8 min read
—


Investment teams spend two to three hours assembling market context manually each morning. Here is how multi-agent AI pipelines handle that step, and what changes when they do.

The morning routine at most investment firms follows a familiar sequence. Someone pulls up Bloomberg, checks overnight moves from Asian sessions, scans earnings releases from portfolio company competitors, reviews the macro calendar for the day ahead. Meanwhile, another analyst is assembling something similar in a different tab, compiling notes that will not fully align with the first set until the 8am call. By the time the team convenes, two to three hours have passed — hours spent not on judgment, but on assembly.
The problem is not the volume of information. Investment teams have always operated in information-dense environments. The issue is that the information arrives across sources that do not speak to each other, and the synthesis step requires more than speed. Mapping a macro signal to a specific portfolio holding, flagging a regulatory filing that touches a tracked acquisition target, noticing that a sector-wide earnings trend has implications for a deal in active diligence: each of these requires context the raw data does not carry. That context has to be added by someone who knows the portfolio.
According to Deloitte's 2025 M&A GenAI Survey, 86 percent of PE and corporate leaders have integrated generative AI into deal workflows. The outcomes vary because the approach varies. Teams using chat-based AI for market research get generic summaries. Teams that have built automated briefing pipelines get something different: a structured morning output calibrated to their specific portfolio, assembled before the first meeting of the day.
This piece covers how those pipelines work, what they pull from, and what investment teams using them report in practice.

AI for document processing
Get your morning market briefing built by AI agents
Get started today
The Hidden Cost of Manual Market Monitoring
Every investment team has some version of the morning briefing. The problem is that building it manually is not a single step: it is a sequence of ten to fifteen steps repeated each day, across sources that require different access credentials, different reading approaches, and different interpretive lenses. A treasury yield move means something different if a portfolio company carries floating-rate debt. A competitor's earnings miss matters differently depending on whether the fund has a live deal in that sector. Context is not a feature of the raw data; it has to be added by someone who knows the portfolio.
Senior associates and VPs at PE and asset management firms consistently report spending the first two to three hours of the day in a mode closer to document handling than to analysis. The information gets assembled, but the process is not reproducible in a systematic way. Different analysts weight sources differently. Coverage gaps appear. By the time the briefing reaches the IC, its provenance is informal and its completeness is assumed rather than verified.
That is the problem multi-agent AI is designed to address — not by removing the analyst from the loop, but by handling the assembly chain so the analyst's time starts at interpretation rather than collection.
Five Components of a Structured AI Briefing
A well-constructed automated briefing for an investment team covers five distinct areas, each requiring different data inputs and different analytical framing.
Macro signals. Treasury yield movements, Fed rate probability shifts from CME FedWatch, overnight inflation data from CPI and PPI releases, and currency moves for funds with cross-border exposure. These set the context for everything else in the briefing. An agent monitoring the 10-year treasury yield series can flag a material threshold move before the trading day opens.
Sector watch. Earnings results, analyst rating changes, and news flow for the sectors in which the fund operates. For a firm running a concentrated thesis in healthcare IT and industrial SaaS, the relevant sector signals are narrow but specific. An automated system tracks these continuously rather than relying on a weekly digest that may miss intra-week developments.
Portfolio company signals. Earnings, management changes, competitor announcements, and news for specific portfolio companies. Knowing that a sector had a good quarter is different from knowing that one of the fund's companies is seeing margin compression while its closest competitor outperformed on the same metrics.
Deal pipeline intelligence. Public filings and news flow for tracked acquisition targets. Investor presentations, proxy filings, 8-K disclosures from SEC EDGAR: events that indicate a target company's strategic direction or financial condition, often ahead of any formal process.
Regulatory and filing alerts. 8-Ks, SEC registration statements, CFTC notices, and other filings that may affect portfolio companies or deal targets. In a compressed diligence timeline, a material event disclosure that surfaces late can change the entire picture.
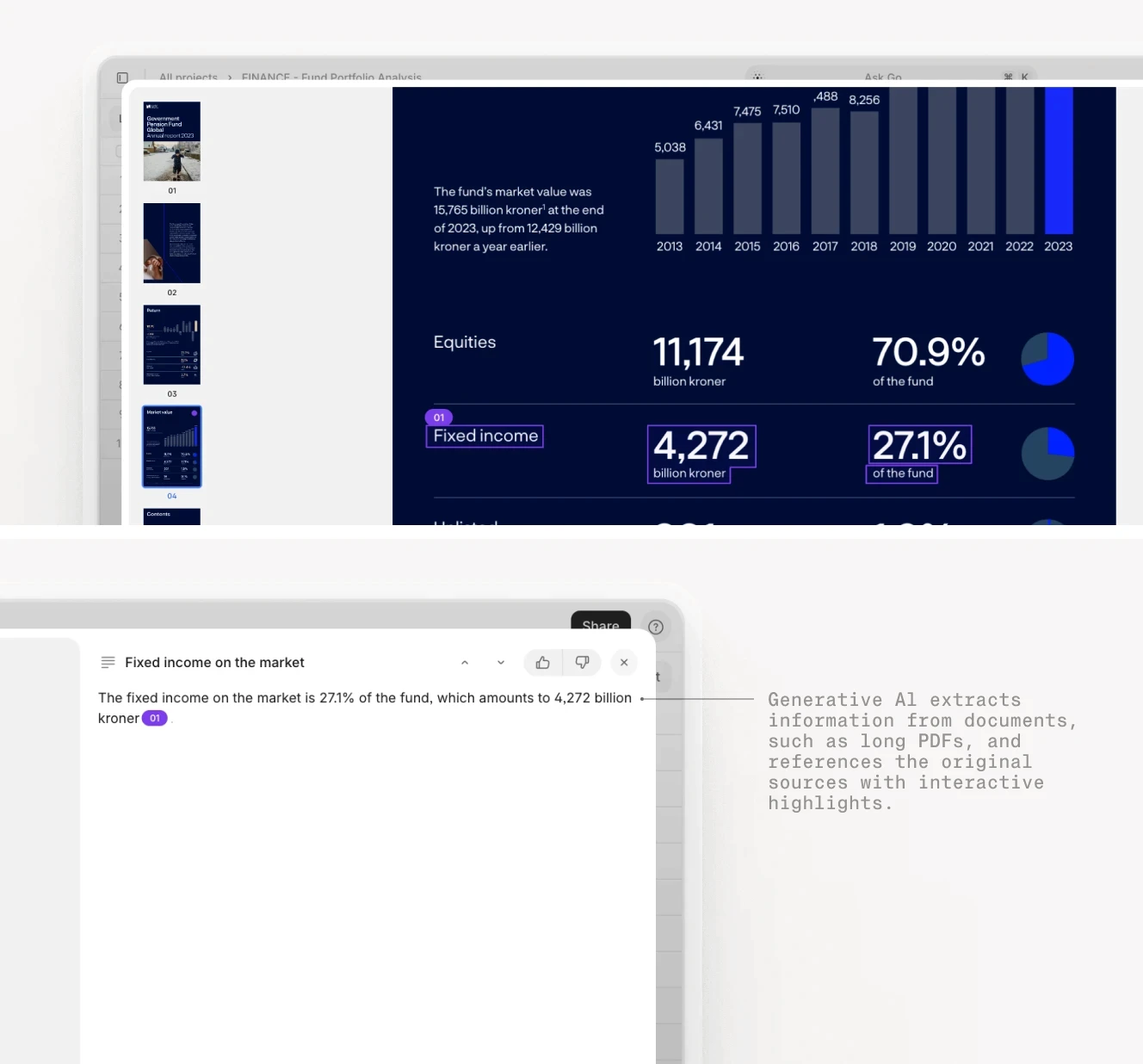
What the Agents Actually Pull From
A reliable automated briefing draws from authoritative, structured sources rather than general web scraping. The source set determines the quality of the output.
For macro data: The Federal Reserve Economic Data system maintained by the St. Louis Fed provides programmatic access to thousands of economic time series, including treasury yields, inflation expectations, and employment indicators. CME FedWatch provides real-time Fed rate probability estimates derived from futures pricing. These are the sources that professional economists cite; they are also the sources an automated Monitor agent can watch continuously.
For regulatory filings: The SEC's EDGAR full-text search system indexes 8-K filings, 10-K and 10-Q submissions, proxy statements, and registration documents. An agent monitoring specific company tickers can retrieve new filings within hours of submission, before they appear in any curated digest.
For market data and sector news: Structured feeds from financial data providers, earnings transcripts, and targeted news sources for tracked companies. The key design principle is specificity: the system should cover the fund's actual investment universe, not the market at large.
For proprietary context: The fund's own documents — investment theses, portfolio company reports, CRM data, prior diligence notes — provide the interpretive layer that makes macro and market signals meaningful. This is where a firm's internal knowledge base becomes part of the briefing infrastructure, and where a generic AI tool cannot substitute for a purpose-built system.
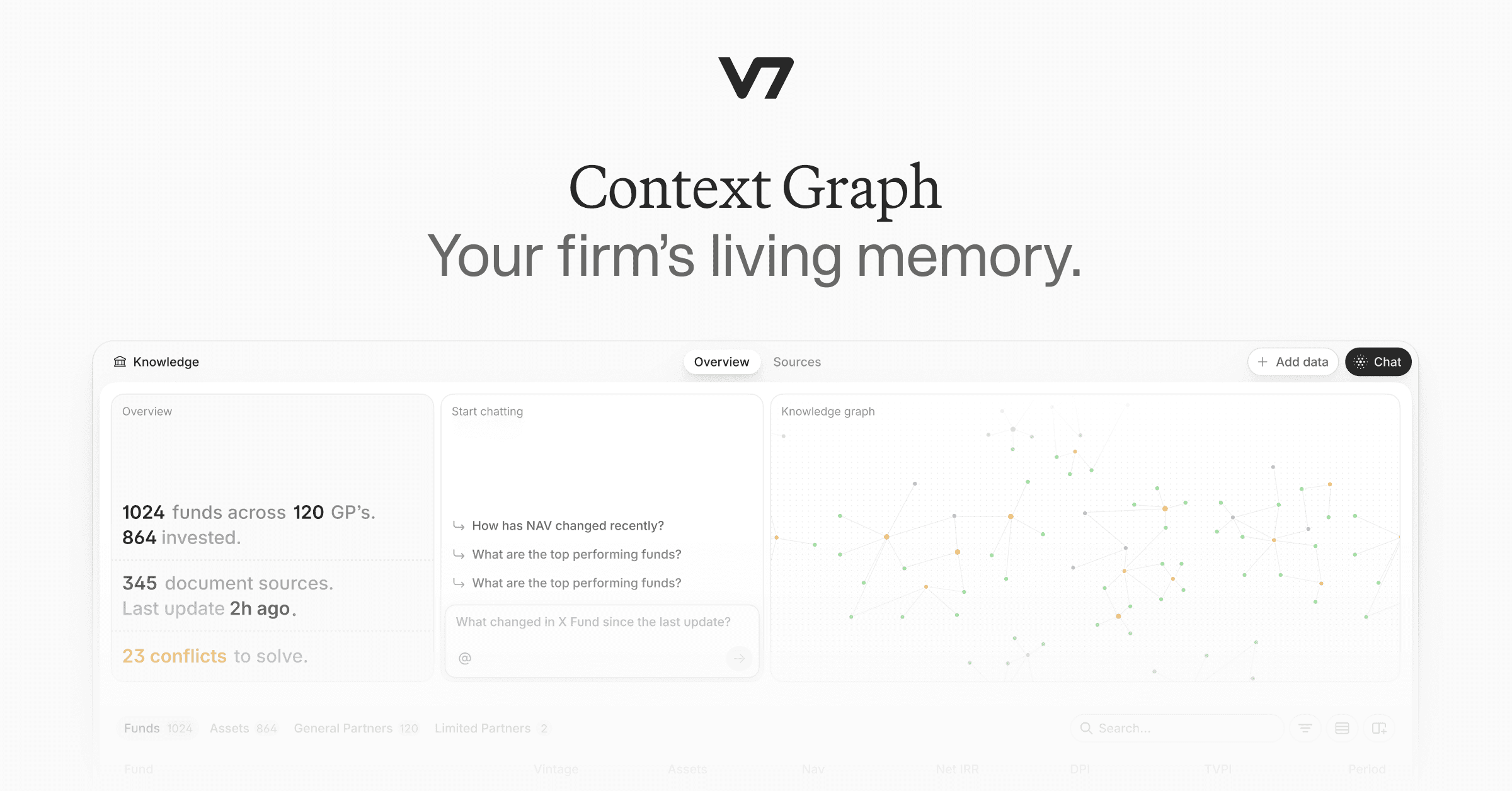











How Multi-Agent Systems Build the Briefing
A single AI model prompted to summarize today's market conditions will produce a generic output. Building a briefing that is portfolio-specific and source-traceable requires a different architecture: multiple specialized agents, each with a defined scope, running in parallel or in sequence.
The architecture typically involves four agent types working in coordination.
A Monitor agent watches designated sources continuously. It does not summarize; it detects. When the 10-year yield crosses a configured threshold, when a tracked company files an 8-K, when an overnight macro release falls outside expected ranges, the Monitor agent triggers downstream processing. It is the event-detection layer of the pipeline.
An Extractor agent processes the flagged content, pulling specific data points from raw documents. For an earnings release, it extracts revenue, EBITDA, guidance, and management commentary on forward outlook. For an 8-K filing, it identifies the material event type and the affected entities. For a macro release, it extracts the key figure and its deviation from consensus estimates.
A Relevance agent scores each extracted finding against the fund's portfolio and active pipeline. A sector-wide earnings trend is relevant to the fund's thesis at one level; a direct competitor's margin compression affecting a portfolio company is relevant at another. This scoring step is what transforms a market summary into a portfolio briefing.
An Editor agent assembles the scored findings into the morning briefing format: structured sections, source citations, and flagged items requiring attention before the day's first meeting. The output is not a wall of text but a navigable document with clear signal hierarchy.
From Briefing to Action
The output of an automated briefing is not just informational. Teams using these pipelines report three categories of downstream value.
The first is IC-ready context. When a macro signal or portfolio company development is relevant to an active deal, the briefing pre-populates context into a memo template. The analyst still writes the memo; the briefing ensures they are not starting from scratch or from notes assembled under time pressure in the thirty minutes before the call.
The second is pipeline maintenance. Briefing findings that relate to tracked companies can be logged automatically to the firm's CRM or deal tracking system. This keeps the pipeline current without requiring manual updates after each morning session. Teams using the Portfolio Monitoring workflow report that pipeline data quality improves when the update step is part of the automated process rather than a manual follow-up.
The third is source traceability. Every finding in an AI-generated briefing should link to its source: the specific EDGAR filing, the specific FRED data series, the specific earnings transcript sentence. For regulated entities, this is a compliance requirement. For any team taking the output into an IC meeting, it is how the briefing maintains credibility. V7 Go's document processing produces citations that open to the exact sentence or data point in the source document, not a reference to the general file.
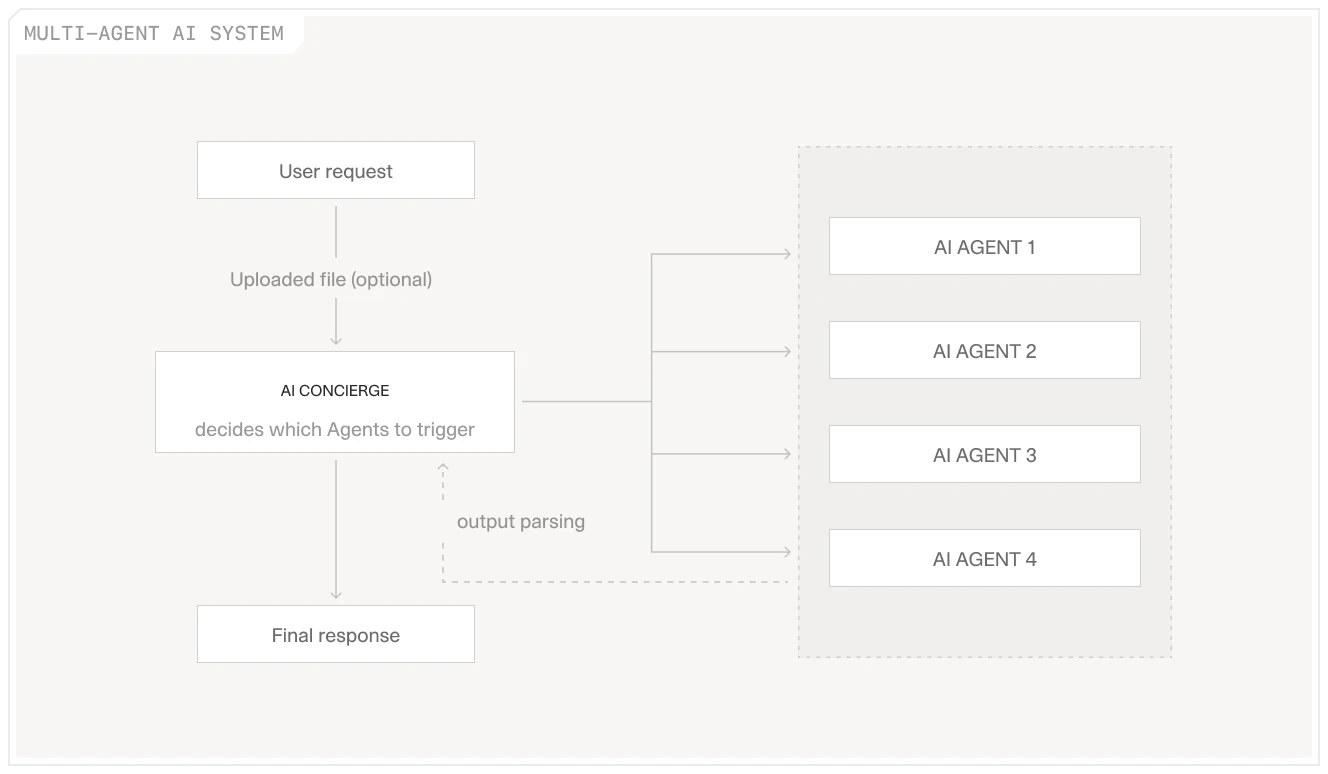
What Investment Teams Build with V7 Go
V7 Go provides the workflow layer for investment teams building production-grade automated briefings. The platform's agent-based architecture supports the multi-step pipeline described above, with Monitor, Extractor, Relevance, and Editor agents configured to the fund's specific data sources and portfolio universe.
The Market Intelligence Agent and AI Investment Analysis Agent provide established starting templates for teams building on common finance patterns. The Daily Brief use case covers the standard pattern: a structured daily output assembled before markets open, with configurable sections and source connections.
What distinguishes a production briefing system from a one-off AI query is the Context Graph. Each morning's briefing draws on the firm's accumulated knowledge base: prior investment theses, portfolio company histories, sector views built over years of deal activity. The system becomes more specific to the firm as the document corpus grows. Institutional context that previously existed only in specific analysts' heads becomes part of the infrastructure that generates the briefing each morning, and remains there when those analysts move on. Most AI systems know a great deal about the world and nothing about your firm. The Context Graph addresses the second part.

What is an AI morning briefing for investment teams?
An AI morning briefing is a structured daily summary of market signals, portfolio company developments, regulatory filings, and sector news, assembled automatically by a multi-agent pipeline before the trading day begins. Unlike a generic market digest, it is calibrated to the fund's specific holdings, active pipeline, and investment thesis. Each finding links to its source, whether a FRED data series, an SEC filing, or an internal investment thesis document, so the output can be verified and brought into IC meetings without additional research. The briefing arrives in a consistent format, with flagged items ranked by relevance to the fund's current positions. Teams receive the same analytical coverage every morning regardless of who is in the office, which matters during analyst transitions, busy deal periods, or when senior partners need to stay current across multiple active processes simultaneously.
+
How is this different from using a general-purpose AI chatbot for market summaries?
A general-purpose chatbot produces market summaries based on training data or a single prompt against whatever context the user provides. It cannot connect to live data sources, score findings against a specific portfolio, or trace its output to a verifiable source document. An automated briefing pipeline uses multiple specialised agents, each responsible for one part of the information chain: one pulls treasury yields and Fed rate probabilities from CME FedWatch, another monitors SEC EDGAR for 8-Ks affecting tracked companies, a third scores all findings against the fund's portfolio and thesis. The outputs of those agents are then assembled into a structured briefing, not a conversational summary. The difference matters in practice: a chatbot cannot tell you that a portfolio company filed a material event disclosure this morning. A purpose-built pipeline can, and it logs the finding to the deal record automatically.
+
What data sources does an AI market briefing pull from?
Production briefing systems draw from several source categories. Structured financial data includes treasury yields, Fed rate probabilities via CME FedWatch, equity index moves, and credit spreads. Regulatory monitoring covers SEC EDGAR for 8-Ks, 10-Ks, proxy statements, and registration filings that may affect portfolio companies or deal targets. Macro context comes from sources such as FRED, which publishes GDP, CPI, employment, and industrial production series on a known release schedule. Earnings data includes both the structured releases and, where available, transcript text for companies the fund monitors. Proprietary documents from the firm itself, including investment theses, portfolio company reports, and CRM records, provide the interpretive layer that makes external signals meaningful within the fund's specific context. The specific source set is configured per fund and can be extended as monitoring needs change.
+
How long does it take to set up an automated briefing pipeline?
Teams using V7 Go report that an initial working briefing pipeline takes days to configure, not months to build. The platform provides pre-built agent templates for common finance workflows, so teams start from documented patterns rather than building data infrastructure from scratch. Initial configuration covers three areas: selecting and connecting the external data sources the pipeline will monitor, defining the portfolio companies, sectors, and thesis terms the Relevance agent scores against, and setting the output format and delivery method. The most time-intensive step is usually populating the portfolio context so the scoring layer reflects the fund's actual investment universe. After go-live, the configuration is updated as the portfolio changes. Teams typically refine scoring thresholds and source selection over the first two to four weeks based on which signals prove most useful in practice.
+
Can the briefing be customized for a specific fund's portfolio and thesis?
An automated briefing feeds directly into downstream workflow steps rather than sitting as a standalone output. In V7 Go, the same pipeline that produces the morning briefing can pre-populate context into IC memo templates, log flagged regulatory events to the relevant deal record, and update the CRM with news affecting tracked companies. When a portfolio company files an 8-K, the briefing flags it and the record is updated without manual entry. When a macro signal crosses a threshold, it can trigger a follow-on agent run that pulls the most recent portfolio company financials for comparison. The daily-brief use case at v7labs.com/use-cases/daily-brief documents how this connection to the broader workflow is configured. The result is that the briefing is not just informational. It is the first step in a sequence that keeps deal and portfolio data current through the trading day.
+
How does the briefing connect to the rest of the investment workflow?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

