15 min read
—



Every underwriter at a carrier or managing general agent (MGA) knows this routine: a submission arrives as a PDF email attachment — a Market Reform Contract (MRC) slip, a loss run, an ACORD form, sometimes all three — and someone opens it and starts typing. Named insured. Policy period. Total insured value. Limits. Deductibles. Into the system, field by field. McKinsey estimates that underwriters spend only 30% of their time on actual underwriting decisions; the remaining 70% goes to administrative work, and re-keying submission data sits near the top of that list. Insurance document automation is the discipline that addresses this problem directly.
Across the industry, 97% of insurance data arrives as unstructured text (Accenture). That figure does not reflect a technology gap — it reflects the nature of the documents themselves. MRC slips vary by broker despite the MRC standard. ACORD forms arrive completed by hand. Loss runs have no standard column format. Each document type presents different extraction challenges, and the volume only grows as carriers expand into new lines or markets.
This article covers what insurance document automation is, how the underlying technology works, which document types it applies to, and how AI is changing what is possible for carriers, Lloyd's of London syndicates, MGAs, and coverholders processing dozens of submissions per week. For those focused specifically on the claims side, see our guide to automated claims processing for insurance.
In this article:
What insurance document automation is and how it differs from document generation and legacy document scanning
The re-keying problem and why insurance documents resist automation in ways that other industries do not
The specific document types involved: MRC slips, ACORD forms, bordereaux, loss runs, and e-submissions
How OCR, intelligent document processing, and LLM-based extraction work — and where each one falls short
Straight-through processing for insurance submissions and what actually determines STP rates in practice

AI for document processing
Extract structured data from every slip and submission
Get started today
What is insurance document automation?
Insurance document automation is the automated extraction, classification, and routing of structured data from insurance documents — submissions, slips, forms, and policy records — without manual re-keying. The output is structured data that can populate a policy administration system, a pricing tool, or a compliance database directly.
That definition matters because it distinguishes insurance document automation from two things it is frequently confused with. The first is digital document storage: scanning a PDF and saving it to a document management system is not document automation. The second is document generation — tools that produce outbound policy documents from templates. This article is about the inbound problem: documents arriving from brokers, coverholders, and claimants that need to be read, understood, and acted on.
Three technologies do most of the work in a modern extraction pipeline:
OCR (optical character recognition): converts scanned or image-based documents into machine-readable text.
Intelligent document processing (IDP): layers classification, field extraction, and validation on top of OCR output.
LLM-based extraction: uses large language models to understand context, handle ambiguity, and extract fields from formats the system has never encountered before.

Insurance documents vs. insurance slips: what is the difference?
"Insurance documents" is the broad category — anything generated during the insurance lifecycle, from a first notice of loss to a policy schedule to a coverholder's monthly bordereaux. An "insurance slip" is more specific.
A slip is the structured risk placement document used in the London Market and commercial lines. In the London Market, the standard format is the Market Reform Contract (MRC) slip: a document, typically 4 to 12 pages, that captures the risk description, named insured, policy period, limits, deductibles, perils, exclusions, reinsurance terms, and the subscription lines showing each syndicate's participation. The MRC format was introduced to bring consistency to Lloyd's of London placements, but in practice every broker uses their own template, and the variation between them is substantial.
E-submissions are the digital delivery mechanism: a broker sends a package by email or a submission platform containing the slip, a risk questionnaire, loss runs from the prior insurer, and any supplemental attachments. By the time that package lands in an underwriter's inbox, it may contain five separate documents in three different formats, and all of it needs to be read before a quote can be produced.
In the US market, ACORD forms play an equivalent role. ACORD 125 (Commercial General Liability), ACORD 75 (Excess Liability), ACORD 80 (Homeowners), ACORD 101 (Additional Remarks), and ACORD 23 (Personal Watercraft) each define a field schema. But they arrive completed by hand, often with supplemental attachments that modify or override the printed fields. The standardisation is less useful than it appears when the forms themselves are manually completed.
The re-keying problem in insurance
The numbers on manual data entry in insurance are not ambiguous. McKinsey puts underwriter administrative time at roughly 70% of the working week. Deloitte estimates that each manual data touch in insurance costs $40 to $60, dropping below $20 with automation. Accenture and AutomationEdge have consistently found that 97% of insurance data arrives as unstructured text, which means that for every structured output your system needs, a human is first converting something that arrived as prose or a scanned table.
Scale that up. A mid-size MGA processing 200 submissions per week, with an average of 45 minutes of re-keying per submission, is consuming 150 staff-hours per week on pure data entry before a single underwriting judgment has been made. That figure does not include the transcription error rate, which in practice runs between 1% and 4% per field. Even at 1%, across hundreds of fields per submission, the cumulative error count is significant, and those errors propagate downstream into pricing models, compliance records, and reinsurance statements.
The business impact extends beyond operational overhead. Slow quote turnaround loses business. In competitive specialty lines, a broker who receives a quote in four hours rather than four days will often bind with the faster market, all else being equal. Carriers that have deployed submission automation report 25% faster quote turnaround times on average. The capacity freed by removing re-keying overhead returns to underwriting judgment. For context on how leading platforms are approaching the broader workflow, see our guide to AI for insurance underwriting.
Why insurance documents are uniquely difficult to process automatically
Insurance documents resist automation in ways that general-purpose document processing tools do not anticipate.
The first problem is format variation. No two MRC slips look alike. Brokers use their own templates, and while the MRC standard defines required fields, the physical layout (where those fields appear on the page, whether they appear in a table or free text, whether they are labelled at all) differs between brokers and sometimes between placements from the same broker. A legacy OCR system trained on one broker's template fails silently on another's, often without any error signal.
The second problem is embedded complexity. Sub-limits, endorsements, and co-insurance terms often appear as free-text paragraphs, not in clearly labelled fields. A reinsurance attachment point might read: "excess of $500,000 ultimate net loss per occurrence, with an annual aggregate limit of $5,000,000." That sentence needs to be extracted as two structured values, not stored as a prose string.
The third problem is terminology density. Insurance documents are written in professional shorthand that requires domain knowledge to parse correctly. TIV (total insured value), ROL (rate on line), NCP (net combined premium), excess-of-loss attachment points: a general-purpose extraction model will misidentify or miss these entirely. Some Lloyd's of London documents still include handwritten annotations, which modern OCR handles poorly at production scale.
Legacy OCR fails when field labels and values are misaligned, when tables span multiple pages, or when the document uses a multi-column layout that the parser reads as a single continuous text block. The result is extracted text that looks correct but is not. That is the worst kind of error, because it passes initial validation.
Types of insurance documents that require automated processing
Insurers and MGAs encounter a range of document types across the policy lifecycle. Each presents different extraction challenges, and a mature automation program needs to handle all of them.
MRC slips (Market Reform Contract): The primary submission document in the London Market for commercial lines. Contains risk description, named insured, policy period, limits, deductibles, perils, exclusions, reinsurance terms, and subscription lines showing each Lloyd's syndicate's participation. The challenge: substantial format variation between brokers despite the MRC standard.
ACORD forms: ACORD 125, 75, 80, 101, 23, and others define field schemas for US commercial and personal lines risks. The challenge: manually completed fields, inconsistent handwriting quality, and supplemental attachments that modify or override the printed fields.
Loss runs: Historical claims records from a prior insurer. Multi-year tabular format showing claim date, amount paid, amount reserved, and claim status. The challenge: no standard format. Every insurer produces their own version, and the column order and terminology vary.
Bordereaux: Monthly or quarterly data files submitted from coverholders to Lloyd's syndicates, reporting bound risks and claims activity. Often in Excel, high volume. The challenge: column mapping varies between coverholders, and the files arrive on a regular schedule, creating batch-processing bottlenecks.
Policy schedules: The full policy document post-bind, used for renewals and endorsement processing. Underwriters compare the current schedule against a renewal submission to identify changes in coverage or exposure.
E-submissions: Broker email packages containing a slip, a risk questionnaire, loss runs, and supplemental attachments. The challenge: a single e-submission may contain five separate documents across three formats, requiring classification before extraction can begin.
First notice of loss (FNOL): Claims intake documents. The challenge: submitted under time pressure, often in non-standard formats, and the extracted data feeds directly into claims triage decisions. Errors at FNOL propagate through the entire claims lifecycle. See our guide to automated claims processing for more on this side of the workflow.

A typical submission intake workflow: documents are classified on arrival, fields are extracted and confidence-scored, and low-confidence results are routed for human review before data reaches the policy administration system.











How insurance document automation works
Modern insurance document automation operates in three layers: digitisation (converting document content to machine-readable text), comprehension (extracting and classifying specific fields from that text), and validation (confidence scoring and exception routing). Each layer has distinct capabilities and failure modes.
OCR and digitisation
Optical character recognition converts scanned PDFs, image files, and photographed documents into machine-readable text. Modern OCR achieves 95%+ accuracy on clean typeface at standard resolution, good enough that OCR error is rarely the primary problem in an extraction pipeline. The degradation cases are predictable: handwriting, low-contrast scans, watermarks overlapping text, and multi-column layouts that the parser reads as a single continuous block. For the Lloyd's market, where some older documents carry handwritten annotations, accuracy on those annotations runs significantly lower.
OCR produces raw text. That text is not structured data. You cannot query a policy administration system with raw OCR output. The structured extraction step happens after OCR, and that is where the real difficulty lies.
Intelligent document processing (IDP)
Intelligent document processing adds document classification, field extraction, and validation on top of OCR output. A standard IDP pipeline works as follows: the document is classified by type (MRC slip, ACORD form, loss run), a pre-trained model for that document type extracts the relevant fields, and each extracted value receives a confidence score. Fields below a confidence threshold are flagged for human review.
Traditional IDP is trained on labelled examples of specific document templates. This works reliably when the document type is known and the templates are consistent. It breaks when a broker submits a slip in a format the model has not seen, which in a market where each broker uses their own template happens constantly. The accuracy drop is steep: an IDP model trained on ten broker templates will often fail almost entirely on an eleventh.
Most carriers that built bespoke IDP systems between 2018 and 2022 are now replacing or augmenting them. The template-based approach required continuous maintenance as broker formats changed, and the engineering overhead of adding new document types was high. The question of build vs. buy has largely resolved in favour of configuring an existing platform rather than maintaining a bespoke one.
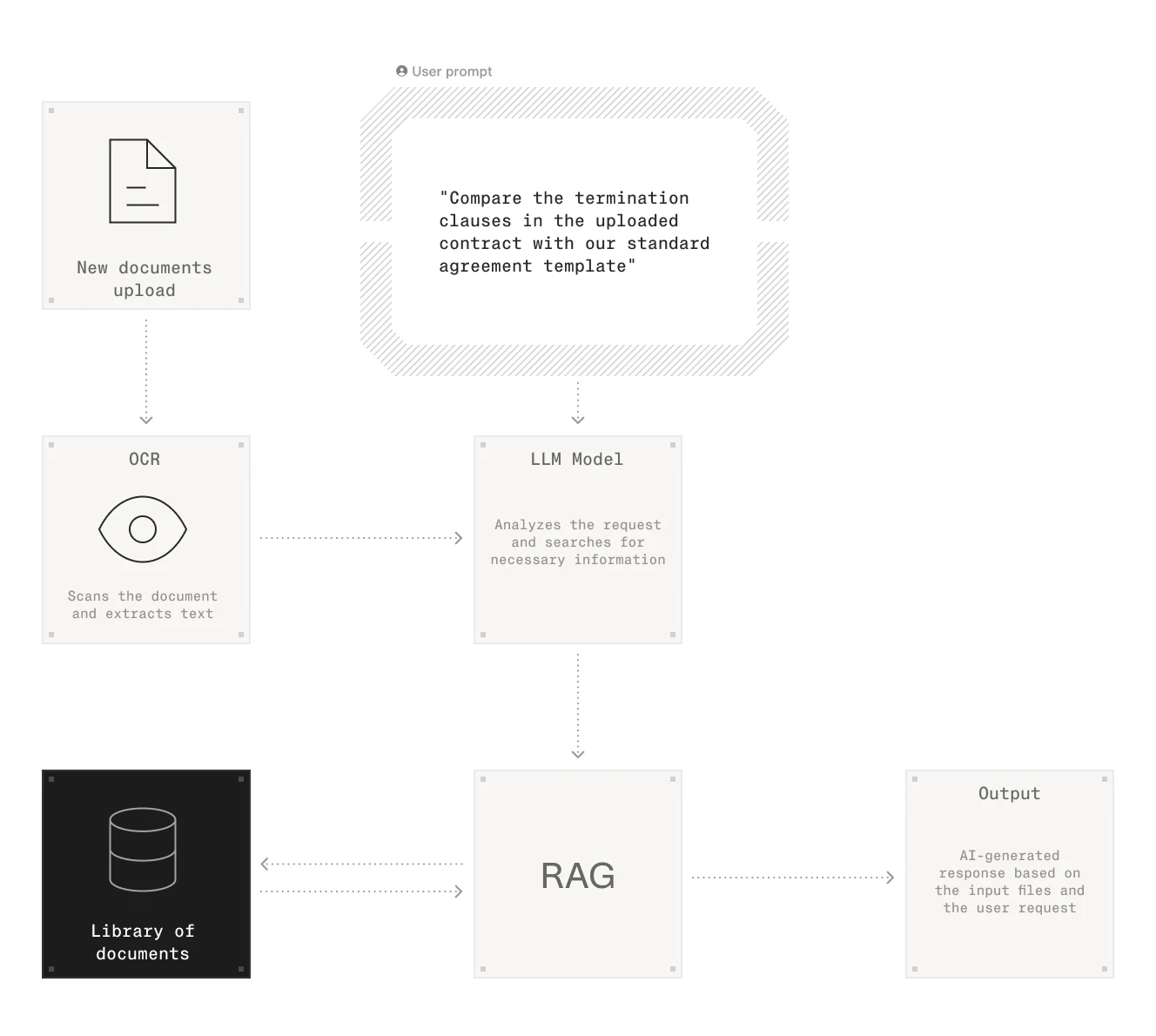
An IDP pipeline for insurance: OCR digitises the document, the LLM extracts and classifies fields, confidence scoring flags exceptions, and validated data routes to the downstream system.
LLM-based extraction — what is different
Large language models change the extraction equation in one specific way: they understand context rather than patterns.
A template-based system extracts TIV because it has been trained to look for the label "Total Insured Value" or "TIV:" in a specific region of the document. An LLM extracts TIV because it understands what TIV means in an insurance context, recognises that a number following the phrase "insured for" or "valued at" in an MRC slip is likely the TIV, and can reason about ambiguous cases rather than defaulting to null.
The practical consequence: LLM-based extraction generalises across new formats without retraining on each new broker template. A model that has processed MRC slips from 50 brokers handles a slip from the 51st broker almost as well as the first, not because it was trained on that format, but because it understands the domain.
Multi-modal models extend this to visual document structure: tables, form fields, and layout relationships can be processed in a single pass rather than requiring separate table-extraction and text-extraction pipelines.
The limitation is hallucination. LLMs will sometimes produce a plausible-sounding value that does not appear in the document. For insurance extraction, where an incorrect limit or deductible has real financial consequences, hallucination is not a tolerable failure mode. Enterprise-grade extraction pipelines layer additional validation on top of LLM output: cross-referencing extracted values against known ranges for that risk class, checking for internal consistency (does the sum of individual sub-limits equal the stated aggregate?), and routing anomalies to human review before the data enters any downstream system.
Straight-through processing (STP) for insurance submissions
Straight-through processing (STP) is the condition in which a submission moves from receipt to bound policy without any manual human intervention. The document is received, data is extracted, risk appetite is checked, pricing is confirmed within pre-agreed parameters, and the policy is issued automatically.
Industry average STP rates for commercial lines run between 15% and 30%. The leading carriers and MGAs with mature automation programs reach 60% to 70%. The gap between average and leader is largely an extraction problem: STP is only possible when extracted data is accurate and complete enough to drive an automated underwriting decision. If the TIV is wrong, or the policy period is missing, or the sub-limit for flood is extracted as the primary limit, the system either fails silently or flags the submission for manual review — and the STP opportunity is lost.
Document automation is the prerequisite for STP, not a downstream benefit of it. You cannot automate an underwriting decision if you cannot first accurately read the submission. This is why carriers investing in STP capability consistently find that the document extraction layer is the constraint, not the pricing model, not the risk appetite logic, not the policy administration system.
How AI is changing insurance document automation
From 2015 to 2022, most carriers and MGAs that invested in document automation built rule-based or template-based systems. Those systems worked in the narrow cases they were trained on. When a broker changed their slip format, or a new class of business arrived with unfamiliar document types, the system required a re-training cycle that could take weeks and substantial engineering resources. The automation held together until it did not.
What has changed since 2022 is the generalisation capability. LLM-based extraction does not require a new template for each new broker format. A well-configured extraction pipeline reads an MRC slip it has never seen before and produces accurate structured output, because it understands the domain, not just the layout. For an MGA processing submissions from 80 different brokers, this is the difference between automation that scales and automation that requires constant maintenance.
The second change is the agentic layer. Extraction is step one. Enterprise workflows require validation, enrichment, appetite matching, and routing, and each of those steps has historically been a separate system with its own integration overhead. The current generation of AI automation platforms connects extraction to the downstream workflow in a single configurable pipeline, without requiring custom engineering at each connection point.
V7 Go's insurance slip processing automation reads MRC slips, e-submissions, and ACORD forms, extracts structured risk fields, and validates extracted values before populating downstream systems. The AI insurance document ingestion automation supports the MRC slip format specifically, handling the format variation that breaks template-based systems.
For submission triage — which submissions to prioritise, in what order — AI can score and rank incoming submissions against a carrier's appetite before extraction even begins. An underwriter starts the day with a ranked queue rather than an unordered inbox. The AI insurance underwriting agent and the AI claims triage agent handle the downstream steps once extraction has produced clean structured output.
This is what insurance document automation looks like in practice: not a single model that does everything, but a configured pipeline where each step — extraction, validation, scoring, routing — is handled by an agent with the right capability for that task, with human review inserted wherever the confidence threshold or business rules require it.
V7 Go processing an insurance submission: from document receipt through field extraction and validation to structured output, configurable without engineering resources.
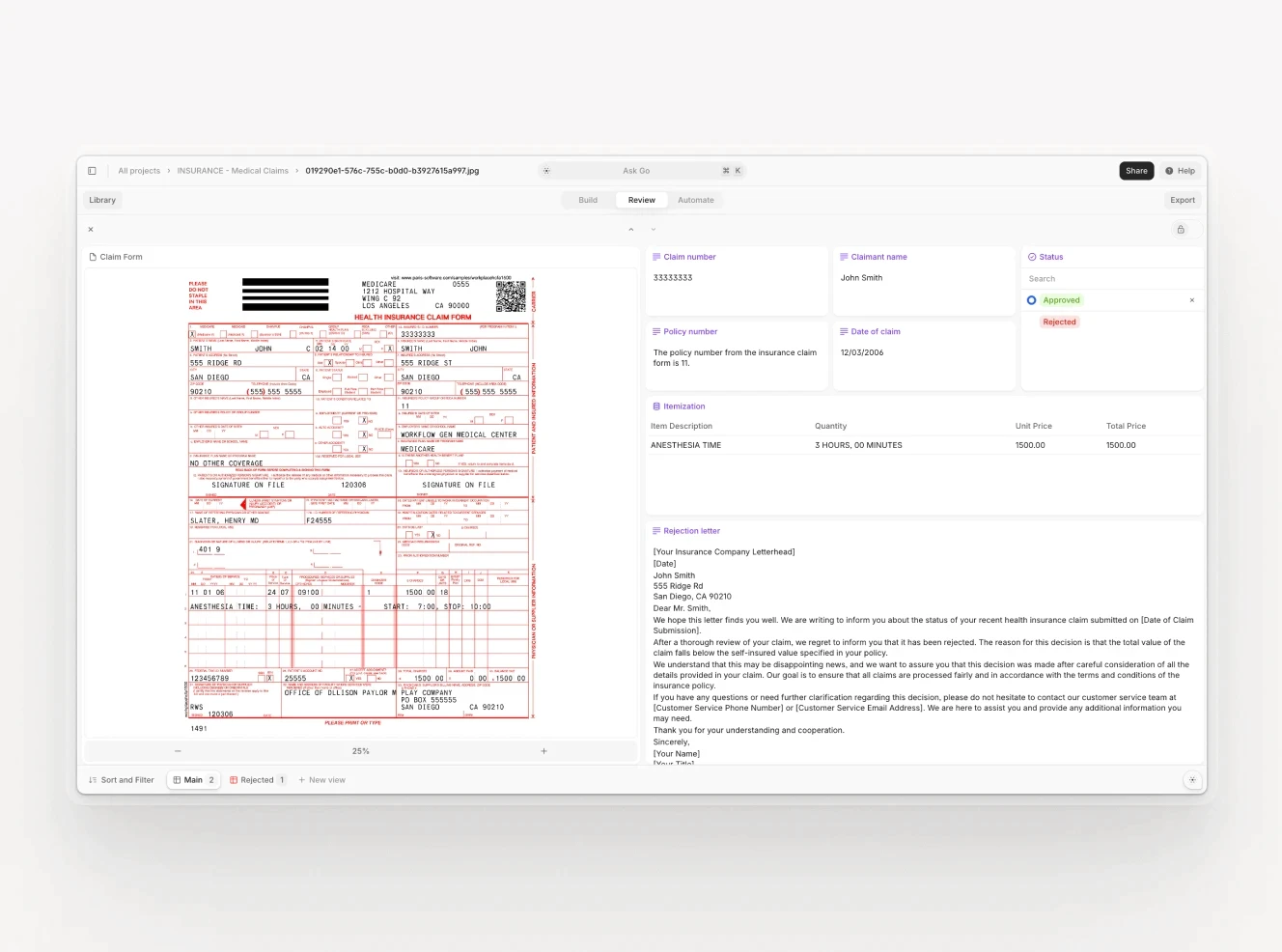
The V7 Go platform displaying extracted fields from an insurance submission, structured for direct input to a policy administration system, with each extracted value linked to its source location in the original document.
The operational case for insurance document automation
The argument for insurance document automation has always been intuitive. The measurement has been harder. Underwriters know that re-keying takes time; they are less certain about how much time is recoverable with technology, or what the transcription error rate actually is across their book.
The measurement question has become more tractable as extraction pipelines have matured. A modern extraction system produces confidence scores for every field it extracts, which means it also produces a record of every field that required human correction. That record becomes the baseline for understanding where the real friction is, which document types are causing the most exceptions, and which broker formats fail most often. The data that documents an automation program's ROI is produced by the automation itself.
For carriers and MGAs that have deployed extraction automation, the operational pattern is consistent. The first benefit is speed: quote turnaround times fall because the data preparation step is no longer the bottleneck. The second is accuracy: the transcription error rate drops, and errors that do occur are caught by the confidence-scoring layer rather than discovered after binding. The third is capacity: underwriters handle more submissions per week without additional headcount, because the administrative overhead has shifted to the system.
The configuration question has also changed. The earlier generation of template-based IDP required weeks of labelling and retraining for each new document format. LLM-based extraction platforms can be configured for a new document type in days. For a coverholder managing 30 different bordereaux formats from 30 different carriers, that difference determines whether automation is worth doing at all. For a broader look at how current AI tooling compares across the underwriting workflow, see our comparison of the best AI insurance underwriting software available to carriers and MGAs.

What is insurance document automation?
Insurance document automation is the automated extraction, classification, and routing of structured data from insurance documents including submissions, slips, ACORD forms, loss runs, and policy schedules, without manual re-keying. The process begins when a document arrives (typically as a PDF email attachment or through a submission platform), extracts relevant data fields such as named insured, policy period, limits, deductibles, and total insured value (TIV), and routes that structured data directly to a policy administration system, pricing tool, or downstream workflow. Insurance document automation is distinct from document generation (producing outbound policy documents) and from digital document storage (scanning and filing). Its purpose is to eliminate the manual data entry step between document receipt and underwriting decision, reducing administrative time, improving data accuracy, and enabling straight-through processing for submissions that meet pre-agreed appetite and pricing parameters.
+
What is an MRC slip and what does it contain?
A Market Reform Contract (MRC) slip is the standardised risk placement document used in the London Market for commercial insurance. Introduced to bring consistency to Lloyd's of London placements, the MRC slip typically runs 4 to 12 pages and contains: the risk description (class of business, type of coverage), named insured and policyholder details, policy period, limits of liability, deductibles and self-insured retentions, covered perils and exclusions, reinsurance terms and conditions, and the subscription lines showing each participating syndicate's line size and share of the risk. Despite the MRC standard, in practice every broker uses their own template, and the physical layout (where fields appear on the page, whether values are in tables or free text, and how sub-limits are presented) varies substantially between brokers. This variation is the primary reason template-based OCR systems struggle with MRC slips, and why LLM-based extraction, which understands the content rather than the layout, performs more reliably across the London Market submission base.
+
What is intelligent document processing (IDP) in insurance?
Intelligent document processing (IDP) in insurance combines optical character recognition (OCR) with document classification, field extraction, and validation to convert incoming insurance documents into structured data. A typical IDP pipeline works as follows: an incoming document is digitised by OCR, classified by type (MRC slip, ACORD form, loss run, etc.), a pre-trained extraction model identifies and extracts the relevant fields, and each extracted value receives a confidence score. Fields below the confidence threshold are routed to a human reviewer rather than passed directly to the downstream system. Traditional IDP systems are trained on labelled examples of specific document templates, which makes them accurate for known formats but unreliable when documents arrive in new or modified layouts. The current generation of IDP platforms replaces or augments template-based models with large language models (LLMs), which generalise across new formats without requiring retraining on each new broker template. This is a significant operational advantage in a market where no two broker slips look alike.
+
What is straight-through processing (STP) in insurance?
Straight-through processing (STP) in insurance refers to a submission or transaction that moves from receipt to completion (quote, bind, or policy issue) without any manual human intervention. For insurance submissions, STP requires three conditions: accurate and complete data extraction from the incoming document, a risk profile that matches the carrier's or MGA's predefined appetite, and pricing that falls within pre-agreed parameters. Industry average STP rates for commercial lines run between 15% and 30%; the leading carriers and MGAs using mature automation programs reach 60% to 70%. Document automation is the enabling step for STP: you cannot automate an underwriting decision if the data feeding that decision is incomplete or inaccurate. STP also applies post-bind: endorsement processing, renewal processing, and coverholder bordereaux reconciliation are all candidates for STP once the extraction step reliably produces clean structured data. For most operations, the bottleneck preventing higher STP rates is extraction accuracy, not the downstream pricing or policy administration logic.
+
How does AI improve insurance document processing?
The main document types requiring automated processing in commercial insurance are: MRC slips (Market Reform Contract slips), the primary placement documents in the London Market; ACORD forms (ACORD 125, 75, 80, 101, 23, and others) used in US commercial and personal lines; loss runs, which are multi-year historical claims records from the prior insurer; bordereaux, monthly or quarterly data files from coverholders to Lloyd's syndicates reporting bound risks and claims activity; policy schedules used for renewals and endorsement processing; e-submissions, which are broker email packages containing multiple documents in different formats; and first notice of loss (FNOL) documents used in claims intake. Each document type presents different extraction challenges: loss runs have no standard column format, bordereaux arrive in high volume on a schedule, ACORD forms are manually completed with variable handwriting quality, and MRC slips vary by broker despite the MRC standard. An enterprise extraction pipeline needs to handle all of these formats, classify them correctly on arrival, and route each document type to the appropriate extraction model.
+
What types of documents do insurers need to process automatically?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

