Document processing
9 min read
—


Compare AI tools for commercial lines underwriting: submission intake, SOV extraction, loss run processing, and STP automation for P&C carriers and MGAs.

A commercial lines submission arrives as a 40-page PDF. Inside: an ACORD 125, a schedule of values covering 300 locations, three years of loss runs from two prior carriers, and a supplemental questionnaire the broker completed by hand. The underwriter has 48 hours to quote or decline.
That is the job today. Submission volume has grown while underwriting teams have stayed flat. The tools most carriers rely on—shared mailboxes, PDF readers, spreadsheets—were not designed for this pace or this document complexity. Commercial lines is the largest segment of the US property-casualty market, yet its document processing workflows remain among the most manual in financial services.
This article compares the AI tools built for commercial lines underwriting workflows: what each category does, where it fits in the process, and how to evaluate options against your operation's specific bottlenecks.
In this article:
The document problem in commercial lines underwriting
AI tool categories for submission processing and STP
V7 Go for commercial lines document extraction
How to evaluate and select tools for your operation

Document processing
AI for document processing
Get started today
The Document Problem in Commercial Lines Underwriting
Commercial lines underwriting is, at its core, a document processing problem. Before an underwriter can make a risk decision, someone must extract structured data from unstructured documents. At most carriers, that someone is still a person typing values into a system for two to four hours per submission.
The Submission Triage Problem
A submission that takes four hours to manually process costs the carrier roughly the same whether it binds or not. For a book with a 30% bind rate, seven out of ten submissions consume full processing time for zero written premium. At scale—500 submissions a month across a commercial lines team—the math stops working.
The core bottleneck is structured extraction from unstructured documents. ACORD forms follow a standard layout on paper, but submissions arrive as scanned PDFs, broker-generated PDFs, email attachments, and occasionally faxes. The named insured on the ACORD may not match the entity name on the loss run. The schedule of values may list 200 locations in a format designed by the prior carrier, with address fields split across columns that share no label with any recognized standard.
Carriers that have reduced triage time built a front-end intake layer that classifies documents, extracts summary risk data, and routes submissions before a processor touches them. The AI insurance underwriting guide covers the full workflow in depth, but the entry point is always the same: reliable document classification followed by accurate field extraction.
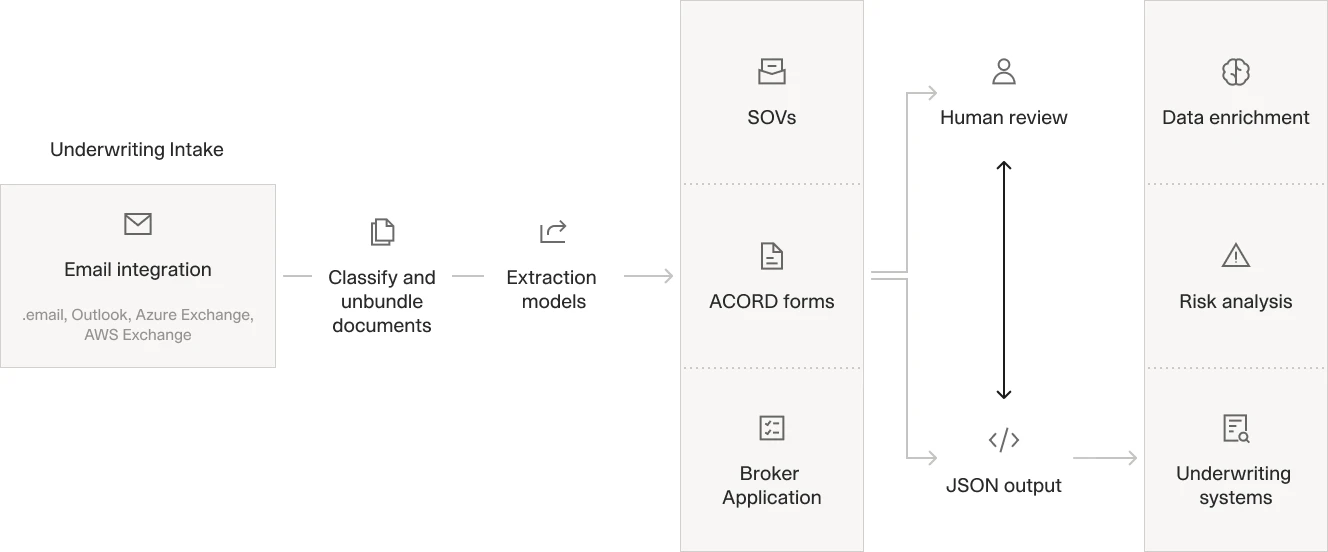
An automated submission intake workflow, from document receipt through classification to triage and routing.
Three Document Types That Create the Most Friction
Schedules of value arrive in carrier-specific Excel formats, broker-generated spreadsheets, and hand-typed tables. A 300-location SOV may contain 40 columns (construction type, occupancy, year built, replacement cost value, protection class) across multiple tabs with no consistent structure. One carrier's "TIV" column is another's "RCV." Extraction requires understanding the semantic meaning of the field, not just reading its label.
Loss runs present a different problem. Each prior carrier formats its loss run PDFs differently. Reserve amounts may appear at the claim level, the policy level, or not at all. Open claims require different treatment from closed claims for actuarial purposes. A five-year loss history spread across three prior carriers produces three documents with no common structure and no cross-document key to reconcile them.
Supplemental applications for specialty lines (contractors, habitational, professional liability) contain risk-specific questions alongside standard ACORD data. These question-and-answer pairs must be extracted and mapped to referral rules in the underwriting guidelines. A 40-question contractor supplemental produces 40 data points that must reach the rating system before the underwriter sees the account.
An intelligent document processing platform mapping raw submission documents through extraction and insight generation to downstream underwriting actions.
What Straight-Through Processing Actually Requires
Straight-through processing (STP) in commercial lines means the system reads submission documents, extracts the necessary fields, applies referral rules, and either generates a quote or routes the submission for human review, without a processor manually entering data at any step.
Reaching STP for even a portion of a commercial book requires four capabilities working in sequence: reliable document classification, accurate field extraction, rule application, and system integration. Each step must succeed for the pipeline to deliver a result the underwriter can act on. A failure at any step reverts the submission to manual handling.
Most carriers achieve partial automation for personal lines but struggle with commercial lines because of document variability. The NAIC's InsurTech research notes that carrier AI adoption concentrates first in structured data extraction from standardized forms before expanding to semi-structured commercial documents, which reflects the real technical difficulty of the problem, not a lack of carrier interest.
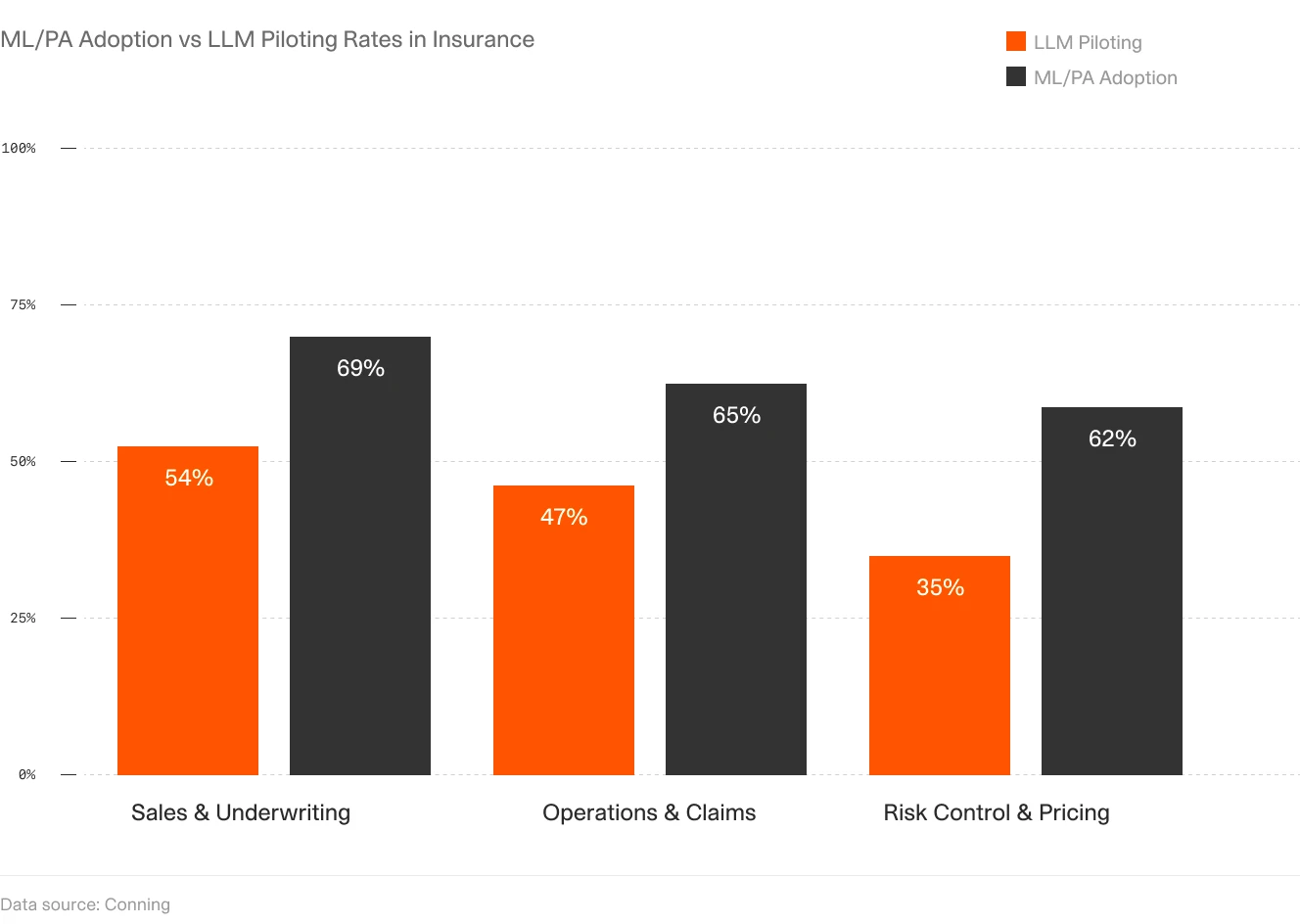
ML and predictive analytics adoption in insurance has outpaced LLM deployment, reflecting the maturity gap between proven extraction tools and generative AI applications in underwriting workflows.











AI Tool Categories for Commercial Lines Underwriting
The commercial lines AI tool market has three distinct categories, each addressing a different part of the submission workflow. The best AI insurance underwriting software guide compares leading options in detail. The short version: the category you need depends on where your processing time is going, not on vendor positioning.
Submission Intake and Triage Platforms
The first category addresses the front end of the process: receiving submissions, classifying documents, extracting summary data, and routing to the right underwriter or queue.
These tools typically integrate with the carrier's shared mailbox or broker portal. When a submission arrives, the tool identifies the document types present, extracts key risk characteristics (named insured, coverage type, effective date, TIV or payroll) and routes based on class of business or account size.
The value is triage speed and consistency. An underwriter who previously spent 30 minutes opening attachments and reviewing an account before deciding whether to quote can instead review a structured summary and make that decision in five minutes. At volume, this difference determines whether the carrier's bind ratio reflects underwriting judgment or processing capacity.
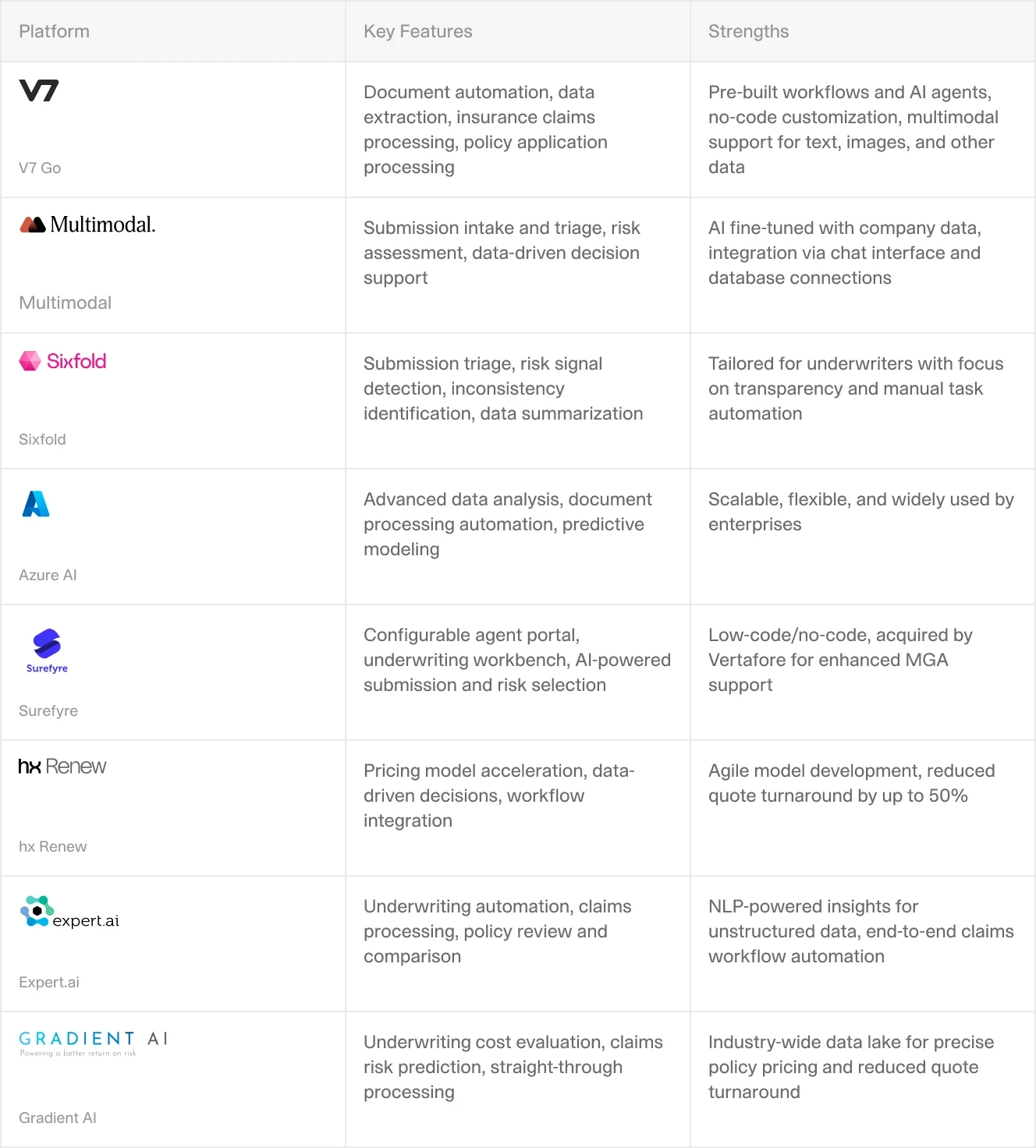
A feature comparison of AI underwriting platforms by workflow stage, document type, and integration capability.
Intelligent Document Processing for SOVs and Loss Runs
The second category focuses on high-complexity document extraction: schedules of value, loss runs, supplemental applications, and endorsements. These are the document types where manual processing time is highest and where data entry errors create downstream pricing problems.
Intelligent document processing tools combine OCR with extraction models trained on insurance document formats. The distinction from general OCR is semantic understanding: IDP tools recognize that "Replacement Cost," "RCV," and "Insured Value" refer to the same data point across different SOV formats, because they understand context, not just because the column headers match.
For loss runs specifically, capable tools identify claim status (open vs. closed), extract reserves, calculate five-year incurred losses, and flag catastrophe years for separate actuarial treatment. This structured output replaces the work of a processor reading each claim line and transcribing values into a spreadsheet the underwriter then re-reads.
The Insurance Information Institute reports that commercial lines represents the largest segment of the US property-casualty market by written premium, a scale that makes even incremental processing efficiency gains material for carriers operating at volume.
Purpose-Built Underwriting Intelligence Platforms
A third category combines extraction with underwriting logic: referral rules, appetite checks, pricing guidance, and workflow management. These platforms sit between submission intake and the policy admin system, adding applied underwriting judgment to the data pipeline.
The limitation is configurability. Each carrier's referral rules, authority thresholds, and underwriting guidelines differ. Platforms that embed their own logic require significant configuration to approximate carrier-specific requirements and ongoing maintenance as guidelines change. For carriers with stable, clearly documented appetite, this works. For carriers that revise guidelines frequently, the maintenance overhead is a real implementation cost that vendors rarely lead with in sales conversations.
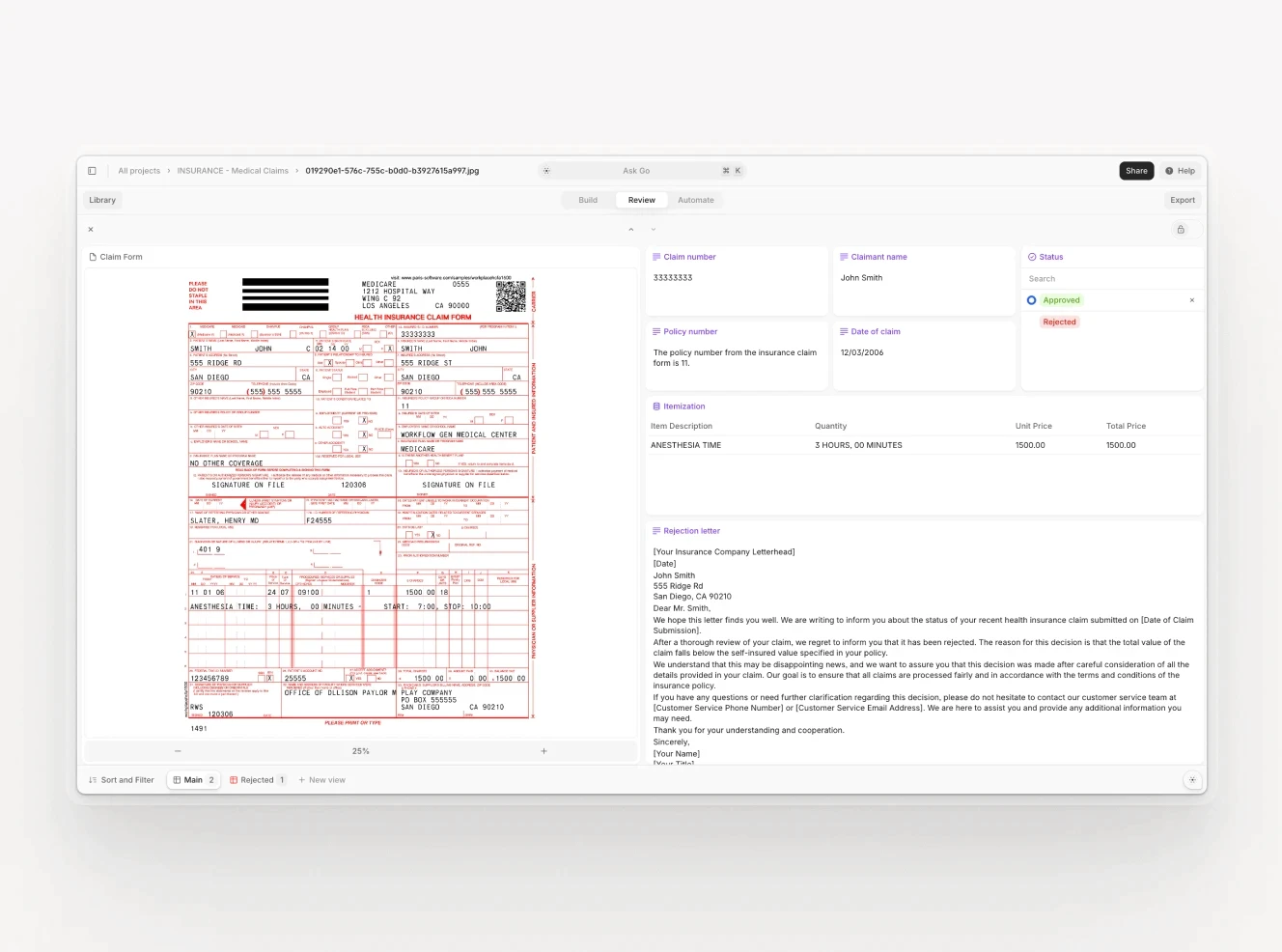
V7 Go for Commercial Lines Submission Processing
V7 Go addresses commercial lines document processing through configurable AI agents that carriers and MGAs build to match their specific workflow requirements, rather than configuring a vendor's predefined logic to approximate those requirements. For a production view of submission processing at scale, the V7 Go workflow covers intake to structured extraction in under 30 seconds per submission.
An underwriting team configures an agent that receives the full submission package—ACORD application, SOV, loss runs, supplementals—and extracts the fields their system needs. The agent applies the carrier's classification logic, produces a structured submission summary, and routes the result to the appropriate queue based on the carrier's own referral rules. No vendor-defined logic sits between the carrier's guidelines and what the agent does.
What distinguishes this approach from point solutions is how the agent handles document variability. When a broker submits an SOV in a format the agent has not previously processed, the agent reasons about the column structure and maps fields to the output schema. For carriers that receive submissions from hundreds of brokers using different document templates, this matters more than benchmark accuracy on a standardized test set.
The V7 Go underwriting agent displaying extracted fields from a commercial submission: coverage details and structured risk data surfaced from raw documents without manual entry.
V7 Go agents connect to policy admin systems, rating engines, and broker portals through the platform's API and MCP integrations. Extracted submission data flows into the underwriting system directly, eliminating the manual transfer step that offsets most of the efficiency gain from point extraction tools.
Carriers using the platform for insurance underwriting automation report that structured data extraction from a complex commercial submission previously requiring two to four hours of manual processing completes in under five minutes. For MGAs and program administrators, insurance document ingestion automation workflows handle submission intake from multiple broker channels simultaneously, without separate tool deployments per channel.
Where AI Tools Struggle
No current tool handles all commercial lines documents reliably. Poor scan quality (common with faxed or photographed ACORD applications from smaller brokers) reduces extraction accuracy for every tool in this category. Loss runs from older carriers sometimes use inconsistent claim numbering across pages, creating reconciliation failures that require manual resolution.
Documents with handwritten annotations present a harder problem. A broker who writes corrections over printed fields, or a risk manager who hand-marks changes on a renewal endorsement, creates an interpretation task that exceeds current AI extraction capability. Tools can flag these annotations; none interpret them reliably at production accuracy.
AI tools for commercial lines also require ongoing calibration as guidelines change. An agent configured for current referral rules needs updating when the carrier revises its property appetite after a catastrophe season. This maintenance overhead is real and should factor into vendor evaluation, not just initial implementation cost.
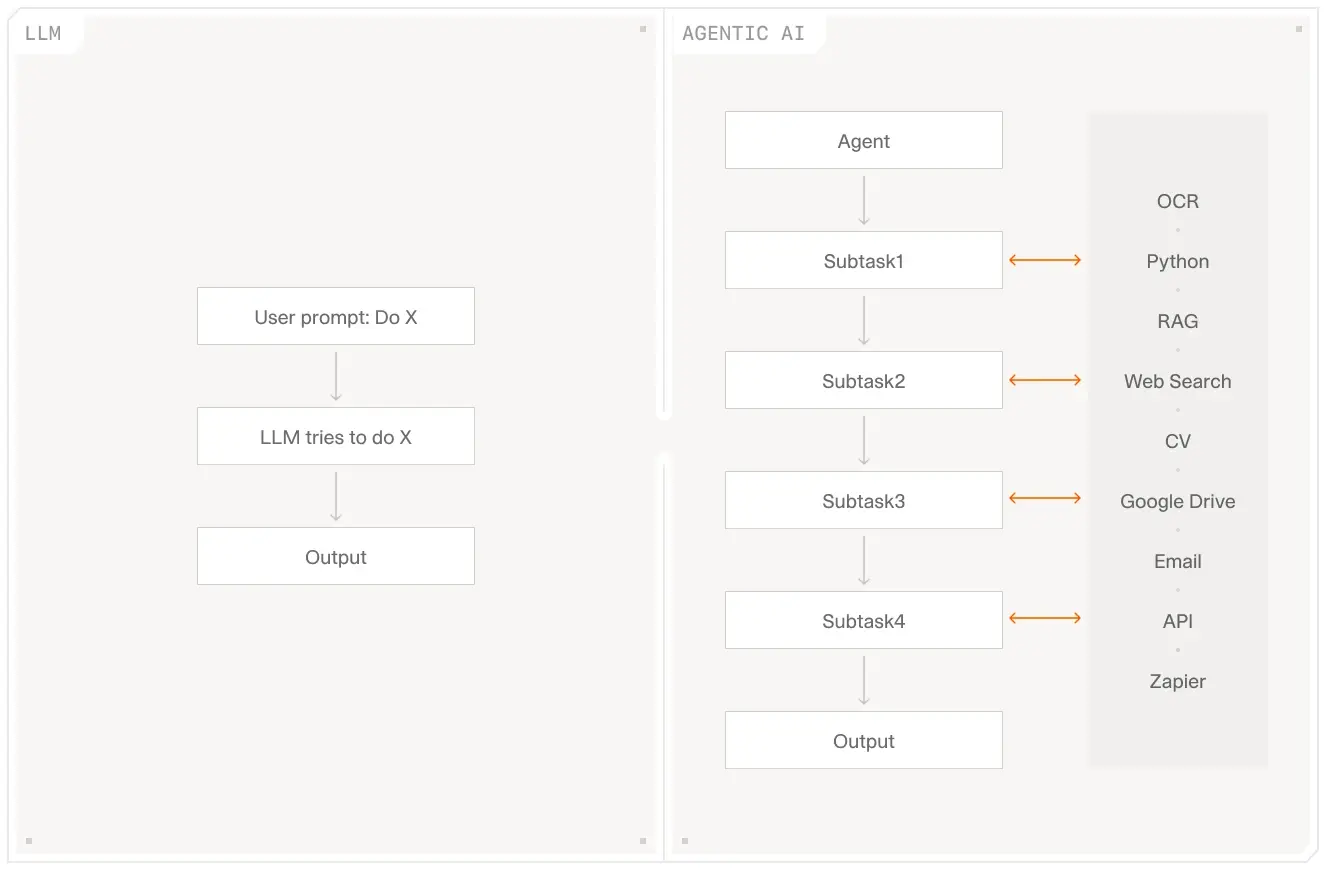
The difference between a basic LLM and an agentic architecture matters for commercial lines processing: agents can apply rules, handle multi-document submissions, and route results, not just extract text from a single document.
How to Evaluate AI Tools for Commercial Lines Underwriting
Carriers that approach AI tool selection with a specific workflow problem get better outcomes than those evaluating tools broadly. The questions worth answering before a vendor conversation: which document types create the most processing time? Which submission types are consistent enough to automate? What does STP mean for your operation (full bind without human review, or structured triage with a ten-minute underwriter decision)?
Start with the Workflow Stage, Not the Tool
A carrier whose primary bottleneck is SOV extraction for property submissions has different requirements from one trying to automate triage across a mixed commercial book. The tool that solves one problem well may not address the other. Purchasing a platform that covers both when you need one creates configuration scope you will pay for in implementation time and ongoing maintenance.
Map the submission workflow from receipt to bind or decline. Identify the three steps where the most processing time is spent, where errors most commonly occur, and where delays most directly affect the bind ratio. Those three steps determine which tool category applies and which vendor conversations are worth having.
Accuracy Requirements and Document Variability
Extraction accuracy benchmarks are vendor-published and optimistic. When evaluating tools, test on your actual document population. Specifically, include the messiest 20% of submissions you receive. A tool that achieves 98% field-level accuracy on clean ACORD PDFs may perform considerably worse on scanned applications from smaller regional brokers or older-format loss runs from carriers that have since been acquired.
For any field that feeds a rating or referral decision, the cost of an extraction error exceeds the cost of a human review step. Building structured human review for flagged fields into the workflow is not a failure of automation. It is the correct architecture for regulated underwriting decisions that require a documented audit trail.
The NAIC's guidance on AI in insurance addresses carrier obligations around AI system documentation and explainability. For carriers subject to state regulatory review, AI governance documentation is increasingly part of market conduct examination scope, not just an internal operational consideration.
Integration Requirements
AI tools that extract data but don't connect to the policy admin system create a new manual step: copying structured output into the system of record. This eliminates most of the efficiency gain the tool was purchased to deliver.
Evaluate integration through the API documentation, not the sales conversation. Key questions: can extracted data push directly to your PAS intake endpoint? What does the output data model look like, and does it map to your field schema? Who owns integration maintenance when either system updates?
For carriers that also handle claims, the same extraction architecture applies to claims documents. The claims triage agent model extends the underwriting automation approach to the claims workflow without a separate implementation project, with AI handling structured processing and adjusters taking the edge cases requiring judgment.
The Implementation Path
For carriers evaluating V7 Go for commercial lines submission processing, implementation follows three stages. First, agent configuration: the underwriting team defines the input documents, required output fields, and referral rules the agent should apply. This step does not require engineering resources. Underwriting staff configure the agent through V7 Go's interface.
Second, validation against the carrier's actual document population. Before production deployment, agents process a sample of historical submissions. Extraction accuracy is measured against known values. Fields that fall below the accuracy threshold are reviewed and the agent configuration is adjusted. This validation phase is where carriers discover whether vendor accuracy claims translate to their specific document mix.
Third, integration and production deployment. The validated agent connects to the submission intake channel and the policy admin system. Human review steps are configured for flagged submissions. The result is a workflow where the agent handles structured processing and underwriters handle edge cases, which is what underwriters were hired to do.
For a broader view of AI across the insurance value chain, the AI in the insurance industry trends guide covers the current state of automation across underwriting, claims, and distribution, including which workflow categories are seeing the fastest adoption and which remain primarily manual.
What types of commercial lines documents can AI tools process?
AI tools for commercial lines underwriting handle ACORD applications (125, 126, 130, and line-specific supplements), schedules of value in Excel and PDF format, loss run PDFs from prior carriers, supplemental questionnaires, endorsements, and certificates of insurance. More capable tools also process engineering reports, inspection summaries, and broker-generated risk narratives. Document complexity varies considerably. Standard ACORD applications follow a known layout and produce the most reliable extraction results. Schedules of value are harder because every carrier and broker uses a different column structure for the same underlying data. Loss runs present additional challenges because claim formatting differs by carrier and the data relationships across claims, policies, and policy years require semantic understanding, not just character recognition. The practical question is not whether a tool can process a document type in a demonstration, but whether it maintains acceptable accuracy on your actual submission population, including submissions that arrive as scanned faxes, photographed spreadsheets, or older-format PDFs from brokers in regional markets. Pilots run on vendor-selected samples rarely predict production performance across the full submission mix.
+
How accurate is AI extraction for schedules of value?
Extraction accuracy for schedules of value depends heavily on document quality and format consistency. For clean, digitally-produced SOVs in common Excel formats, well-trained extraction tools typically achieve field-level accuracy above 90% on standard fields: named insured, location address, construction type, year built, and total insured value. Replacement cost value fields are somewhat less reliable because carriers and brokers use different column labels for the same concept, requiring the tool to resolve that ambiguity correctly. Accuracy drops for scanned Excel-to-PDF conversions, SOVs with handwritten additions or corrections, and multi-tab workbooks where location data is split across sheets with inconsistent naming. Merged cells cause systematic extraction failures in most tools because they break the column-to-field mapping logic the extractor relies on. The practical architecture for most carriers is to automate extraction for high-confidence fields and route low-confidence fields to a human review queue. A tool that extracts 85% of SOV fields automatically with structured review for the remaining 15% delivers most of the processing time savings while maintaining accuracy on the fields that feed pricing decisions. Aiming for 100% extraction without a review step is the wrong target for commercial property lines, where an error in TIV or construction type has direct pricing consequences.
+
What is straight-through processing in commercial lines underwriting?
Straight-through processing (STP) in commercial lines underwriting means a submission moves from receipt to a quote or decline decision without manual data entry at any step. The system receives the submission documents, extracts the structured data the underwriting system needs, applies eligibility and referral rules, and either generates a quote automatically or routes the submission to the appropriate underwriter with a complete structured summary. Full STP (where the system quotes or declines without human review) is currently achievable only for the most standardized commercial accounts: small BOP submissions with clean loss histories, simple mono-line accounts within defined eligibility parameters, and clean renewals with no material changes from the expiring policy. For larger or more complex accounts, partial STP is the realistic near-term goal. The economic case for partial STP is strong even without full automation. Reducing the time an underwriter spends per submission from two hours to twenty minutes multiplies their effective account capacity without adding headcount. For carriers with growing submission volume and flat team sizes, this is the primary driver of AI tool investment in commercial lines: not full automation, but a significant reduction in the manual burden per account.
+
How does V7 Go differ from point IDP solutions for insurance document extraction?
Point IDP solutions are trained on specific document formats and perform well on the formats they were trained for. When a new broker submits a schedule of value in a format the tool has not seen, the typical result is a failed extraction or a low-confidence output that routes to manual review. Retraining requires labeled data from the new format and a model update cycle that can take weeks to complete. V7 Go takes a different approach. Agents are configured to describe what they need from a document (which fields, what data types, how to handle ambiguous cases) and the underlying model reasons about the document structure to produce that output, including for formats it has not explicitly been trained on. For carriers receiving submissions from hundreds of brokers with different document conventions, this reduces the ongoing maintenance burden of adding new templates to the extraction system. The other practical difference is integration depth. Point IDP tools typically produce structured output that still requires manual transfer into the policy admin system, which offsets much of the processing efficiency gained. V7 Go agents connect to policy admin systems and rating engines through the platform's API and MCP integrations, so extracted data flows directly into the underwriting system. For carriers that need extraction plus integration in a single implementation, this reduces overall project scope.
+
What should carriers verify when integrating AI extraction tools with a policy admin system?
The NAIC's guidance on AI in insurance focuses on three areas directly relevant to commercial lines underwriting deployments: explainability, accountability, and governance. Explainability means carriers should be able to describe how decisions made with AI tools are reached, specifically how the tool extracts data, applies rules, and produces referral or eligibility determinations. Carriers using AI tools that function as black boxes face documentation challenges during regulatory examination. This is a vendor selection criterion, not just an internal design preference. Accountability means the carrier, not the vendor, is responsible for underwriting decisions made with AI assistance. This affects how carriers structure human review steps in AI workflows and what they include in vendor contracts. Consequential decisions (binding, declining, pricing departures) should have documented human review as part of the workflow design. Governance means maintaining a defined process for monitoring AI tool performance over time, updating configurations when guidelines change, and retaining records of how AI systems are used in underwriting decisions. For carriers subject to market conduct examinations, AI governance documentation is increasingly part of the examination scope. Vendors should be evaluated on how their tools are designed to support this requirement, not just on extraction accuracy.
+
What do NAIC guidelines mean for carriers deploying AI in commercial underwriting?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

