Document processing
19 min read
—


AI document automation for financial services: how it works, where it delivers the most value, and how to choose the right platform.

Document automation for financial services addresses a problem that scales with transaction volume. A residential mortgage file arrives at closing with an average of 500 pages: appraisal reports, title searches, income verification, tax returns, credit reports, insurance documentation, and the application itself. A Know Your Customer (KYC) onboarding process typically involves 12 or more documents per client. A single commercial loan request might land with 200 pages of financial statements, operating agreements, rent rolls, and environmental assessments.
None of this is new. Financial institutions have always been document-intensive. What has changed is the volume, the diversity of document formats, and the regulatory expectations around how those documents are processed, stored, and audited.
Most firms respond by adding headcount. More analysts, more operations staff, more third-party processors. The documents keep arriving; so do the costs. Manual data entry errors accumulate. Processing backlogs stretch from days to weeks. Audit trails become impossible to reconstruct cleanly. Compliance teams spend more time chasing records than reviewing them.
Document automation for financial services breaks this cycle. Not by replacing professionals, but by eliminating the mechanical parts of their work through intelligent document processing: extraction, classification, validation, routing, and filing. The professionals handle decisions. The systems handle everything else.
In this article:
What document automation for financial services is, and how it differs from document management
The types of documents financial institutions actually process and which present the greatest automation opportunity
How AI-powered document automation works, step by step
Specific use cases across banking, insurance, investment management, and wealth management
The difference between legacy rule-based tools and AI-native platforms
Compliance and regulatory requirements to evaluate before purchasing
How to select the right platform for your specific workflow

Document processing
AI for document processing
Get started today
What Is Document Automation for Financial Services?
Document automation for financial services is the use of software to capture, classify, extract, validate, route, and archive financial documents without manual intervention. The goal is to take an incoming document (a loan application, a KYC bundle, a claims submission, or an investment committee memo) and produce a structured, validated, actionable data output from it, ready for downstream systems to consume.
The most capable modern systems rely on intelligent document processing (IDP), which combines optical character recognition (OCR), machine learning classification models, and large language models to handle documents that vary in format, layout, and completeness. IDP is not the same as OCR alone. OCR converts image pixels into text characters. IDP understands what the text means: which numbers are revenue figures, which names are counterparties, which clauses modify indemnification terms.
This matters because financial documents are rarely uniform. A bank statement from one institution looks nothing like one from another. A due diligence questionnaire (DDQ) from one institutional investor has different fields than one from another. A lease abstract for a central London office building has different clause structures than one for a suburban retail unit. Rule-based systems that work well on standardised forms break down the moment the format changes.
The difference between document management and document automation
These terms are often conflated, but they describe different problems.
Document management | Document automation |
|---|---|
Stores and retrieves documents | Extracts data from documents and acts on it |
Organises files into folders or repositories | Classifies documents and routes them to the correct workflow |
Enables search by filename or metadata | Makes document content machine-readable and queryable |
Tracks version history | Validates extracted data against business rules |
Examples: SharePoint, Box, Documentum | Examples: IDP platforms, AI-native document workflows |
A financial institution can have world-class document management and still require four analysts to manually re-key data from PDFs into core banking systems. Document automation addresses the gap between storage and action.
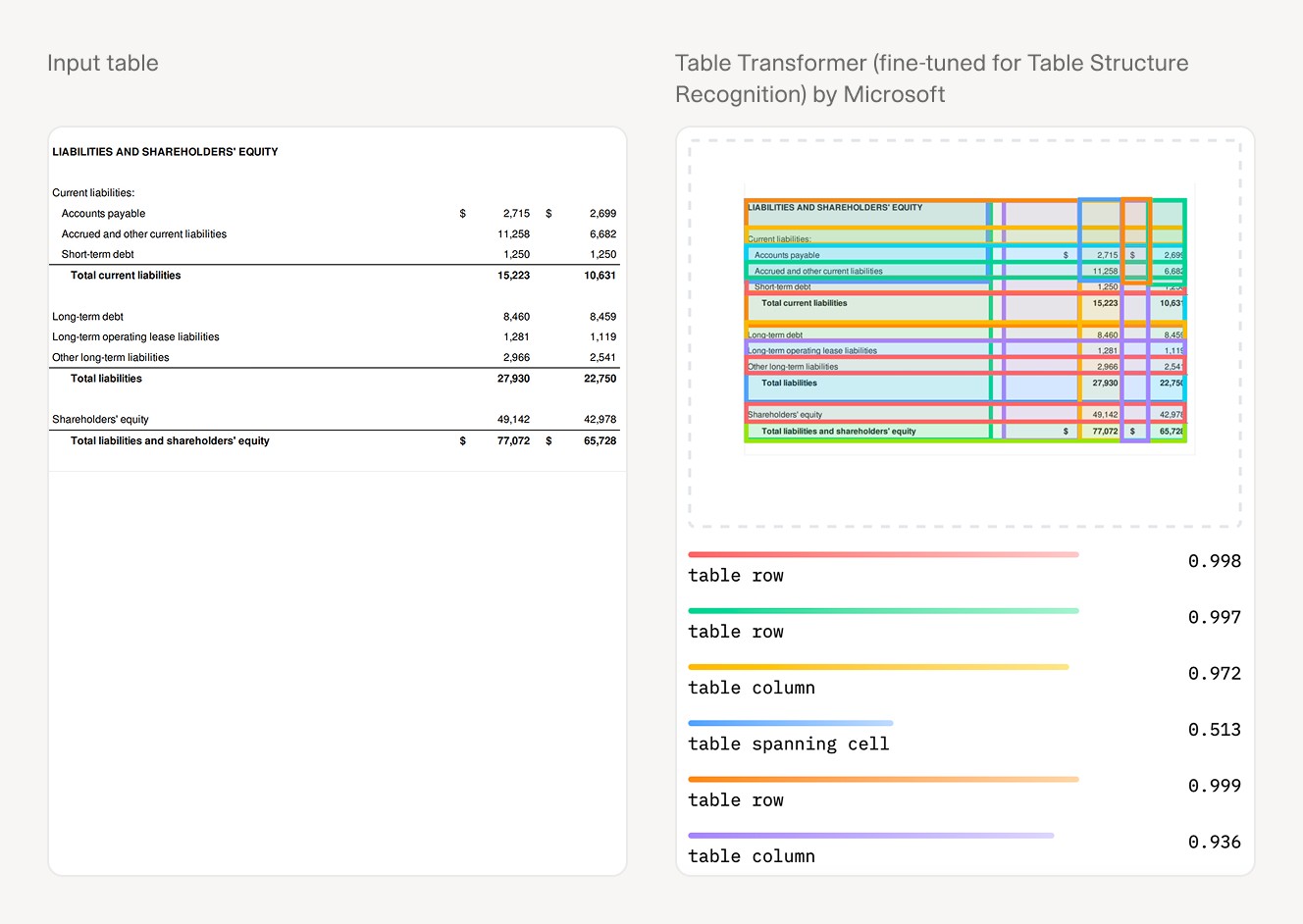
Raw financial table data alongside an AI-parsed structured output: the transformation document automation delivers at the extraction stage.
The Documents Financial Services Firms Actually Process
The automation opportunity varies significantly by document type. Some documents are highly structured and amenable to template-based extraction. Others are semi-structured or unstructured, requiring models that reason about context rather than match against fixed positions. The table below covers the document categories most commonly targeted for automation across financial services verticals.
Document type | Vertical | Automation challenge |
|---|---|---|
KYC / identity documents | Banking, wealth management | Varied formats across jurisdictions; non-Latin scripts; expiry validation |
Loan applications | Retail and commercial banking | Inconsistent layouts; multiple supporting document types per application |
Bank statements | Lending, credit, compliance | Format varies by institution; transaction categorisation at scale |
Invoices and receipts | Operations, accounts payable | Vendor format proliferation; line-item extraction; matching against purchase orders |
Trade finance documents | Corporate and investment banking | Letters of credit; bills of lading; certificates of origin, each with strict field requirements |
Insurance claims bundles | P&C, health, life insurance | Multi-document, multi-format submissions; medical records; photographs |
Investment policy statements | Wealth management | Client-specific; handwritten amendments; investment constraint extraction |
Fund reports and capital call letters | Private equity, asset management | Narrative-heavy; bespoke formats per GP; comparison across reporting periods |
Investment committee (IC) memos | Private equity, private credit | Lengthy narrative; financial model assumptions; decision logic extraction |
Due diligence questionnaires (DDQs) | Asset management, private equity | Long-form; 200-plus questions; answer quality varies significantly across respondents |
Regulatory filings (10-K, AIFMD, MiFID) | All financial verticals | High volume; material changes across periods; cross-reference requirements |
How AI-Powered Document Automation Works (Step by Step)
The mechanics of AI-powered document automation follow a consistent pattern, though the sophistication at each stage varies considerably between platforms. Each step reveals where a given platform adds genuine value and where manual intervention is still required.
Step 1: Capture and ingest
Documents arrive through multiple channels: email attachments, portal uploads, API feeds, scanned paper, and in some cases photographs taken in the field. Multi-modal ingestion — the ability to process PDFs, images, Word documents, and spreadsheets within a single workflow — is a baseline requirement for financial services, where document format diversity is the norm rather than the exception. Systems that require pre-conversion to a single format add manual handling steps that defeat the purpose of automation.
Step 2: Classify and extract
The system identifies what type of document it is processing and then extracts the relevant fields. Classification is not always straightforward: a 200-page loan package contains a loan application, financial statements, tax returns, entity documents, and insurance certificates, each requiring different extraction logic. Extraction accuracy is where AI-native platforms separate from legacy OCR tools. Rule-based systems degrade when layouts shift. Machine learning models generalise across format variation, and large language models can extract information from narrative text, not just structured fields.
Step 3: Validate and flag exceptions
Extracted data is checked against business rules: does the income figure on the bank statement match the figure on the application? Is the entity name on the signature block the same as on the certificate of incorporation? Is the invoice date within the allowed period for this purchase order? Exceptions are flagged for human review rather than passed downstream silently. This human-in-the-loop (HITL) capability is not optional in financial services. It is required under GDPR Article 22 for decisions with legal or financial significance.
Step 4: Route and approve
Validated documents and their extracted data are routed to the appropriate workflow stage. A loan application that passes income verification goes to underwriting. A claims submission with a missing document goes back to the submitting broker. An invoice above a certain threshold requires a second approver. The routing logic is configured per workflow and incorporates conditional branching based on extracted values.
Step 5: Integrate and act
The extracted, validated data flows into downstream systems: core banking platforms, CRM systems, loan origination software, claims management systems, portfolio management tools, or ERP platforms. Integration via API or flat-file export means the document automation layer does not require replacing existing infrastructure. It slots in as an intelligence layer on top of what is already there.
Step 6: Archive and audit
Every document, every extracted field, every validation result, and every routing decision is logged with a timestamp and user attribution. This produces an immutable audit trail that satisfies requirements under SOC 2, MiFID II transaction reporting, BSA/AML record retention, and GDPR data processing logs. The audit trail is not a secondary feature; for financial institutions, it is the primary compliance mechanism.
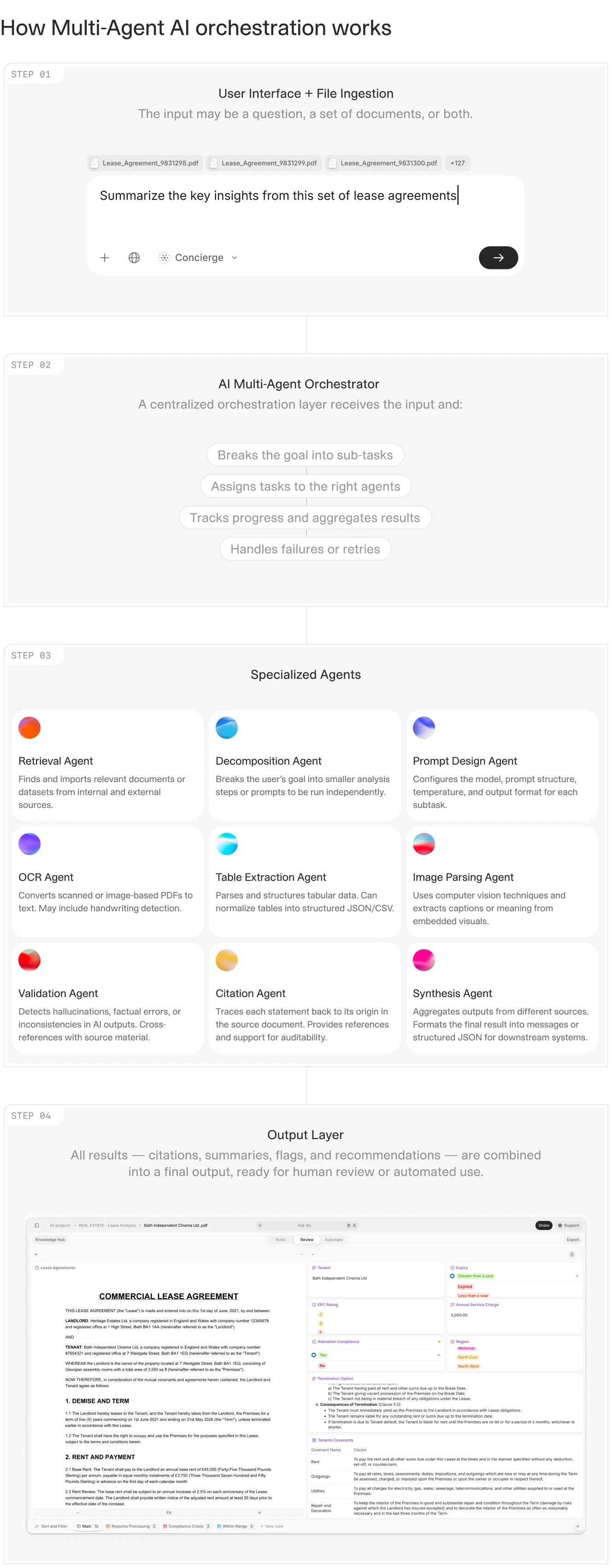
The six-stage document automation pipeline applied to financial services: capture, classify, extract, validate, route, and archive.
Document Automation Use Cases in Financial Services
The automation opportunity across financial services is not uniform. Some verticals have invested heavily in document automation for specific high-volume processes. Others — particularly alternative investment managers and private credit firms — have barely started. The use cases below illustrate both ends of that spectrum.
Banking and lending: loan processing and KYC
Loan processing is the most commonly cited financial services automation target, and for good reason. A commercial real estate loan package arrives with 150 to 300 pages across a dozen document types. Underwriters need the income and debt figures, the rent roll summary, the environmental report conclusions, and the entity structure, not the raw documents. The extraction step, when automated, reduces analyst time from six to eight hours per application to under 30 minutes, depending on the complexity of the deal.
KYC presents a different challenge: document variety rather than document volume. A cross-border corporate onboarding requires documents in multiple languages, from multiple jurisdictions, with different formats for the same underlying facts. Passport formats differ by country. Certificate of incorporation layouts differ by state or territory. An AI-native IDP system trained on global document formats handles this variation; a rules engine configured for a specific market does not.
Banks running automated KYC report processing time reductions from several weeks to two to three days for complex corporate onboarding, and near-instantaneous processing for individual retail customers where identity documents are the only input required.
Insurance: claims processing and policy administration
A property and casualty claims bundle typically includes the first notice of loss (FNOL), the adjuster report, contractor estimates, photographs, and sometimes medical records, all arriving through different channels in different formats. A single complex claim, handled manually, can take a claims examiner four to six hours. An automated intake and classification system reduces that to minutes for the mechanical parts, freeing the examiner to focus on coverage determination and settlement negotiation.
Policy administration is a secondary insurance use case that is frequently overlooked. Policy documents accumulate endorsements, exclusions, and amendments that layer onto base forms over the policy's lifetime. When a claim arrives, the examiner needs to know the current effective terms. Policy term extraction and reconciliation across amendment history, once automated, eliminates the manual review that currently causes most coverage disputes to drag on.
Investment management and private equity: the underserved use case
Banking and insurance have received the most attention in financial document automation discussions. Investment management and private equity have not. This is the gap worth examining.
An asset management operations team at a mid-sized fund manager might spend 30 to 40 hours per quarter manually compiling LP quarterly reports: pulling performance data from portfolio management systems, calculating attribution, formatting tables, drafting commentary, and cross-checking figures across multiple documents. AI agents can execute the assembly and verification steps in a fraction of that time. The investment judgement stays with the team; the mechanical work does not.
Private equity due diligence generates similar volumes. A deal team reviewing a target company works through a data room that might contain 500 to 1,500 documents: financial statements, customer contracts, employment agreements, regulatory licences, intellectual property registrations, and environmental reports. Each document type requires different extraction logic. The AI handles extraction and flags discrepancies. The analyst handles interpretation.
See how AI for investor reporting is changing how fund managers approach LP communications, and what the leading AI tools for investment banking are delivering across deal workflows.
The most underserved documents in this vertical are the bespoke ones: IC memos that follow no standard format, side letters with individually negotiated terms, DDQs from institutional investors with 200-plus questions, and capital call letters that require precise financial calculations. These are exactly the documents where rule-based automation fails and AI-native IDP adds material value. The dataroom to IC memo workflow and DDQ completion automation represent two of the highest-ROI entry points for investment managers evaluating document automation.
The video below shows V7 Go processing a CIM document bundle, applying the classification, extraction, and cross-referencing logic described above.

V7 Go processing a CIM: the type of multi-document task that currently consumes multiple hours of senior analyst time.
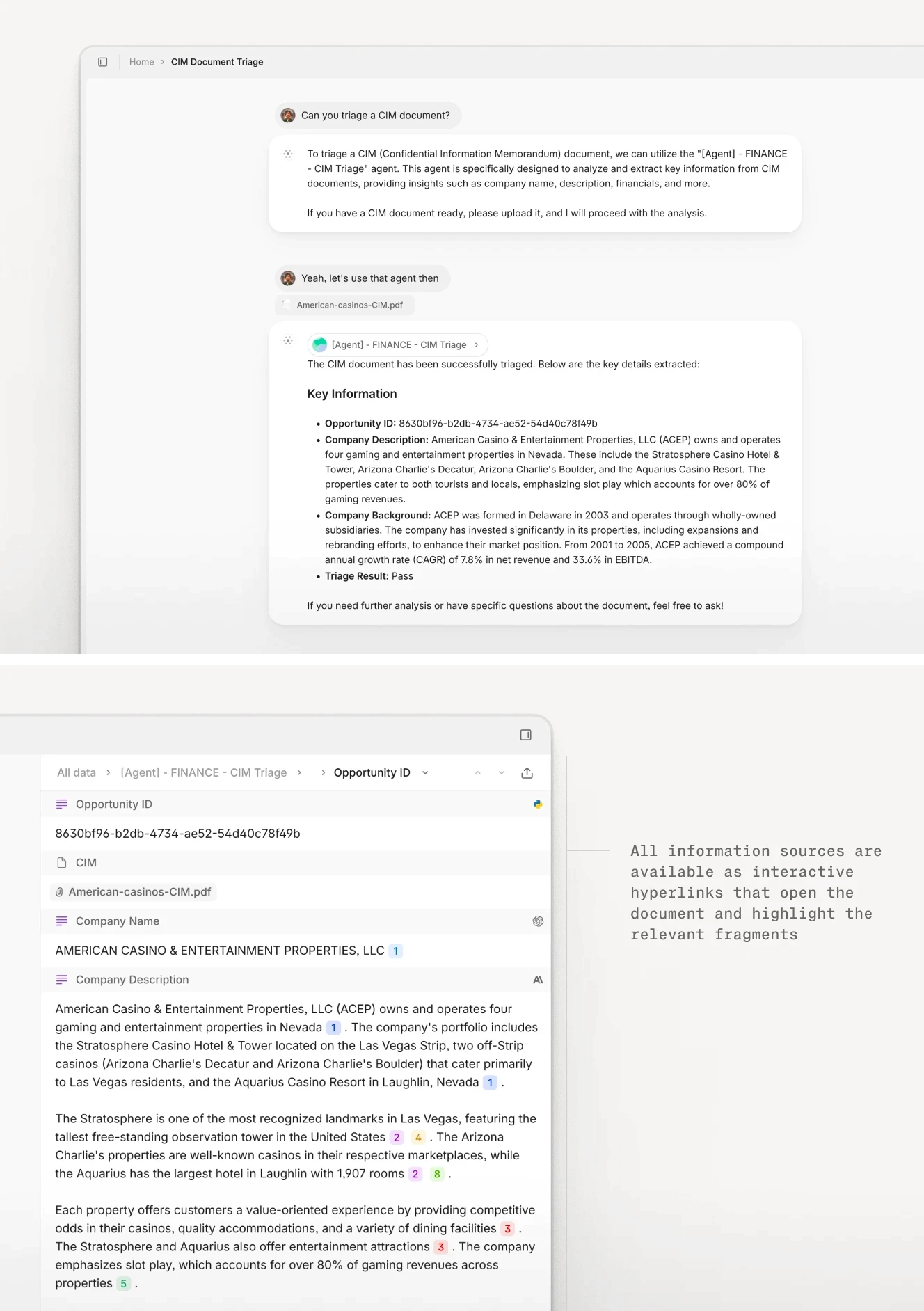
V7 Go extracting financial metrics from a CIM document bundle, with field-level source citations for each extracted value.
Wealth management: personalised client communications at scale
Wealth managers face a document automation challenge that is less about volume and more about personalisation. A client with a substantial portfolio, a specific investment policy statement, tax constraints, and ESG exclusions requires communications that reflect those specifics. At the scale of hundreds or thousands of clients, producing accurate, personalised reports and letters by hand is not sustainable.
Document automation in wealth management addresses two distinct workflows: the inbound side: processing client documents such as investment policy statements, tax filings, and custody statements from external managers, to extract and reconcile client data; and the outbound side: generating client-specific reports, proposals, and communications that incorporate extracted data. Both workflows are amenable to automation. Most wealth managers have neither fully automated.











Key Benefits of Document Automation in Financial Services
The business case for financial document automation is quantifiable at the process level. The figures below are drawn from independently published benchmarks.
Benefit | Benchmark | Source |
|---|---|---|
Reduction in per-document processing cost | Manual invoice processing costs an average of $9.40 per invoice; best-in-class automated processing costs $2.36 | Ardent Partners, AP Metrics that Matter |
Productivity improvement | AI-assisted workers complete 12.2% more tasks per hour and produce results rated 40% higher quality by independent evaluators | Harvard Business School / Boston Consulting Group, 2023 |
Revenue potential from AI in banking | Applying AI to financial document workflows could generate up to $1 trillion in additional annual value across banking | McKinsey Global Institute, 2023 |
Reduction in approval cycle times | Automated routing and exception handling reduce approval cycles by up to 20 times versus manual processing | Ardent Partners, Strategic Finance benchmarks |
Error reduction | Manual data entry error rates of 1 to 3% are common; automated extraction with validation reduces this to below 0.1% | Industry benchmarks across financial services |
Compliance risk reduction | Complete audit trails and automated retention policies address the most common cause of regulatory findings: missing or inconsistent documentation | PwC Financial Services Regulatory Report |
The arithmetic at the invoice level illustrates the broader point. At $9.40 per manually processed invoice and $2.36 per automated invoice, a financial institution processing 50,000 invoices per year saves $352,000 annually on that single document type. Most large financial institutions process millions of invoices, and several times more loan documents, claims submissions, KYC packages, and regulatory filings than invoices. The cost basis compounds across every document category.
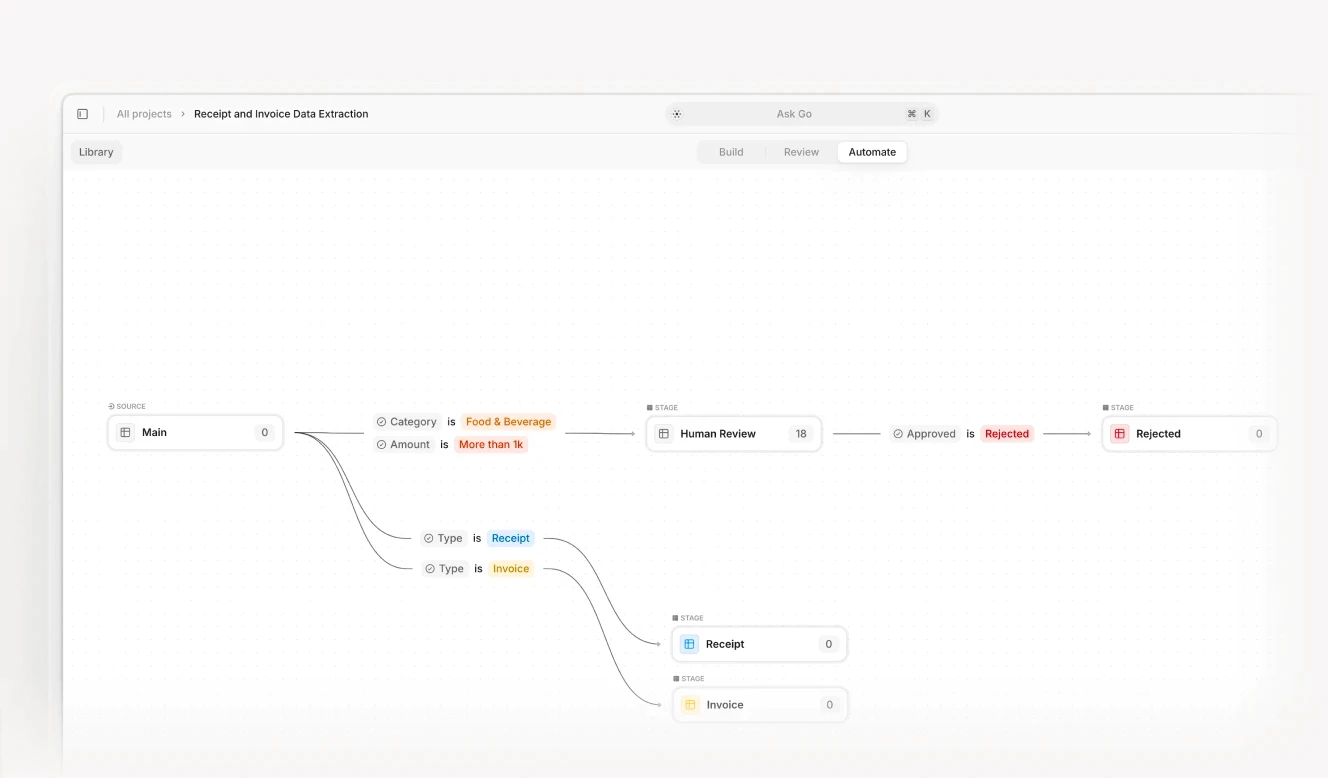
Automated invoice and receipt processing with AI extraction and configurable HITL routing: the cost differential between $9.40 and $2.36 per document is visible at workflow level.
Why AI-Native Beats Legacy Document Automation: The Buyer's Distinction
Most financial institutions that have attempted document automation previously did so with legacy tools: OCR engines combined with rigid extraction templates and rule-based routing logic. These systems work until they do not. The moment a document format changes, a new document type arrives, or a vendor updates their layout, the rules break and the exceptions accumulate.
AI-native document automation platforms take a fundamentally different approach. Rather than encoding document structure as rules, they learn from examples and reason about content. This is the distinction that separates vendors in the current market, and it is the distinction that buyers need to understand before committing to a contract.
Dimension | Legacy (OCR + rules) | AI-native (IDP + LLM) |
|---|---|---|
Document format handling | Fails on layout variation | Generalises across formats |
New document types | Requires template rebuild by IT or vendor | Configurable by the operations team |
Unstructured text extraction | Not possible | LLMs extract from narrative text |
Accuracy on handwritten content | Low; OCR degrades significantly | Higher; multi-modal models handle handwriting |
Exception handling | Documents fall to a manual queue without context | Exceptions flagged with reason codes, routed to HITL review |
Audit trail quality | Action logs only | Field-level provenance with source citations |
Configuration ownership | IT or vendor-dependent | Operations or business teams |
Scalability to new use cases | Each use case is a separate implementation project | Single platform; workflow-level configuration |
The configuration ownership point deserves emphasis. Legacy platforms require IT involvement or vendor professional services to add a new document type or adjust an extraction rule. This creates a backlog of document automation requests that business teams learn to stop submitting. AI-native platforms are configurable by the operations or compliance teams who understand the documents, not by engineers who have never handled a loan package or an IC memo.
For a broader view of how AI capabilities are reshaping financial workflows beyond document processing, see our analysis of generative AI in finance.

Eight dimensions where AI-native IDP outperforms legacy OCR-based automation: the differences compound across large document portfolios.
Compliance and Regulatory Requirements for Financial Document Automation
Compliance is not a post-purchase consideration in financial document automation; it shapes platform selection. The regulatory requirements below apply across the major financial services verticals and should be verified before any vendor evaluation begins.
Regulation | Requirement for document automation | Applies to |
|---|---|---|
GDPR Article 22 | Decisions with legal or financial significance cannot be made by automated means alone; HITL review required for in-scope decisions | All EU-regulated financial institutions |
SOC 2 Type II | Audit trail integrity; access controls; data retention and deletion capabilities | Financial institutions handling US client data |
MiFID II | Transaction records must be retained for 5 years; communications related to orders must be stored and reproducible on demand | Investment firms, brokers, and trading platforms in the EU |
Basel III / CRD V | Credit decision documentation; model risk management; data lineage for regulatory capital calculations | Banks and credit institutions under EU/UK prudential rules |
HIPAA | Health information in claims bundles must be handled with access controls, encryption, and audit logging | Health insurance and benefits providers |
BSA / AML | SAR and CTR documentation retained for 5 years; transaction records must support forensic reconstruction | All US-registered financial institutions |
Two practical implications follow. First, any platform deployed in EU-regulated financial services must support configurable HITL workflows, not as an option but as a default for in-scope decisions. Second, the audit trail must capture field-level provenance: which source document produced which extracted value, and who reviewed and approved it. An audit trail that logs only that a document was processed does not satisfy MiFID II or BSA/AML forensic reconstruction requirements.
How to Choose a Document Automation Platform for Financial Services
The market includes legacy OCR vendors that have added AI marketing to their product pages, point solutions built for a single document type, and genuinely AI-native platforms capable of handling the full range of financial document workflows. The distinction between vendors is only visible when tested against your actual document portfolio, not demo materials.
Six criteria should anchor the evaluation:
1. Accuracy on your specific document types. Request a proof of concept on 50 to 100 documents from your production environment. Measure field-level accuracy, not document-level success rates. A system that extracts 90% of fields correctly but consistently misses the key financial figures in your specific document format is not production-ready for that format.
2. Format generalisation. Test the platform on format variants it has not seen during the proof of concept. How does accuracy change when a bank modifies their statement layout, or a new insurance carrier joins your network? A rule-based system degrades sharply. An AI-native system degrades gradually and continues to function.
3. Configuration ownership. Who builds and maintains extraction workflows: your operations team or a vendor professional services team? The answer determines how quickly you can onboard new document types and how expensive it is to maintain the system over time.
4. HITL and exception handling. What happens when extraction confidence is low? Can your team review and correct extractions in the same interface, with corrections feeding back into model performance? A system that routes low-confidence results to a separate manual queue without learning from corrections will plateau in accuracy.
5. Integration depth. Can the platform send extracted, validated data directly to your core systems via API, webhook, or structured file export without custom development? What is the vendor's integration track record in your specific technology environment?
6. Regulatory compliance posture. Has the vendor completed SOC 2 Type II? Can the platform produce MiFID II-compliant audit trails? Is HITL a configurable workflow or an afterthought? Ask for evidence of each, not assurances.
How V7 Go Automates Financial Document Workflows
V7 Go is an AI agent platform built for document-intensive workflows in financial services. Rather than offering a single extraction model, it allows operations and compliance teams to configure multi-step agent workflows that capture, classify, extract, validate, and route documents through to downstream systems, without writing code.
The platform handles the full range of financial document types covered in this guide: KYC bundles, loan packages, bank statements, insurance claims, fund reports, IC memos, DDQs, and regulatory filings. Extraction is performed by large language models that reason about document content rather than match against rigid templates. When a bank modifies their statement format or a new general partner sends fund reports in an unfamiliar structure, the workflow continues to function without rule adjustments.
For investment management specifically, V7 Go supports AI-powered due diligence workflows that process data rooms at the document level, extracting and cross-referencing key facts across hundreds of files. The platform also handles financial statement spreading, converting raw financial statements from target companies or borrowers into structured data for underwriting or credit analysis, at a fraction of the time required for manual spreading.
Human-in-the-loop review is built into every workflow. Extracted fields that fall below confidence thresholds are surfaced to reviewers with source citations: the reviewer sees the extracted value alongside the exact passage in the source document from which it was drawn. Corrections are logged. Every processing decision is auditable at the field level, satisfying the documentation requirements of MiFID II, SOC 2, and BSA/AML.
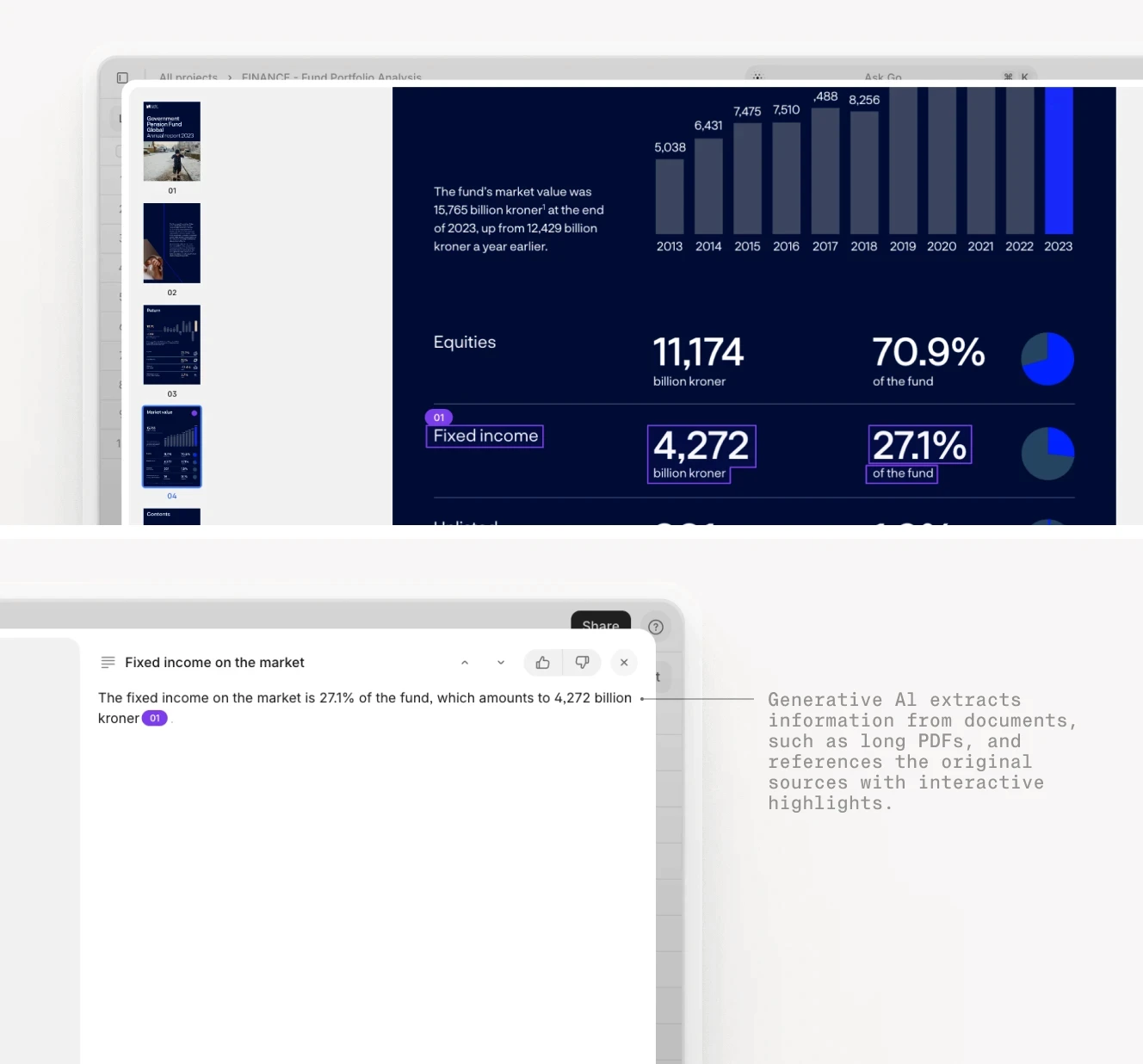
V7 Go extracting and highlighting financial metrics from a fund PDF, with field-level source citations linking each value to its origin in the source document.
Private credit and private equity firms sit at an interesting position in the document automation market. Their document volumes are lower than a commercial bank's, but the documents themselves are far more complex: bespoke legal agreements, confidential information memoranda, side letters with individually negotiated terms, and quarterly reports in formats that vary by general partner. The firms that have invested in document automation for these workflows consistently report the same outcome: not that they needed fewer people, but that the people they have were able to review more deals, serve more LPs, conduct portfolio monitoring more frequently, and focus on work that requires genuine investment judgement rather than mechanical data assembly.
Start with one workflow. The firms that have deployed document automation most successfully in financial services did not attempt to automate everything at once. They identified the document type that was consuming the most analyst time for the least analytical return, typically bank statement extraction for credit analysis or financial statement spreading for due diligence, automated that first, measured the result, and expanded from there.
At $9.40 per manually processed document and $2.36 per automated document, the return on the first workflow is calculable before you start. The return on the second, third, and fourth workflows — as your team's capacity is freed for higher-value work — is harder to quantify in advance. The firms that have gone through this cycle do not go back.

What is document automation in financial services?
Document automation in financial services is the use of software to capture, classify, extract, validate, and route financial documents, such as loan applications, KYC packages, insurance claims, and regulatory filings, without manual data entry. Modern systems use intelligent document processing (IDP), which combines optical character recognition (OCR) with machine learning models and large language models to handle documents that vary in format and layout. The goal is to produce structured, validated data from incoming documents and route it to the appropriate downstream system or workflow, reducing processing time, error rates, and operational cost. Unlike document management systems, which store and retrieve files, document automation systems act on document content.
+
How does document automation improve compliance in financial services?
Document automation improves compliance through three mechanisms. First, it produces immutable audit trails that log every extraction, validation, and routing decision with timestamps and user attribution, satisfying requirements under MiFID II, BSA/AML, and SOC 2. Second, it enforces consistency: every document is processed against the same validation rules, eliminating the variability that creates compliance gaps in manual processing. Third, configurable human-in-the-loop (HITL) workflows ensure that decisions with legal or financial significance, as defined under GDPR Article 22, are reviewed by qualified staff before action is taken. The audit trail produced by an automated system is typically far more complete and reproducible than what a manual process generates.
+
What types of documents can AI automate in financial services?
AI-powered document automation handles both structured and unstructured financial documents. Structured documents such as invoices, bank statements, and standardised application forms are amenable to template-based extraction, though AI adds value by handling format variation. Unstructured and semi-structured documents such as IC memos, side letters, DDQs, fund reports, legal agreements, and regulatory correspondence require AI systems that reason about narrative content, not just match fields to positions on a page. In practice, the highest-value automation opportunities in financial services are often the semi-structured documents: the ones that human analysts currently spend the most time on precisely because they cannot be handled by legacy rules-based tools.
+
What is the difference between legacy document automation and AI-native IDP?
Legacy document automation tools combine OCR with rigid extraction templates and routing rules. They work well on standardised forms with predictable layouts and break when formats change, new document types arrive, or content appears in unexpected positions. AI-native intelligent document processing (IDP) uses machine learning models and large language models to understand document content rather than match it to templates. This produces better accuracy on format variation, enables extraction from narrative text, and allows operations teams to configure new document types without IT involvement. The practical difference is most visible in financial services, where document format diversity is high: a legacy system handling 20 document types requires 20 separately maintained rule sets; an AI-native system handles them through a single configurable framework.
+
How long does implementation take for financial document automation?
Six criteria matter most. First, accuracy on your specific document portfolio: test against production documents, not demo materials. Second, format generalisation: how does accuracy hold up when document layouts change or new format variants arrive? Third, configuration ownership: can your operations team build and modify workflows without involving IT or vendor professional services? Fourth, human-in-the-loop capability: are HITL review queues and correction workflows built in, and do corrections feed back into model performance? Fifth, integration depth: can the platform connect directly to your core systems via API without custom development? Sixth, compliance posture: has the vendor completed SOC 2 Type II, and can the platform produce field-level audit trails that satisfy MiFID II and BSA/AML requirements?
+
What should financial institutions look for when choosing a document automation platform?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

