Darwin JSON
Play video
7:07
Darwin JSON serves as the core export format for V7 annotations and model predictions. In this video, we will explore its structure and advantages over other data annotation formats. You’ll also learn how to convert your labels to and from Darwin JSON. Whether you want to import existing annotations into V7 or export your annotations to other formats, this tutorial has got you covered.
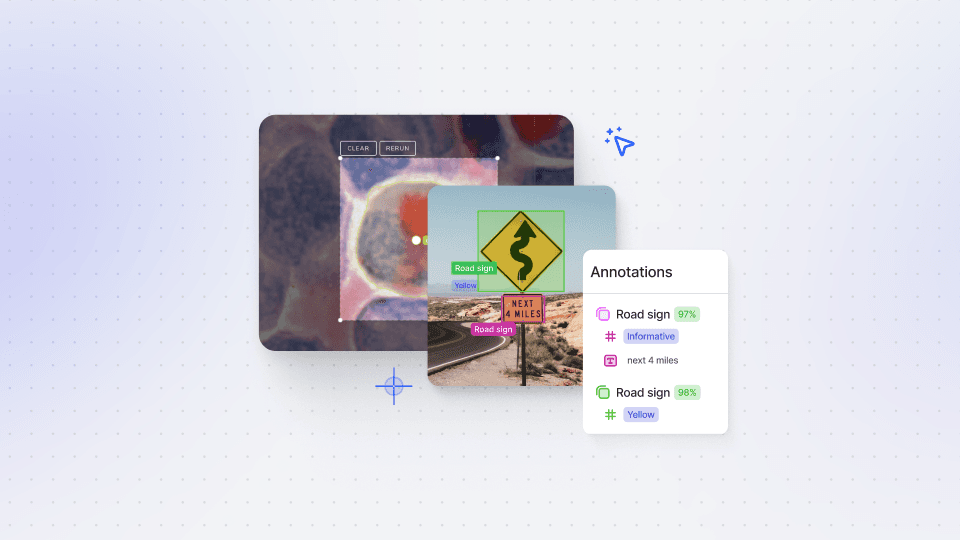
Darwin JSON contains essential specifications, including the item and annotations fields, providing all the necessary information about the exported resource. It includes details about datasets, teams, and resource URLs, making it a rich source of metadata.
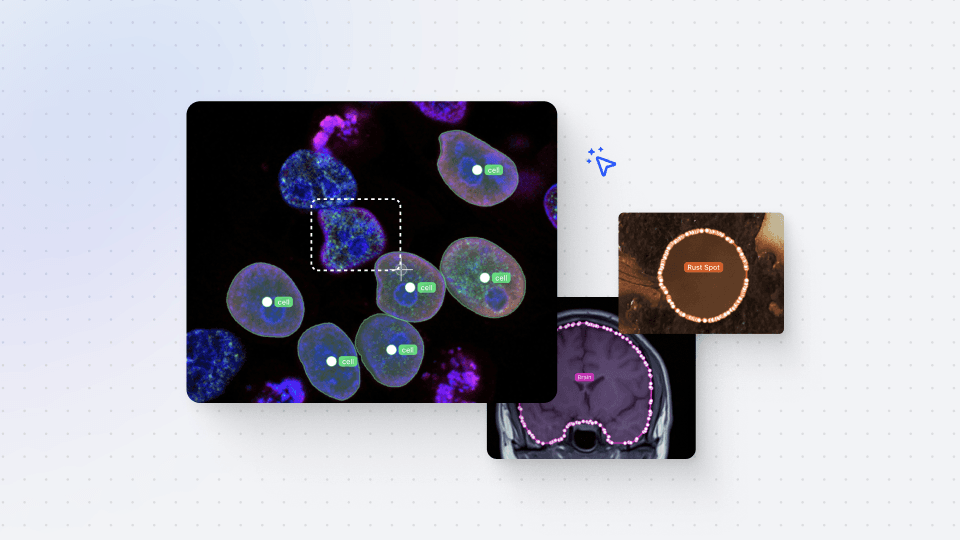
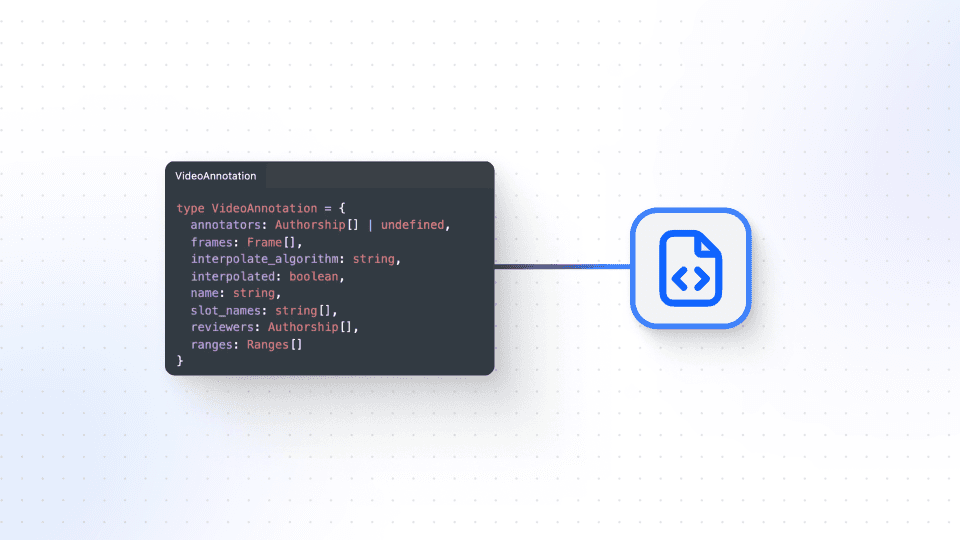
You'll learn how to access essential data, such as image dimensions, thumbnail URLs, and the original image file name and URL. Then, we’ll explore different annotations, covering various types like bounding boxes or polygons. You'll discover how to represent annotation data in Darwin JSON, including optional sub-annotation data and annotation authorship information. For video annotations, the video annotation object is explained, encompassing frame annotation data and interpolation information.
Converting annotations to and from Darwin JSON is a crucial skill for integrating V7 into your existing workflows and tech stack. The video demonstrates how to convert annotations using the Darwin command line interface function library. Converting from Darwin to other formats, like YOLO, is as simple as calling a function with the right arguments.
By the end of this video, you'll have a solid understanding of Darwin JSON and its benefits. You'll be equipped with the knowledge to import your existing annotations into V7, export your annotations to other formats, and leverage Darwin JSON's flexibility for seamless integration into your computer vision projects.
V7 Darwin JSON reference: https://docs.v7labs.com/reference/darwin-jso