The role of vector embeddings in vector databases
Vector embeddings play a crucial role in vector databases. They are the numerical arrays that represent various characteristics of an object, serving as the output from the training part of the machine learning process. In the context of Large Language Models, vector databases can store the vector embeddings resulting from the model's training. This allows the database to perform similarity searches that find the best match between a user's prompt and a particular vector embedding.
In addition to their role in Large Language Models, vector embeddings are used in next-generation search engines and recommender systems. For example, Home Depot improved the accuracy and usability of its website search engine by augmenting traditional keyword searches with vector search techniques. This approach enables machine learning to infer a user's intent rather than requiring a perfect keyword match.
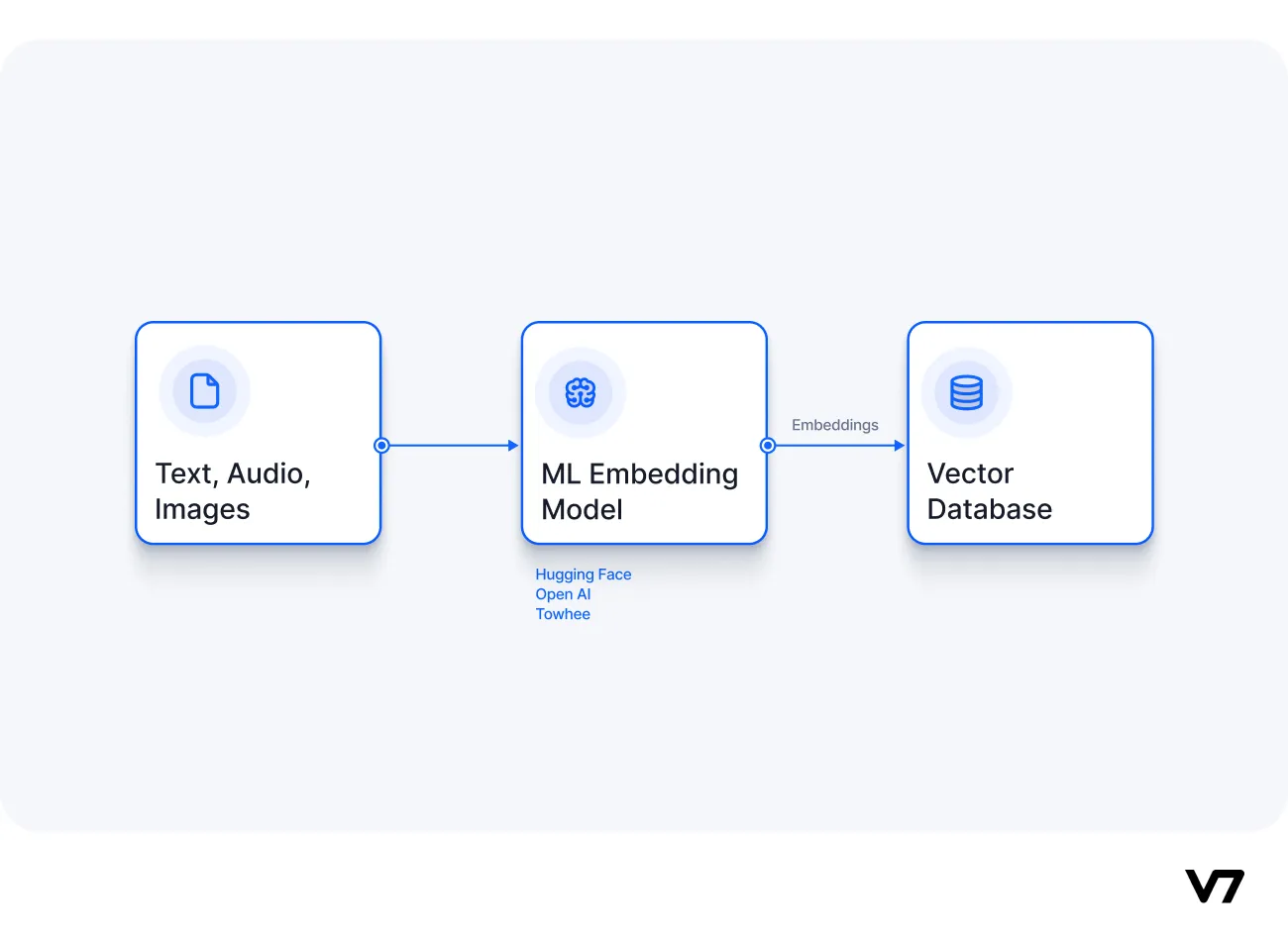
The mechanics of vector databases
Vector databases is a unique database designed to handle high-dimensional vector data, often the output of machine learning models. They are particularly well-suited for managing and searching through large amounts of unstructured data, which is transformed into a structured format using vector embeddings. The key elements of vector databases—unstructured data, vector embeddings, and vector indexing—are interconnected and play a crucial role in the functioning of these databases.
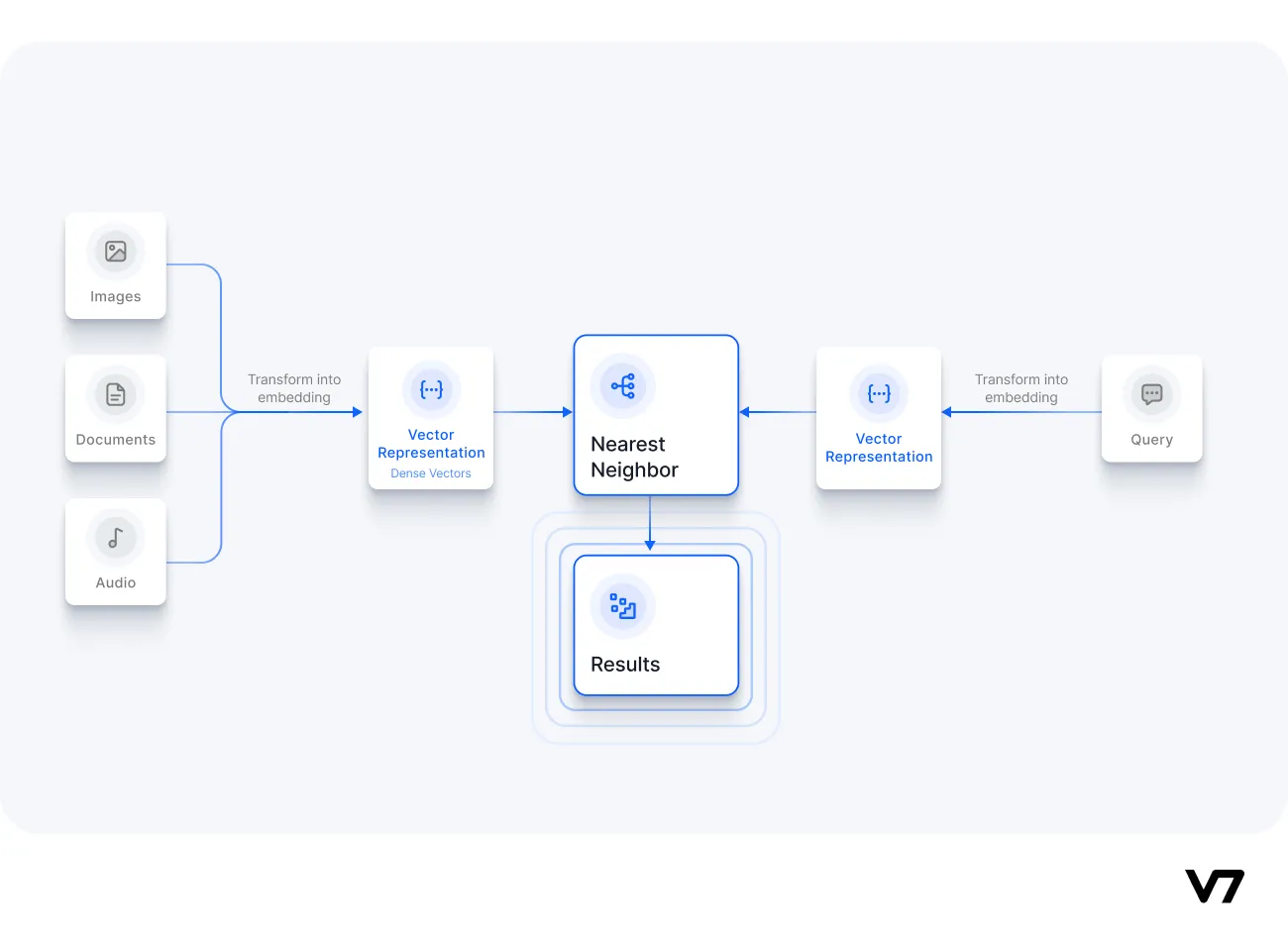
How do vector databases work?
Let's discuss three core elements of vector databases and how they interconnect to form a functional vector database.
Unstructured data
Vector embeddings
Vector indexing
Unstructured data
Unstructured data is information that doesn't conform to a specific, pre-defined data model. It's often text-heavy and includes data types such as emails, social media posts, videos, and more. Dealing with unstructured data is a common challenge in AI and machine learning. Vector databases address this challenge by transforming unstructured data into a structured format using vector embeddings.
The conversion process involves using AI models, such as Large Language Models, to generate embeddings that carry semantic information. These embeddings have many attributes or features representing different data dimensions, essential for understanding patterns, relationships, and underlying structures.
Consider a scenario where we want to index a big collection of articles for a semantic search application. The articles, which are unstructured data, can be processed by a Large Language Model to create vector embeddings. Each article is transformed into a vector that captures its semantic meaning in a high-dimensional space. These vectors are then inserted into the vector database, creating a structured representation of the unstructured data.
When a user issues a query, the same language model creates an embedding for the query. This query embedding is then used to search the vector database for similar vector embeddings. Similar embeddings are associated with the original articles used to create them, allowing the system to retrieve articles semantically related to the user's query.
This process enables efficient management, search, and processing of complex, unstructured data in a structured and organized manner.
Vector embeddings
Vector embeddings are numerical representations of data objects. They are generated by machine learning models and serve as a distilled, structured representation of unstructured data. Each point in this high-dimensional space corresponds to a unique data object, and the distance between points represents the similarity between the corresponding data objects.
In the context of vector databases, vector embeddings are used to transform and store unstructured data in a way that allows for efficient similarity search. This is particularly useful in applications such as semantic search and natural language processing, where the goal is to find data objects that are semantically similar to a given query.
Vector indexing
Once unstructured data has been transformed into vector embeddings, the next challenge is to store these embeddings in a way that allows for efficient search and retrieval. This is where vector indexing comes in.
Vector indexing involves organizing and storing vector embeddings in a database in a way that allows for efficient similarity search. The high dimensionality of the vector space and the need to perform complex distance calculations make it a challenging task. However, using advanced indexing algorithms and data structures, vector databases are designed to handle this task efficiently.
Similarity search in vector databases
The concept of similarity search in vector databases is central to their operation. This process involves finding the most similar vectors to a given vector within the database.
The similarity is often determined using distance metrics such as Euclidean distance or Cosine similarity. In the context of LLMs, the similarity search is used to find the best match between the user’s prompt and the stored vector embeddings. This allows the LLM to generate appropriate responses to questions based on the training data it has been provided.
Native vector databases, such as those from Pinecone and Zilliz, have an advantage in this area as they were designed from the ground up to manage vector embeddings. For instance, Zilliz's Milvus, an open-source vector database, can deliver millisecond searches on trillion vector datasets.
A large-scale application using vector databases for similarity search is Amazon's recommendation system. This system uses a collaborative filtering algorithm that analyzes customer behavior and preferences to make personalized recommendations for products they might be interested in purchasing. It considers past purchase history, search queries, and customer shopping cart items to make recommendations. Amazon's recommendation system also uses natural-language processing techniques to analyze product descriptions and customer reviews to provide more accurate and relevant recommendations.
This is a prime example of how vector databases can enhance the functionality and efficiency of large-scale applications. By representing items as vectors, the system can quickly and effectively search for similar items, providing personalized recommendations that improve the user experience.
Top vector databases
The landscape of vector databases is diverse and rapidly evolving, with several key players leading the charge. Each database offers unique features and capabilities, catering to different needs and use cases in machine learning and AI.

Pinecone
Pinecone is a fully-managed vector database service that excels in large-scale machine-learning applications. It is designed to handle high-dimensional data and provides efficient similarity search capabilities. Pinecone's key differentiator is its focus on simplicity and ease of use—it offers a serverless and cloud-based environment.
Zilliz
Zilliz is an open-source vector database built for big data and AI applications. It offers powerful features such as distributed search and computing, making it ideal for handling large datasets. Zilliz's core differentiator is its commitment to open-source, fostering a community-driven approach to development and innovation. It also provides a cloud-native architecture, ensuring scalability and flexibility.
Milvus
Milvus is an open-source vector database designed for similarity search and AI applications. It offers rich features, including index building, vector similarity search, and data management. Milvus's key differentiator is its high performance and efficiency, powered by advanced indexing algorithms and hardware acceleration techniques. It is an open-source project, encouraging community contributions and collaboration.
Qdrant
Qdrant is a vector similarity search engine focusing on flexibility and performance. It supports a wide range of distance metrics and provides advanced filtering capabilities. Qdrant's key differentiator is its support for complex filtering conditions in combination with vector search, enabling more precise and targeted search results. Qdrant is an open-source project promoting transparency and community involvement.
Deeplake
Deeplake is a cloud-native vector database designed for machine learning workloads. It offers real-time data ingestion, high-speed vector search, and scalability. Deeplake's key differentiator is its cloud-native architecture, providing seamless scalability and high availability. It is a cloud-based service offering ease of use and accessibility.











Use cases of vector databases
Let’s review the top use cases for vector databases.
Search engines
Vector databases are revolutionizing the way search engines operate. Traditional search engines rely on keyword matching, which often fails to capture the semantic meaning of queries. Vector databases, on the other hand, enable semantic search by converting text into high-dimensional vectors that capture the semantic meaning of the text. This allows search engines to return results semantically similar to the query, even if they don't contain the exact keywords. For instance, Google's search engine has been using vector databases to improve its search results, providing users with more relevant and contextually accurate information.
Recommender systems
Recommender systems are another area where vector databases are making a significant impact. These systems often must deal with high-dimensional data and find similar items in a large dataset. Vector databases excel at this task by using Approximate Nearest Neighbor (ANN) search to identify similar items quickly. This capability is particularly useful for recommendation systems, where the goal is to recommend items similar to what the user has liked in the past. Companies like Netflix and Amazon leverage vector databases to power their recommendation systems, resulting in more personalized and accurate recommendations.
Large Language Models
Large Language Models such as GPT-3 and BERT are transforming the field of natural language processing. These models generate high-dimensional vector representations of text, which need to be stored and retrieved efficiently. Vector databases are perfectly suited for this task, as they are designed to handle high-dimensional data and support efficient similarity search. Using vector databases, companies can leverage Large Language Models to power applications such as chatbots, sentiment analysis, and text classification.
Semantic search
Semantic search is another prominent use case for vector databases. Unlike traditional keyword-based search, semantic search aims to understand a search query's intent and contextual meaning. By converting text into high-dimensional vectors, vector databases can find the most semantically similar results, even if the exact keywords are absent.
Vector databases also excel in finding similar items in a large dataset thanks to their ability to perform large-scale, efficient approximate nearest neighbor (ANN) searches. This feature lets them quickly identify the most similar vectors in the database, making them ideal for tasks like image or text similarity searches.
Vector databases and Large Language Models
Pro tip: Check out our guide to intelligent document processing with LLMs.
Large Language Models (LLMs) have emerged as a transformative force in artificial intelligence, enabling machines to understand and generate human-like text. These models, trained on vast amounts of data, can predict the likelihood of a word given its context in a sentence, a capability that underpins tasks like text completion, translation, and summarization. However, these models' sheer size and complexity present unique challenges, particularly when managing and retrieving the high-dimensional data they generate. This is where vector databases come into play.
Vector databases, with their ability to handle high-dimensional data and perform efficient similarity searches, are ideally suited to support the operations of LLMs. They provide a structured and organized way to store and retrieve the vector embeddings that these models generate, enabling efficient similarity searches in high-dimensional space.
Long-term memory in Large Language Models
Large Language Models, particularly transformer-based models like GPT-3, are known for capturing long-range dependencies in text. This "long-term memory" results from the model's architecture, which allows it to consider the context of a word in relation to all other words in a sentence, regardless of their distance. However, as the length of the text increases, maintaining this long-term memory becomes computationally expensive.
Vector databases can help mitigate this issue. By storing the vector representations of words or sentences in a structured manner, these databases can effectively serve as a model's long-term memory, allowing it to retrieve and consider the context from much earlier in the text. This can significantly enhance the model's ability to understand and generate coherent, contextually accurate text over longer passages.
How vector databases enable LLMs to perform long-range context dependency
Vector databases are crucial in enabling LLMs to handle long-range context dependencies. By storing the high-dimensional vector representations of words or sentences, these databases allow models to efficiently retrieve and consider the context from earlier in the text, even as the length of the text increases. This is particularly important for tasks such as text completion or summarization, where understanding the full context of a passage is critical for generating accurate and coherent results.
Moreover, the ability of vector databases to perform efficient similarity searches means that models can quickly identify and retrieve contextually relevant information from the database. This can significantly enhance the model's performance, generating more accurate and contextually relevant responses.
Are vector databases the right choice for your project?
Project type of project is a significant determinant. Vector databases excel in projects that involve large volumes of high-dimensional data and require efficient similarity searches, such as recommendation systems, image recognition, and natural language processing.
The scale of your project is another crucial factor. Vector databases are designed to handle large-scale data and provide fast query responses, making them suitable for projects that require processing huge amounts of data in real time.
However, vector databases also have their limitations. They can be complex to implement and maintain, especially for those unfamiliar with the technology. While some vector databases are open-source and relatively easy to set up, others may require more technical expertise or come with licensing costs. Additionally, while they excel at handling large volumes of data, they may not be the best choice for projects with smaller data sets or those that do not require similarity searches.
The future of vector databases in AI
Using vector databases in AI and machine learning is expected to grow. As AI models become more complex and the amount of data increases, the need for efficient data management tools like vector databases will only become more critical. Specific use cases include improving the accuracy of recommendation systems, enhancing natural language processing capabilities, and advancing image and speech recognition technologies.
Vector databases offer many benefits, but they may not be the right choice for every project. It's essential to carefully consider your project's requirements and the benefits and limitations of vector databases before deciding.

Deval is a senior software engineer at Eagle Eye Networks and a computer vision enthusiast. He writes about complex topics related to machine learning and deep learning.

