18 min read
—


From FNOL automation to fraud detection, discover how AI agents are solving the operational bottlenecks that legacy systems cannot touch. Real deployment data and practitioner insights.

Every Gen AI demo I see handles a simple invoice or something equally basic. But what about ingesting multi-layered, complex slips, or those 50-page risk engineering reports?
That question, posed by an underwriting director at a major carrier, captures the core challenge facing insurance operations in 2025. While 88% of auto insurers and 70% of home insurers report using or planning to use AI, only 7% have successfully scaled AI systems into production. The gap between pilot projects and enterprise deployment is not a technology problem. It is a workflow problem.
The bottleneck is not whether AI can read a document. It is whether AI can handle the specific artifacts that insurance teams process every Monday morning: scanned handwritten FNOL forms, 50-page risk engineering reports with embedded tables and diagrams, multi-layered slips with inconsistent formatting, and loss run reports that span multiple policy periods.
In this article:
Claims Automation: How AI agents reduce FNOL processing time from days to hours while maintaining audit trails
Underwriting Intelligence: Extracting COPE data, analyzing risk engineering reports, and automating submission triage
Fraud Detection: Real-world deployment data showing 29% improvement in detection rates
Policy Administration: Automating renewals, endorsements, and compliance checks across legacy systems
Implementation Reality: What actually works in production versus what fails in pilots

AI for document processing
Deploy AI agents across claims and underwriting workflows
Get started today
Why Insurance AI Projects Fail
Before examining specific use cases, you need to understand why most insurance AI implementations stall between pilot and production. The failure pattern is consistent across carriers: a vendor demonstrates impressive accuracy on a clean dataset, the pilot shows promise, and then the project dies during integration with actual workflows.
The issue is not the AI model. It is the gap between what the model was trained on and what your operations team actually processes.
The Document Reality Gap
Insurance documents are not clean PDFs with consistent formatting. A typical claims intake workflow processes handwritten FNOL forms with varying legibility, accident scene photographs taken on mobile phones, scanned police reports with stamps and annotations, medical records faxed from provider offices, and repair estimates in proprietary formats.
Legacy OCR systems handle structured forms reasonably well. They fail on the edge cases that represent 30-40% of actual claim volume. If you have a BPO team that re-keys anything the OCR system flags as low confidence, that could still mean thousands of documents per week.
V7 Go agent dashboard showing automated document processing across multiple file types, from invoices to complex insurance submissions.
The Integration Bottleneck
Even when AI successfully extracts data, the next challenge is getting that data into your core systems. Most carriers run on platforms like Guidewire, Duck Creek, or legacy mainframe systems that were not always designed for API-first integration.
"Our claims system requires 47 separate fields for a property claim. The AI vendor gives us a JSON object with 12 fields. Someone still has to map the rest manually, which defeats the entire purpose." - A claims director at a national carrier
This is where intelligent document processing differs from basic OCR. The goal is not just extraction. It is transformation into the exact format your downstream systems require.
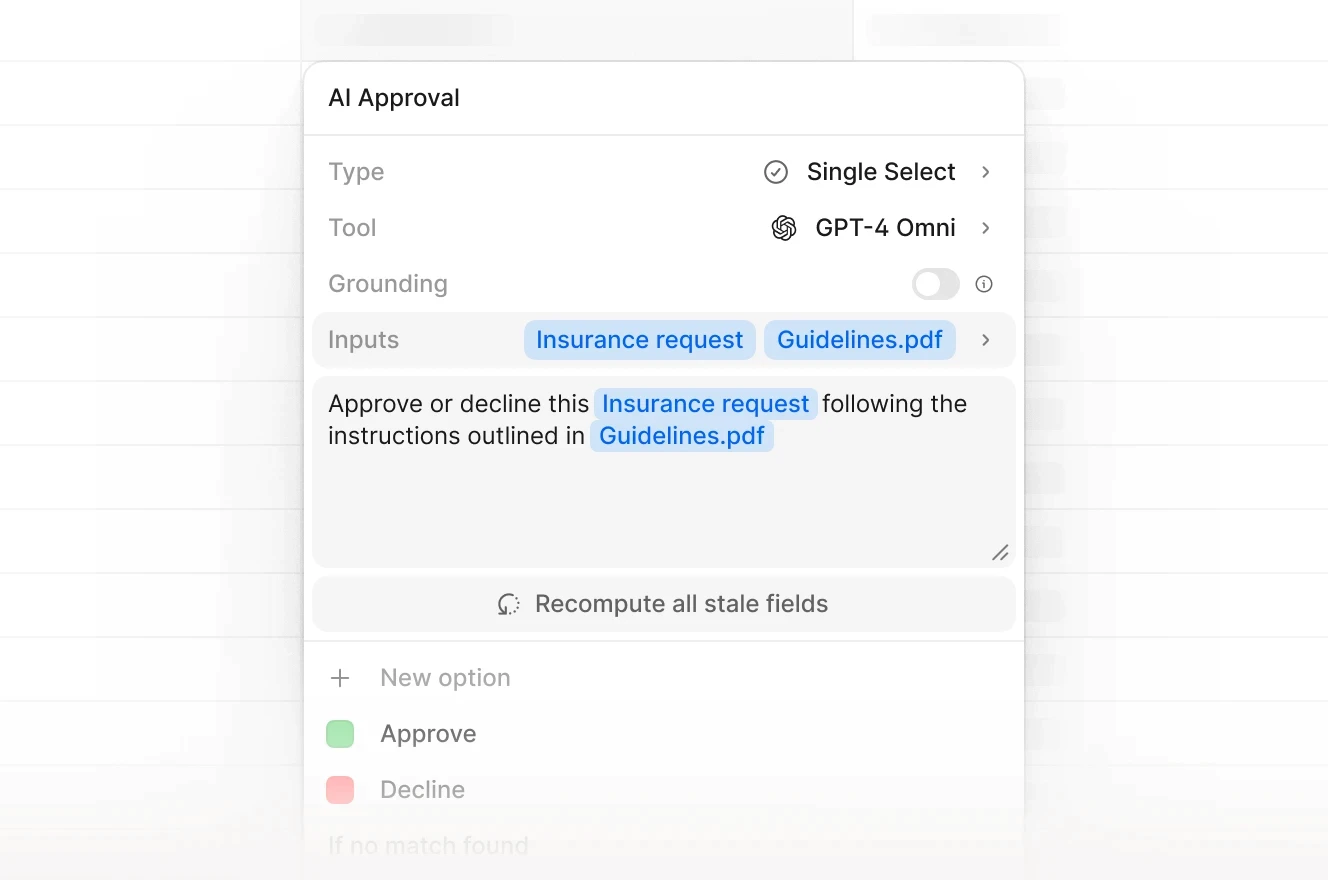
AI approval interface in V7 Go processing insurance requests with structured field extraction and decision logic.
Use Case 1: First Notice of Loss (FNOL) Automation
FNOL processing is the highest-volume, most time-sensitive workflow in claims operations. A typical auto insurer processes 500-1,000 FNOLs per day. Each one requires extracting 30-50 data points from forms, photos, and supporting documents.
The Current Process
Most carriers still rely on a hybrid approach. The customer submits a claim via web portal, mobile app, or phone. Initial data entry happens through the call center or policyholder self-service. Documents get uploaded, including photos, police reports, and estimates. Then a claims examiner performs manual review and data validation before the claim gets assigned to an adjuster based on complexity and geography.
The bottleneck is the review step. Even with structured web forms, claims examiners spend 15-20 minutes per FNOL validating data, cross-referencing policy details, and flagging inconsistencies. For complex commercial claims, this can extend to several hours.
The AI Solution
An Insurance Claims Automation Agent handles the entire intake workflow. Document ingestion accepts photos, PDFs, and scanned forms in any format. Data extraction pulls structured fields such as date of loss, location, parties involved, and damage description. Policy verification cross-references extracted data against policy records. Triage and routing assigns a severity score and routes to the appropriate adjuster queue.
The key difference from legacy OCR attempts was handling edge cases. The agent processed handwritten notes on accident diagrams, extracted data from photos of damaged vehicles, and reconciled conflicting information across multiple documents. Run these pilots inside Cases with auditable trails. Store your underwriting guidelines and policy manuals in a Knowledge Hub so agents can answer coverage questions with cited pages.
CIM due diligence workflow in V7 Go showing split-screen document analysis with extracted fields and entity relationships.
Use Case 2: Risk Engineering Report Analysis
Commercial property underwriters rely on risk engineering reports to assess large accounts. These reports run 50-100 pages and include COPE data (Construction, Occupancy, Protection, Exposure), fire protection system details, sprinkler coverage maps, hazard identification and mitigation recommendations, and Estimated Maximum Loss (EML) calculations.
"I get 3-5 of these reports per week. Each one takes me 2-3 hours to review and extract the data points I need for underwriting. The reports are never formatted the same way, so I cannot just search for keywords." - A senior underwriter at a specialty carrier
The Extraction Challenge
Risk engineering reports are unstructured narratives with embedded tables, diagrams, and photos. Critical data points are scattered throughout. Building construction details might be in paragraph 3 of the executive summary. Sprinkler coverage percentages might be in a table on page 23. EML figures might be in a footnote on page 47.
Legacy document processing tools fail because they rely on consistent formatting. An Insurance Risk Assessment Agent uses context-aware extraction. It reads the entire report to understand structure, identifies sections containing COPE data regardless of formatting, extracts numerical values with units and context, flags inconsistencies (such as sprinkler coverage stated as 80% in one section and 75% in another), and generates structured output with source citations.
When reviewers want to see the source of a figure, AI Citations shows the exact page and bounding box that produced it.
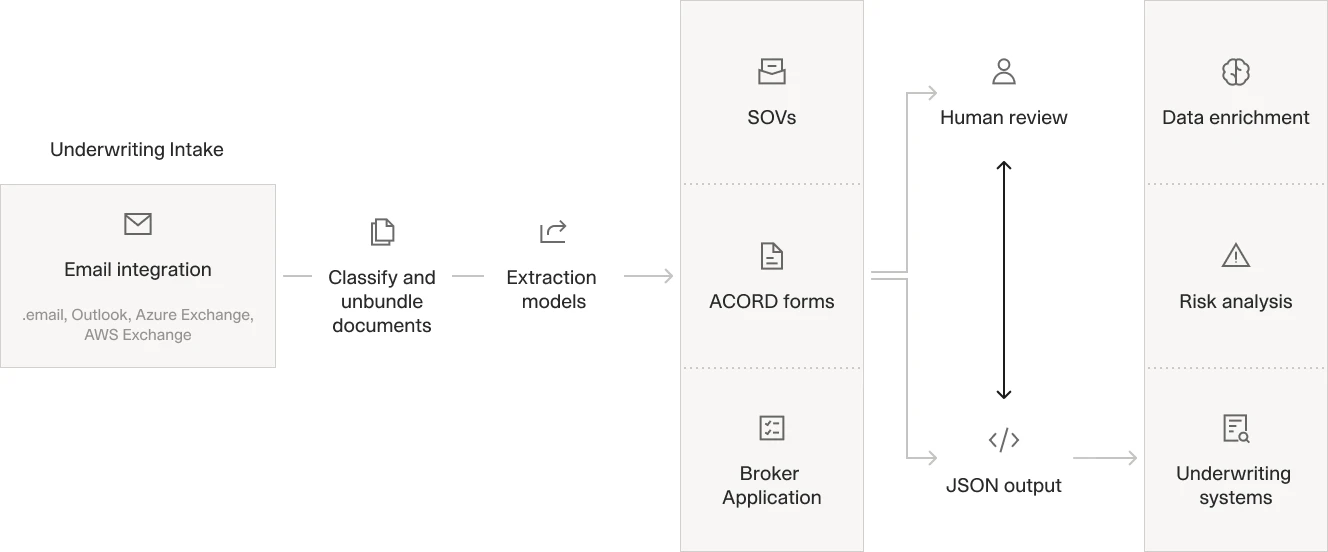
Automated underwriting workflow processing email submissions through classification, extraction, and structured data output.
Use Case 3: Submission Triage and Routing
Underwriting teams receive hundreds of submissions per week via email, broker portals, and direct uploads. Each submission requires initial review to determine line of business and coverage type, risk characteristics and complexity, appropriate underwriter assignment, and required additional information.
A mid-sized commercial carrier described their current process: "We have two people who do nothing but read incoming emails and route submissions to the right underwriter. They spend about 5 minutes per submission just figuring out what it is and who should handle it."
The Routing Logic Problem
Submission triage is not a simple keyword matching exercise. It requires understanding industry classification (SIC/NAICS codes), revenue and employee count (which determines market segment), geographic exposure (multi-state versus single location), coverage requirements (standard versus specialty), and underwriter expertise and current workload.
An Underwriting Submission Analysis agent automates this workflow. It ingests the submission package including application, loss runs, and financials. It extracts key classification data, applies routing rules based on risk characteristics, generates a preliminary risk assessment, and routes to the appropriate underwriter with a summary.
Use Case 4: Policy Renewal Processing
Renewals represent 70-80% of premium volume for most carriers, but the process is heavily manual. A typical commercial lines renewal requires reviewing prior year loss experience, updating exposure data (payroll, revenue, vehicle count), applying rate changes and coverage modifications, and generating renewal quote and documentation.
The Data Collection Problem
Renewal data comes from multiple sources: policyholder questionnaires (often incomplete), loss runs from prior carrier, updated financial statements, vehicle schedules or equipment lists, and certificates of insurance from vendors. Each document type has different formatting. A workers' compensation renewal might require extracting payroll by class code from an Excel file, while a commercial auto renewal needs vehicle VINs from a PDF schedule.
An Insurance Policy Review Agent handles the entire renewal data workflow. It ingests all renewal documents regardless of format, extracts exposure data and maps to policy structure, compares current year to prior year to identify changes, flags missing or inconsistent information, and generates a structured renewal summary for underwriter review.
Risk engineering agent analyzing property insurance submissions, extracting EML calculations and mitigation recommendations with source citations.
Use Case 5: Fraud Detection and Investigation
Insurance fraud costs the industry an estimated $80 billion annually in the United States alone. Traditional fraud detection relies on rules-based systems that flag obvious patterns such as duplicate claims, suspicious timing, and known fraud rings. These systems generate high false positive rates and miss sophisticated fraud schemes.
The Pattern Recognition Problem
Sophisticated fraud involves subtle patterns across multiple claims: staged accidents with consistent injury patterns, provider networks billing for unnecessary treatments, inflated repair estimates from specific body shops, and claimants with multiple claims across different carriers. These patterns are invisible when reviewing individual claims. They only emerge when analyzing hundreds or thousands of claims simultaneously.
AI fraud detection systems like Allianz's Incognito platform have demonstrated a 29% improvement in fraud detection rates by analyzing cross-claim patterns that human investigators cannot spot.
The agent workflow powered by V7 Go can ingests claim documentation (photos, estimates, police reports), analyze damage patterns and repair estimates, cross-reference against historical claims database, identifies anomalies (damage inconsistent with reported accident, estimates from flagged providers), and generate investigation priority score with supporting evidence. An AI Claims Triage Agent can further accelerate investigation prioritization by routing high-severity cases to senior investigators immediately.
The key improvement is not just flagging suspicious claims, but providing investigators with specific evidence and context. Instead of "this claim is suspicious," the system can generate insights like "this estimate is 40% higher than average for similar damage, and this body shop has been involved in 12 other flagged claims in the past 90 days."

AI invoice matching showing automated discrepancy detection between invoice and purchase order.
Use Case 6: Loss Run Analysis and Pricing
Loss runs are the foundation of commercial insurance pricing. They document a policyholder's claim history, including dates of loss, claim amounts, and current status (open, closed, reserved). Underwriters use this data to calculate loss ratios and determine appropriate pricing.
The problem is that loss runs come in dozens of different formats. Each carrier has its own template. Some are structured PDFs with clear tables. Others are scanned images of printed reports. Many include handwritten notes and annotations.
The Normalization Challenge
Loss run analysis requires normalizing data across different formats: date formats (MM/DD/YYYY versus DD-MMM-YY), claim status terminology (Closed versus Settled versus Paid), reserve amounts (some carriers show case reserves, others show total incurred), and claim descriptions (free text with varying detail levels).
An AI Loss Run Processing Agent handles this workflow. It ingests loss runs in any format (PDF, Excel, scanned image), identifies table structure and column headers, extracts claim-level data with normalization, calculates loss ratios and frequency metrics, flags high-severity claims and adverse trends, and outputs structured data for pricing models.
The agent also identifies patterns that manual review missed. For example, it can flag an account where claim frequency was declining but severity was increasing. This pattern can indicate potential safety program issues that warranted premium adjustment.











Use Case 7: Certificate of Insurance (COI) Verification
Certificates of Insurance are a persistent source of friction in commercial insurance operations. Every contractor, vendor, and service provider needs to provide COIs proving they carry required coverage. Risk managers and project managers spend hours verifying that certificates meet contract requirements.
The Compliance Verification Problem
COI verification requires checking multiple data points: coverage types match contract requirements, limits meet minimum thresholds, additional insured endorsements are included, effective dates cover project duration, and carrier is admitted and financially rated. Each of these checks requires cross-referencing the COI against contract language, which varies by project and client.
An Insurance Coverage Analysis Agent automates this workflow. It ingests the COI (typically an ACORD 25 form, but handles non-standard formats), extracts all coverage details, limits, and endorsements, compares against contract requirements, flags deficiencies with specific citations, and generates a compliance report with accept/reject recommendation.
The system can also maintain an audit trail showing exactly which contract requirements were checked and what evidence supported the accept/reject decision. This documentation proved critical for litigation defense when a subcontractor's lapse in coverage led to a claim.
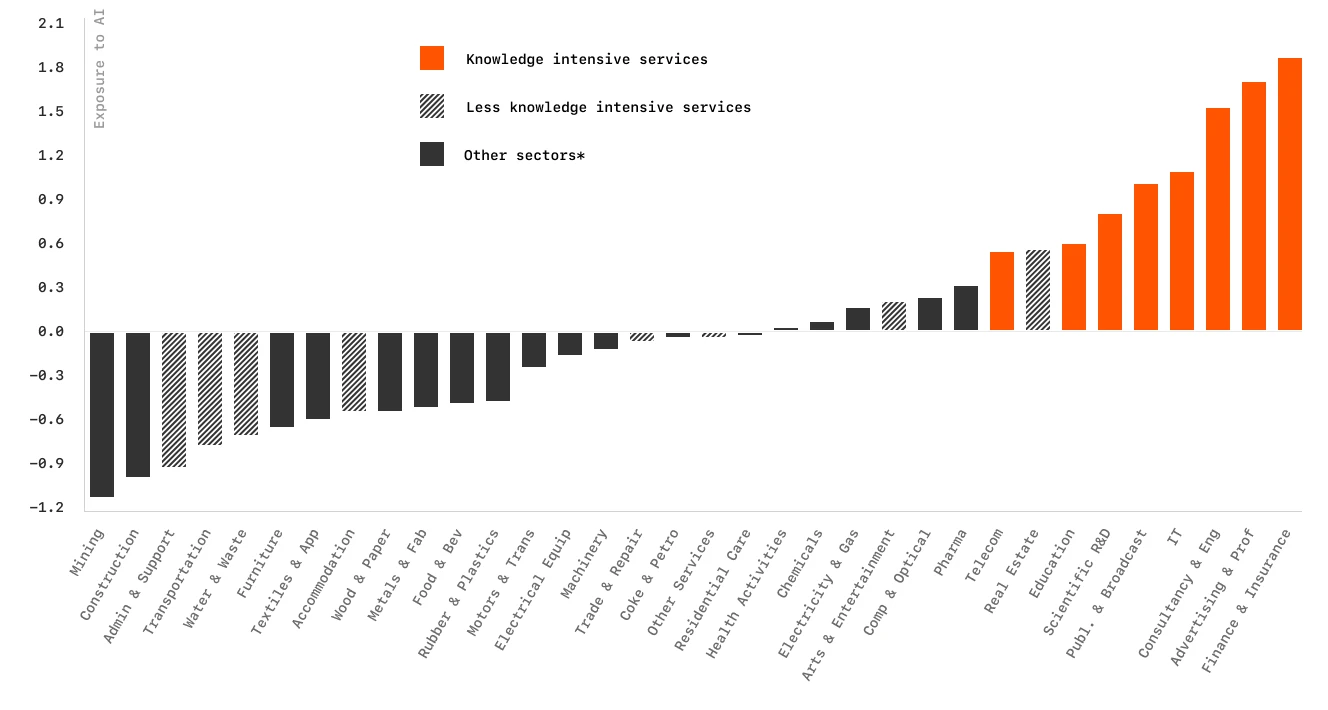
Industry analysis showing AI adoption rates across sectors, with Finance and Insurance leading implementation.
Use Case 8: Actuarial Data Extraction and Modeling
Actuarial analysis depends on extracting historical data from policy administration systems, claims databases, and financial reports. This data feeds into pricing models, reserve calculations, and regulatory filings. The challenge is that actuarial data often spans decades and multiple legacy systems.
The Data Consolidation Problem
Actuarial modeling requires consistent data across policy effective dates and coverage periods, premium by coverage and class code, claim counts and amounts by accident year, exposure bases (payroll, sales, vehicle count), and rate changes and coverage modifications. Each source system stores this data differently. Policy systems track coverage periods. Claims systems track accident dates. Financial systems track accounting periods. Reconciling these different time dimensions is manual and error-prone.
An AI Actuarial Analysis Agent handles data extraction and normalization. It connects to multiple source systems via API or file export, extracts relevant data with appropriate filters, normalizes dates, amounts, and classification codes, reconciles discrepancies across systems, and outputs structured datasets for actuarial models.
The agent also maintains data lineage, documenting exactly which source systems contributed each data point. This documentation can prove essential for regulatory audit defense when examiners questioned reserve methodology.
Use Case 9: Regulatory Compliance and Reporting
Insurance is one of the most heavily regulated industries. Carriers must file quarterly and annual reports with state regulators, maintain detailed documentation of underwriting decisions, and demonstrate compliance with rate filing requirements. The compliance burden grows with every new state license and product line.
The Reporting Complexity Problem
Regulatory reports require data from multiple sources: policy counts and premium by state and line of business, claim counts and loss ratios by coverage, underwriting guidelines and rate filings, financial statements and reserve calculations, and market conduct documentation. Each state regulator has different formatting requirements. Some accept electronic filing in specific XML schemas. Others require PDF submissions with specific page layouts. Many still require paper filings with original signatures.
An AI Regulatory Compliance Agent automates report compilation. It extracts required data from policy and claims systems, applies state-specific business rules and calculations, formats data according to regulatory specifications, generates draft reports with supporting documentation, and flags potential compliance issues for review.
Reports can be assembled in Cases with traceable documents. Index Knowledge supports cited policy and filing references, so when regulators ask for documentation, every figure has a source.
Use Case 10: Reinsurance Treaty Administration
Reinsurance treaties are complex contracts that define how risk is shared between ceding companies and reinsurers. Treaty administration requires tracking cessions, calculating premiums, and reporting claim activity. All of this depends on detailed policy and claim data matched against specific treaty terms.
The Treaty Matching Problem
Treaty administration requires matching policies and claims to treaty terms: identifying which policies are subject to each treaty, calculating ceded premium based on treaty formulas, determining which claims exceed attachment points, applying coverage limits and exclusions, and generating bordereaux in reinsurer-specific formats. Each treaty has unique terms. Some are quota share (fixed percentage of all business). Others are excess of loss (only claims above a threshold). Many have complex exclusions and territorial limitations.
An AI agent for Reinsurance Agreement Analysis automates treaty administration. It ingests treaty contracts and extracts key terms, matches policies to applicable treaties based on coverage, territory, and effective dates, calculates ceded premium and claim amounts, generates bordereaux reports in required formats, and flags potential treaty disputes or coverage questions.
Use Case 11: Customer Service and Policy Inquiries
Policyholders call with questions about coverage, billing, and claims status. Contact center agents need to access information from multiple systems to answer these questions. A typical inquiry requires checking policy details and coverage limits, billing history and payment status, claim status and payment information, and prior correspondence and notes.
The Information Retrieval Problem
Customer service requires synthesizing information from disparate sources: the policy administration system for coverage details, billing system for payment history, claims system for claim status, document management system for policy documents and correspondence, and CRM system for interaction history. Each system has its own interface and search logic. Agents must know which system contains which information and how to query each one.
V7 Go provides the document intelligence and retrieval via API. It is not a chatbot builder. It supplies the document retrieval and citations that customer service interfaces consume. Your contact center platform calls Go to retrieve policy pages, past correspondence, and claim notes with page-level citations so agents can answer faster. AI chatbots have reduced customer response times by up to 80% compared to human agents for routine inquiries when backed by this kind of document intelligence layer.
The system can also identify common inquiry patterns that indicate process problems. For example, a spike in billing inquiries can revealed that policy renewal notices are unclear about payment due dates. Define acceptance metrics: average handle time reduction target, deflection rate for routine billing questions, percentage of answers with citations, and escalation rules for complex coverage disputes.
V7 Go agent library showing pre-built templates for insurance, legal, tax, and financial document processing workflows.
Use Case 12: Predictive Analytics for Underwriting
Traditional underwriting relies on historical loss data and actuarial tables to price risk. Predictive analytics uses machine learning to identify patterns that human underwriters cannot see. These are correlations between seemingly unrelated risk factors that predict future losses.
The Pattern Recognition Opportunity
Predictive models analyze thousands of data points to identify loss predictors: business characteristics (industry, revenue, employee count), financial metrics (profitability, debt ratios, growth rate), operational factors (safety programs, training, equipment age), external data (weather patterns, economic indicators, regulatory changes), and historical loss patterns (frequency, severity, claim types). The challenge is that this data exists in dozens of different formats and systems. Building a predictive model requires assembling a clean, consistent dataset. This is where most projects fail.
V7 Go's document processing capabilities enable predictive analytics by automating data extraction from unstructured sources: safety program documentation, equipment maintenance records, training certifications, financial statements, and inspection reports.
Feature Engineering from Documents
From inspection reports, extract mean time between failure for key equipment, number of near-miss incidents, and training completion rates. From financial statements, normalize leverage and payroll volatility. From safety logs, pull recorded OSHA incident rates. From equipment schedules, capture lift truck age and maintenance intervals. Combine these with historical loss types to predict severity bands.
Accept a model only if it passes a 3-fold temporal validation and the top 10 features remain stable across refits. Watch for bias: if certain industry codes or geographies dominate the high-risk predictions, validate that the signal is real before deploying.

AI extracting structured financial data from unstructured documents with traceable source citations.
Implementation Reality: What Actually Works
The use cases above demonstrate proven value. But implementation success depends on understanding what separates successful deployments from failed pilots. The patterns are consistent across carriers of all sizes.
Start with High-Volume, Low-Complexity Workflows
The most successful AI implementations start with workflows that process hundreds or thousands of similar documents. FNOL intake, COI verification, and loss run analysis are ideal starting points because high volume justifies the implementation effort, document formats are relatively consistent within each workflow, success metrics are clear (processing time, accuracy, cost per transaction), and errors are low-risk (human review catches mistakes before they impact customers).

Avoid starting with complex, high-stakes workflows like large commercial underwriting or catastrophe claims. These require more sophisticated logic and have lower error tolerance.
Integrate with Existing Systems, Do Not Replace Them
The fastest path to production is augmenting existing workflows, not replacing them. An AI agent that extracts data and populates fields in your current policy system delivers value immediately. A project to replace your entire policy administration system will take years and may never complete.
V7 Go's API-first architecture enables integration with legacy systems like Guidewire, Duck Creek, and mainframe platforms. The agent handles document processing and data extraction. Your existing systems handle policy administration, billing, and claims management.
Maintain Human Review for High-Stakes Decisions
AI should automate data gathering and initial analysis, not final decisions. A claims examiner should review the agent's fraud assessment before denying a claim. An underwriter should review the agent's risk analysis before declining a submission.
The goal is not to eliminate human judgment. It is to give humans better information faster so they can focus on the decisions that require expertise and discretion.
Define Acceptance Criteria and Guardrails
Before deploying any agent, define sampling rates for human review (100% initially, then drop to 10-20% as confidence builds), confidence thresholds that trigger escalation (if extraction confidence falls below 85%, route to human review), fallback procedures when the agent cannot complete a task, and integration tests that validate data flows correctly to downstream systems.
Measure What Matters
Do not measure AI success by accuracy alone. Measure business outcomes: processing time (days from submission to quote), cost per transaction (fully loaded, including human review), error rates (mistakes that reach customers or regulators), employee satisfaction (are people doing more valuable work?), and customer experience (faster quotes, fewer follow-up questions).
The Path Forward: From Pilot to Production
The gap between pilot success and production deployment is not a technology problem. It is a change management problem. The carriers that successfully scale AI share three characteristics.
1. Executive Sponsorship with Operational Ownership
Successful implementations have C-level sponsorship but operational ownership. The CIO or Chief Claims Officer champions the project and secures budget. But the claims director or underwriting manager owns the day-to-day implementation and measures results.
Failed projects have executive sponsorship without operational buy-in. The innovation team runs a pilot, demonstrates impressive results, and then the project dies because the people who actually do the work were not involved in designing the solution.
2. Iterative Deployment with Continuous Improvement
Successful implementations start small, measure results, and expand gradually. They deploy to one line of business, one region, or one workflow before scaling enterprise-wide.
Failed projects try to automate everything at once. They attempt every workflow simultaneously, which creates complexity, delays deployment, and makes it impossible to isolate what is working and what is not.
3. Clear Success Metrics Tied to Business Outcomes
Successful implementations define success in business terms: reduce claims processing time by 50%, improve loss ratio by 5 points, increase underwriter capacity by 30%.
Failed projects define success in technical terms: achieve 95% accuracy, process 10,000 documents per day, integrate with five systems. These metrics do not connect to business value, which makes it impossible to justify continued investment when the project hits obstacles.
What Changes Monday Morning
If you implement one AI workflow this quarter, focus on the bottleneck that costs you the most time or money. For most carriers, that is either FNOL processing or underwriting submission triage.
Start with a pilot on 100 documents. Measure processing time, accuracy, and cost. If the results justify scaling, expand to 1,000 documents. If they do not, adjust the workflow or try a different use case.
The carriers that win in the next five years will not be the ones with the most sophisticated AI models. They will be the ones that successfully integrate AI into their operational workflows and use the time savings to focus on the decisions that actually require human judgment.
To see how V7 Go can automate your highest-volume document workflows, from claims intake to underwriting submissions, book a demo.

What is the difference between AI for insurance and traditional automation?
Traditional automation (like RPA) follows fixed rules and breaks when document formats change. AI adapts to variations in formatting, handles unstructured data like handwritten notes or photos, and can make contextual decisions based on document content. For example, a traditional OCR system can extract text from a structured form, but an AI agent can read a 50-page risk engineering report and extract COPE data regardless of where it appears in the document.
+
How long does it take to implement AI document processing for insurance?
Implementation time depends on scope and integration complexity. A focused pilot on a single workflow (like FNOL intake or COI verification) can be live in 2-4 weeks. Enterprise-wide deployment across multiple lines of business typically takes 3-6 months. The key variable is integration with existing systems. Carriers with modern API-enabled platforms deploy faster than those with legacy mainframe systems.
+
What accuracy rate should I expect from AI document extraction?
Accuracy varies by document type and use case. For structured forms like ACORD applications, expect 95-98% field-level accuracy. For unstructured documents like risk engineering reports, expect 90-94% accuracy on key data points. The critical metric is not raw accuracy but error impact. A system with 92% accuracy that flags low-confidence extractions for human review is more valuable than a system with 96% accuracy that provides no confidence scores.
+
Can AI handle handwritten claim forms and scanned documents?
Yes, but with caveats. Modern AI can process handwritten text with 85-90% accuracy when handwriting is reasonably legible. Scanned documents work well if scan quality is good (300 DPI or higher, minimal skew). The challenge is not whether AI can read the document, but whether it can extract the right data points and handle edge cases like crossed-out text, annotations, and stamps. V7 Go's visual grounding capabilities help by showing exactly which part of the document each extracted value came from.
+
How do I measure ROI on insurance AI projects?
AI should not make high-stakes decisions autonomously. The correct architecture is AI for data extraction and initial analysis, human review for final decisions. For example, an AI agent can analyze a claim and flag it as potentially fraudulent with 85% confidence, but a human investigator makes the final decision to deny the claim. This hybrid approach combines AI speed with human judgment and maintains accountability. V7 Go's citation features help by showing exactly which document sections support each extracted value, making human review faster and more reliable.
+
What happens when the AI makes a mistake on a high-stakes decision?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

