Document processing
9 min read
—



The right crm for private equity is rarely the problem. DealCloud, Affinity, or a custom system: most mid-market firms have already chosen. But open the deal record for a company that came through three months ago and you'll find the same thing: revenue blank, EBITDA blank, growth rate blank. The analysts reviewed the CIM. They just didn't have time to populate twelve fields in the CRM on top of writing their deal memo.
This is not a discipline problem. It is a structural economics problem. Mid-market PE firms review 200 to 400 confidential information memoranda per year. Each CIM takes 4 to 6 hours to process thoroughly. Expecting an analyst to extract and enter nine standardised data fields per document, on top of that workload, is a decision to keep the CRM permanently half-empty.
An AI extraction layer is the practical answer: ingest the CIM, pull the structured fields, produce a cited, reviewable record in minutes rather than hours.
This article covers:
Which CRM systems PE firms actually use, and how they differ
Why CIM data entry is the bottleneck, not the CRM software
The nine core fields that belong in every deal record at intake
How CIM sections map to fields in DealCloud and Affinity
What to look for when evaluating AI tools for this workflow
How V7 Go extracts structured deal data and populates your CRM automatically

Document processing
AI for document processing
Get started today
What CRM Do Private Equity Firms Use?
Two platforms dominate mid-market and growth equity: DealCloud (now part of Intapp) and Affinity. They approach the same problem from opposite directions, and understanding the difference clarifies why neither solves the data entry problem on its own.
DealCloud is purpose-built for the deal lifecycle. It handles pipeline management, LP relationship tracking, portfolio monitoring, and regulatory reporting in a single system. Firms with complex fund structures (multiple vintages, co-investment vehicles, separate accounts) typically choose DealCloud for its configurability and compliance features. It integrates with data providers like PitchBook and S&P Capital IQ, which reduces some manual enrichment work. CIM data entry is not one of them.
Affinity built its reputation on relationship intelligence. It auto-populates contact records from email and calendar activity, tracking every touchpoint with an adviser or founder without anyone opening the CRM. Mid-market and growth equity firms that prioritise relationship tracking and warm-deal sourcing tend to prefer Affinity for this reason. Its deal data fields are less granular than DealCloud's, but it requires less manual maintenance to stay current on who talked to whom.
Feature | DealCloud | Affinity |
|---|---|---|
Primary strength | Full deal lifecycle + LP management | Relationship intelligence + pipeline |
Auto data capture | Limited (data provider integrations) | Strong (email and calendar sync) |
Deal field configurability | High | Moderate |
Fund reporting | Yes | No |
Typical firm profile | $500M+ AUM, complex fund structures | $100M-$2B AUM, sourcing-focused |
CIM financial data entry | Manual | Manual |
The last row is the one that matters. Both platforms track who sent the CIM and when. Neither reads it. The structured financial data — revenue, EBITDA, growth rate, headcount, leverage — comes from analysts who open the PDF and type. Explore how generative AI is reshaping finance workflows more broadly, but the CIM data entry gap is the place where the lost hours are easiest to count.
Why CIM Data Entry Is the Real Bottleneck for PE Deal Teams
The economics are straightforward. A typical mid-market PE firm reviews 200 to 400 CIMs per year. Each document takes 4 to 6 hours to process properly: reading, extracting financial data, writing preliminary notes, and entering the key fields into the CRM. At the low end of both ranges, that is 800 analyst hours per year going into data transcription. At the high end, it exceeds 2,400 hours. That is more than a full analyst's annual capacity spent on form-filling.
The consistency problem compounds the volume problem. CIMs are unstructured documents. Each one is formatted by a different M&A adviser following different conventions. One presents TTM revenue in the executive summary; another puts it in a footnote to the adjusted EBITDA bridge on page 31. One states headcount as full-time equivalents; another gives total employees including seasonal contractors. Analysts interpret these figures and make judgment calls. Those calls are rarely documented in the CRM record. Six months later, comparing two deals on revenue is comparing figures that were not measured the same way.
Nine core fields should populate every CRM deal record at intake, regardless of platform:
Field | Where it typically appears in a CIM |
|---|---|
Revenue (TTM) | Financial highlights, executive summary, or management discussion |
EBITDA (TTM, adjusted) | Financial summary, EBITDA bridge, or add-back schedule |
YoY revenue growth rate | Financial highlights or historical performance table |
EBITDA margin | Stated in financial summary, or derived from revenue and EBITDA figures |
Employee headcount | Business overview, company description, or org chart section |
Founded year | Company history or executive summary |
HQ geography | Cover page or company description |
Primary vertical | Investment thesis or business overview |
Leverage / debt structure | Transaction overview (when disclosed) |
These nine fields are the minimum required for portfolio-level pattern recognition: spotting whether a sector is getting more competitive, whether EBITDA multiples are compressing, whether firms in a given geography are growing faster than the broader market. An empty CRM is a research tool that has never been switched on. The broader shift in PE due diligence processes starts here, at intake, where the most hours disappear.
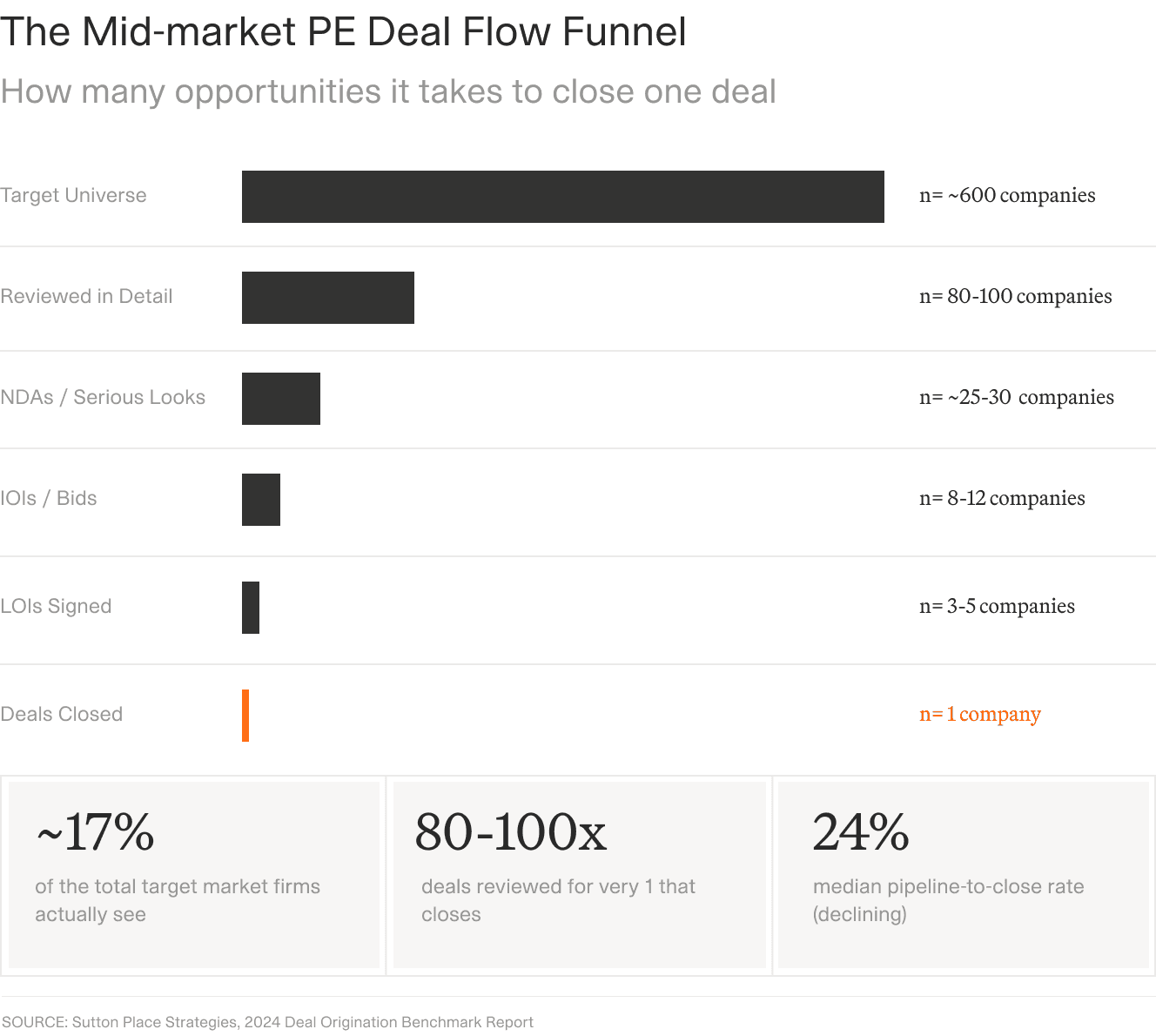
Deal volume across the PE funnel. CIM review is the highest-volume stage and the point where unstructured document data most often fails to reach the CRM.

AI introduces a structured extraction step at CIM intake, before the deal moves into formal diligence, so the CRM record is populated from the moment a company enters the pipeline.











Mapping CIM Sections to CRM Fields in DealCloud and Affinity
CIMs are not random documents. They follow a loose industry convention: business overview and investment highlights up front, financial performance in the middle, management team and transaction details at the end. The fields your CRM needs are distributed across all three sections, but the mapping is consistent enough to automate.
CIM section | Data extracted | DealCloud field | Affinity field |
|---|---|---|---|
Cover / Executive Summary | Company name, HQ, sector | Deal Name, Geography, Sector | Opportunity Name, Location, Industry |
Financial Highlights | Revenue TTM, EBITDA TTM | Revenue, EBITDA | Custom: Rev (TTM), EBITDA (TTM) |
Historical Performance | YoY growth rate, EBITDA margin | Revenue Growth, EBITDA Margin | Custom: Growth Rate, Margin |
Business Overview | Headcount, founded year | Employees, Founded | Custom: Headcount, Founded |
Transaction Overview | EV range, process type | Deal Size (Est.), Deal Type | Deal Value, Stage |
The complication is that the same field often appears in multiple places with different values. Revenue might appear in the executive summary as a rounded figure, in the financial highlights as a precise TTM number, and in the historical table as a full-year figure from the most recent audited period. An extraction agent needs to know which figure is authoritative — and needs to flag when figures across sections do not reconcile, rather than silently picking one. See the CIM-to-pipeline use case for how extraction connects to the broader deal qualification workflow.
How to Evaluate AI Tools for CIM-to-CRM Automation
Most AI extraction demos look identical. Upload a PDF, get a table of values. The differences that matter for production use do not show up in demos — they show up three months in, when the analyst asks why the revenue figure in the CRM does not match the CIM they reviewed last quarter.
Five criteria separate production-ready tools from polished demonstrations:
Source traceability. Does the tool cite the exact page, paragraph, and text behind each extracted value? Without citations, the analyst's verification workflow is to re-read the CIM, which is precisely what automation is supposed to eliminate. With citations, verification takes 90 seconds per field.
Field-level configurability. Can you define the exact CRM fields to populate, the format each field expects (numeric vs. string, thousands vs. millions, USD vs. local currency), and the section of the CIM to prioritise for each field? A tool that extracts "revenue" as unformatted text when DealCloud expects a numeric field in thousands produces a data cleaning problem, not a solution.
Handling of conflicting figures. What happens when the CIM has a $48.3M revenue figure on page 4 and a $47.1M figure on page 19? Does the tool pick one silently, average them, or flag the discrepancy for human review? Silent resolution is not acceptable when the downstream use case is investment analysis.
Integration path to the CRM. Does the output connect to DealCloud or Affinity directly, or does it produce a CSV that someone then imports manually? The latter replaces one form of manual work with another. A production workflow writes to the CRM without an intermediate human step.
Audit trail for compliance. Can operations or compliance see what was extracted, from which document version, by which agent configuration, and when? For SEC-registered advisers, this is not optional infrastructure.
How V7 Go Extracts Deal Data from CIMs and Populates Your CRM
V7 Go is a document AI platform built around configurable extraction agents. For CIM-to-CRM workflows, the architecture maps directly to the five criteria above.
A CIM arrives via direct upload or from a deal intake email address. An extraction agent, configured to the exact field schema of your CRM, reads the document and pulls each value with a citation: the page number, the paragraph, and the verbatim text that produced the result. The AI Citations feature means the analyst opens a pre-populated CRM record with sources attached. Verification is a spot-check, not a re-read.
Field output format is configurable at the property level. Revenue comes out as a number in thousands, or millions, formatted to match what DealCloud or Affinity expects. EBITDA includes the adjustment schedule reference. Headcount distinguishes FTEs from total employees if the CIM makes that distinction. When figures conflict across sections, the agent flags the discrepancy rather than resolving it silently: the analyst sees both values and selects the authoritative one.
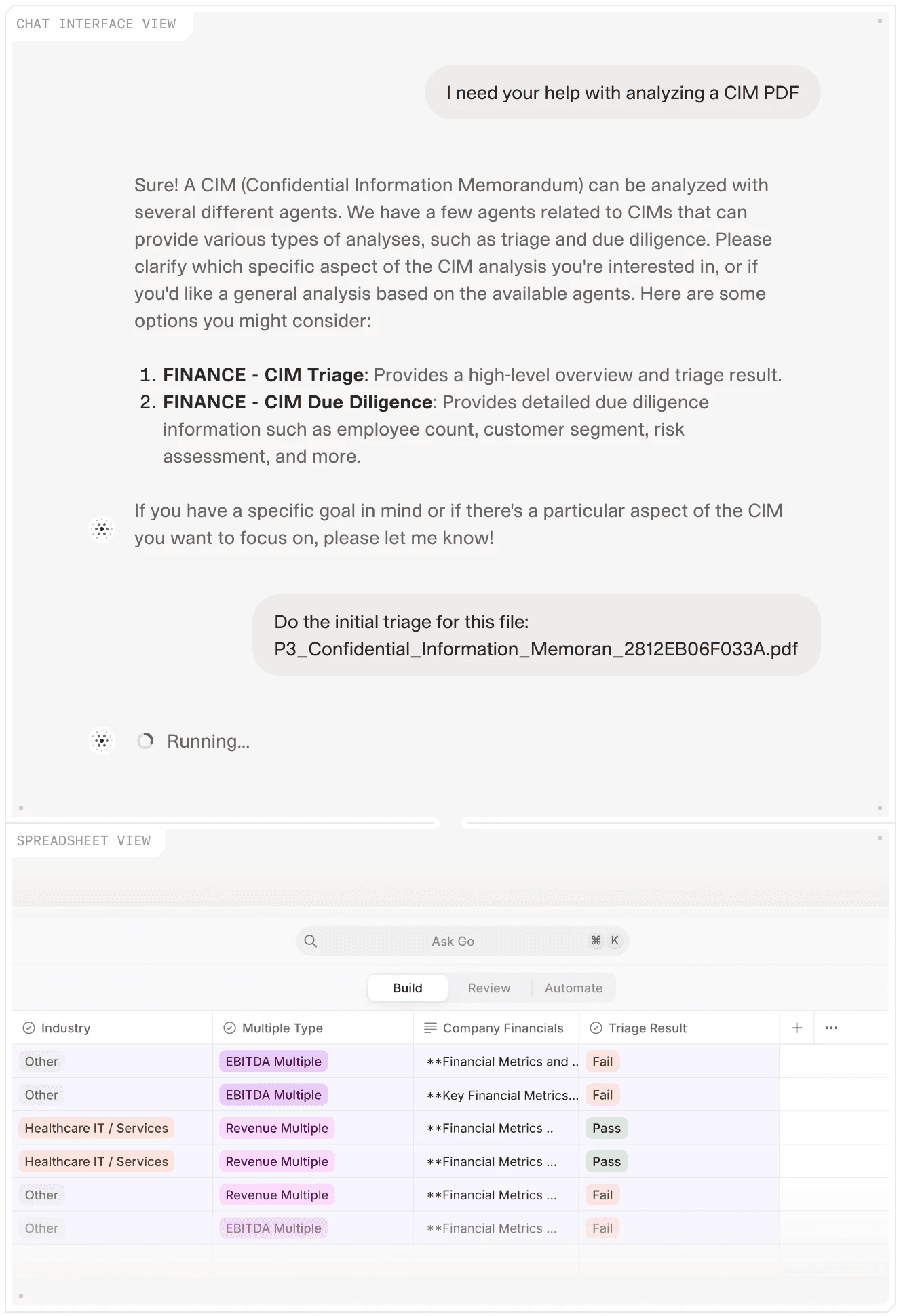
V7 Go's CIM analysis interface. Analysts select between triage and full extraction modes; results populate a structured deal record with citations to the source document.
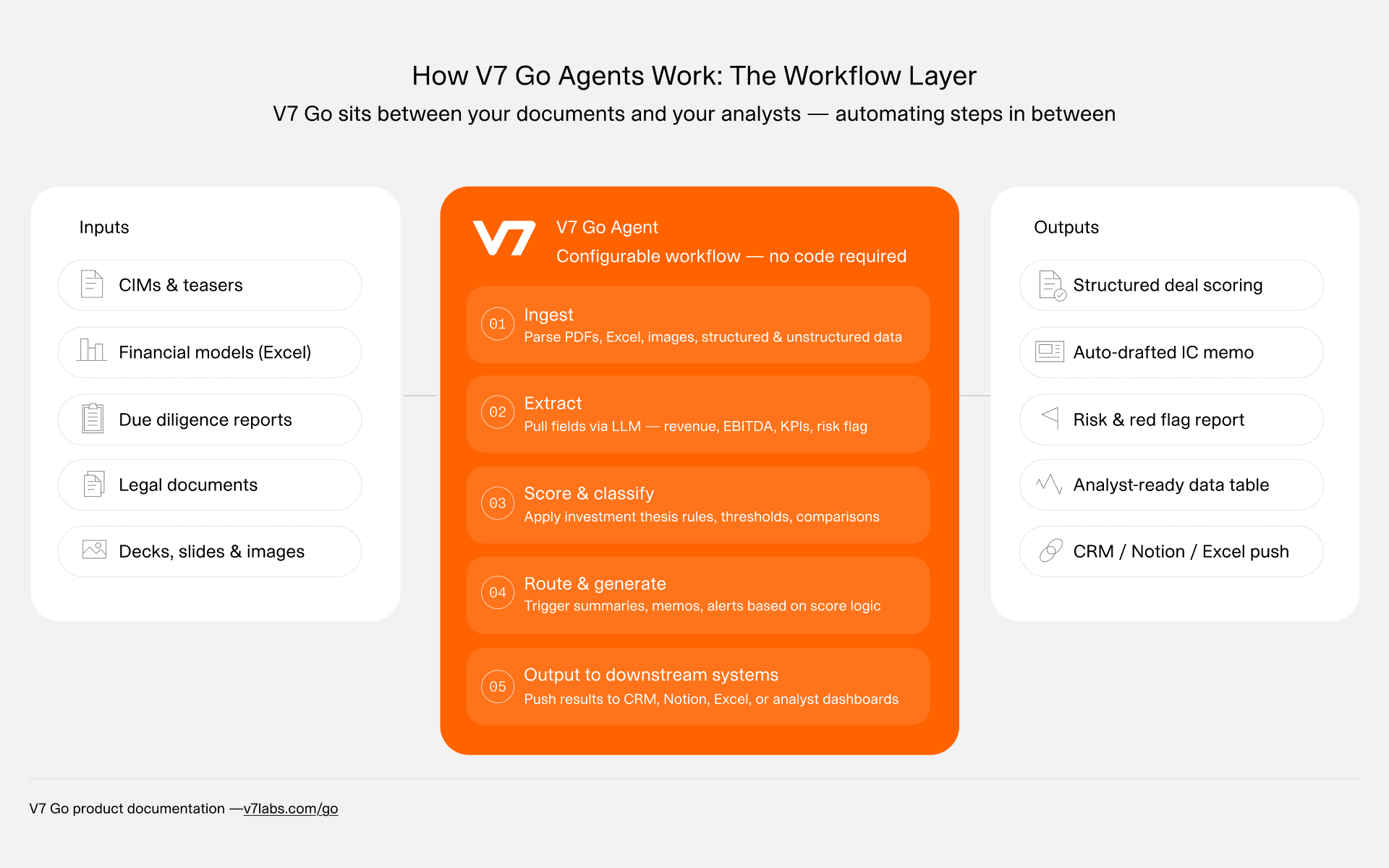
V7 Go's agent architecture: documents feed into a configurable extraction pipeline that produces structured, cited outputs ready for CRM integration.
The CIM review automation handles the extraction step. If your team also runs CIMs through an investment triage pass before the deal enters the formal pipeline, the AI due diligence agent handles the qualification layer upstream, so triage and data entry run in parallel rather than sequentially.
The practical outcome: a CIM that arrives at 9:00 AM produces a populated, reviewed CRM record by 9:15. The analyst spent those 15 minutes on exception handling: reviewing discrepancies the agent flagged, not on transcription. The CRM data is current, consistent, and cited back to its source document.
The CRM Was Already a Good Investment. AI Makes It Worth Using.
Private equity firms did not overpay for DealCloud or Affinity. They underfunded the data entry step that determines whether those platforms contain anything useful.
An AI extraction layer does not change the CRM. It changes what the CRM contains. When every CIM produces a populated, cited, reviewable record within minutes of arrival, the analytics the CRM was supposed to enable — sector pattern recognition, valuation benchmarks, coverage gap analysis — become possible for the first time. The database you needed has been there all along. It was just empty.
See the CIM-to-CRM use case to understand exactly how V7 Go maps CIM data to your deal fields in DealCloud or Affinity.

What is the best CRM for private equity?
The most widely used CRMs in private equity are DealCloud (Intapp) and Affinity. DealCloud is generally preferred by larger firms or those with complex fund structures: multiple vintages, co-investment vehicles, LP-specific reporting requirements. It offers deeper deal lifecycle tracking, portfolio monitoring, and compliance features. Affinity is favoured by mid-market and growth equity firms that prioritise relationship intelligence. It auto-populates contact records from email and calendar activity, reducing manual CRM maintenance for sourcing-focused teams. Both platforms are capable. The more relevant question for most PE teams is not which CRM to choose but how to ensure that CIM financial data actually populates the deal records, regardless of platform. An empty CRM is not a platform problem; it is a data entry problem. AI extraction tools like V7 Go address this gap by automatically pulling structured fields from CIMs and writing them to your CRM, whichever system you use.
+
Does DealCloud support AI data extraction from CIMs?
DealCloud integrates with third-party data providers such as PitchBook and S&P Capital IQ to auto-populate certain company-level fields from external databases. It does not natively extract structured financial data from CIM documents. CIMs are proprietary, unstructured PDFs, each formatted differently by the adviser who prepared it, and they contain non-public financials that external data providers do not carry. Extracting revenue, EBITDA, growth rates, and deal terms from a specific CIM requires a document AI layer on top of DealCloud, not a data provider integration. V7 Go connects to DealCloud's data model through configurable field mapping: the extraction agent pulls each value from the CIM and outputs it in the format DealCloud expects, so the deal record populates without manual entry. The same approach works for Affinity's custom fields and opportunity tracking structure.
+
How does AI extract structured data from a CIM?
A CIM extraction agent works by reading the full document and identifying where each target field is located, based on section headers, table structures, and the language surrounding a given figure. For each field, the agent pulls the value and records a citation: the page number, the paragraph, and the verbatim text that produced the result. This citation is critical. Financial figures in CIMs often appear in multiple places with slightly different values. An executive summary might round revenue to the nearest million while the detailed financial table shows the precise TTM figure. A well-configured extraction agent knows which source to prioritise for each field and flags discrepancies for analyst review rather than resolving them silently. The output is a structured record with each field, its value, its format, and its source, mapped directly to the CRM field schema. Analysts review cited outputs rather than re-reading the document from scratch.
+
What data fields should a PE CRM capture from every CIM?
Nine core fields should populate every CRM deal record at the point of initial CIM review: revenue on a trailing twelve-month basis, adjusted EBITDA on the same basis, year-over-year revenue growth rate, EBITDA margin (stated or derived), employee headcount, founded or incorporated year, headquarters geography, primary industry vertical, and leverage or debt structure where disclosed in the transaction overview. These nine fields are the minimum required for portfolio-level pattern recognition: comparing sector valuations over time, identifying compression in EBITDA multiples, spotting geographic concentration in the deal pipeline. Additional fields vary by firm strategy. Recurring revenue percentage, customer concentration, churn or retention metrics, and management team tenure are common additions for software or services-focused mandates. The exact list should match your CRM's field schema so that extraction outputs write directly to the right place.
+
How long does it take to set up CIM-to-CRM automation with V7 Go?
AI extraction accuracy is high for well-defined, clearly labelled fields: company name, geography, founded year, stated revenue figures, headcount where given as a single number. Accuracy is lower for derived or ambiguous fields: EBITDA margin calculated from unstated figures, growth rates that require choosing between fiscal year and TTM bases, or leverage ratios that depend on which debt tranche the CIM disclosed. The practical answer is that AI-extracted data is accurate enough to populate the CRM for pipeline tracking and pattern recognition, which is the primary use case, but should always carry citations so analysts can verify specific inputs before using figures in an investment committee memo or valuation model. V7 Go's AI Citations feature attaches the source text to every extracted value, so the verification step is targeted: the analyst checks flagged discrepancies and the highest-stakes fields, rather than re-reading the full document. Source traceability is what converts AI extraction from a convenience into a workflow that finance teams trust.
+
Is AI-extracted CIM data accurate enough for investment decisions?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

