Playbooks
4 min read
—

The world's best data scientists are shifting their focus away from adding more humans to their workforce. Instead, they want to empower humans to deliver more accurate labels. Read on to learn why.

Matt Brown
Former Head of Sales
Training data and processes have evolved a lot over the last few years. An initially cautious approach was abandoned in place of massive scale in training datasets. Companies either built massive contact centers themselves or contracted with massive BPOs with a simple mandate: give us more training data.
However, this inevitably led to inaccuracies in the training data. These inaccuracies led to inaccurate models. And inaccurate models mean huge wastages in computer vision resources.
In one pertinent example, the talented team of CV Engineers at Lyft trained models against validation sets that are only 72% accurate.
So this model of building contact centers, sending data, receiving data back, training models, and deploying models requires change.
In this article, we’ll show that the world’s best data scientists shifted their focus away from adding more humans into their workforce and are obsessing over empowering those humans to deliver the most accurate labels to ensure the reliability of their models.
Bear in mind that every human we add to a team adds another layer of risk of inaccuracy.

Data labeling
Data labeling platform
Get started today
Train and label iteratively
Great teams avoid looking at training computer vision models as periods of labeling and then training. Instead, they do both continuously.
Thanks to progress in AutoML solutions, initial POC models can be produced earlier in the lifecycle than ever before, even at the scale of 10 input files. From there, pipelines can be built to establish programmatic iterative training cycles, to allow for almost constant re-training, visualization of the labels created, and correction of those labels before adding those back into a training dataset.
All this means that inaccuracies and edge cases are identified, ironed out, and that knowledge is passed back to the model as a continuous process, rather than a process of training and post-mortem diagnosis. Whilst model metrics can be helpful, using the methodology of full visualization of labels allows us to really understand the context.
So, our advice is to train iteratively, shorten your re-training cycles, and use labeling as a correction and visualization layer to models.
Rely more on consensus
Nowadays, great AI teams are obsessive over quality. They are using smart workflow automation to replace exhaustive human review with smart, consensus-driven workflows and model diagnosis for challenging tasks.
Now, this relies on smart workflow tools and constant analysis and re-analysis of data, but it allows us to quickly diagnose blind spots in our labeling and automate much of the QA process.
This is most powerful when combining human consensus with model confidence and adversarial model consensus, as well as model vs. human consensus.
All of this provides increasingly accurate statistics on where models and humans are underperforming and where consensus systems like IOU thresholds and majority voting can provide a further advantage.
Moreover, we’re finding that regulators like the FDA are increasingly looking for consensus-driven labeling for test and validation sets for devices that they are seeking to approve.
Specialize your humans
Great teams are looking at ways to reduce the complexity of human tasks so they can focus on consistently generating perfect labels on a more limited set of tasks.
We hear Tesla’s team are down to the level of having a “traffic light” team where all they label in panoptic segmentation tasks is the traffic lights.
Some tasks require specific domain knowledge or expertise, particularly in healthcare AI, so again, we’ll want to reduce the number of tasks where that expertise is needed. For example, if you work in dentistry and you want to identify pathologies in dentistry through an instance segmentation model, you may want to use models or humans to segment the teeth before dentists label the pathologies.
We’ve found that the more humans specialize and are trained on specific tasks, the more accurate their work becomes. Therefore our recommendation isn’t to grow the team but specialize their work more.











AI-assisted labeling
The key to fast labeling isn’t just to replace humans with models or to massively increase the number of humans you have working on tasks. Instead, it is to help and empower those humans to label accurately at greater speed.
Whilst the nature of labeling means that there will always be a human decision-making process, by using AI or ML-assisted labeling techniques, we can massively increase their efficiency, particularly for complex polygon creation.
This can be by empowering them to run models over images and correcting the output or identifying weak spots, or it can be by giving them semi-automatic tools to use to effectively “copilot” their annotation or provide greater assistance for challenging objects.
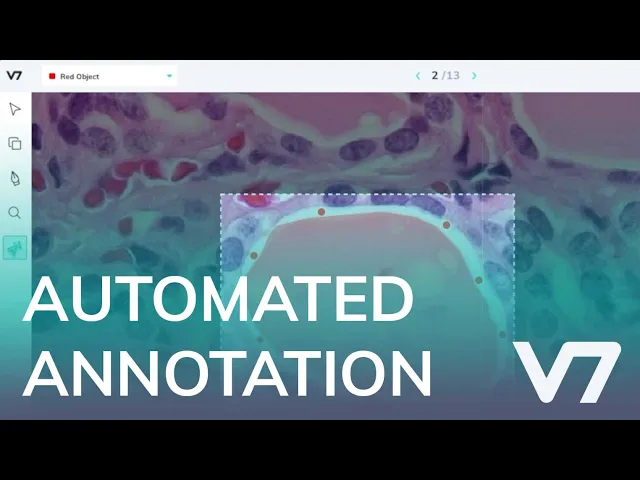
Every time we increase the number of clicks an annotator has to make, we increase the chances for error in our dataset, so we recommend providing them AI-assisted tools to enable them to work efficiently and accurately by generating large numbers of points at once.








