Document processing
13 min read
—



Every insurance claim begins with a single event: the policyholder picks up the phone, fills out a form, or sends an email. That moment is FNOL, or First Notice of Loss, and it sets every downstream process in motion. In an industry where AI in insurance is reshaping operations end to end, FNOL remains one of the most document-intensive, error-prone handoffs in the entire claims lifecycle.
The FNOL moment shapes more than the opening record. The initial reserve level set at this stage feeds directly into the insurer's financial reporting. The adjuster assigned here determines how fast the investigation can begin. And the first documented account of the loss becomes the baseline against which every subsequent change in damages, liability assessment, or fraud indicators is measured — errors at intake do not stay at intake.
The J.D. Power 2023 U.S. Property Claims Satisfaction Study identifies initial claims reporting as the stage that generates more claimant problems than any other point in the process. At the same time, claims volume is rising, staff capacity is flat, and policyholders expect resolution in hours, not weeks.
The result is an intake process under structural pressure. Documents arrive in dozens of formats: police reports, repair estimates, medical records, photos, and coverage declarations. Someone has to read each one, extract the right fields, and push data into the claims management system. When that someone is a human adjuster working a queue of hundreds of open files, errors accumulate and cycle times stretch.
AI document automation addresses the document problem directly. Modern AI agents read every document in the intake packet, extract structured fields, flag mismatches and missing values, and write to the claims system in minutes, not days.
This guide covers how FNOL works, where the process stalls, and how AI is enabling insurers to cut intake cycle times while improving data accuracy and regulatory compliance.
What you will find in this article:
A step-by-step breakdown of the FNOL process
The operational bottlenecks that slow manual intake
How AI agents extract and validate structured claim data from unstructured documents
Regulatory requirements for AI-assisted claims decisions
How V7 Go handles FNOL document extraction in production

Document processing
AI for document processing
Get started today
What Is FNOL in Insurance?
FNOL stands for First Notice of Loss. It is the formal notification that a policyholder submits to their insurer when a covered event occurs — a car accident, a house fire, a workplace injury, a cargo shipment reported stolen. The FNOL is not a full investigation; it is the trigger that opens the claims file and sets every downstream process in motion.
At its core, the FNOL is a data collection event. The insurer needs, at minimum: the policy number and policyholder identity, the date, time, and location of the loss, the type of incident, the parties involved and their contact details, an initial description of damages or injuries, and whatever supporting documentation the claimant can provide at the time of filing.
This data feeds every decision that follows. Coverage verification confirms the loss falls within policy scope. Reserve setting produces an initial estimate of total claim cost that affects financial reporting and adjuster authority. Triage determines whether the claim routes to fast-track, specialist, or special investigations handling. Poor data quality at FNOL compounds downstream: a misspelled policy number delays coverage verification; a missing date of loss creates reserve ambiguity; an incomplete damage description forces the adjuster to call the claimant back, adding days to the cycle.
FNOL also carries a legal dimension. Most insurance policies require the insured to report losses promptly or within a defined window. Missed FNOL deadlines can affect claim validity. On the insurer's side, regulatory frameworks in many jurisdictions require acknowledgement of the FNOL within 10 to 15 business days of receipt and set maximum timelines for claims resolution.
In claims management vocabulary, FNOL is distinct from the full claims file. The FNOL record captures the initial report. The full file accumulates documentation, adjuster notes, correspondence, estimates, expert opinions, and legal materials over the life of the claim. FNOL quality therefore has a multiplier effect: every document that enters the file after the initial report is anchored to the FNOL data. If the opening record contains errors, every subsequent document that references or updates it carries those errors forward.
FNOL is also particularly time-sensitive by line of business. In auto insurance, carriers expect FNOL within hours of the accident and use real-time intake data to dispatch roadside assistance, arrange rental vehicles, or initiate total loss evaluation. In workers' compensation, employers face regulatory requirements to file FNOL with state agencies within defined windows, often 24 to 48 hours of learning of an injury. In commercial property, FNOL triggers preservation of evidence and the mitigation obligations that determine coverage applicability. The time window is not just an operational target; in many lines, it is a legal requirement with direct consequences for claim validity.
The FNOL Process: Step by Step
FNOL handling varies by line of business. Auto claims move faster than commercial property; liability claims involve more third-party documentation than first-party. The core intake sequence is consistent across carriers.
Step 1: Loss occurrence and initial contact. The policyholder or a third party contacts the insurer by phone, web portal, mobile app, agent, or email. In commercial lines, the broker often files on the client's behalf.
Step 2: Identity and policy verification. The insurer confirms the policyholder's identity, validates the policy number, and checks that coverage was in force on the date of loss.
Step 3: Loss data capture. A claims representative or an automated intake system collects the structured fields above: date, location, incident type, parties, damages. This creates the FNOL record in the claims management system (CMS).
Step 4: Documentation collection. The claimant provides supporting documents: police reports, photos, repair estimates, medical bills, invoices, witness statements. In complex claims, this step involves dozens of files arriving over days or weeks.
Step 5: Reserve setting. Based on the FNOL data, the insurer sets an initial loss reserve, an estimate of total claim cost, which affects financial reporting and adjuster authority levels.
Step 6: Adjuster assignment and triage. The claim routes to the appropriate adjuster or team: fast-track handling for straightforward claims, specialist assignment for complex or high-value losses, special investigations unit (SIU) referral when fraud indicators are present.
Each handoff in this chain is a potential delay point. Each field that requires manual lookup or re-entry is a potential error. Each document that sits unread in an email queue is a day added to the cycle time.
Where Manual FNOL Breaks Down
Manual FNOL processing works at low volume. It fails at scale.
The J.D. Power 2023 Property Claims Satisfaction Study found that nearly one in five claimants reports problems during initial claims reporting, more than at any other stage. Yet most insurers run intake processes that add 48 to 72 hours to the point at which structured data reaches the adjuster. The gap between claimant expectation and operational reality is wide.
Three structural problems drive this:
Document format fragmentation. Claims documents arrive as PDFs, photos, scanned paper forms, handwritten notes, and free-text emails. No two police report formats are identical. No two repair shop invoices use the same field layout. Rules-based extraction systems handle this by building templates for known document types. When a new format arrives, the template fails and the document falls to manual review. These systems automate only what they have seen before, and every new format requires engineering time to add.
Data entry error and re-keying. Claims representatives enter CMS data by reading documents and typing fields. Manual data entry error rates run between 1% and 3% per field. This sounds minor until you consider that a complex commercial claim may involve 200 or more fields, and that a single transposed digit in a policy number can block coverage verification entirely.
Queue depth and staffing constraints. Claims volume spikes after weather events, natural disasters, and economic shocks. Staffing cannot scale at the same rate. The result is queue depth that stretches acknowledgement times beyond regulatory thresholds and creates adjuster burnout that raises error rates further.
The compounding effect of these three problems is significant. A document arrives in an unfamiliar format and gets flagged for manual review. The manual reviewer misreads a field and makes a data entry error. That error enters the CMS and sits in the live claims file. A supervisor catches it during a quality audit and sends the record back for correction. The original document is retrieved, the correction is made, and the record is reprocessed. Two or more days of adjuster time are consumed on a single field. This is not an edge case. It is the normal failure mode of manual FNOL intake at volume.
McKinsey estimates that AI-driven claims automation can reduce loss adjustment expenses by 25 to 30 percent. That figure reflects the structural cost of these inefficiencies, and the scale of the opportunity to address them through automated claims processing.
How FNOL Automation Is Changing the Intake Channel
Automation at FNOL does not mean replacing claims representatives with chatbots. It means removing the document-processing burden from the intake workflow so that representatives can focus on policyholder communication, coverage judgment, and complex case decisions.
The automation stack operates in three layers:
Intake channel automation. Web portals, mobile apps, and AI-assisted phone systems capture structured FNOL data at point of first contact. These channels reduce the manual transcription step by collecting fields directly into the CMS, but they do not solve the document problem. The claimant still needs to upload a police report, a repair estimate, or a medical bill, and those documents still need to be read and processed.
Document extraction automation. AI document extraction systems read every file in the claim packet, identify relevant fields regardless of document format, and write structured data into the CMS. This is the highest-value automation layer in FNOL because it addresses the format fragmentation problem that manual and rules-based systems cannot.
Triage and routing automation. Once structured data is in the CMS, automated rules route straightforward claims to fast-track processing, flag complex claims for specialist assignment, and refer fraud indicators to the SIU. This layer depends entirely on the quality of extracted data from the layer above.
The three layers are additive. Better intake channel data feeds better extraction. Better extraction data feeds better triage. The accuracy and completeness of the document extraction step determines the quality of the full automation stack. For insurers measuring the first operational return on automation investment, data completeness at the point the adjuster opens the file is the clearest leading indicator of whether the system is working.
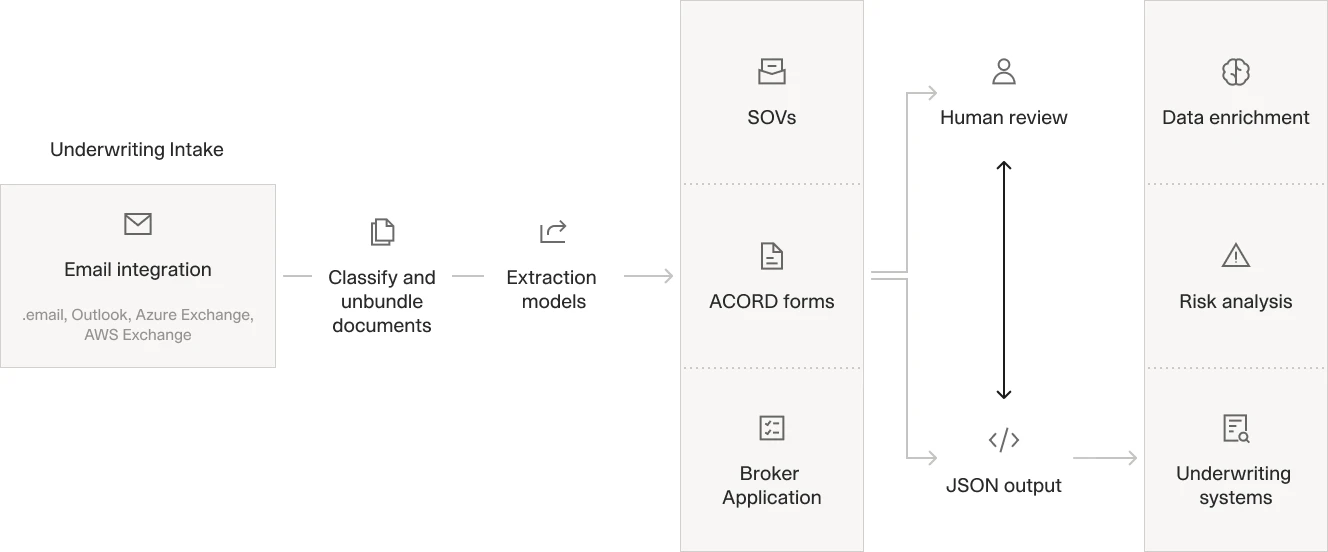











AI Document Extraction at the Point of First Notice
The document extraction problem at FNOL is harder than it looks. A multi-document claim packet might contain a police report from one jurisdiction, a repair estimate from an independent shop, photos from the claimant's phone, and a coverage declaration from the insurer's own system. All arrive as separate uploads, all with different layouts, and all requiring the same set of fields extracted into the CMS.
Rules-based extraction systems handle this by building templates for known document types. When a new format arrives, the template fails and the document falls through to manual review. These systems automate only the documents they have seen before, and every new format requires engineering time to handle.
AI document extraction works differently. Instead of matching templates, it reads documents the way a trained analyst would: understanding context, inferring field meaning from surrounding text, and adapting to layout variation without requiring a pre-built template for every format. A well-calibrated extraction model can handle a police report from any jurisdiction, an estimate in any shop format, and a medical bill from any provider, extracting the same fields into the same CMS schema each time.
How V7 Go Handles FNOL Document Extraction
V7 Go is an agentic document processing platform used by insurance carriers and third-party administrators (TPAs) to automate FNOL intake, claims document extraction, and underwriting data capture.
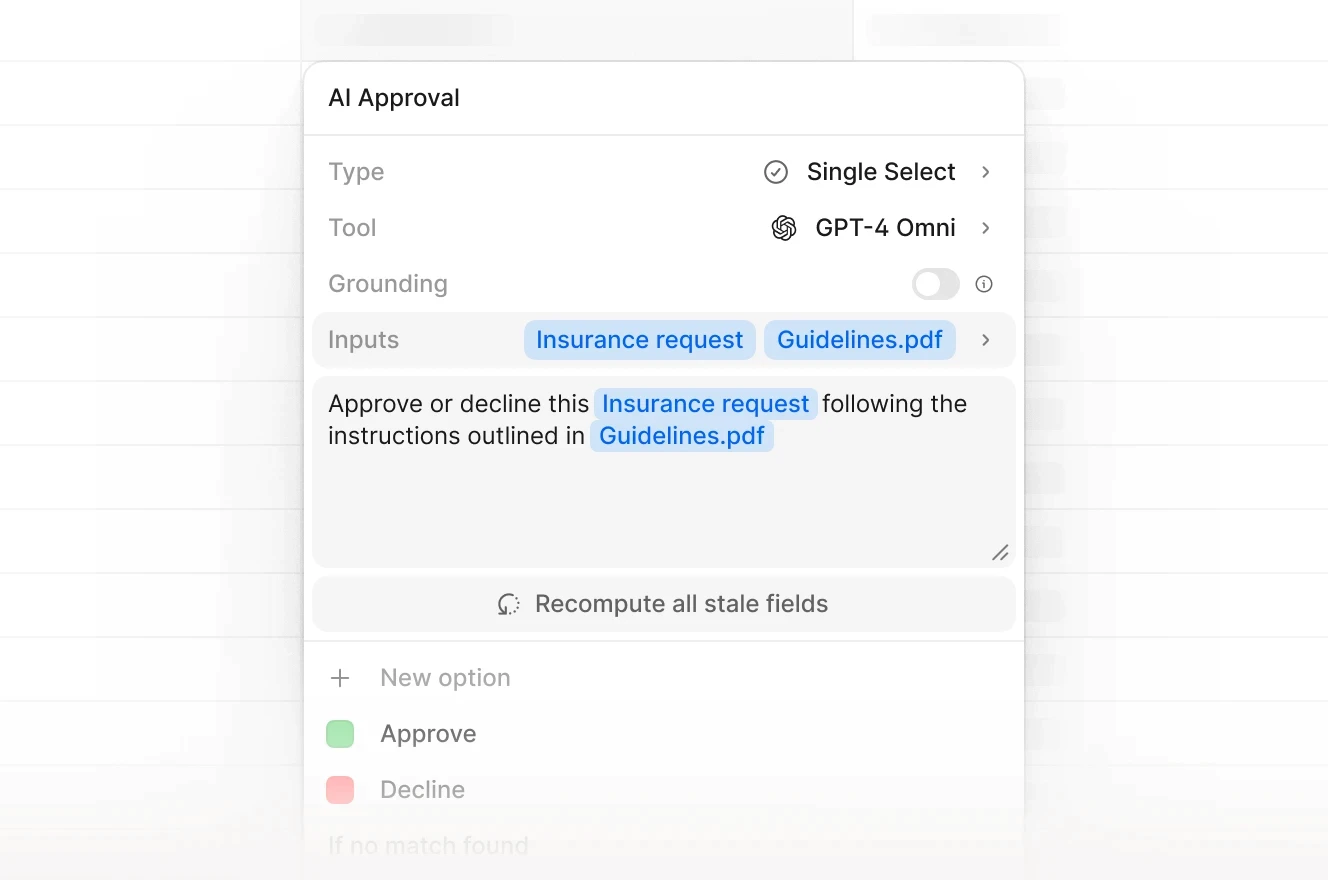
For FNOL workflows, V7 Go deploys a coordinator model that receives the incoming document packet and routes each file to specialist sub-agents: one for classification (what type of document is this?), one for extraction (what are the field values?), one for validation (does this data match the policy record?), and one for anomaly scoring (are there indicators that warrant SIU review?). Each sub-agent is optimized for its task, and the coordinator handles the sequencing logic that a human triager would otherwise perform.
Each extraction output includes a Visual Grounding citation: a precise reference to the exact location in the source document where each extracted value was found. If the system extracted a date of loss from page 2, line 14 of a police report, that citation is recorded alongside the extracted value in the CMS. Adjusters can review any field and navigate directly to the source passage without opening the full document.
This citation architecture addresses a specific regulatory requirement. The NAIC Model Bulletin on Artificial Intelligence, adopted December 2023 and now in force in 24 US states, requires that AI-assisted claims decisions be explainable and auditable. Visual Grounding creates the audit trail that regulators require, not as a post-hoc report, but as a native output of every extraction run.
Fraud signal detection is particularly valuable at the point of first notice because this is the earliest stage at which the system captures anomaly indicators before the file advances in the pipeline. The reported date of loss, the claimant's prior claims history, the geographic match between the incident location and the policy address, and the time elapsed between the incident and the report all carry signal value that is easiest to assess before adjusters have taken action on the file. V7 Go scores each new FNOL record against configurable anomaly rules and flags discrepancies for SIU review without blocking the main intake workflow.
The V7 Go insurance document ingestion automation handles the full intake packet: policy documents, loss notices, third-party correspondence, and all supporting attachments. The claims triage agent then scores each claim against coverage rules and fraud indicators, routing straightforward claims to fast-track and flagging anomalies for adjuster review.
The insurance underwriting agent extends the same extraction approach to renewal and mid-term adjustment workflows, where changes in exposure reported at FNOL can trigger underwriting review. A new vehicle added during an auto claim, or an address change noted in a property loss report, can both affect the renewal risk profile.
V7 Go stores all document packets and extraction outputs in Knowledge Hubs: structured repositories that make every processed document searchable and retrievable across the claims file. Adjusters handling a complex multi-claimant loss can query across all documents in the file without opening attachments individually. The same repository supports subrogation analysis, making it straightforward to identify third-party liability indicators across the documented evidence without manual document review.
The platform does not train on customer data and does not modify source documents. Every extraction is traceable to the document passage that produced it. For insurers navigating growing regulatory scrutiny of AI in claims, that combination of extraction accuracy, citation depth, and data isolation is what separates a compliant deployment from a liability.
FNOL Automation: Accuracy First, Speed Second
The appeal of FNOL automation is obvious: faster intake, lower cost, higher adjuster capacity. But the insurers who have deployed it successfully report that the operational case rests primarily on accuracy, not speed.
A claim that arrives with accurate, complete structured data moves faster through every downstream stage: coverage verification, reserve setting, adjuster assignment, and settlement. A claim that arrives with errors requires rework at each stage. The cumulative cost of that rework, in adjuster hours, delay, and claimant dissatisfaction, far exceeds the cost of getting the extraction right at FNOL.
The most practical evaluation criterion for any FNOL automation system is what happens when it encounters a document it has not seen before. Rules-based systems fail on unknown formats and escalate to manual review, which removes the efficiency gain for any non-standard intake. AI extraction models adapt to new document layouts without requiring template updates, extracting the same target fields from the same schema regardless of source format. For insurers handling commercial lines, specialty risks, or high-volume weather events where documentation formats vary by jurisdiction and by vendor, this adaptability is not a secondary consideration. It is the core functional requirement.
AI document extraction at the point of first notice changes the intake economics in a specific way: adjusters start their review with a complete, structured record instead of spending the first hours correcting errors before substantive work can begin.
Every claim starts at FNOL. What the system captures in that first moment determines reserve quality, investigation speed, and adjuster workload across the life of the file. For insurers evaluating extraction systems, the standard is straightforward: accurate data on every document, a citation trail that satisfies regulatory review, and the ability to handle a format it has never seen before.
What does FNOL stand for in insurance?
<p>FNOL stands for First Notice of Loss. It is the formal initial report that a policyholder or claimant submits to their insurance company when a covered event occurs, such as a vehicle collision, property damage, theft, or bodily injury. The FNOL is not a complete claims investigation; it is the trigger that opens the claims file and initiates coverage verification, reserve setting, and adjuster assignment.</p><p>Different insurers and lines of business use slightly different terminology. Some call it First Report of Loss (FROL) or Initial Loss Report, but all refer to the same intake event. Filing FNOL promptly is typically required by policy conditions, and failure to do so within the specified window can affect claim validity.</p>
+
What information is collected during FNOL?
<p>The standard FNOL data set includes policy number and policyholder identity, the date, time, and location of the loss, a description of the incident and the type of claim (auto, property, liability, workers' compensation), the identity and contact details of any third parties involved, an initial description of damages or injuries, and the availability of supporting documentation.</p><p>In practice, the information collected at FNOL is rarely complete. Claimants may not have all details immediately; police reports may not yet be filed; repair estimates may take days to obtain. Modern claims management systems are designed to accept partial FNOL data and allow supplemental submission as documents become available, with the full picture assembled during the investigation phase. Regulatory frameworks in most jurisdictions permit supplemental FNOL submissions, provided the initial report is filed within the required window.</p>
+
How long does the FNOL process take?
<p>The time to complete FNOL intake varies by line of business and intake channel. A straightforward auto FNOL submitted through a web portal with all required fields completed can be processed in under an hour. A complex commercial property claim involving multiple parties, regulatory reporting requirements, and extensive documentation may take several days before a complete FNOL record is established in the claims management system.</p><p>Most regulatory frameworks require insurers to acknowledge FNOL within 10 to 15 business days of receipt and to make a coverage decision within 30 to 45 days, though many carriers aim for faster timelines to meet claimant expectations and improve satisfaction scores. AI-assisted intake automation can compress the data-ready timeline significantly, even when the regulatory acknowledgement clock remains the same. The practical gain is that adjusters receive a complete, structured record at the start of their review rather than spending the first part of their shift correcting intake errors before substantive work can begin.</p>
+
What is the difference between FNOL and a full claims investigation?
<p>FNOL is the intake event: the moment the insurer learns a loss has occurred and opens a claims file. A full claims investigation is the subsequent process in which an adjuster gathers evidence, assesses damages, determines coverage applicability, and calculates the settlement amount.</p><p>FNOL typically captures a snapshot of the loss as the claimant understands it at the moment of reporting. The investigation fills in the gaps: independent damage assessment, witness interviews, review of third-party reports, fraud screening, and coverage analysis. In straightforward claims, the gap between FNOL and resolution may be days. In complex or disputed claims, investigation can extend over months. Poor data quality at FNOL extends investigation timelines because adjusters spend time correcting intake errors before they can begin substantive review. AI-assisted FNOL intake reduces this rework burden, which is why extraction accuracy at the point of first notice has a direct effect on overall claims cycle time.</p>
+
Can FNOL be submitted online?
<p>AI improves FNOL accuracy in two primary ways: by extracting structured fields from unstructured documents more reliably than manual data entry, and by flagging data inconsistencies that human reviewers miss under volume pressure.</p><p>AI document extraction models process any document format, from police reports to repair estimates to medical bills, and extract the same set of fields regardless of layout variation. Each extracted value includes a citation back to the exact document location it came from, giving adjusters a way to verify any field without reading the full document. Anomaly detection runs in parallel: if the reported date of loss falls outside the policy period, or if the vehicle description does not match the policy record, the system flags the discrepancy for human review before the file advances in the pipeline.</p>
+
How does AI improve FNOL accuracy?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

