21 min read
—



Every quarter, somewhere in the back office of a PE firm, an analyst opens a spreadsheet and starts copying figures from LP statements into a master table. NAV here. IRR there. MOIC from this PDF, distribution amount from that one. The job takes three days. Sometimes four, if the fund administrator is running late with their quarterly reports.
This is portfolio reconciliation. Or rather, this is the part of portfolio reconciliation that rarely makes it into vendor documentation. The industry conversation tends to focus on trade breaks and position matching between prime brokers and order management systems. Those problems are largely solved. What they do not address is the document layer: verifying that the figures in your LP quarterly statements match the fund administrator's NAV report, that the capital call notice references the correct capital commitment from each subscriber's election, that the IRR in the board pack and the IRR in the investor letter are the same number. That verification still lives in spreadsheets, and the spreadsheets carry real risk.
A KPMG survey found that over 30% of asset management firms still rely on spreadsheets for critical portfolio management functions. For document-level reconciliation specifically, that figure is almost certainly higher. The problem extends beyond operations. EMIR, Dodd-Frank, and SEC recordkeeping rules all require documented reconciliation trails. A spreadsheet with colour-coded cells is not a trail.
This guide covers the complete picture of portfolio reconciliation for PE and private credit firms: what it actually includes, where the process breaks down at scale, and how AI agents have changed the economics of the document layer. For context on how this connects to the investor reporting cycle, the guide to AI in investor reporting for PE firms covers the communication workflows that depend on reconciliation accuracy.
In this article:
What portfolio reconciliation actually covers, including the two-layer model most practitioners are not explicitly managing
The four types of reconciliation PE firms run every quarter, and which carries the highest error risk
Why the process breaks down at scale and what the regulatory exposure looks like
How AI agents close the document reconciliation gap, with specific workflow examples and output descriptions
Five criteria for evaluating reconciliation tools and five properties of a defensible reconciliation process

AI for document processing
Extract portfolio data from any document automatically
Get started today
What portfolio reconciliation actually covers
Most practitioners working in fund operations have a definition of portfolio reconciliation that centres on position matching: verifying that the fund's recorded holdings match the records held by custodians, prime brokers, and administrators. That definition is correct. It is also incomplete in a way that costs PE back-offices significant time every quarter.
Reconciliation in investment management operates across two layers, and most PE firms treat them as one. The first is the data layer: matching structured position files, trade records, and cash movements between internal systems and external counterparties. The second is the document layer: verifying that the figures in investor-facing PDFs, capital call notices, and fund administrator reports are consistent with each other and with the book of record. Both layers matter. The operational burden falls almost entirely on the second one.
A virtual data room environment showing the document library, deal overview, and AI-generated financial summary that PE back-office teams work with every quarter. Document reconciliation spans every layer of this environment.
The data layer: systems-to-systems matching
The data layer covers four reconciliation types. Position reconciliation confirms quantity and market value of each security against the custodian's or prime broker's records. Cash reconciliation verifies all settlement movements, dividends, interest payments, and fees against bank statements and administrator records. NAV reconciliation checks the fund's internally calculated net asset value against the administrator's figure. Derivatives reconciliation, where relevant, verifies outstanding OTC positions against all counterparty records.
This layer has been largely automated for firms with meaningful AUM. Platforms like Advent Geneva, Allvue, and SS&C provide daily position and cash reconciliation as standard capability. Matching rules are configurable by asset class, tolerance thresholds are defined per security type, and exception management workflows route breaks to the right analyst. For liquid strategies running daily NAV calculations, the data layer produces a morning exception report that the team works through before the market open. Hard to configure initially. Near-automatic once set up. Documented exception history available for audit.
The document layer: the harder problem
The document layer is different in almost every respect. Instead of structured data files arriving via sFTP at consistent times, the document layer consists of PDFs, Word files, and Excel attachments arriving on varying schedules, in different formats, from multiple parties with different templates. An LP quarterly letter from one administrator might present IRR, MOIC, and DPI in a summary table on page three. A different administrator's letter for the same fund might embed the same figures in a narrative paragraph on page eight.
For a mid-size PE firm managing five funds with 200 to 400 LPs in aggregate, the document layer generates the following quarterly reconciliation tasks: verify the IRR, MOIC, and DPI figures in each fund's LP letter against the administrator's NAV report; confirm capital call notices reference the correct capital commitment from each LP's subscription agreement; check distribution notices against the waterfall calculation in the LPA; verify co-investment vehicle figures against the parent fund's performance data; confirm board-level performance figures match the investor letter for the same period. None of these tasks involves a data feed or matching engine. They require reading documents, locating figures, and confirming consistency.
Done manually at scale, this process takes 15 to 20 hours per quarter for a 300-LP fund. Done under time pressure, it produces errors. One transposed NAV figure distributed across 40 LP statements generates 40 correction letters, 40 explanatory conversations, and a lasting question in at least some LPs' minds about the quality of the operations team behind the fund. That is not a data layer problem. It is a document layer problem, and it requires a different solution.
The four types of fund reconciliation
PE and private credit firms typically run four categories of reconciliation per quarter, each with different data sources, different frequency requirements, and different downstream consequences if breaks go undetected.
Position reconciliation verifies quantity and market value of each security or investment position against the records of the custodian or prime broker. For PE firms with illiquid holdings, this runs at the valuation date rather than daily. Breaks at this layer typically surface quickly because custodians flag outstanding discrepancies as part of their standard reporting cycle.
Cash reconciliation verifies all cash movements: capital contributions, distributions, management fees, and fund expenses against bank statements and administrator records. This should run at minimum weekly. Daily for funds with active capital call or distribution activity. Cash breaks left undetected for more than a few days can create downstream errors in NAV calculations that propagate into LP statements.
NAV reconciliation checks the fund's net asset value calculation, typically performed by the fund administrator, against the GP's shadow NAV. Differences commonly arise from pricing source variations, expense allocation timing, or different methodology for carried interest accrual. These discrepancies require resolution before LP statements distribute. NAV reconciliation is where the data layer and the document layer first intersect: the NAV figure lives in the administrator's report (a document) and must match the figure in the GP's own system (structured data).
Document reconciliation verifies the figures in investor-facing communications: LP quarterly letters, capital call notices, distribution notices, and annual reports against the source data from which those figures derive. This is the layer that separates audit-ready reconciliation processes from processes that produce accurate outputs most of the time. Firms that run the first three types and skip the fourth have an audit trail for their internal systems and no trail for their LP communications.
Why portfolio reconciliation breaks down at scale
The data heterogeneity problem is real at both layers but manifests differently. On the data side, the issue is identifier mismatches, rounding convention differences, and timing differences between counterparties. An OMS might carry a security under its ISIN while the prime broker uses a proprietary internal code. One system might mark positions at the 4 p.m. close while another uses end-of-day adjusted prices. These mismatches are systematic and can be resolved with matching rules once catalogued.
On the document side, heterogeneity has no systematic resolution. Administrator A produces a ten-page quarterly report with figures presented in one order. Administrator B produces a twenty-page report with the same figures in a different order, with different labels, and different rounding conventions. IRR to two decimal places versus one decimal place will always produce a reconciliation discrepancy when the true figure is, for example, 17.35%. Your fund counsel produces capital call notices in a format unchanged for years. Co-investment vehicles use a third format entirely. No configuration resolves this without a document-aware system.
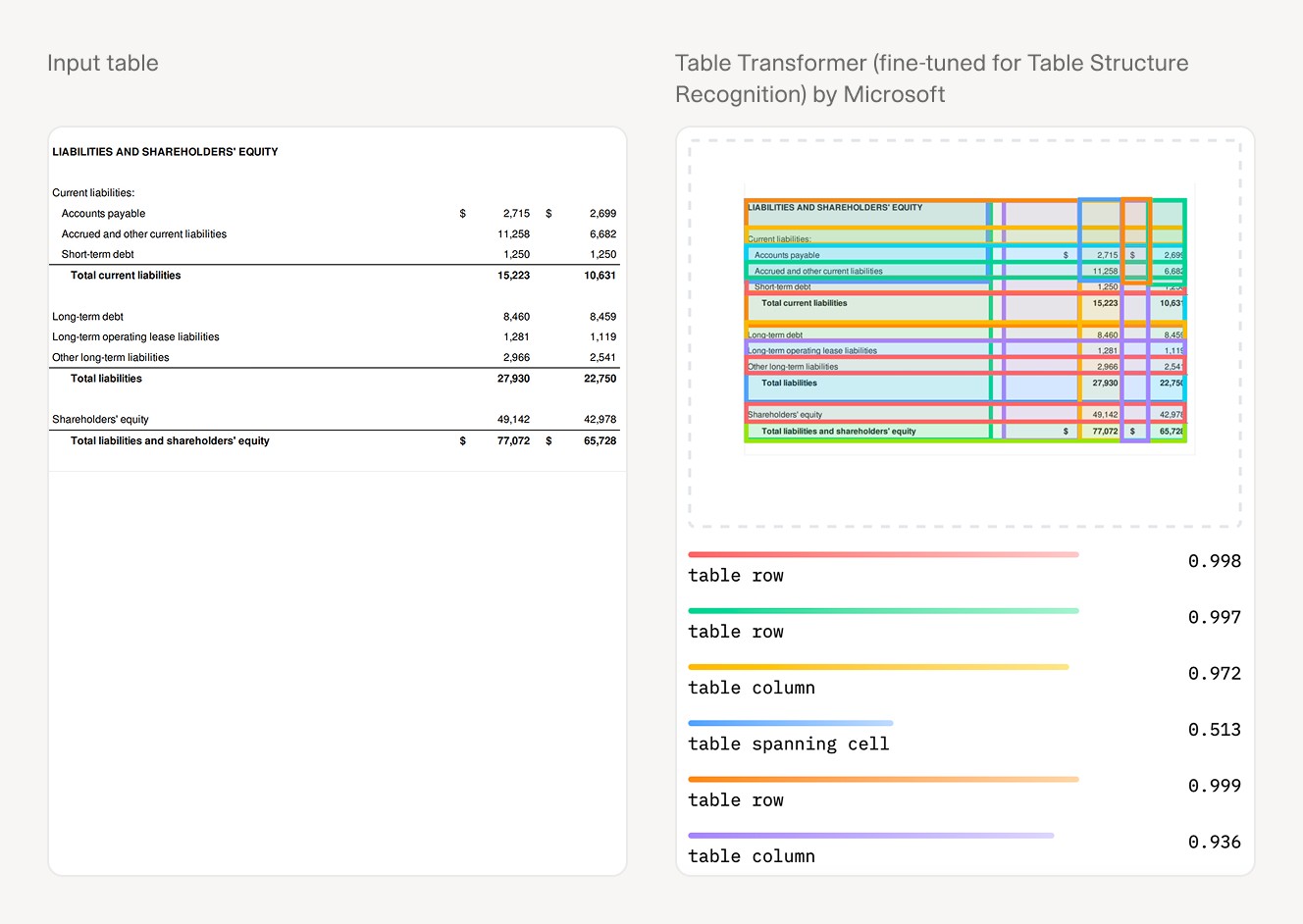
Manual document reconciliation requires locating each figure by reading the document. AI can identify, extract, and compare the same information across multiple documents simultaneously, with each figure linked to its source page.
This is why manual document reconciliation does not scale. It is not that processing a single document takes long. An experienced analyst can work through one administrator report in 20 minutes. The problem is that 60 documents at 20 minutes each is 20 hours, and those hours cluster at the worst possible point in the quarter: the two weeks before LP letters distribute, when the analytics team is simultaneously preparing board materials, performance attribution, and the next quarter's projections.
Then there is the regulatory exposure. Dodd-Frank's portfolio reconciliation requirements, codified at 17 CFR 23.502 under CFTC rules, require swap counterparties to confirm outstanding positions and resolve disputes at regular intervals. EMIR carries equivalent requirements for European counterparties. SEC recordkeeping rules apply broadly to registered investment advisers and require that reconciliation processes be documented and traceable. A spreadsheet with manually entered figures satisfies none of these documentation requirements. It shows a result. It does not show a process.
The portfolio reconciliation workflow, step by step
Whether reconciling position data or fund documents, the underlying workflow follows the same sequence. Automation changes which steps require human judgment, not the sequence itself. Mapping your current process against this sequence clarifies where the cost accumulates and where technology delivers value.

The manual financial analysis workflow: each step carries time costs, with data collection and figure extraction consuming the largest share of analyst hours in document-heavy processes.
Step 1: Data collection. On the data layer, this means pulling position files from custodian portals, retrieving administrator NAV files, and importing cash statements. With modern infrastructure, most of this arrives via automated feeds or sFTP connections. On the document layer, this means downloading PDFs from administrator portals, retrieving LP letters from the prior quarter's distribution, and pulling capital call documents from the data room. Document retrieval is often the slowest step on the document side because administrators do not use standardised delivery methods, and fund documents arrive through email, shared drives, and portal downloads with no consistent timing.
Step 2: Normalization. Data layer normalization maps each counterparty's identifier scheme to a common internal identifier, converts currencies, and aligns decimal precision. Document layer normalization means locating the relevant figure within each document. An analyst who reads a 20-page administrator report and identifies the correct IRR on page 11 has completed normalization. This step is automated on the data layer and entirely manual on the document layer.
Steps 3 and 4: Matching and break identification. On the data layer, matching software compares position quantities and values against defined tolerance thresholds, and surfaces anything outside tolerance as a break. On the document layer, matching is comparison: does the IRR in the LP letter match the IRR in the administrator's performance report? If they differ by 20 basis points, is that within tolerance or a reportable discrepancy? These comparisons cannot occur until step 2 is complete, and on the document layer, step 2 is entirely manual without AI.
Step 5: Investigation and resolution. Once a break is identified, root cause work begins. Data layer breaks typically fall into well-understood categories: pricing source differences, settlement timing mismatches, corporate action processing errors. Document layer breaks are harder to categorise: an IRR discrepancy might reflect a different performance period assumption, a different cash flow timing convention, or a genuine calculation error. Resolution requires direct contact with the administrator or fund counsel, and the resolution needs documentation whether or not the original figure changes.
Step 6: Audit trail and reporting. A complete reconciliation record documents what was reconciled, what was found, how discrepancies were resolved, and who approved the resolution. For LP-facing documents, the reconciliation record is evidence that the figures in the letter are correct. For regulatory purposes, it is evidence that the required process was performed. An audit trail that lives in a shared spreadsheet, with no version history, no timestamp, and no sign-off mechanism, satisfies none of these purposes reliably. The broader picture of how AI is reshaping fund accounting and financial reporting workflows is worth reading alongside this workflow analysis.











How AI closes the document reconciliation gap
The conventional reconciliation platforms handle the data layer well. They do not handle the document layer. Advent, Allvue, and SS&C process structured data feeds from custodians and prime brokers. None of them open a PDF capital call notice, identify the capital commitment figure, and compare it against the subscriber's election in the subscription agreement. That gap is where AI document agents operate.
The technical capability is not complicated to describe. An AI agent reads a document in any format, on any template, and extracts specified fields with a reference to the exact location of each figure in the source document. Run the same agent across 40 LP letters, and the output is a structured table: fund name, reporting period, IRR, MOIC, DPI, distribution amount, and source page reference for each. Cross-reference that table against the administrator's confirmed figures, and discrepancies surface immediately.
According to Grant Thornton's Digital Transformation Survey for Asset Management, nearly three-quarters of firms in the sector are already using AI in day-to-day operations. The question for most back-office teams is no longer whether to adopt. It is which workflows to prioritise. Document reconciliation is a strong candidate for early adoption: the current process is entirely manual, the benefit from automation is immediate and measurable, and the risk of errors in LP communications is material enough that the business case writes itself.
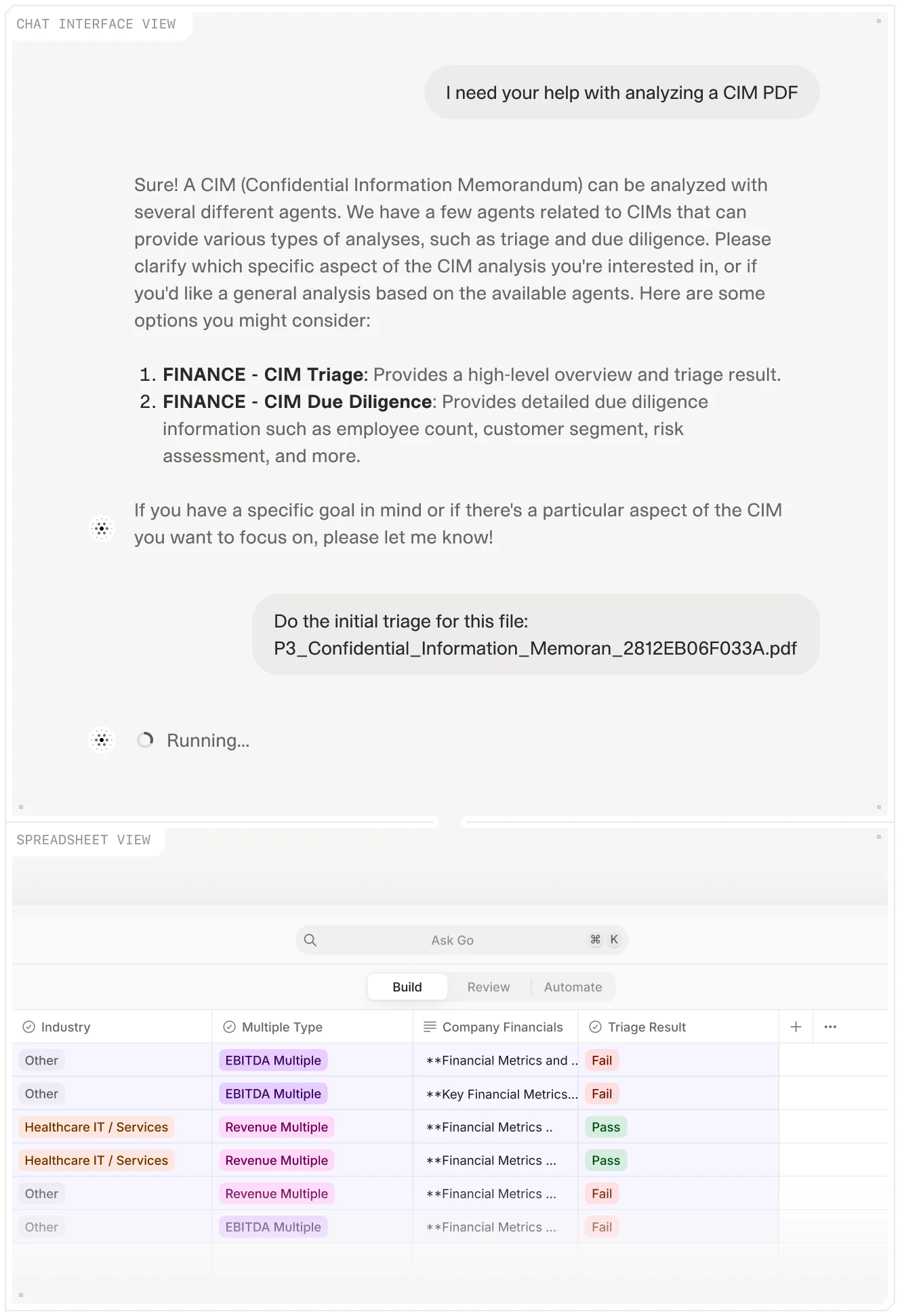
An AI platform processing a financial document through specialized agents, with extracted results consolidated in a structured spreadsheet view. Defining the fields once and running the agents across the full document set is what makes document-layer reconciliation scalable.
What the output looks like in practice
Consider a mid-market buyout fund running its Q4 reconciliation. The fund administrator has distributed quarterly reports to 85 LPs. Each report runs to 15 to 20 pages. The reports contain IRR, MOIC, DPI, RVPI, and total value per fund, alongside capital account statements showing each LP's commitment, contributions, and distributions to date.
Without automation, an analyst opens each PDF, locates the figures, and enters them into the master reconciliation table. The process takes approximately 90 seconds per figure, and there are six key figures per LP report. At 85 reports, that is roughly 765 individual figure extractions, or about 19 hours of work. And that is before any investigation of the breaks identified.
With a document AI agent configured to this process, the workflow changes. The agent ingests all 85 PDFs, extracts the six key figures per document with page citations, and produces a structured comparison table against the administrator's reference figures. The extraction completes in under 15 minutes. The analyst reviews the discrepancy report. Six breaks surface: three rounding differences within tolerance, two capital account figures with a timing difference from the previous quarter's distribution, and one genuine IRR discrepancy requiring investigation. The analyst spends two hours investigating and resolving. Total analyst time: two and a half hours, down from nineteen.
That is the practical output. Not a black-box result the analyst must trust, but a cited table they can verify, with every figure traceable to the specific page in the source document.
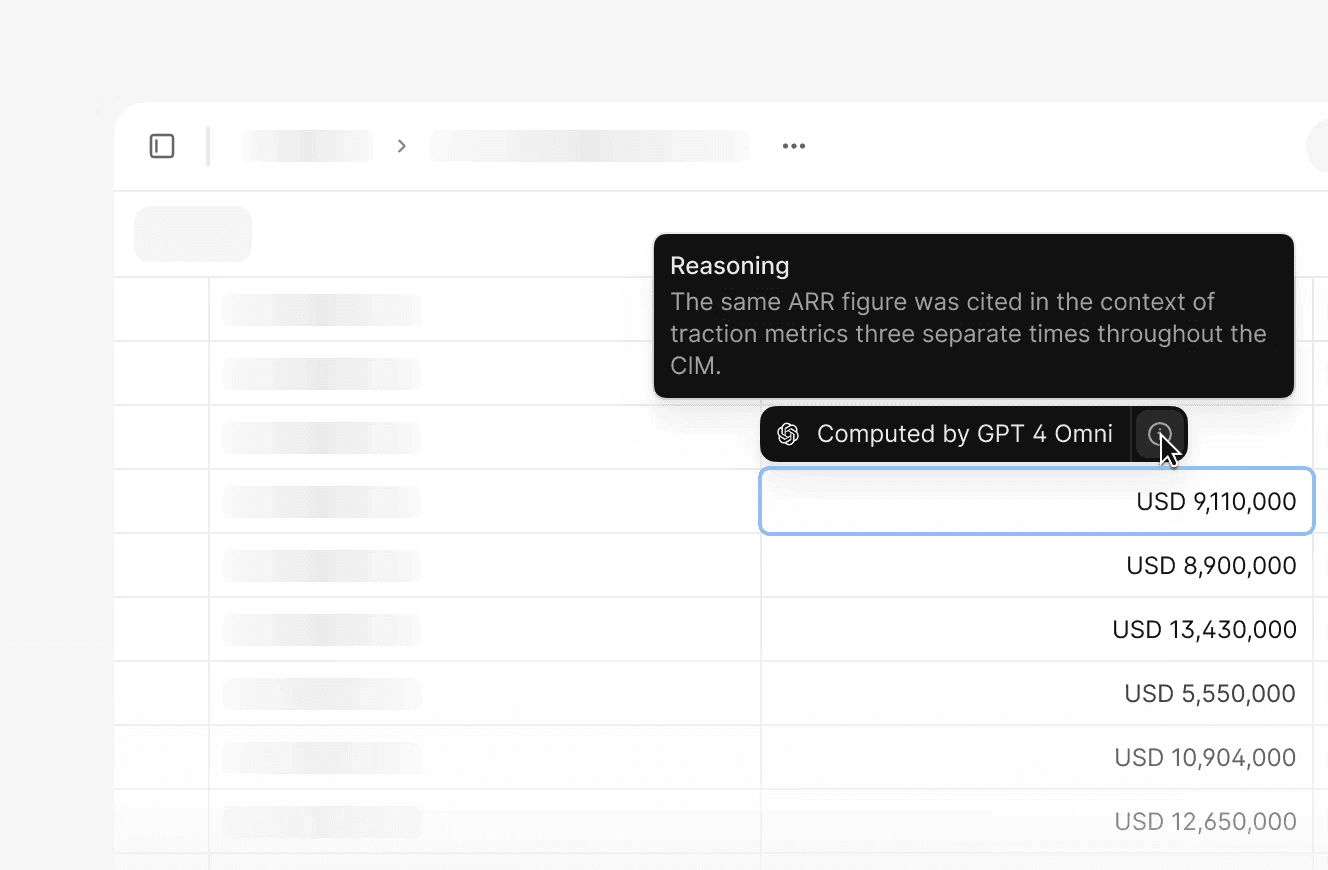
AI citation tooltips trace each extracted figure back to its source references in the document. A fund controller responding to an LP query or audit request can point to the exact location in the original document, rather than only the number in the output table.
V7 Go for document-layer reconciliation
V7 Go is an AI agent platform built for document-heavy knowledge work in finance, legal, and insurance. For portfolio reconciliation specifically, the relevant capabilities are multimodal document ingestion (PDFs, DOCX, and image-based scans all process through the same workflow), AI Citations (V7 Go's visual grounding feature), which links every extracted figure to its exact location in the source document, and the ability to run comparison logic across multiple documents within a single agent workflow.
A V7 Go reconciliation agent works like this: you define the fields you want to extract from each document type. IRR, MOIC, and DPI from LP letters. NAV and expense ratios from administrator reports. Capital commitment figures from capital call notices. The agent runs across your document set, extracts each field with a page-level citation, and routes the results into V7 Go's project view for team review. The team sees a structured grid: document, field, extracted value, reference value, match status, and source page. Discrepancies flag automatically. The team investigates flagged items, documents their conclusions within the same workflow, and generates an output for audit or LP communication purposes.
The Document Comparison Agent handles a related use case: comparing two versions of the same document to identify changes, deletions, or figure modifications between draft and final. For firms that need to verify that a fund administrator's final report matches the draft reviewed by the GP before distribution, this agent removes the manual side-by-side review step.
For the financial modelling and spreading workflows that run in parallel with reconciliation, the Financial Statement Spreading automation and the AI Financial Model Builder Agent address the structured data extraction that feeds into portfolio performance calculations. The data that flows through these workflows is the same data that document reconciliation must verify.

V7 Go organises fund documents and extracted data into structured workflows, making it straightforward to route documents by fund, period, or entity type for systematic reconciliation across a multi-fund portfolio.
What AI reconciliation does not replace
Extraction and comparison are automatable. Root cause investigation is not.
When the AI agent flags an IRR discrepancy of 40 basis points between the LP letter and the administrator's confirmed figure, a human still needs to determine why. Is it a different performance period? A different cash flow timing assumption in the DPI calculation? A genuine calculation error? That determination requires knowledge of the fund's methodology, the administrator's calculation practices, and the LPA's definitions. The agent surfaces the discrepancy. The analyst investigates it.
LP relationship management when a discrepancy is material is also human work. If a fund controller needs to contact an LP to explain a figure correction, no AI agent does that conversation. What the agent does is ensure the controller arrives at that conversation with a clear factual record: here is the figure that appeared in the letter, here is the source document that contained it, here is when the discrepancy was identified, and here is the corrected figure with the administrator's confirmation.
Criteria for evaluating reconciliation tools
The established reconciliation platforms — Linedata, NeoXam, ReconArt — handle the data layer well. Their matching engines are mature, their tolerance configuration is flexible, and their exception management workflows are built for the daily volume a hedge fund operation requires. None of them were designed for the document layer. When evaluating tools for document-layer reconciliation, five questions separate useful platforms from expensive demonstrations.
Can it handle any document format without template configuration? Template-based OCR requires manual field mapping for each document type. A fund administrator changes their report template and the extraction breaks. AI document agents do not require template configuration because they understand document structure contextually. If a platform requires manual field mapping for each new document format, it will not scale to a multi-administrator environment.
Does it cite the source of every extracted figure? An extraction result with no source reference is a number with no provenance. Any platform that cannot tell you that a specific IRR figure came from page 4, paragraph 2 of a particular administrator report cannot support the documentation requirements of a regulatory review or an LP query. Citation-linked extraction is a hard requirement for PE back-office deployment.
Can you configure tolerance rules per fund and per field type? An IRR tolerance of 5 basis points might be appropriate for one fund strategy and too tight for another where the calculation methodology differs from the administrator's. Platforms that apply uniform tolerances across all asset types will produce either too many false positive breaks or too many missed genuine discrepancies.
Does it integrate with your existing fund administration infrastructure? A reconciliation tool that requires manual document uploads from each administrator portal adds a step to the workflow rather than removing one. The target state is direct integration with data room feeds or administrator portals, or at minimum an automated ingestion layer that handles document retrieval without analyst intervention.
Does the output satisfy an LP or an auditor? The reconciliation output must be readable by a qualified person who did not perform the work. If you need to explain the reconciliation record when presenting it to an auditor, the record is not complete. A useful output shows what was reconciled, what was found, and what was done about it, with every figure traceable to its source.
Building a defensible reconciliation process
Technology is one component. A defensible portfolio reconciliation process has five structural properties, and most PE firms are currently missing at least two of them.
Building an AI-augmented reconciliation process follows a practical sequence: identify the manual steps that carry the highest error risk, rank them by volume and complexity, then assess the ROI of automating each one before committing to a platform.
Frequency tied to risk, not convenience. Cash and position reconciliation should run daily. NAV reconciliation should run at every administrator cut-off. Document reconciliation should run in parallel with every investor communication cycle, with enough lead time to investigate and resolve breaks before LP letters distribute. If reconciliation only happens after LP letters have gone out, breaks surface after the fact.
Tolerance rules in writing. 'We will know a discrepancy when we see it' is not a reconciliation policy. Tolerance thresholds need documentation by fund, by data type, and by source pair. For example: IRR differences between administrator report and LP letter within 10 basis points are within tolerance; differences above 10 basis points require investigation and Fund Controller sign-off before distribution. Written tolerances allow the process to be audited and defended.
Break resolution tracked with ownership. Every break that surfaces needs an assigned owner, a timestamp, a root cause determination, and a resolution record. Reconciliation tools that do not support this natively require a complementary case management process. V7 Go's Cases feature handles this directly: each flagged discrepancy becomes a case with an assigned owner, timeline, and documentation record, giving the team a single place to track open items through to resolution.
Output readable without explanation. The reconciliation record should be self-explanatory to a qualified reader who did not perform the work. This means every figure in the reconciliation output is traceable to its source document, every break is accompanied by a root cause determination, and every resolution is dated and attributed. If the record requires a walk-through to make sense, it is incomplete.
Scope reviewed annually. Reconciliation processes drift. New fund structures are added, new administrator relationships begin, and the scope of documents requiring reconciliation expands. A process scoped for a three-fund portfolio may no longer cover a five-fund portfolio with a new co-investment vehicle. Annual scope review, with Fund Controller sign-off, keeps the process current.
The specific starting point for most PE operations teams is not to automate everything at once. Identify the three highest-frequency break types from the last two quarters. Automate detection of those three. Build the documentation workflow around them before expanding scope. That sequencing is consistent with how AI adoption is proceeding across finance operations more broadly: targeted first, then expanded once the foundation is proven. Linnovate Partners' analysis of fund operations automation ROI documents cases where reconciliation project delivery was cut from 74 days to hours. That is an exceptional result from a specific implementation context, but the direction is consistent with what fund operations teams report across the board: automation at the document layer returns analyst time to work that actually requires judgment.
For the financial analysis workflows that feed into reconciliation, the guide to AI-assisted financial statement analysis covers the extraction and comparison processes that underpin portfolio-level performance data.
The operational case for acting now
The argument for upgrading document reconciliation is not primarily about efficiency. It is about where operational risk lives in a PE back office. Position breaks in a trading system are visible: they generate exception reports, trigger defined workflows, and resolve within a documented timeline. Document discrepancies in LP communications are often invisible until an LP notices them. That is the worst possible moment for a fund manager to be correcting errors.
LP relationships in private credit and PE are long-term. A firm that consistently produces accurate, clearly documented quarterly communications builds trust over multiple years. A firm that sends correction letters, even occasionally, raises questions that take several correct quarters to settle. Document reconciliation is what prevents correction letters from being necessary in the first place.
The first step is honest assessment: identify every manual step in your current document reconciliation workflow, estimate the analyst hours each step consumes per quarter, and calculate what a 90% reduction in those hours would return to the team. Then ask the harder question: could your current reconciliation output be presented to an LP or an auditor without additional explanation? If the answer is no, that is the problem to solve first. The full picture of AI in asset management operations provides context for where document reconciliation fits within a broader operational modernisation strategy.

What is portfolio reconciliation in private equity?
Portfolio reconciliation in private equity is the process of verifying that every figure recorded in the fund's books of record matches the corresponding figure held by external parties: custodians, prime brokers, fund administrators, and the figures distributed to limited partners in quarterly statements and capital call notices. The process operates across two distinct layers. The data layer involves matching structured position files, trade records, and cash movements between internal systems and external counterparties. This is largely automated through platforms like Advent, Allvue, and SS&C. The document layer involves verifying that the figures in investor-facing PDFs, LP letters, and fund administrator reports are consistent with each other and with the book of record. This layer remains largely manual for most PE firms, requires reading and extracting figures from unstructured documents, and carries the highest error risk for LP communications. Both layers are required for a complete reconciliation process. Most guidance on reconciliation software focuses on the data layer and does not address the document layer at all.
+
What are the four types of reconciliation PE firms run?
PE firms typically run four categories of reconciliation. Position reconciliation verifies the quantity and market value of each security or investment position against custodian or prime broker records. For funds with illiquid holdings, this runs at valuation dates rather than daily. Cash reconciliation verifies all cash movements including capital contributions, distributions, management fees, and fund expenses against bank statements and administrator records. This should run at minimum weekly, daily for funds with active cash activity. NAV reconciliation checks the fund's net asset value calculation against the fund administrator's independently calculated figure. Differences commonly arise from pricing source variations, expense timing, or carried interest methodology. Document reconciliation verifies the figures in investor-facing communications, including LP quarterly letters, capital call notices, and distribution notices, against the source data from which those figures derive. This is the type most commonly skipped or performed inconsistently, and the type that creates the highest reputational risk when errors reach LP communications.
+
What are the regulatory requirements for portfolio reconciliation?
Portfolio reconciliation requirements vary by jurisdiction and entity type. Under Dodd-Frank, CFTC rules at 17 CFR 23.502 require swap counterparties to confirm outstanding positions with each other at regular intervals, identify any discrepancies, and attempt to resolve them. The frequency of reconciliation required depends on the number of outstanding transactions between the parties. EMIR carries equivalent requirements for European counterparties to OTC derivative contracts. SEC recordkeeping requirements apply broadly to registered investment advisers and require that reconciliation processes be documented, not just completed. This means that a spreadsheet showing results without process documentation does not satisfy the regulatory standard. A defensible reconciliation record must show what was reconciled, when, by whom, what discrepancies were found, and how they were resolved. For PE firms not subject to Dodd-Frank or EMIR, institutional LP due diligence processes typically impose equivalent documentation expectations, particularly for funds seeking commitments from pension plans or endowments with formal operational due diligence requirements.
+
How long does manual portfolio reconciliation typically take?
The time required for manual document-layer reconciliation depends on the number of LPs, the number of documents per LP, and the number of fields requiring verification. A practical benchmark: extracting and verifying six key figures from a single 15-to-20-page administrator report takes an experienced analyst approximately 20 minutes. For a fund with 85 LPs, that is roughly 30 hours of extraction work before any investigation of breaks begins. For a 300-LP fund, the quarterly document reconciliation process regularly takes 15 to 20 hours of analyst time, concentrated in the two-week period before LP letters distribute. Data-layer reconciliation, by contrast, is largely automated for firms using standard reconciliation platforms and produces exception reports for analyst review rather than requiring full manual processing. The 15 to 20 hour estimate covers document reconciliation only and does not include investigation and resolution time for the breaks identified, which adds additional hours depending on break frequency and complexity.
+
What should PE firms look for when choosing reconciliation software?
AI improves portfolio reconciliation accuracy in two specific ways: it eliminates manual transcription errors and it processes every document, not a sample. Manual transcription of figures from PDFs into reconciliation spreadsheets introduces errors at a rate of roughly 2 to 5 percent per data entry, according to fund operations research. Automated extraction achieves accuracy rates above 99 percent on structured numerical data, provided the extraction agent is configured correctly and includes a review step for edge cases. The more significant accuracy improvement comes from comprehensiveness. Manual document reconciliation under time pressure often involves spot-checking: reviewing a sample of documents and assuming the rest are consistent. AI agents process all documents in the same pass, which means discrepancies that would be missed in a sample-based review surface consistently. The third accuracy improvement is provenance: AI-extracted figures come with source citations, so an analyst investigating a discrepancy can go directly to the source page rather than re-reading the entire document to find where the figure originated.
+
How does AI improve portfolio reconciliation accuracy?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Imogen is an experienced content writer and marketer, specializing in B2B SaaS. She particularly enjoys writing about the impact of technology on sectors like law, finance, and insurance.

