Slots
Play video
12:17
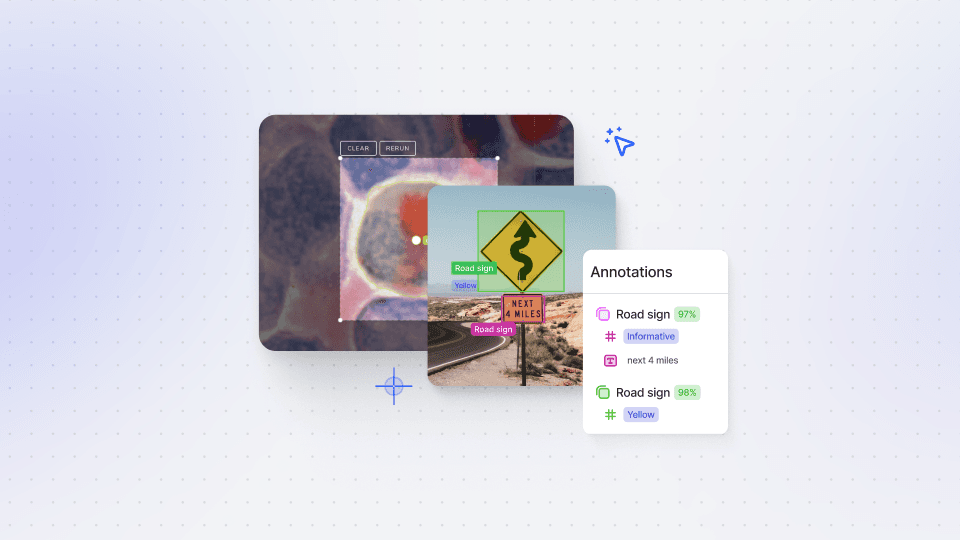
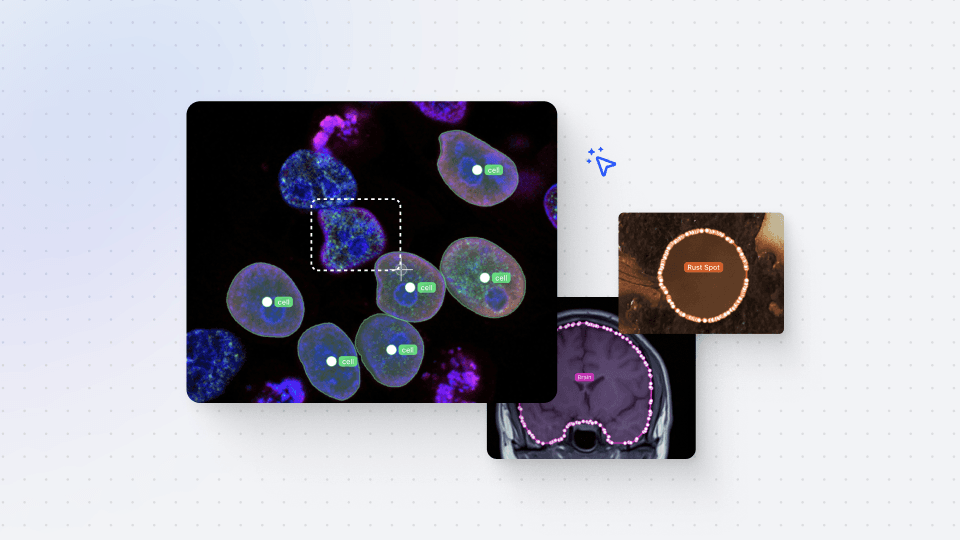
In this session, we dive into V7 slots, which allows you to annotate multiple files on the same screen simultaneously. This feature is especially valuable for medical use cases, for example, mammography hanging protocols, and any scenario that requires multiple files and file types on screen at once. Let's say you need to annotate a dataset with PDF instructions on an item level rather than a dataset level – that's where slots come in handy.
Slots offer a seamless way to register PDF files or other additional information alongside the main image. This means annotators always have specific instructions or reference data available while they annotate. For example, you could load an ultrasound image on the right slot and a healthcare record as a PDF on the left slot, allowing annotators to make more informed decisions.
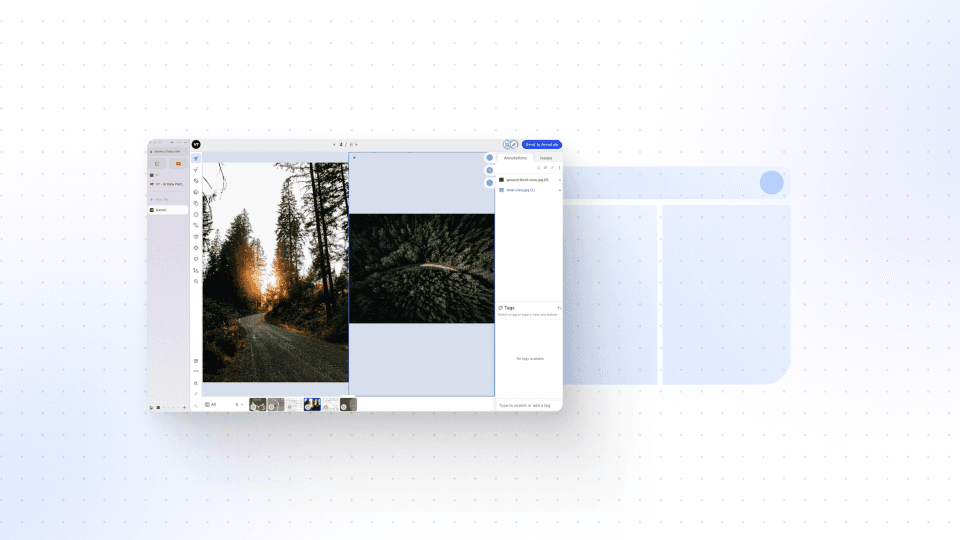
This video takes you through the process of uploading data into specific slots using the V7 REST API. Although the demonstration involves medical images (DICOM files), you can use the same process for any file types, including images, videos, and PDFs.
The video covers step-by-step instructions, including setting up the necessary imports, signing and uploading images, and confirming the successful upload. You'll learn how to handle multiple slots for a single item and how to access annotations for individual slots within a Darwin JSON file.
By the end of this video, you'll have a comprehensive understanding of how to leverage slots Annotation in V7 to enhance your annotation workflow. Whether you're dealing with medical datasets or any other scenario that requires concurrent annotation of multiple files, this feature will boost efficiency and accuracy.