18 min read
—

Looking to dive deeper into foundation models? In this article, we’ll cover all the basics and throw in theoverview of their applications, benefits, and current landscape.

Foundation models have taken the world of AI by storm. These pre-trained powerhouses have revolutionized natural language processing, computer vision, and speech processing, remarkable advancements in various domains.
With their ability to understand language, images, or multimodal data at a deep level, foundation models have paved the way for cutting-edge AI applications and accelerated development timelines. From language models like GPT and BERT to vision models like ResNet, foundation models excel in various domains, serving as starting points for specialized tasks.
However, despite their immense potential, foundation models still pose challenges that must be addressed. From ethical considerations to data privacy concerns and model limitations, the journey of foundation models is not without obstacles.
In this article, we will discuss:
What are foundation models?
Foundation models examples
Types of foundation models
Applications of foundation models
Benefits of foundation models
Challenges of foundation models
Read on!

AI for document processing
Give Your Team AI Agents That Actually Retain Knowledge
Get started today
What are foundation models?
Foundation models, also known as pre-trained models, are large-scale artificial intelligence (AI) models trained on vast amounts of data to acquire a deep understanding of language, images, or other modalities. These models serve as a starting point for various AI tasks, as they have already learned valuable data representations and can be fine-tuned or adapted for specific applications.
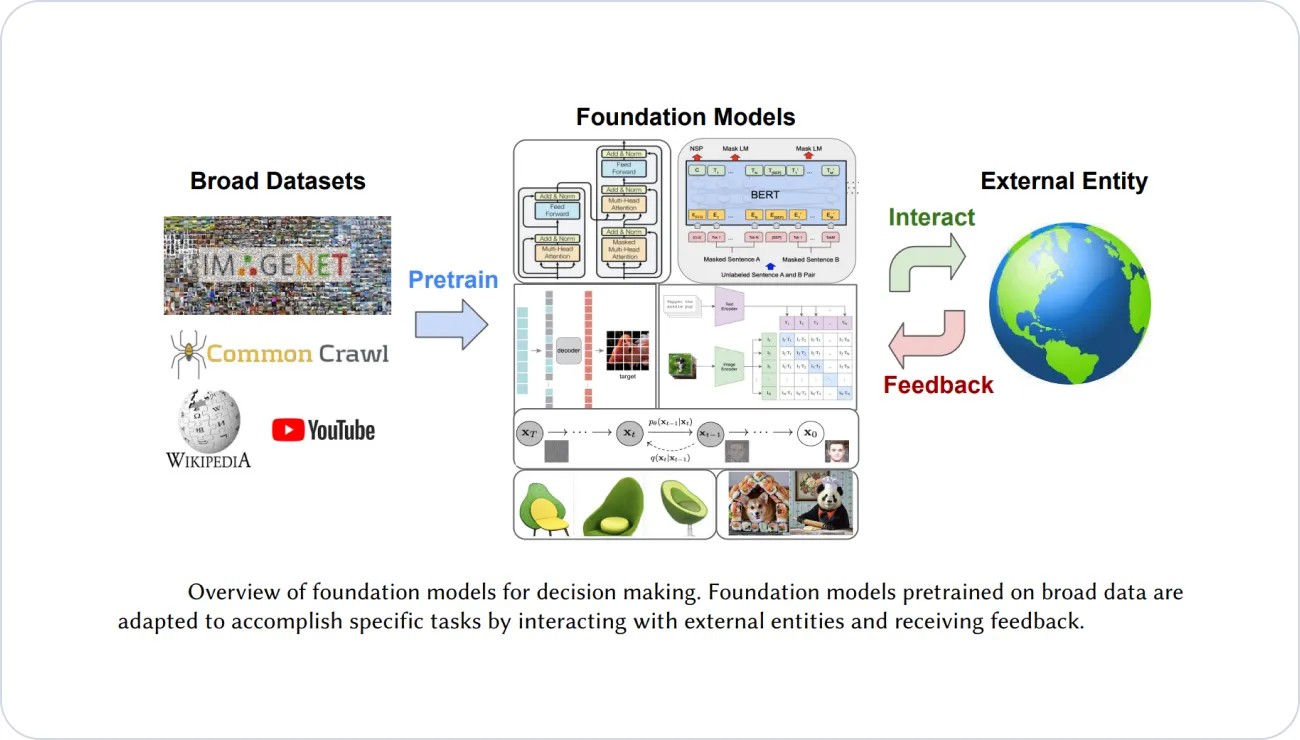
The training process of foundation models involves exposing the model to massive amounts of data, including text from books, articles, and websites, as well as image or video data. By learning from such extensive datasets, foundation models develop a broad understanding of the underlying patterns, semantics, and syntax of the data domain they have been trained on.
How transformers paved the way for foundation models
The architecture of foundation models plays a crucial role in their effectiveness. Transformer-based architectures, such as the popular GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) models, have been instrumental in advancing natural language processing tasks.
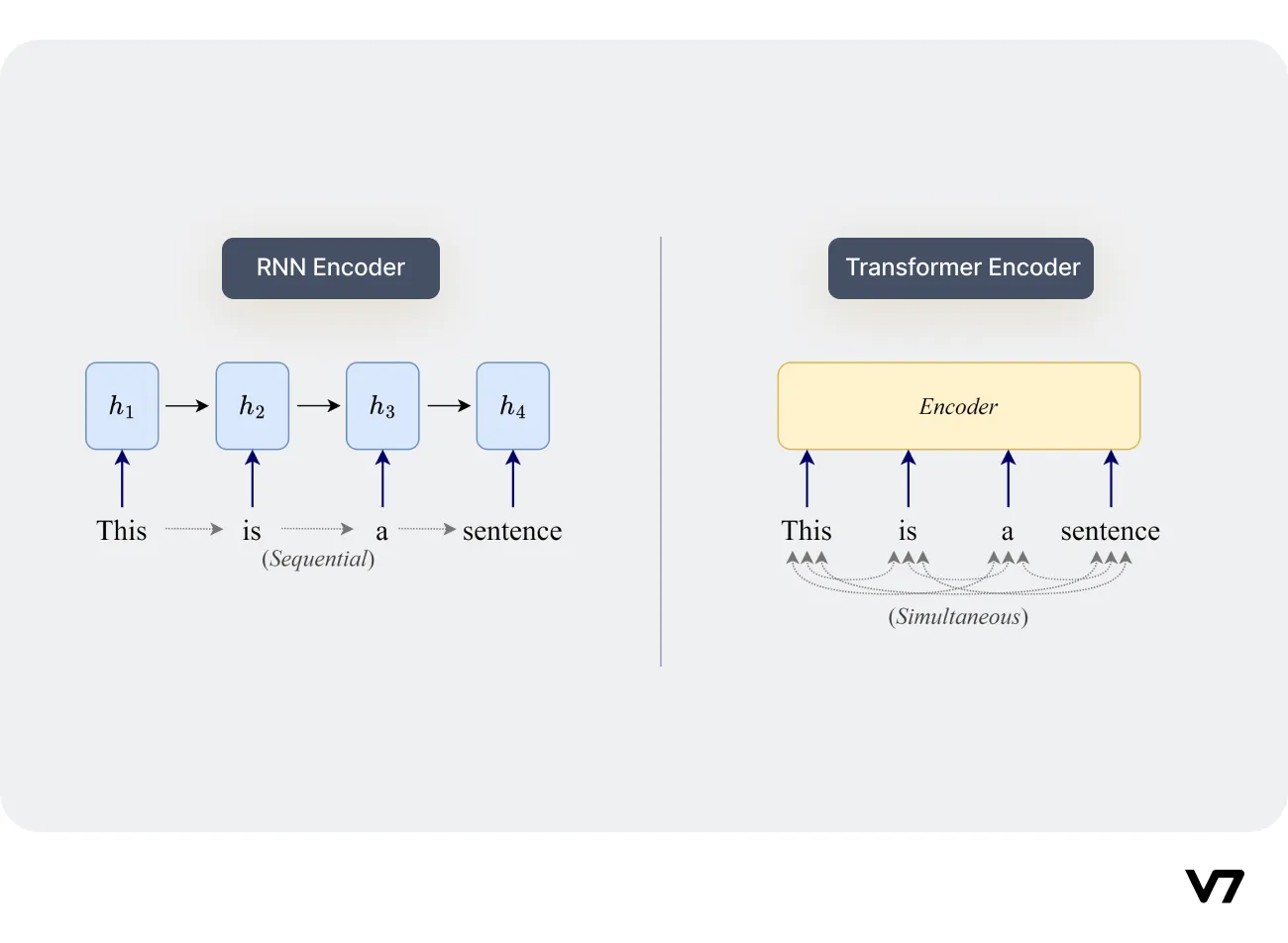
Prior to transformers, Recurrent Neural Networks (RNNs) were widely used for natural language processing tasks. However, RNNs struggled with capturing long-term dependencies, limiting their ability to understand context and generate coherent text.
Transformers introduced a revolutionary self-attention mechanism that transformed the landscape of language modeling. By allowing the model to attend to different parts of the input sequence, transformers could capture long-range dependencies and contextual relationships more effectively. This attention mechanism enabled the model to understand language at a deeper level, generating more accurate and coherent text.
Foundation models examples
Foundation models have made a significant impact across various domains, and several notable examples have emerged in recent years. Let's explore a few real-world examples and the foundation models they rely on.
BERT/Google
BERT (Bidirectional Encoder Representations from Transformers) is a groundbreaking foundation model in NLP developed by Google. It employs a transformer-based architecture, enabling it to capture contextual relationships and dependencies in text data for more accurate language understanding. BERT's key innovation lies in its bidirectional training approach, considering both left and right context to grasp word meaning in relation to the surrounding context.
Pre-trained on vast amounts of internet text data, BERT learns language patterns, grammar, and semantics through predicting masked words and understanding sentence relationships. It encodes words and sentences into fixed-length vectors (embeddings), capturing their contextual meaning.
Fine-tuning BERT for specific tasks, such as question answering, sentiment analysis, and named entity recognition, further enhances its performance and task-specific understanding.
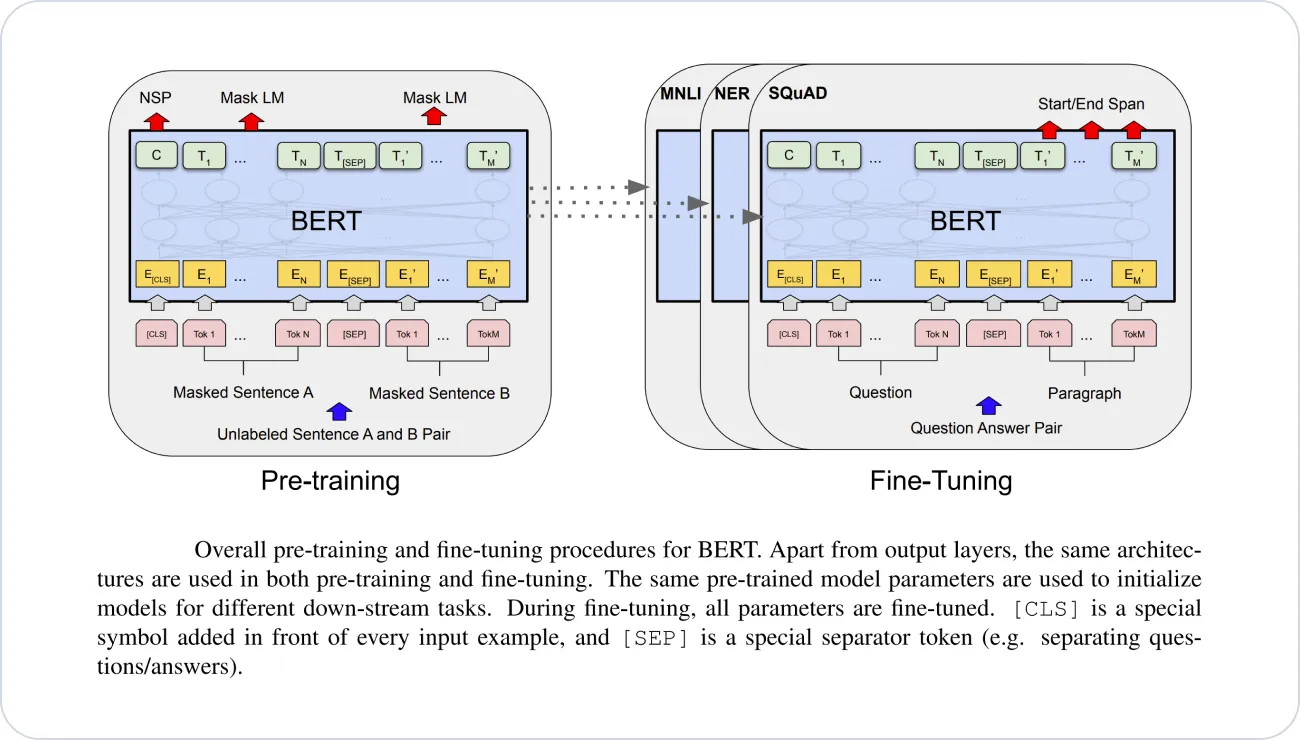
BERT has transformed NLP, setting new performance benchmarks and outperforming previous models. It finds wide-ranging use in sentiment analysis, question answering, text classification, natural language understanding, machine translation, named entity recognition, and more. As an open-source model, BERT's availability fosters collaboration, empowering researchers and practitioners to leverage its pre-trained representations and advance the field of NLP.
GPT/OpenAI
GPT (Generative Pre-trained Transformer) is a foundation model developed by OpenAI that has revolutionized the field of natural language processing (NLP). It has garnered widespread attention and acclaim for its exceptional language generation capabilities and ability to understand and process textual data. GPT is built on a transformer-based architecture, which allows it to capture complex contextual relationships in language and produce coherent and contextually rich text.
The training process of GPT involves pre-training on vast amounts of text data from the Internet, which enables the model to learn the intricacies of language, including grammar, syntax, and semantics. By training on a diverse range of text sources such as books, articles, and websites, GPT acquires a broad knowledge of language patterns and can generate human-like text based on a given prompt or input. The pre-training phase allows GPT to develop a deep understanding of language and form representations that capture the contextual meaning of words and sentences.
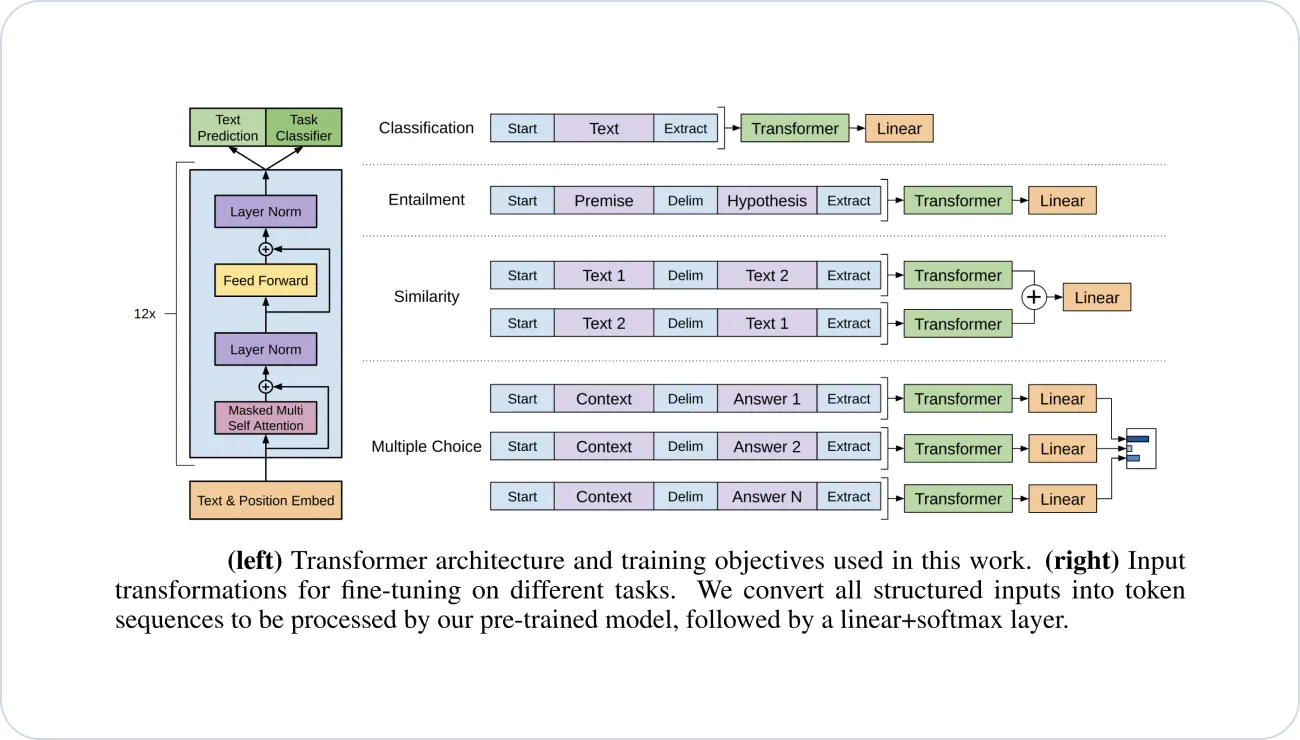
Once pre-training is complete, GPT can be fine-tuned for specific downstream tasks, such as text completion, dialogue systems, and content generation. Fine-tuning involves training the model on task-specific datasets with labeled data, allowing it to adapt and specialize for the desired task. During fine-tuning, the model's parameters are adjusted based on the patterns and features required for the specific task, resulting in improved performance and task-specific language understanding. GPT's fine-tuning capability makes it highly versatile and applicable to a wide range of NLP applications.
GPT has been widely adopted in various industries and domains, including content creation, virtual assistants, customer support chatbots, and creative writing. Newer versions of GPT are even larger and can perform tasks even better. For example, the revolutionary ChatGPT is built on GPT-4.
Read more: Large Language Models (LLMs): Challenges, Predictions, Tutorial
Megatron-Turing/NVIDIA
Megatron-Turing is an advanced foundation model developed by NVIDIA, named after the fictional character Megatron from Transformers and the renowned mathematician Alan Turing. This model combines the power of NVIDIA's Megatron-LM and Turing NLP technologies to push the boundaries of language processing and understanding.
Megatron-Turing is a 105-layer transformer-based architecture with 530 billion parameters, similar to other foundation models. However, what sets Megatron-Turing apart from other models is its massive scale and computational capabilities. It leverages extensive parallelism and distributed training techniques to train on vast amounts of text data, enabling it to learn complex language patterns and generate high-quality text with enhanced fluency and coherence.
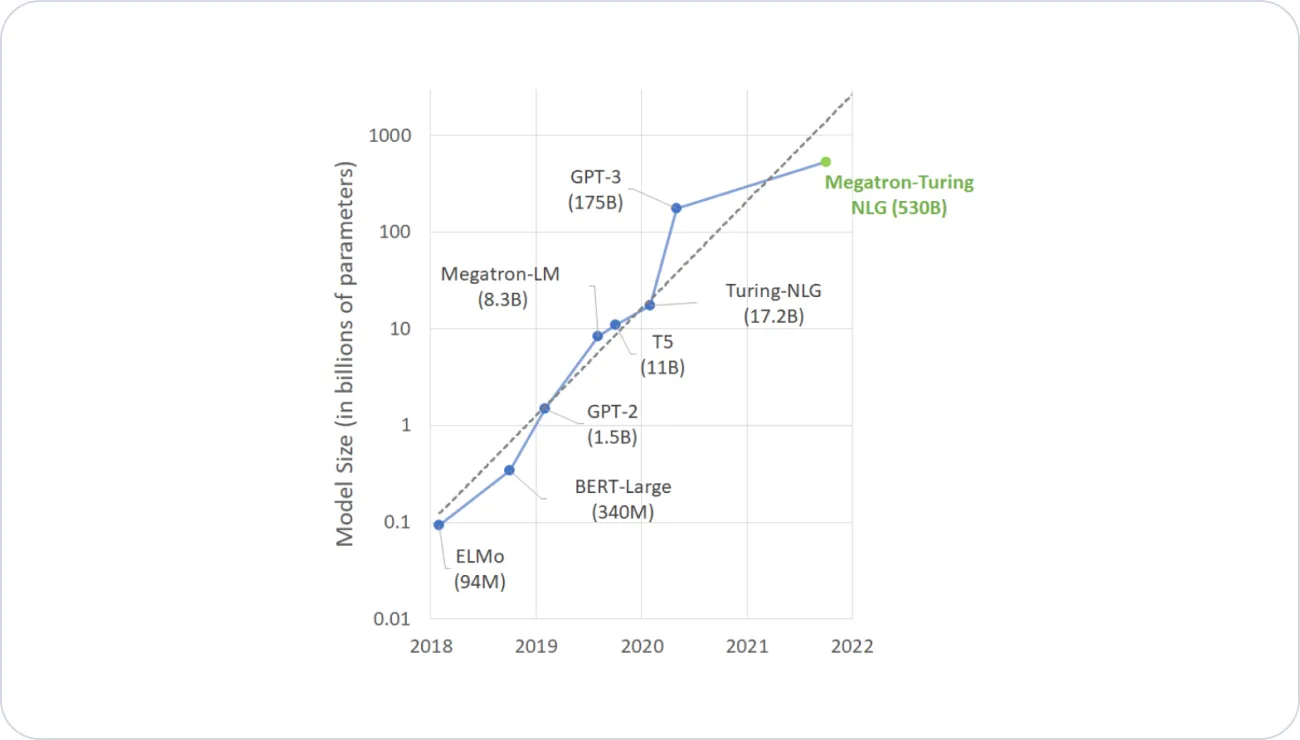
Timeline of Language Model sizes (Source)
The training process of Megatron-Turing involves pre-training on diverse and extensive datasets, such as books, articles, and web pages, to capture a broad understanding of the English language. This pre-training phase allows the model to learn grammar, syntax, and semantics—thanks to which, the model can generate text that exhibits human-like fluency and context sensitivity. Additionally, Megatron-Turing integrates advanced techniques such as unsupervised learning, which allows it to acquire knowledge from unlabeled data, further enhancing its language understanding capabilities.
DALL-E-2/OpenAI
DALL-E-2 is a groundbreaking foundation model developed by OpenAI that has pushed the boundaries of generative image synthesis. It takes its name from the renowned artist Salvador Dalí and the Pixar character WALL-E, signifying its ability to create surreal and imaginative images. DALL-E-2 is built upon the transformer-based architecture, similar to the other foundation models, but focuses on generating images from textual descriptions.
The DALL-E-2 model proposes a combination of two prominent approaches to address the task of text-conditional image generation. These approaches include the CLIP model, renowned for its success in learning representations for images, and diffusion models, which are generative modeling frameworks that have achieved state-of-the-art performance in generating images and videos.
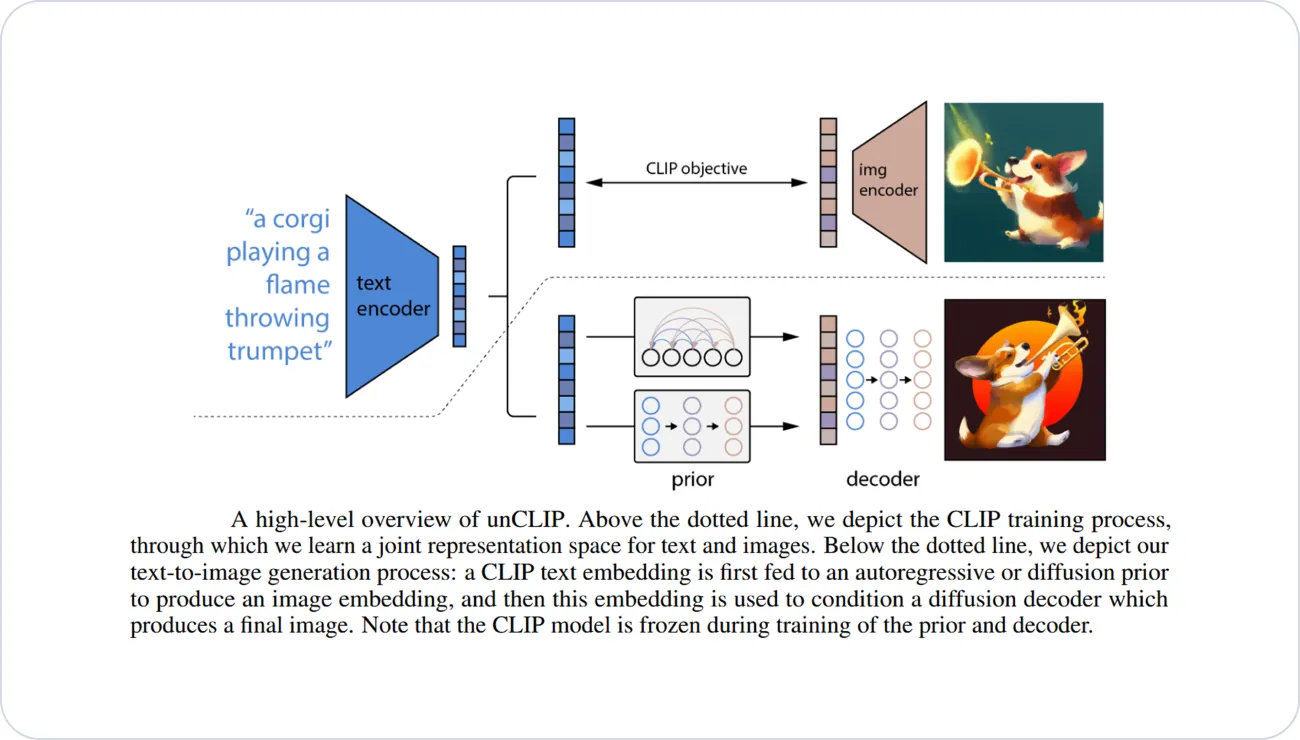
The architecture of DALL-E-2 includes a diffusion decoder that serves to reverse the process of the CLIP image encoder. Notably, the inverter of the model is non-deterministic, enabling the generation of multiple images corresponding to a given image embedding. This integration of an encoder and its approximate inverse, known as the decoder, extends the model's capabilities beyond mere text-to-image translation.
Examples of images produced by the Dall-E-2 model from natural language prompts are shown below.
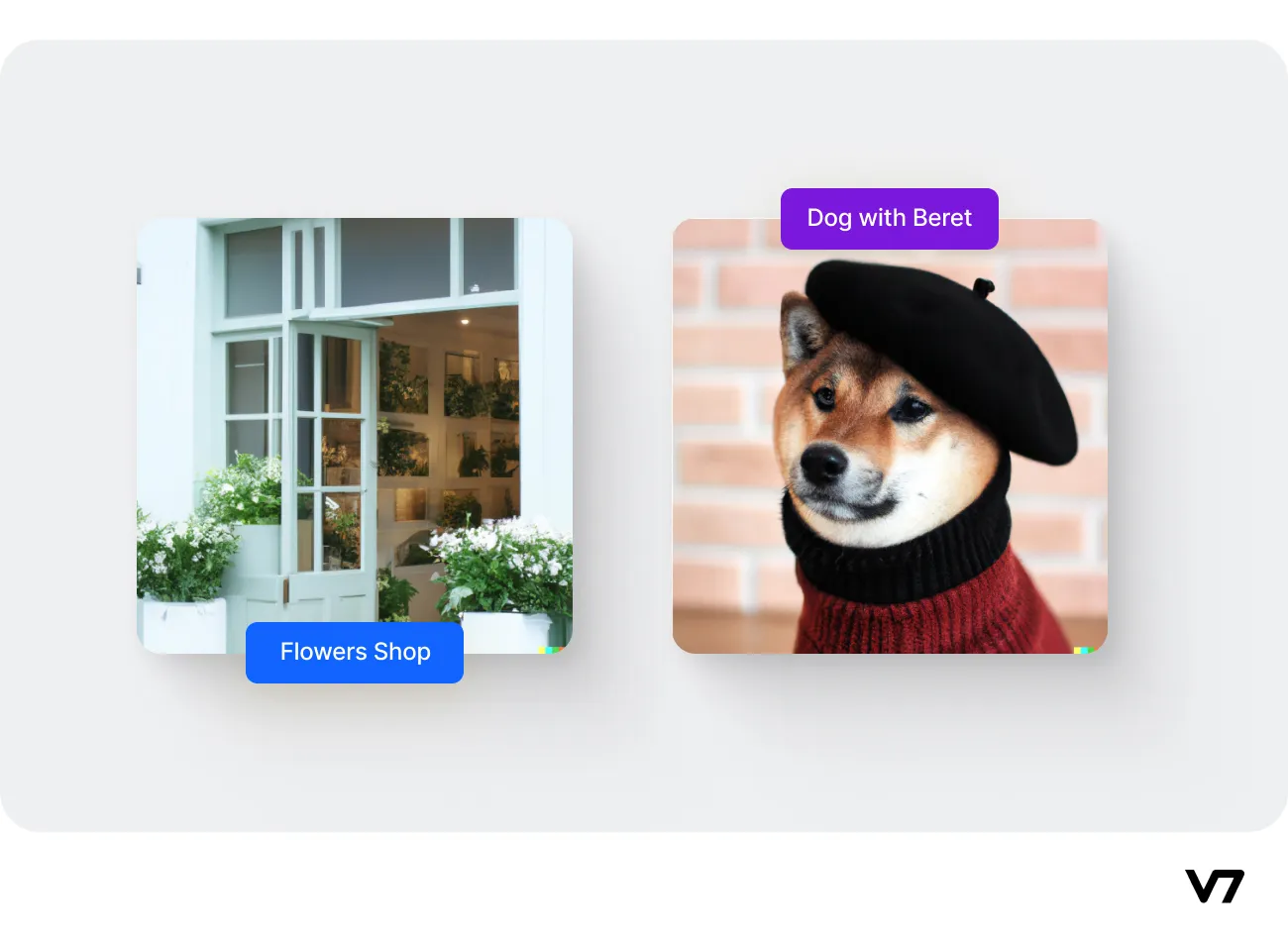
Prompts: “A photo of a quaint flower shop storefront with a pastel green and clean white facade and open door and big window” on the left and “A Shiba Inu wearing a beret and black turtleneck” on the right
Types of foundation models
The different types of foundation models serve as the building blocks for various AI applications and research. They provide a starting point for developers and researchers to leverage pre-trained models and adapt them for specific tasks, saving time and resources in model development.
The diversity of foundation models allows for a wide range of applications, enabling advancements in natural language processing, computer vision, speech recognition, etc.
Let us dive into these types of learning models in more detail.
Language models
Language models focus on understanding and generating human language. They have revolutionized natural language processing (NLP) tasks such as text classification, sentiment analysis, machine translation, and question answering.
BERT and GPT are prime examples of the continuous advancements in language foundation models. These models have played a pivotal role in enhancing the accuracy and capabilities of various language processing tasks, while also contributing to a deeper understanding of the intricacies of human language. These models leverage deep learning architectures to capture the contextual relationships between words and generate coherent and contextually relevant text.
The improved accuracy and understanding of language through these foundation models have opened doors to more sophisticated applications, such as dialogue systems, language translation, and AI assistants (ChatGPT) that can converse and interact with users in a more natural and meaningful way.
Read more: Impact of Large Language Models on Enterprise: Benefits, Risks & Tools
Vision models
Vision foundation models have played a crucial role in revolutionizing the field of computer vision, enabling machines to perceive and understand visual information with remarkable accuracy and efficiency. These models have significantly advanced tasks such as image classification, object detection, segmentation, and image generation.
Convolutional Neural Network (CNN) models have been instrumental in image classification tasks, where the goal is to categorize images into predefined classes. Models like AlexNet, VGGNet, and ResNet have achieved remarkable success in large-scale image recognition challenges, surpassing human-level performance in some cases.
However, these networks are limited—this kind of foundation model can perform only one task. A more advanced foundation model that can be employed for multiple tasks is the SimCLR architecture.
SimCLR is a popular Self-Supervised foundation model for vision applications that leverages the concept of contrastive learning, where the model learns to maximize the agreement between different views of the same data while minimizing the agreement between views of different data points. This approach allows the model to learn rich representations that capture the underlying structure and semantics of the data.
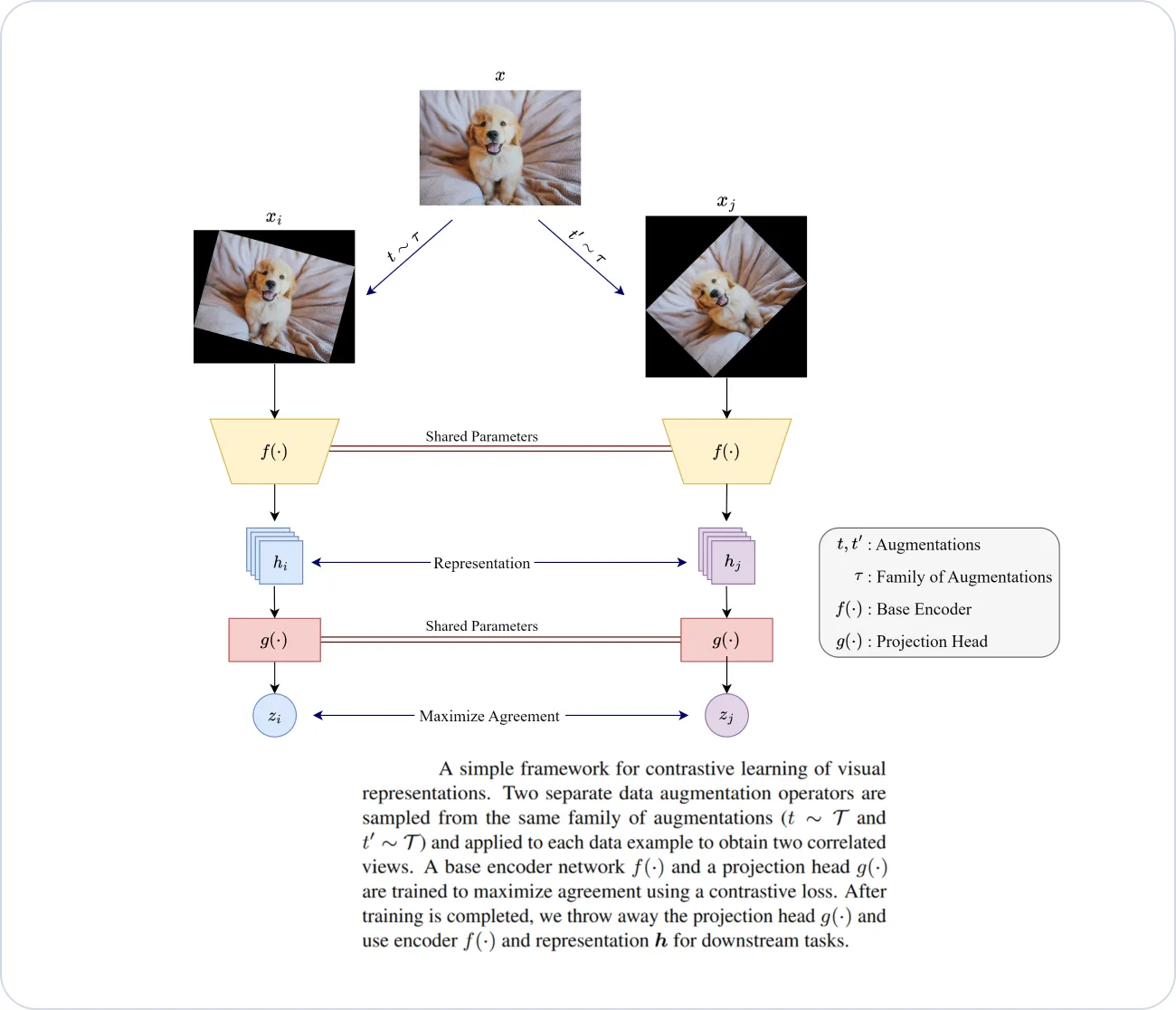
Working principle of SimCLR. Image by the author.
In SimCLR, the model takes pairs of augmented views (like cropping, flipping, etc.) of the same input data and maps them to embeddings in a shared latent space. The model then uses a contrastive loss function to encourage the embeddings of positive pairs (same data point) to be closer together and push the embeddings of negative pairs (different data points) further apart.
By training on a large amount of unlabeled data, SimCLR learns to encode useful and discriminative features in the shared latent space. These features can later be used for various downstream tasks such as image classification, object detection, or image retrieval.
Speech models
Speech foundation models have significantly advanced tasks such as automatic speech recognition (ASR), speech synthesis, speaker identification, and even emotion recognition. Deep learning architectures, such as recurrent neural networks (RNNs) and CNNs can capture temporal dependencies and learn intricate patterns in speech signals, allowing for robust and accurate speech recognition.
Recent advancements in speech foundation models have incorporated transformer-based architectures, similar to those used in language models like BERT and GPT. The transformer architecture leverages self-attention mechanisms to capture long-range dependencies in the speech signal, enabling a more comprehensive understanding of spoken language.
The impact of speech foundation models extends beyond traditional speech recognition and synthesis applications. These models have found applications in voice assistants, call center automation, language translation, and even medical transcription. By leveraging the power of deep learning and innovative architectures, speech foundation models continue to push the boundaries of speech understanding, enabling machines to interact with and process spoken language in a variety of real-world scenarios.
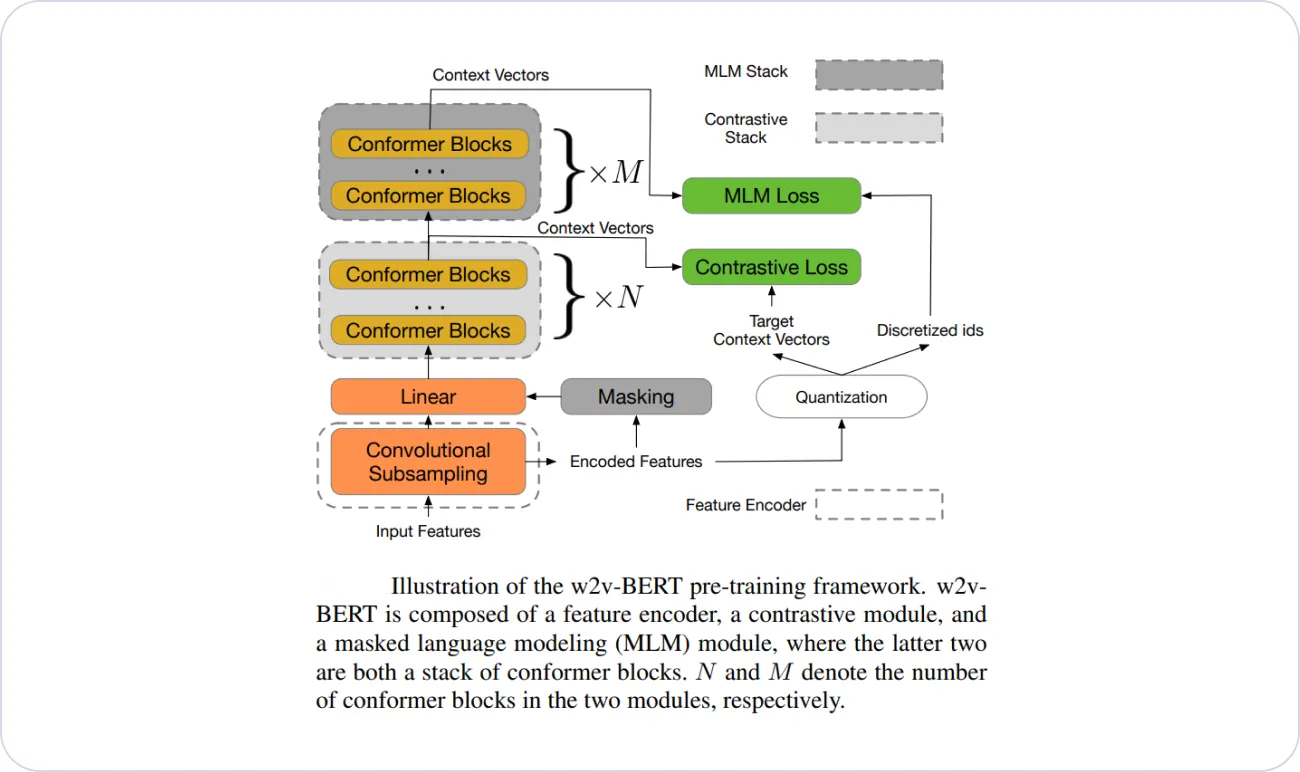
One of the most popular speech foundation models is the w2v-BERT model. It combines the core methodologies from two recent frameworks for self-supervised pre-training of speech and language, respectively: wav2vec 2.0 and BERT.
The idea of w2v-BERT is to use the contrastive task defined in wav2vec 2.0 to obtain an inventory of a finite set of discriminative, discretized speech units. Then, the units are used as a target in a masked prediction task in a way that is similar to masked language modeling (MLM) proposed in BERT for learning contextualized speech representations.











Applications of the foundation models
Foundation models have found numerous applications across various domains, leveraging their capabilities in natural language processing, computer vision, and speech processing. Let’s go through a few of the most significant applications.
Language translation
Foundation models like Google's Neural Machine Translation (GNMT) and OpenAI's GPT have been used to improve the accuracy and fluency of machine translation systems. These models can understand the context of the source language and generate more accurate translations, enabling effective communication across different languages.
Research
Foundation models have proven to be valuable tools in the research community. They can help researchers analyze large volumes of text data, extract meaningful insights, and generate summaries or abstracts of research papers. They can help analyze logistics and accelerate developments in the manufacturing and biotechnology industries.
Object detection
Object detection is the process of locating and classifying objects within images or videos. Foundation models such as YOLO (You Only Look Once) and Faster R-CNN (Region-based Convolutional Neural Networks) have significantly improved object detection accuracy and efficiency, enabling applications such as autonomous vehicles, surveillance systems, and augmented reality.
Healthcare
Foundation models are revolutionizing healthcare by aiding in medical diagnosis, drug discovery, and personalized treatment recommendations. They can analyze medical images, patient records, and genetic data to assist in disease identification, predict patient outcomes, and support healthcare professionals in making informed decisions.
Read more: 7 Life-Saving AI Use Cases in Healthcare
Generative art and content creation
Foundation models such as DALL-E and GPT-3 have been employed to generate creative content, including artwork, poetry, and prose. These models can generate text descriptions based on image prompts, compose coherent and creative stories, and even create unique visual artworks based on textual descriptions.
Read more: Generative AI 101: Explanation, Use Cases, Impact
Virtual assistants and chatbots
Language models such as GPT-3 and BERT have been utilized in the development of virtual assistants and chatbots. These models can understand natural language inputs, provide informative responses, and assist users with tasks such as answering questions, making recommendations, and providing customer support. An AI-powered coding assistant can suggest code completions, provide context-aware code recommendations, etc.
Cloud-based solutions
Foundation models are often deployed in the cloud to provide AI-powered services and solutions. Cloud-based platforms leverage foundation models to offer various functionalities such as natural language understanding, sentiment analysis, chatbots, recommendation systems, and image recognition. These services enable businesses to integrate AI capabilities into their products and applications without building and training models from scratch, accelerating their time to market and expanding their offerings.
These are just a few examples of how foundation models have been applied across different fields. The versatility and adaptability of these models allow them to be utilized in a wide range of applications, enabling advancements in language understanding, image processing, and speech recognition.
Benefits of foundation models
Foundation models offer several benefits that contribute to their widespread adoption and impact in various fields. Here are some key benefits of foundation models.
Adaptability
Foundation models are pre-trained on large-scale datasets, which enables them to learn general features and patterns from diverse data sources. This pre-training allows the models to comprehensively understand language, images, or multimodal data. The knowledge gained during pre-training can then be transferred and fine-tuned for specific tasks with relatively smaller labeled datasets. This adaptability makes foundation models versatile and applicable to various tasks, enabling developers and researchers to tailor the models to their specific needs.
Time and cost-effectiveness
Foundation models provide a significant advantage in terms of time and cost savings. The pre-training phase of foundation models involves training on massive datasets, which requires substantial computational resources and time. However, once pre-training is complete, the resulting model can be reused and fine-tuned for multiple downstream tasks. This eliminates the need to train models from scratch for each new task, saving both time and computational resources. Additionally, fine-tuning a pre-trained model requires a smaller labeled dataset compared to training a model from scratch, further reducing data collection and annotation costs.
Fine-tuning
Foundation models offer the flexibility of fine-tuning, which allows developers to adapt the pre-trained models to specific tasks or domains. Fine-tuning involves training the model on task-specific datasets with labeled examples. By adjusting the model's parameters during fine-tuning, developers can enhance its performance, accuracy, and domain-specific understanding. This process allows for customization of the foundation model to tackle specific challenges and produce better results for the intended application. Fine-tuning leverages the knowledge acquired during pre-training and tailors it to the specific requirements of the target task, maximizing the effectiveness of the foundation model.
Challenges of foundation models
While foundation models offer numerous benefits, they also present several challenges that need to be addressed. Here are the key challenges associated with foundation models:
Data scarcity
Foundation models require large-scale and diverse datasets for pre-training. Acquiring and curating such datasets can be a challenging task. Data collection may involve privacy concerns, copyright issues, or difficulties in obtaining labeled data for specific tasks. Furthermore, ensuring the quality and representativeness of the training data is crucial to avoid biases and improve generalization. Collecting, cleaning, and organizing large volumes of data requires significant resources and expertise.
Machine learning bias
Bias is a significant challenge in foundation models. Biases present in the training data can lead to biased or unfair outcomes in the model's predictions or decisions. For example, if the training data predominantly represents certain demographics or perspectives, the model may show biases towards those groups. Addressing bias requires careful data curation, diversity in the training data, and ongoing monitoring and evaluation of the model's outputs. Ethical considerations and fairness assessments should be incorporated throughout the model development pipeline to ensure that biases are minimized and that the model's outputs are fair and unbiased.
Scaling issues
Foundation models, particularly those with large architectures and parameters, require significant computational resources to train and deploy. Training these models on extensive datasets can be computationally intensive and time-consuming. This poses challenges for organizations or individuals with limited access to high-performance computing infrastructure. Additionally, deploying large-scale models in real-world applications may require efficient hardware and optimized software frameworks to ensure timely and efficient inference. The scale-related challenges highlight the need for scalable infrastructure, resource allocation, and optimization techniques to utilize foundation models in practical scenarios effectively.
The future of foundation models
The future of foundation models is promising, as they continue to drive innovation and advancements in the field of artificial intelligence. Here are some key aspects that shape the future of foundation models:
Enhanced performance. Foundation models will continue to evolve, improving performance in various tasks. As researchers explore new architectures, training techniques, and data augmentation strategies, foundation models will become more accurate, efficient, and capable of handling complex tasks. This will likely lead to the development of more sophisticated AI applications with higher levels of precision and reliability.
Multimodal understanding. The integration of multiple modalities, such as language, vision, and speech, is an exciting direction for foundation models. Multimodal models can understand and generate content that combines different modalities, leading to applications that can process and generate text, images, and audio simultaneously. This will enable more immersive and interactive user experiences, as well as facilitate cross-modal understanding and communication.
Transfer learning and generalization. Transfer learning, the ability of models to leverage knowledge learned from one task to another, will continue to play a crucial role in foundation models. By pre-training on large-scale datasets and fine-tuning for specific tasks, models can quickly adapt and generalize across various domains. This will expedite the development of AI solutions, as models can be readily applied to new tasks with minimal training data, reducing the need for extensive retraining from scratch.
Addressing ethical considerations. As foundation models become more prevalent in real-world applications, addressing ethical issues is unavoidable. The AI community will focus on mitigating biases, ensuring fairness, promoting transparency, and addressing concerns related to privacy and responsible use of AI technologies. Developing guidelines, frameworks, and tools to evaluate and mitigate these ethical considerations will shape the future of foundation models and their responsible deployment.
Democratization of AI. Foundation models have already contributed to the democratization of AI by providing accessible, pre-trained models to developers and researchers. This trend is likely to continue, making AI more accessible to a wider audience. Open-source initiatives, collaborations, and knowledge sharing will drive the adoption and refinement of foundation models, allowing individuals and organizations with limited resources to leverage state-of-the-art AI capabilities.
Bonus: Using foundation models in V7
Connecting large language models to your Darwin workflow takes just a few steps.
With V7’s Bring Your Own Model feature, you can bring custom models to V7, use open-source models, or even connect public models available online on platforms such as HuggingFace.
Watch this video to see how it works:


Rohit Kundu is a Ph.D. student in the Electrical and Computer Engineering department of the University of California, Riverside. He is a researcher in the Vision-Language domain of AI and published several papers in top-tier conferences and notable peer-reviewed journals.

