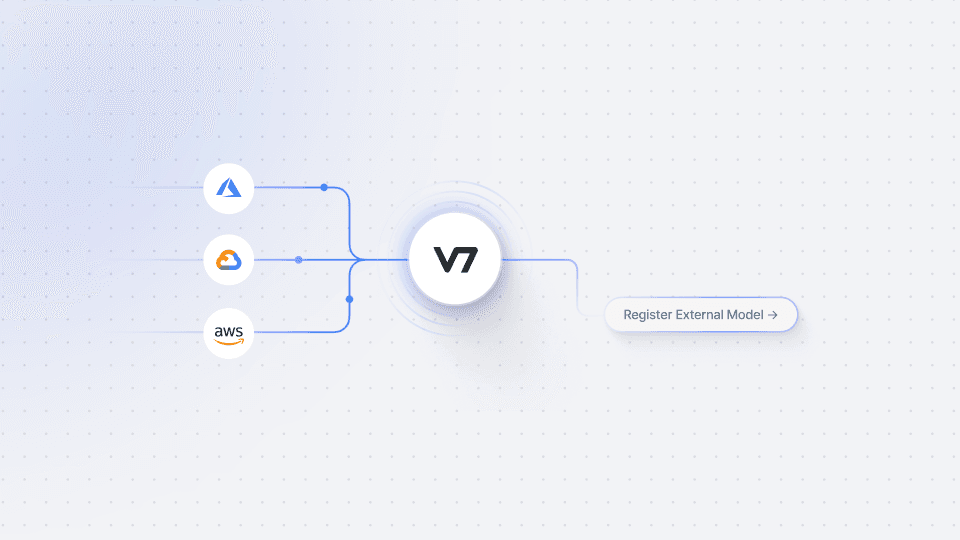
External Models
Play video
8:47
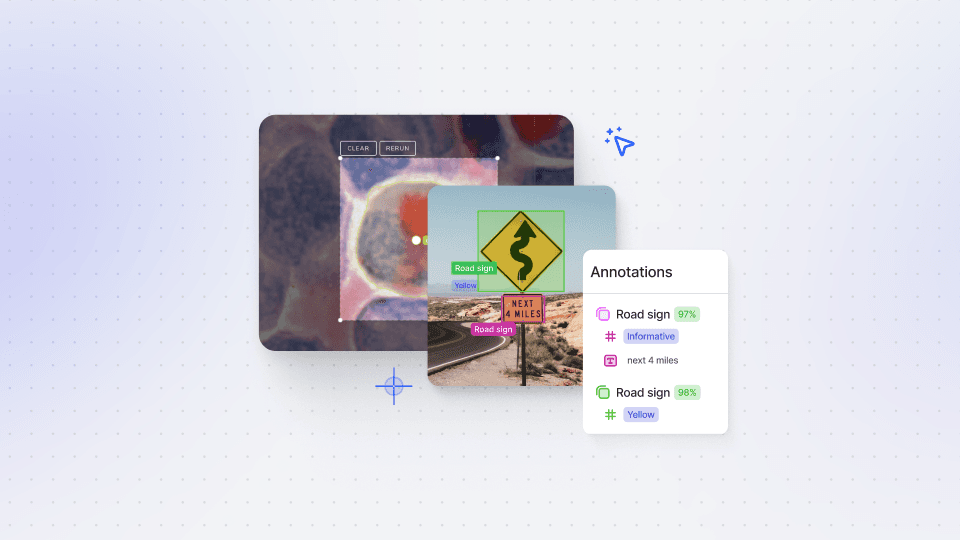
In this session, we will walk you through the process of registering and running inference on your own models in V7. Our recent Bring Your Own Model (BYOM) update has made it easier than ever to register external models with just a few clicks, unlocking a world of possibilities for your AI projects.
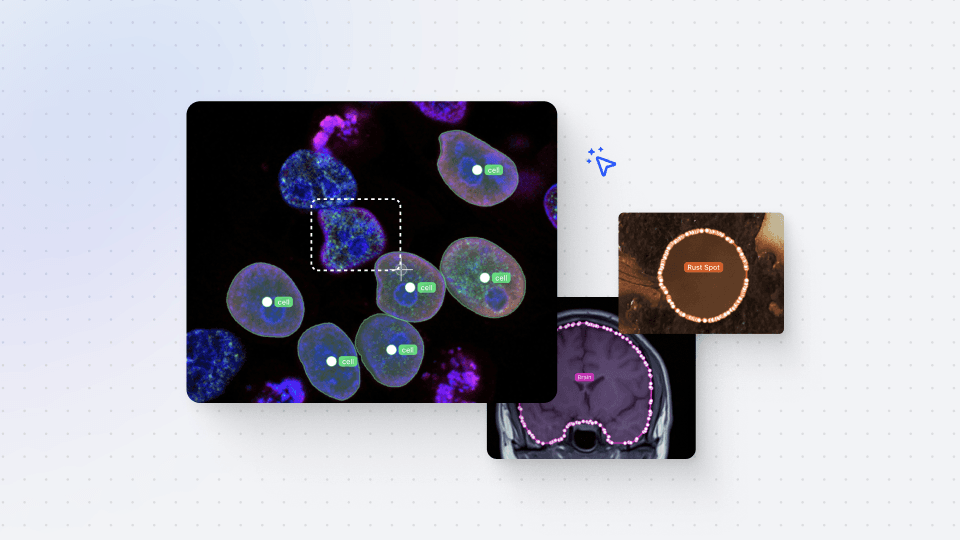
External models can be a game-changer, helping you accelerate your work or solve industry-specific challenges. For instance, if you require a tool for segmenting pieces of clothing, you can utilize an existing third-party instance segmentation model that has been fine-tuned specifically for clothing items.
To get started, we'll provide an overview of the setup, followed by a detailed explanation of the Darwin JSON structure and how request processing works. We will then guide you step-by-step through the process of registering an endpoint, setting up the web app, deploying the model, and finally, connecting and testing the model.
With the BYOM feature, you have the freedom to register custom models and integrate them seamlessly into V7. You can also leverage open-source models or connect with public models available online on platforms like Hugging Face. This flexibility empowers you to tailor your AI workflows to meet your specific requirements and harness the power of diverse AI models. It's worth noting that when using models hosted on Hugging Face, the process becomes even simpler. You can easily add the inference URL and upload a test photo to capture the response and map your classes.
Link to the model used in the tutorial: DETR (End-to-End Object Detection)