Computer vision
10 min read
—
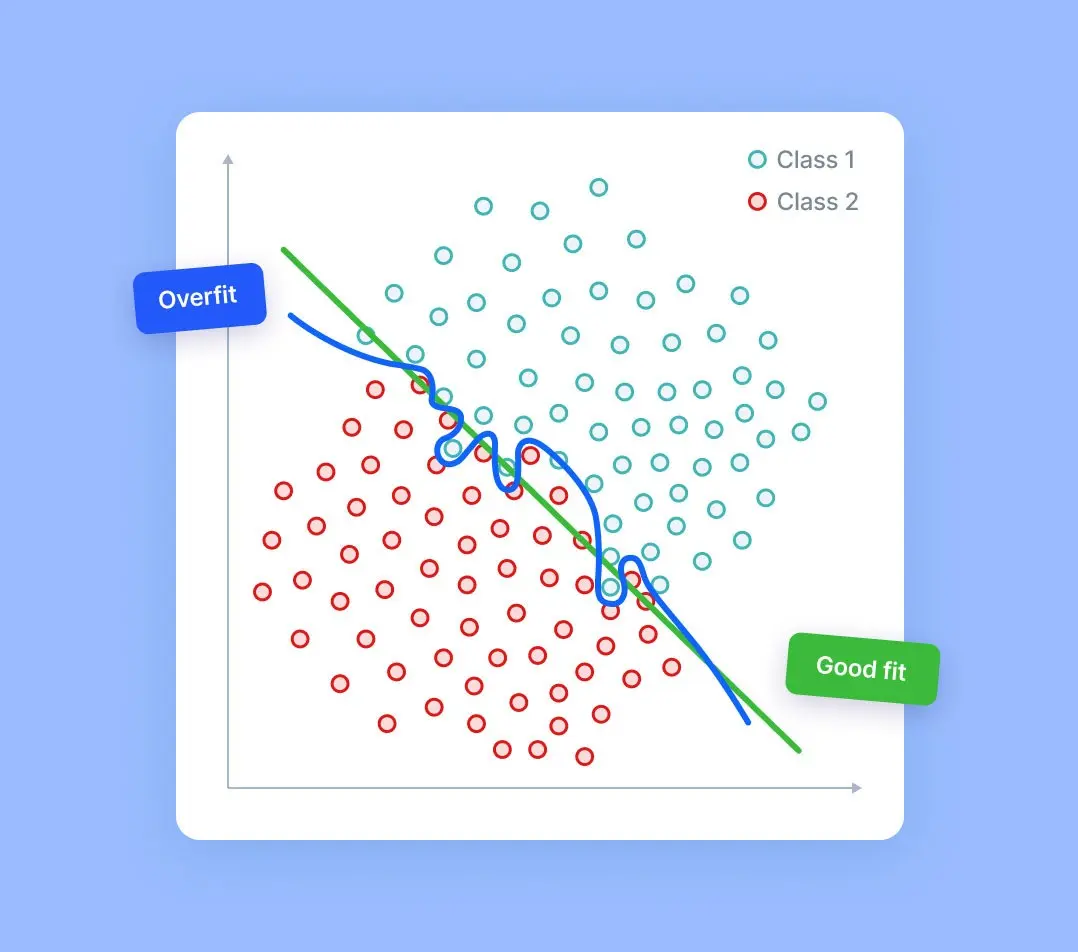
What are the consequences of overfitting your model and how to mitigate the risk? Learn how to train truly robust computer vision models and deploy AI faster with V7.

Out of all the things that can go wrong with your ML model, overfitting is one of the most common and most detrimental errors.
The bad news is that this time, it's not an exaggeration.
Overfitting is a frequent issue and if your model generalizes data poorly on new testing data, you know have a problem.
But—
Worry not! We are here to help you understand the issue of overfitting and find ways to avoid it shall you become dangerously close to overfitting your model.
Here’s what we’ll cover:
What is overfitting?
Overfitting vs. Underfitting
How to detect overfit models?
10 techniques to avoid overfitting

Knowledge work automation
AI for knowledge work
Get started today
And if you happen to be ready to get some hands on experience labeling data and training your AI models, make sure to check out:
What is overfitting?
It is a common pitfall in deep learning algorithms in which a model tries to fit the training data entirely and ends up memorizing the data patterns and the noise and random fluctuations.
These models fail to generalize and perform well in the case of unseen data scenarios, defeating the model's purpose.
When can overfitting occur?
The high variance of the model performance is an indicator of an overfitting problem.
The training time of the model or its architectural complexity may cause the model to overfit. If the model trains for too long on the training data or is too complex, it learns the noise or irrelevant information within the dataset.
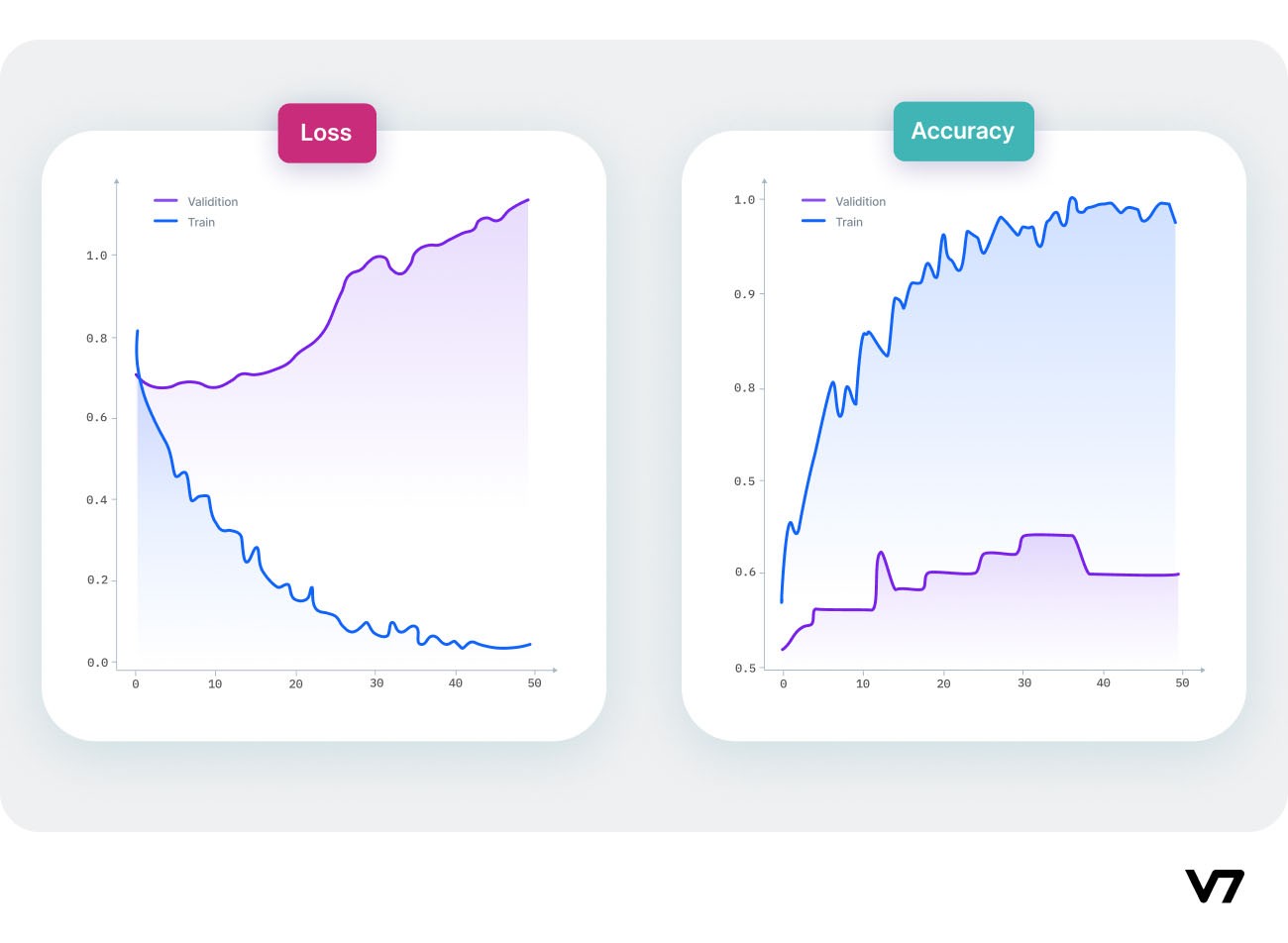
Signs of overfitting
Overfitting: Key definitions
Here are some of the key definitions that’ll help you navigate through this guide.
Bias: Bias measures the difference between the model’s prediction and the target value. If the model is oversimplified, then the predicted value would be far from the ground truth resulting in more bias.
Variance: Variance is the measure of the inconsistency of different predictions over varied datasets. If the model’s performance is tested on different datasets, the closer the prediction, the lesser the variance. Higher variance is an indication of overfitting in which the model loses the ability to generalize.
Bias-variance tradeoff: A simple linear model is expected to have a high bias and low variance due to less complexity of the model and fewer trainable parameters. On the other hand, complex non-linear models tend to observe an opposite behavior. In an ideal scenario, the model would have an optimal balance of bias and variance.
Model generalization: Model generalization means how well the model is trained to extract useful data patterns and classify unseen data samples.
Feature selection: It involves selecting a subset of features from all the extracted features that contribute most towards the model performance. Including all the features unnecessarily increases the model complexity and redundant features can significantly increase the training time.
Pro tip: Refresh your knowledge by reading What is Machine Learning? The Ultimate Beginner's Guide.
Overfitting vs. Underfitting
Underfitting occurs when we have a high bias in our data, i.e., we are oversimplifying the problem, and as a result, the model does not work correctly in the training data.
Overfitting occurs when the model has a high variance, i.e., the model performs well on the training data but does not perform accurately in the evaluation set. The model memorizes the data patterns in the training dataset but fails to generalize to unseen examples.
Overfitting vs. Underfitting vs. Good Model
Overfitting happens when:
The data used for training is not cleaned and contains garbage values. The model captures the noise in the training data and fails to generalize the model's learning.
The model has a high variance.
The training data size is not enough, and the model trains on the limited training data for several epochs.
The architecture of the model has several neural layers stacked together. Deep neural networks are complex and require a significant amount of time to train, and often lead to overfitting the training set.
Pro tip: Want to train your own AI model? Check out V7 Model Training to get started.
Underfitting happens when:
Unclean training data containing noise or outliers can be a reason for the model not being able to derive patterns from the dataset.
The model has a high bias due to the inability to capture the relationship between the input examples and the target values.
The model is assumed to be too simple. For example, training a linear model in complex scenarios.
The goal is to find a good fit such that the model picks up the patterns from the training data and does not end up memorizing the finer details.
This, in turn, would ensure that the model generalizes and accurately predicts other data samples.
Pro tip: Learn more by reading Overfitting vs. Underfitting: What's the Difference?
Have a look at this visual comparison to get a better understanding of the differences.
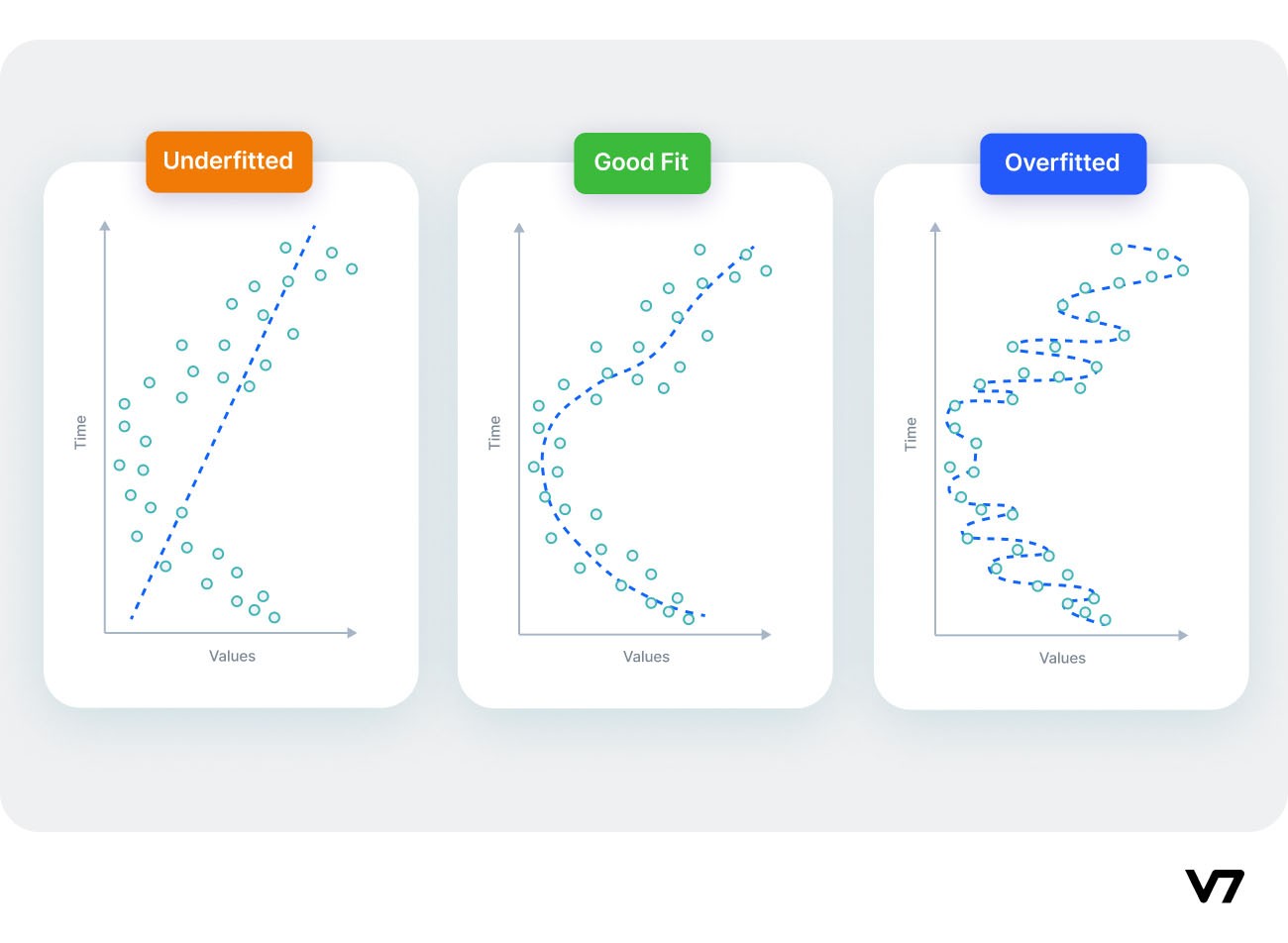
Underfitted vs. Fit vs. Overfitted model
How to detect overfit models?
Here’s something you should know—
Detecting overfitting is technically not possible unless we test the data.
One of the leading indicators of an overfit model is its inability to generalize datasets. The most obvious way to start the process of detecting overfitting machine learning models is to segment the dataset. It’s done so that we can examine the model's performance on each set of data to spot overfitting when it occurs and see how the training process works.
K-fold cross-validation is one of the most popular techniques commonly used to detect overfitting.
We split the data points into k equally sized subsets in K-folds cross-validation, called "folds." One split subsets act as the testing set, and the remaining folds will train the model.
The model is trained on a limited sample to estimate how the model is expected to perform in general when used to make predictions on data not used during the training of the model. One fold acts as a validation set in each turn.
Pro tip: Ready to train your models? Have a look at Mean Average Precision (mAP) Explained: Everything You Need to Know.
After all the iterations, we average the scores to assess the performance of the overall model.
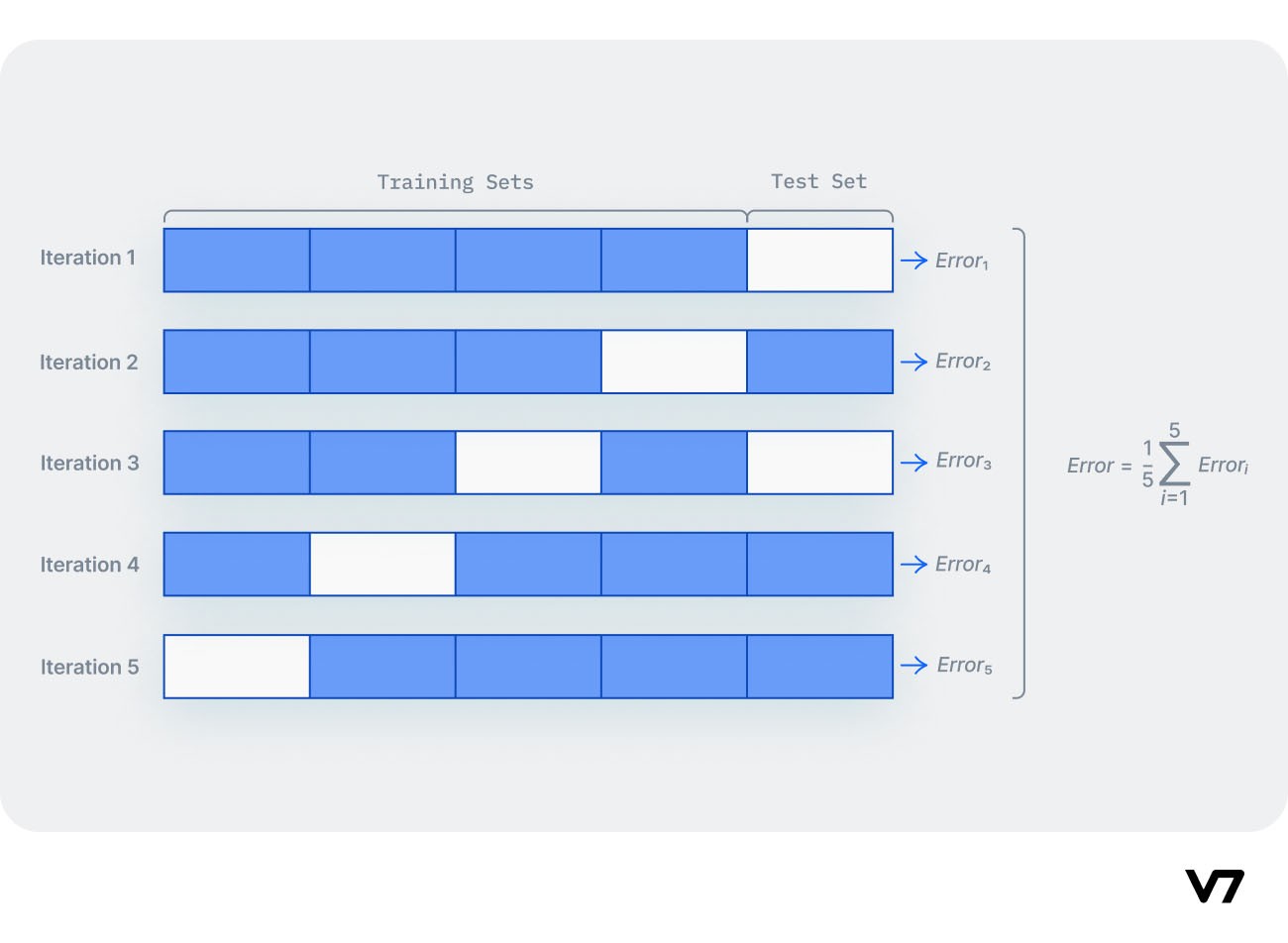
K-fold cross-validation
Pro tip: Read more about data preprocessing and data cleaning before you start training your ML models.











10 techniques to avoid overfitting
Here we will discuss possible options to prevent overfitting, which helps improve the model performance.
Train with more data
With the increase in the training data, the crucial features to be extracted become prominent. The model can recognize the relationship between the input attributes and the output variable. The only assumption in this method is that the data to be fed into the model should be clean; otherwise, it would worsen the problem of overfitting.
Pro tip: Looking for quality data? Check out 65+ Best Free Datasets for Machine Learning.
Data augmentation
An alternative method to training with more data is data augmentation, which is less expensive and safer than the previous method. Data augmentation makes a sample data look slightly different every time the model processes it.
Pro tip: Read also Neural Style Transfer: Everything You Need to Know [Guide].
Addition of noise to the input data
Another similar option as data augmentation is adding noise to the input and output data. Adding noise to the input makes the model stable without affecting data quality and privacy while adding noise to the output makes the data more diverse. Noise addition should be done in limit so that it does not make the data incorrect or too different.
Feature selection
Every model has several parameters or features depending upon the number of layers, number of neurons, etc. The model can detect many redundant features or features determinable from other features leading to unnecessary complexity. We very well know that the more complex the model, the higher the chances of the model to overfit.
Cross-validation
Cross-validation is a robust measure to prevent overfitting. The complete dataset is split into parts. In standard K-fold cross-validation, we need to partition the data into k folds. Then, we iteratively train the algorithm on k-1 folds while using the remaining holdout fold as the test set. This method allows us to tune the hyperparameters of the neural network or machine learning model and test it using completely unseen data.
Simplify data
Till now, we have come across model complexity to be one of the top reasons for overfitting. The data simplification method is used to reduce overfitting by decreasing the complexity of the model to make it simple enough that it does not overfit. Some of the procedures include pruning a decision tree, reducing the number of parameters in a neural network, and using dropout on a neutral network.
Pro tip: Learn more about neural networks by reading 12 Types of Neural Network Activation Functions: How to Choose?
Regularization
If overfitting occurs when a model is too complex, reducing the number of features makes sense. Regularization methods like Lasso, L1 can be beneficial if we do not know which features to remove from our model. Regularization applies a "penalty" to the input parameters with the larger coefficients, which subsequently limits the model's variance.
Ensembling
It is a machine learning technique that combines several base models to produce one optimal predictive model. In Ensemble learning, the predictions are aggregated to identify the most popular result. Well-known ensemble methods include bagging and boosting, which prevents overfitting as an ensemble model is made from the aggregation of multiple models.
Pro tip: Read The Essential Guide to Ensemble Learning.
Early stopping
This method aims to pause the model's training before memorizing noise and random fluctuations from the data. There can be a risk that the model stops training too soon, leading to underfitting. One has to come to an optimum time/iterations the model should train.
Adding dropout layers
Large weights in a neural network signify a more complex network. Probabilistically dropping out nodes in the network is a simple and effective method to prevent overfitting. In regularization, some number of layer outputs are randomly ignored or “dropped out” to reduce the complexity of the model.
Our tip: If one has two models with almost equal performance, the only difference being that one model is more complex than the other, one should always go with the less complex model. In data science, it's a thumb rule that one should always start with a less complex model and add complexity over time.
Overfitting: Key Takeaways
Finally, here’s a short recap of everything we’ve learn today.
A model is trained by hyperparameters tuning using a training dataset and then tested on a separate dataset called the testing set. If a model performs well on training data, it should work well for the testing set.
The scenario in which the model performs well in the training phase but gives a poor accuracy in the test dataset is called overfitting.
The machine learning algorithm performs poorly on the training dataset if it cannot derive features from the training set. This condition is called underfitting.
We can solve the problem of overfitting by:
Increasing the training data by data augmentation
Feature selection by choosing the best features and remove the useless/unnecessary features
Early stopping the training of deep learning models where the number of epochs is set high
Dropout techniques by randomly selecting nodes and removing them from training
Reducing the complexity of the model
Read more:
13 Best Image Annotation Tools
The Complete Guide to Panoptic Segmentation [+V7 Tutorial]
The Definitive Guide to Instance Segmentation [+V7 Tutorial]
9 Reinforcement Learning Real-Life Applications
Mean Average Precision (mAP) Explained: Everything You Need to Know
The Beginner's Guide to Deep Reinforcement Learning
The Ultimate Guide to Semi-Supervised Learning
Multi-Task Learning in ML: Optimization & Use Cases

Pragati is a software developer at Microsoft, and a deep learning enthusiast. She writes about the fundamental mathematics behind deep neural networks.

