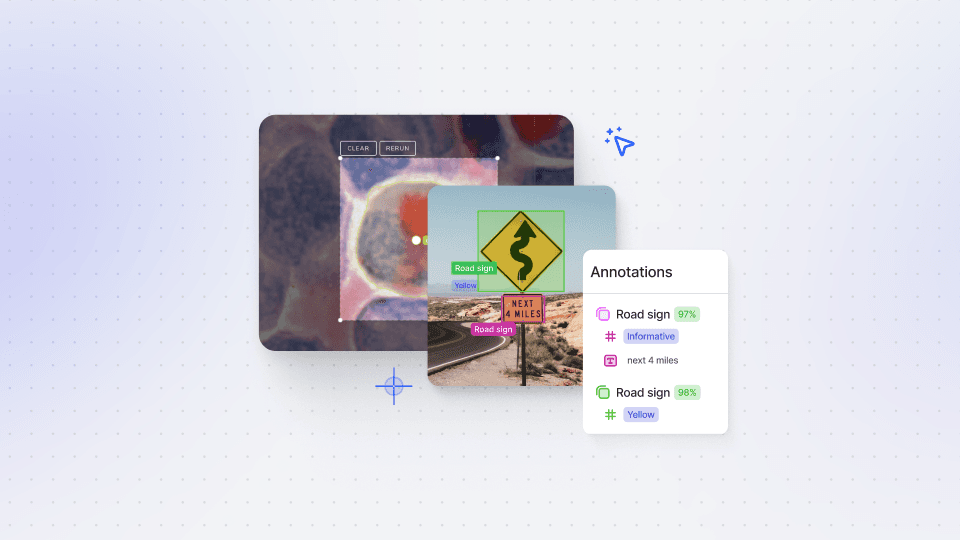
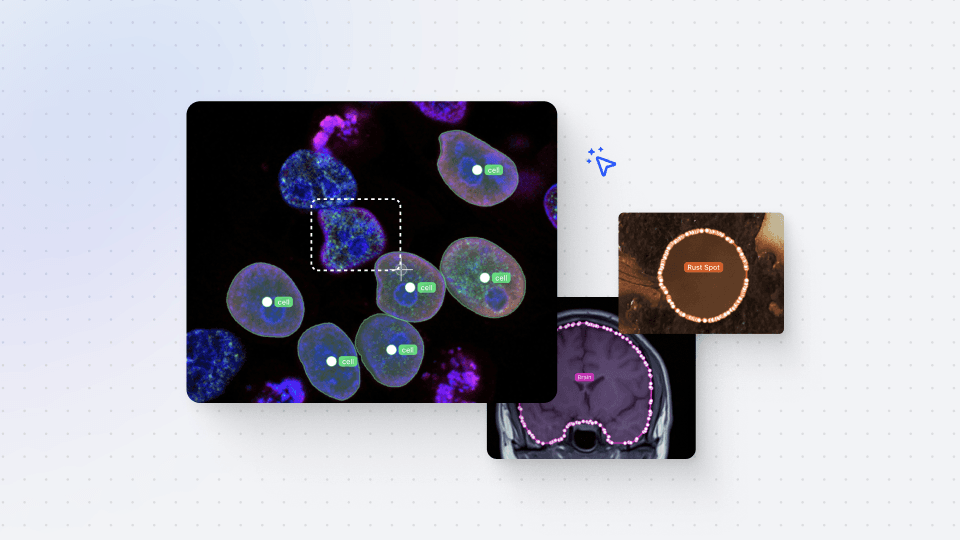
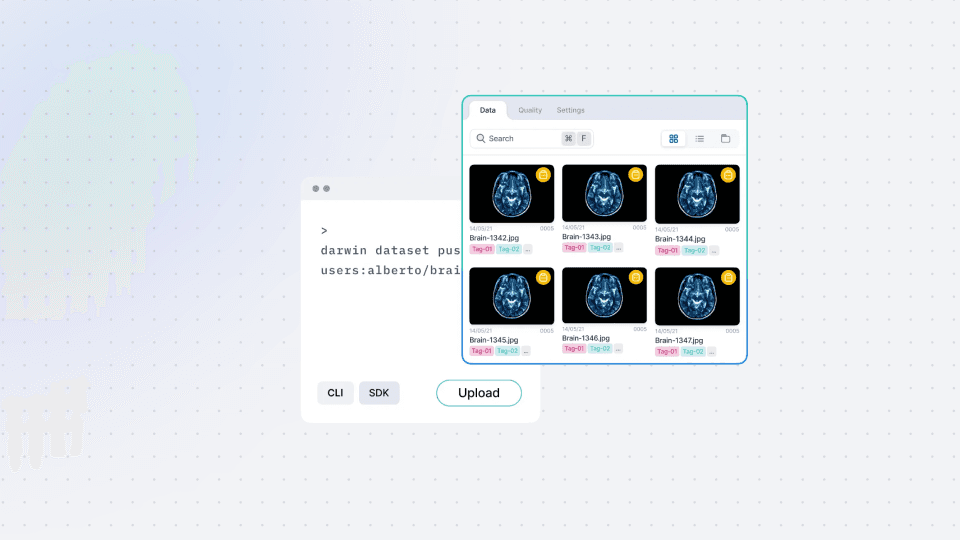
Data Upload
Play video
12:53
During this session, we will guide you through the various methods of uploading data to V7, the all-in-one platform for efficient training data management and AI development. We understand that handling sensitive data or dealing with unique formats like multi-slot files can pose challenges. That's why we are here to assist you every step of the way.
Firstly, we will explore V7's user-friendly interface, where you will learn how to effortlessly create datasets and upload images and videos through the intuitive GUI. You can easily connect your dataset to existing workflows or build new ones from scratch without the need for any coding.
Next, we will introduce you to the command line interface (CLI), demonstrating how to register local data using simple commands. Gain insights into optional arguments for video extraction frame rates, file exclusion, and multiple uploads to enhance your data management experience.
If your data is stored in an external storage bucket and privacy concerns require it to remain there, we have a dedicated method for you. We will guide you through the process of registering files from an external storage bucket directly into V7 using the REST API. This way, you can annotate your data without it ever leaving your secure storage, ensuring the utmost data privacy and compliance.
By the end of this video, you will have a comprehensive understanding of the three different methods for uploading data to V7: UI, CLI, and REST API. Whether you are new to V7 or looking to refine your data management skills, this video will empower you to handle your data efficiently and with confidence. For those dealing with sensitive data or working with multi-slotted items like DICOMs, this video will be particularly valuable, as we address those specific scenarios.