Knowledge work automation
30 min read
—


A technical deep dive into training custom machine learning models for private equity workflows—from deal screening to portfolio monitoring—and why out-of-the-box AI agents are often the smarter path.

Most private equity firms already use models to screen opportunities. The bottleneck is not the model itself. It is the 200 to 300 pages of Confidential Information Memoranda (CIMs), data room documents, and financial reports that must be read, normalized, and reconciled before any model can run. A Vice President of Finance at a mid-sized PE shop will tell you the truth: despite six figures spent on enterprise software, the actual workable data still lives in Excel spreadsheets maintained through manual re-keying and error-prone VLOOKUPs.
Between January and mid-May 2023, private equity and venture capital firms announced $10.34 billion in investments across 342 transactions in AI and machine learning companies. Yet fewer than 10% of private funds had implemented AI in core operational functions by mid-2023. In 2026, the gap between investment thesis and operational reality still remains wide.
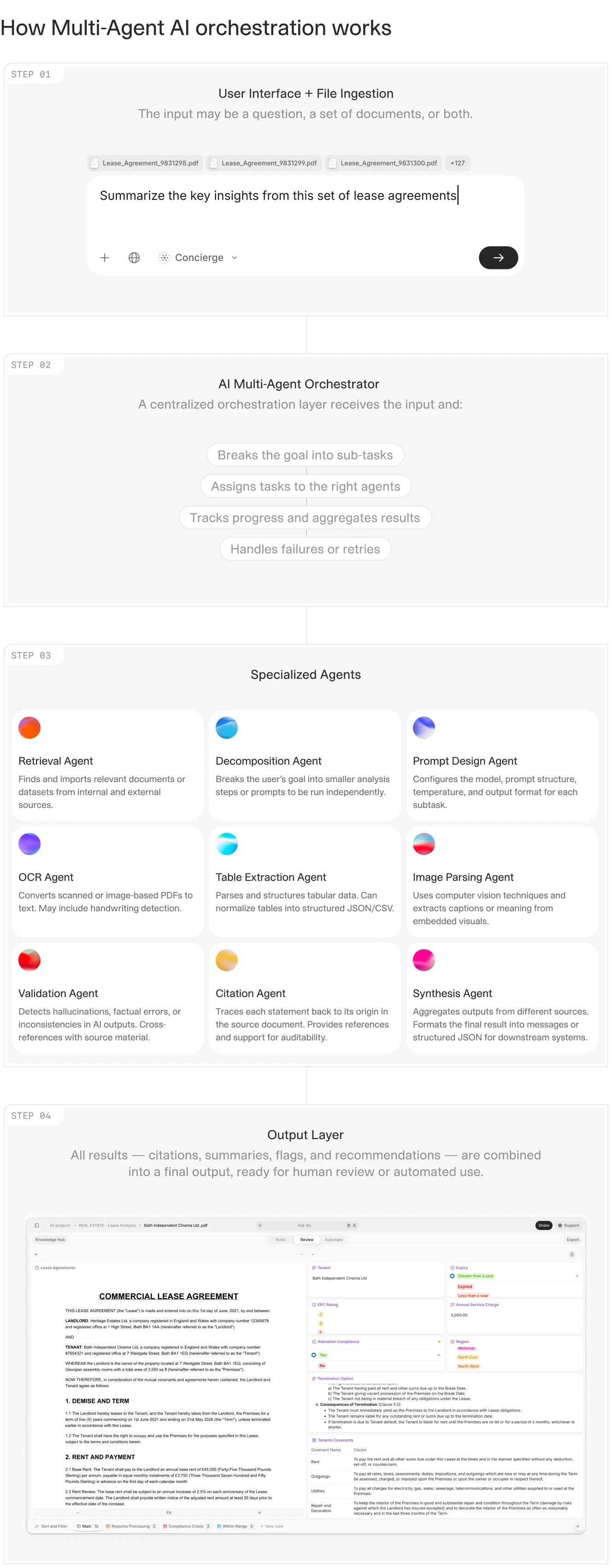
This article is a technical examination of how machine learning actually gets deployed in private equity: what works, what fails, and where the real bottlenecks live. We focus specifically on custom model training for document-heavy workflows, then contrast it with the emerging category of pre-built AI agents that handle the same tasks with less overhead.
In this article:
The ML Stack for PE: Understanding the difference between predictive models for portfolio forecasting and extraction models for due diligence documents.
Custom Model Training: When to build your own models, what data you need, and why most firms underestimate the engineering lift.
The Agent Alternative: How platforms like V7 Go provide out-of-the-box extraction and analysis without requiring a data science team.
Evaluation and Quality Assurance: Acceptance criteria, sampling strategies, and how to measure extraction accuracy in production.
Real Workflows: Concrete examples from CIM triage, covenant monitoring, and portfolio company reporting.

Knowledge work automation
AI for knowledge work
Get started today
The Two Types of Machine Learning in Private Equity
Private equity practitioners often conflate two distinct problem classes under the label "machine learning." Understanding this distinction matters because each requires different architectures, different training data, and different success metrics. Choosing the wrong approach wastes months of engineering effort.
Predictive Models: Forecasting Portfolio Performance
Predictive models attempt to forecast future outcomes based on historical patterns. In private equity, this typically means predicting portfolio company revenue growth, EBITDA margins, or exit multiples based on sector trends, macroeconomic indicators, and company-specific KPIs.
These models rely on structured, numerical data. You feed them time-series data from your portfolio companies—quarterly revenue, headcount growth, customer acquisition costs—and train them to identify patterns that correlate with successful exits or operational distress. The output is a probability distribution or a point forecast.
The challenge is data scarcity. A mid-sized PE firm might have 30 to 50 portfolio companies at any given time, with three to five years of quarterly data per company. That gives you perhaps 600 to 1,000 data points to train a model that needs to generalize across different sectors, geographies, and market cycles. Gradient boosting and random forests can work here, but they require careful feature engineering and strict cross-validation to prevent overfitting.
One Reddit user building a model for a PE firm's investment decisions noted the core challenge: "The problem you're trying to solve is extremely complex. This just isn't a lot of data and you probably don't have all the features that you would need to capture that complexity." The user recommended ensemble models, bootstrapping, and permutation testing as necessities to avoid self-deception about model quality.
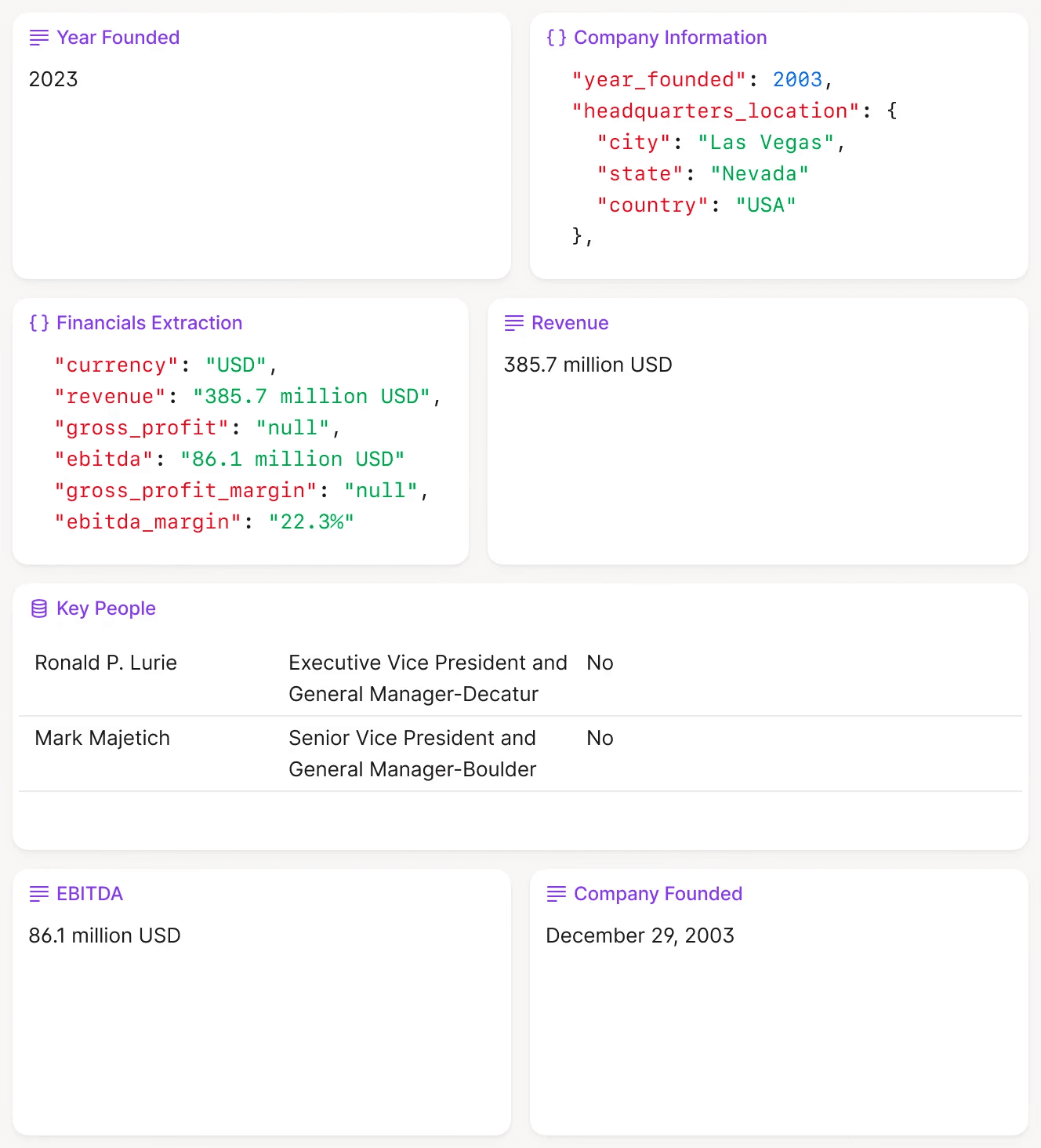
Structured financial data extracted from unstructured documents, ready for model training or direct analysis.
Extraction Models: Document Intelligence for Due Diligence
Extraction models solve a different problem: pulling structured data out of unstructured documents. This is where the real operational pain lives in private equity. Every deal generates hundreds of pages of PDFs—CIMs, pitch decks, legal contracts, financial statements, environmental reports. Analysts spend days copying figures into spreadsheets, flagging inconsistencies, and reconciling data across documents.
Modern extraction models use a combination of Optical Character Recognition (OCR), Natural Language Processing (NLP), and Large Language Models (LLMs) to automate this process. The model reads a document, identifies key entities (company names, revenue figures, covenant terms), and outputs structured data in a format your systems can ingest.
The technical challenge here is not data scarcity. It is data variety. A CIM from a healthcare services company looks nothing like a CIM from a manufacturing roll-up. Contract clauses follow different legal styles. Financial statements use different accounting standards. Your extraction model needs to handle this variability without a complete retraining for every new document type.
V7 Go's CIM due diligence workflow shows automated extraction of company information, financial metrics, and entity relationships from unstructured documents.
The Case for Custom Model Training
Before dismissing custom models entirely, it is worth understanding when they make sense. Building a custom machine learning model for private equity workflows is justified in specific scenarios. If your firm has a narrow, repeatable process—say, you only invest in SaaS companies and you always extract the same 20 metrics from every CIM—then training a custom model on your historical data can yield high accuracy with minimal ongoing maintenance.
When Custom Models Win
Custom models excel under three conditions:
Proprietary data formats. If your target companies use non-standard reporting templates or your firm has developed its own due diligence questionnaire format, a custom model trained on your specific documents will outperform a generic solution. One PE firm focused exclusively on healthcare IT companies found that their CIMs all followed a similar structure because the same three investment banks handled most deals in the sector. A model trained on 200 historical CIMs achieved 94% field-level accuracy after six months of development.
Highly specialized domain knowledge. In sectors like life sciences or energy infrastructure, the relevant metrics and risk factors are not well-represented in public datasets. A model trained on your firm's historical deals can learn to flag sector-specific red flags that a general-purpose model would miss. For example, a private credit fund focused on oil and gas learned to extract reserve-based lending metrics (PV-10, proved developed reserves, decline curves) that standard extraction tools ignored.
Integration with proprietary systems. If you have built custom portfolio monitoring dashboards or risk management tools, a custom extraction model can output data in exactly the format your systems expect. This eliminates post-processing and manual reconciliation. The model becomes a component of a larger data pipeline rather than a standalone tool.
The Hidden Costs of Custom Development
The problem is that most firms underestimate the engineering and operational overhead required to build and maintain a custom model. Here is what the process actually looks like:
Data labeling. Before you can train a model, you need labeled training data. For an extraction model, this means manually annotating hundreds of documents. You highlight every instance of "revenue," "EBITDA," "covenant," and so on. This is tedious, expensive work. A single analyst might label 10 to 15 documents per day. To build a training set with acceptable variance, you need at least 500 to 1,000 labeled documents. That represents two to three months of full-time work.
The labeling work requires a schema. You need to define exactly what constitutes "EBITDA" in your context. Is it GAAP EBITDA? Adjusted EBITDA? Management's pro forma EBITDA? Your labelers need clear guidelines, and you need inter-annotator agreement metrics to ensure consistency. Most PE firms lack this documentation because the definitions live in analysts' heads.
Model training and tuning. Once you have labeled data, you need to train the model. This requires expertise in machine learning frameworks like TensorFlow or PyTorch, knowledge of model architectures (transformers for NLP, convolutional networks for document layout), and access to GPU compute resources. Training a model from scratch can take days or weeks, depending on document complexity and training set size.
Ongoing maintenance. Models degrade over time as document formats change, new legal clauses appear, or your firm expands into new sectors. You need a process for monitoring model performance, collecting new labeled data, and retraining the model on a regular cadence. This is not a one-time project. It is an ongoing operational commitment that requires dedicated headcount.
Multi-agent orchestration architecture showing how specialized models work together to process complex documents.
The Reality Check: Why Most Firms Should Not Build Custom Models
The dirty secret of machine learning in private equity is that most firms lack the data volume, the engineering talent, or the operational discipline to build and maintain custom models successfully. A 2023 Deloitte survey found that fewer than 10% of private funds had implemented AI in core functions, and among those that tried, many abandoned their custom model projects after six to twelve months due to poor accuracy or unsustainable maintenance costs.
The problem is not a lack of ambition. It is a mismatch between the problem structure and the solution approach. Private equity workflows are characterized by high variability and low volume. You might process 50 to 100 CIMs per year, but each one is different—different industries, different document structures, different levels of detail. This is the opposite of the ideal machine learning scenario, which requires large volumes of similar data.
One practitioner on Reddit captured the frustration: "GP focused AI fintechs promise a lot of value in processing data from CIMs, pitch books, credit memos, VDRs, etc but underdeliver because the models hallucinate data points. These systems are not deterministic and can't process information accurately at scale." The user noted that even with tuning, extraction accuracy maxes out around 90 to 92 percent.
Consider the alternative: instead of training a custom model, you use a pre-built AI agent that has already been trained on thousands of financial documents across multiple industries. The agent handles variability out of the box. It uses a combination of OCR, layout analysis, and LLMs to extract data from documents it has never seen before. When it encounters a new document type, it does not require retraining. It adapts using the same general-purpose capabilities it was built with.
This is the approach taken by platforms like V7 Go. Instead of asking you to build and maintain your own extraction models, V7 Go provides pre-configured agents for common private equity workflows: due diligence document processing, investment memo generation, financial statement analysis. These agents use state-of-the-art LLMs combined with V7's Knowledge Hubs and Index Knowledge technology for retrieval and citations. They work out of the box, with no data labeling or model training required. Your documents become context for the agents through Knowledge Hubs, not training data for fine-tuning.
V7 Go's agent dashboard showing pre-built workflows for invoice processing, receipt analysis, and batch document extraction.
The Data Labeling Playbook: If You Still Want to Build
For firms that have decided custom models are the right path, the labeling process is the critical bottleneck. Here is a practical playbook based on what works in production environments.
Define Your Schema First
Before anyone touches a document, you need a labeling schema. This is a formal specification of every field you want to extract, including definitions, edge cases, and examples. For a CIM extraction model, your schema might include:
Financial fields: Revenue (specify: trailing twelve months, fiscal year, pro forma), EBITDA (specify: GAAP, adjusted, management), EBITDA margin, revenue growth rate, capital expenditure, working capital.
Company fields: Legal entity name, headquarters location, founding year, employee count (specify: FTEs only or including contractors), ownership structure.
Deal fields: Asking price or valuation range, transaction type (majority, minority, recap), expected close date, exclusivity period.
Each field needs acceptance criteria. For example: "Revenue must be extracted as an integer in USD thousands. If the CIM reports revenue in millions, multiply by 1,000. If multiple revenue figures appear (e.g., gross revenue and net revenue), extract net revenue and flag the discrepancy."
Measure Inter-Annotator Agreement
Have at least two people label the same 50 documents independently. Calculate agreement metrics: for categorical fields like "sector," use Cohen's Kappa; for numerical fields like "revenue," use mean absolute percentage error between annotators. If agreement is below 80%, your schema is ambiguous. Revise it before scaling up labeling.
Sample Strategically
Do not label documents at random. Stratify your sample by sector, document source, and document age. If you only invest in healthcare and manufacturing, your training set should reflect that distribution. If you receive CIMs from 15 different investment banks, include documents from each bank because formatting varies by source.
Reserve 20% of your labeled data as a held-out test set. Never train on these documents. Use them only for final model evaluation. Another 10% should serve as a validation set for hyperparameter tuning.











Concrete Workflows: Where Machine Learning Actually Helps
The value of machine learning in private equity is not in replacing human judgment. It is in eliminating the manual data processing that prevents analysts from exercising that judgment. The following three workflows illustrate where extraction models and AI agents deliver measurable impact.
Workflow 1: CIM Triage and Deal Screening
A typical PE firm receives 200 to 300 CIMs per year. Each CIM runs 50 to 150 pages of narrative text, financial tables, and management bios. The first-pass screening question is simple: does this company meet our investment criteria? To answer that, you need to extract a handful of key metrics: revenue, EBITDA, growth rate, sector, geography.
Manually, this takes an analyst 30 to 45 minutes per CIM. Multiply that by 250 CIMs, and you have consumed 125 to 187 analyst hours—roughly three to four weeks of full-time work—just to build the initial screening list.
An extraction model or AI agent can reduce this to minutes. The agent reads the CIM, identifies the relevant sections (usually the executive summary and the financial overview), extracts the key metrics, and outputs a structured summary. The analyst reviews the summary, flags any obvious errors, and makes the go/no-go decision. Total time: five to ten minutes per CIM. The time savings compound: instead of spending a month on initial screening, the team spends a week. The other three weeks shift to deeper due diligence on the deals that pass the screen.
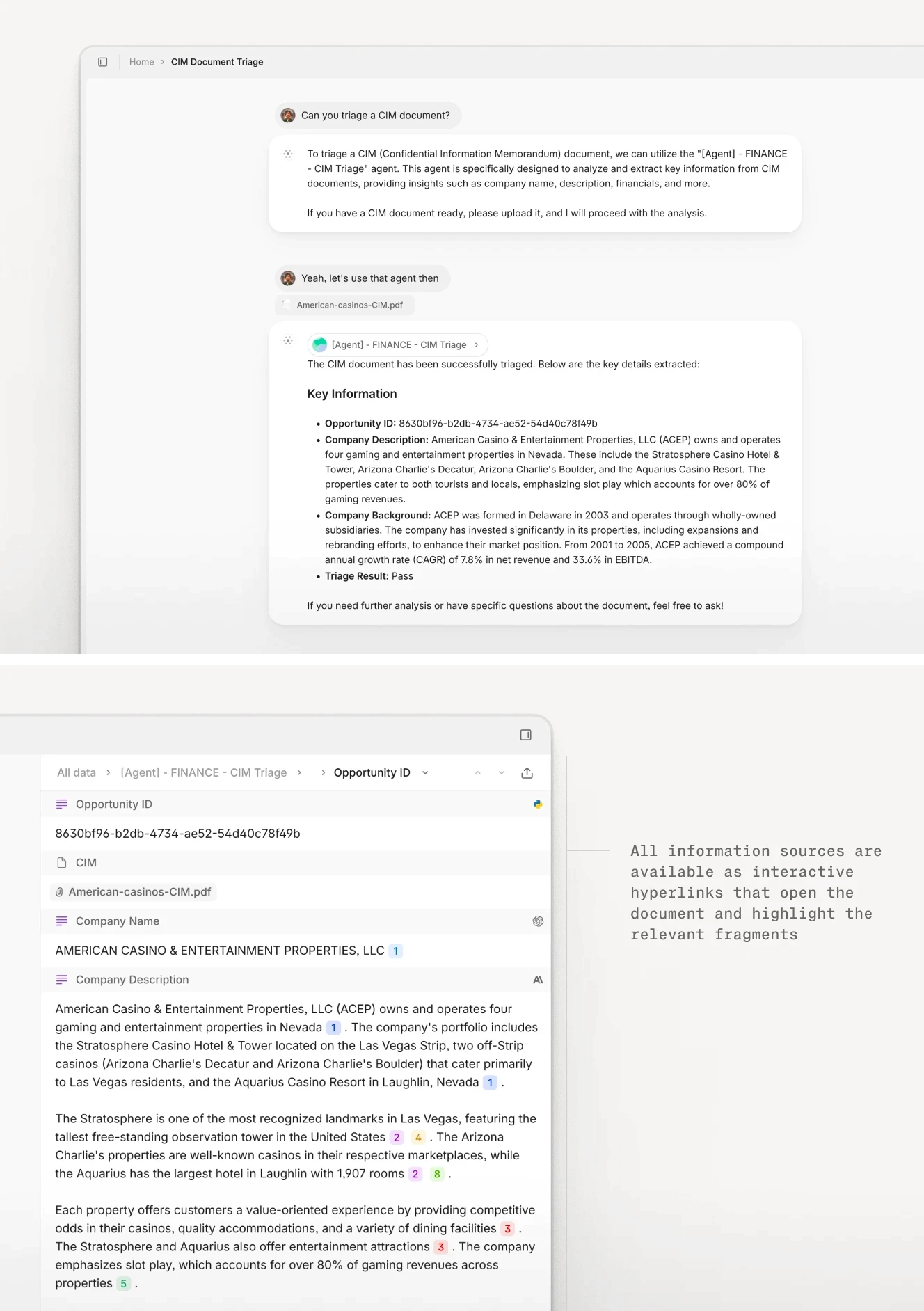
Automated CIM analysis showing extracted company information, financial data, and initial screening classification.
The technical challenge here is variability in document structure. Some CIMs put the financial summary on page 3; others bury it on page 47. Some use tables; others use narrative text. A production-grade extraction model needs to handle all of these formats without manual configuration for each new document.
V7 Go's Deal Screening and Triage Agent solves this through a combination of layout analysis and LLM reasoning. The agent first identifies document structure—where are the headings, where are the tables, where is the narrative text—and then uses an LLM to extract the relevant information from each section. This two-stage approach allows the agent to handle documents it has never seen before.
Workflow 2: Covenant Monitoring in Private Credit
Private credit funds face a different challenge: ongoing monitoring of loan covenants across a portfolio of 20 to 50 borrowers. Each borrower submits quarterly compliance certificates—PDFs that report financial ratios (debt-to-EBITDA, interest coverage, fixed charge coverage) and confirm compliance with loan covenants.
The manual process is straightforward but time-consuming. An analyst opens the compliance certificate, finds the reported ratios, compares them to the covenant thresholds in the credit agreement, and flags any breaches or near-breaches. This takes 15 to 20 minutes per borrower per quarter. For a 40-borrower portfolio, that is 10 to 13 hours of work every quarter—work that must be completed within a tight window after quarter-end.
An extraction model automates the first two steps: reading the compliance certificate and extracting the reported ratios. The model outputs a structured table with the borrower name, the reporting period, and the key ratios. The analyst then compares these ratios to the covenant thresholds (stored in a separate system or spreadsheet) and flags any issues.
The time savings are significant but not transformative. The extraction step might take two to three minutes instead of 15 to 20, but the analyst still needs to perform the comparison and make the judgment call. The real value is consistency and auditability. The model extracts the same fields from every document in the same way, eliminating the risk of human error or oversight.
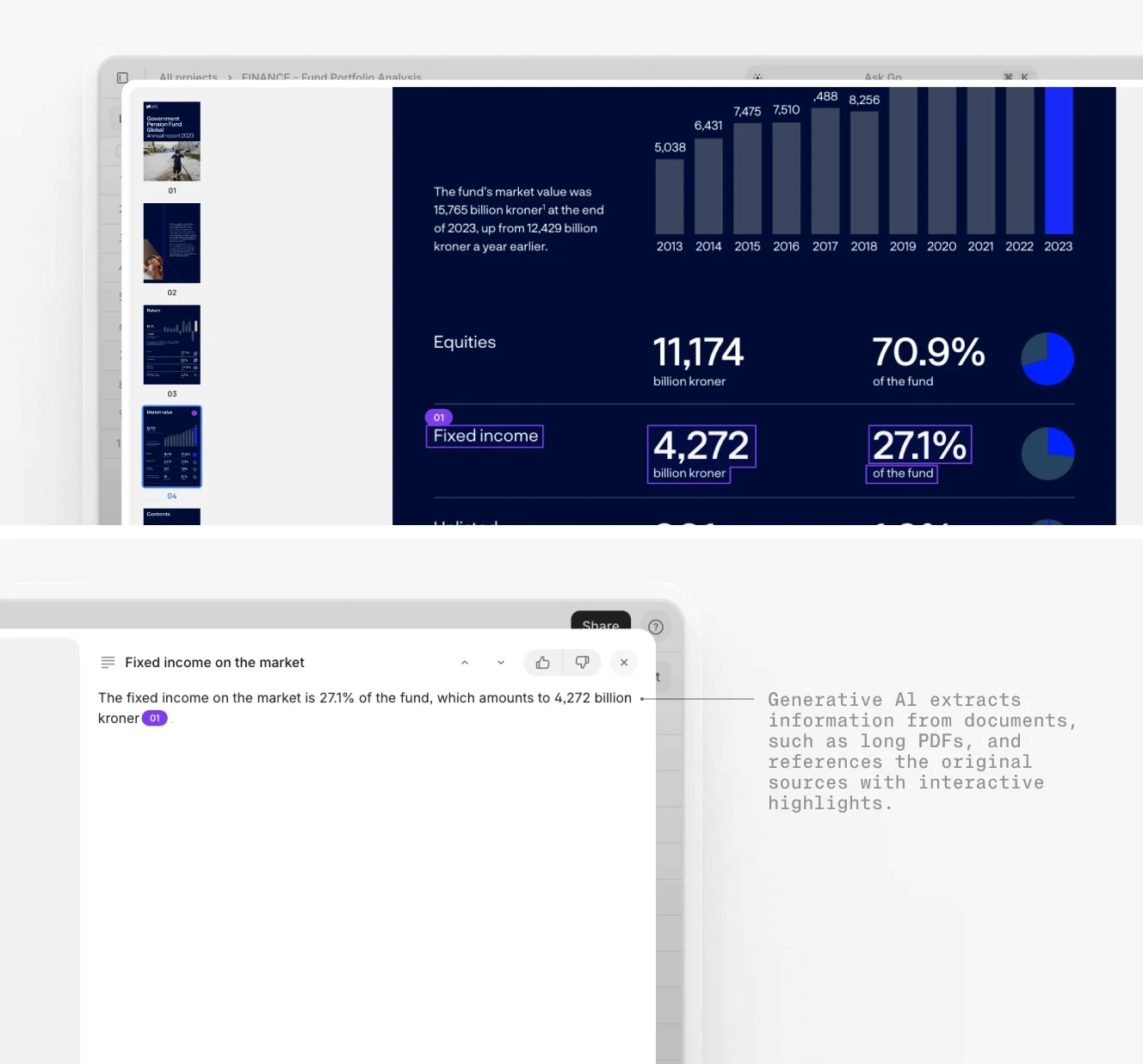
AI extraction with visual grounding shows exactly which text in the source document supports each extracted figure.
V7 Go's approach to this workflow includes a critical feature that custom models often lack: visual grounding and citations. When the agent extracts a ratio from a compliance certificate, it highlights the exact text in the source document that supports that figure. This allows the analyst to verify the extraction in seconds and provides an audit trail for compliance purposes.
Workflow 3: Portfolio Company Reporting Consolidation
Portfolio monitoring is the most data-intensive workflow in private equity. Each portfolio company submits monthly or quarterly reports—financial statements, operational KPIs, management commentary. The PE firm needs to consolidate this data across 10 to 30 portfolio companies, normalize it to a common format, and generate summary reports for the investment committee and limited partners.
The manual process is a nightmare of Excel workbooks and email attachments. Each portfolio company uses a different reporting template. Some send PDFs, some send Excel files, some send PowerPoint decks. The data is inconsistent: one company reports revenue in thousands, another in millions; one reports EBITDA as a dollar figure, another as a percentage of revenue. An analyst spends days after each reporting period chasing missing data, reconciling inconsistencies, and populating the consolidated reporting template.
An extraction model can automate much of this process, but only if it handles variable input formats. The model needs to read PDFs, Excel files, and PowerPoint decks; identify the relevant data fields in each document; normalize the data to a common format; and output a structured dataset for the firm's portfolio monitoring system.
This is a harder problem than CIM triage or covenant monitoring because the input variability is higher and the output requirements are more complex. You are not just extracting a handful of metrics. You are building a complete data pipeline that ingests data from multiple sources, transforms it, and loads it into a target system.
Batch processing of 10-Q filings showing automated extraction of company metadata, financial metrics, and executive summaries.
V7 Go handles this through a combination of intelligent document processing and workflow orchestration. The platform can ingest documents from email, cloud storage, or direct upload; route them to the appropriate extraction agent based on document type; extract the relevant data; normalize it to a common schema; and export it to your portfolio monitoring system or data warehouse. The entire pipeline runs automatically, with human review only required for edge cases or low-confidence extractions.
Evaluation and Quality Assurance for Extraction Models
Whether you build a custom model or deploy pre-built agents, you need a rigorous evaluation framework. Most firms skip this step and end up with false confidence in their extraction accuracy. Here is how to do it right.
Acceptance Criteria by Field Type
Not all extraction errors are equal. Define acceptance criteria for each field type:
Exact match fields: Company name, ticker symbol, headquarters address. These must match the source document exactly. Measure accuracy as (correct extractions / total extractions). Target: 98%+ for native PDFs, 95%+ for scanned documents.
Numerical fields: Revenue, EBITDA, ratios. Allow for formatting variations (commas, currency symbols) but the underlying number must be correct. Measure mean absolute percentage error (MAPE) against human-labeled ground truth. Target: MAPE under 2%.
Categorical fields: Sector, transaction type, geography. These should match your predefined taxonomy. Measure using precision, recall, and F1 score. Target: F1 above 0.90.
Text extraction fields: Management bios, risk factors, business descriptions. These are harder to evaluate because acceptable paraphrasing exists. Use ROUGE scores or human evaluation of a sample. Target: ROUGE-L above 0.85 or human "acceptable" rating above 90%.
Sampling and Statistical Significance
Do not evaluate on a handful of documents and declare victory. You need a statistically significant sample. For a population of 500 documents, you need to evaluate at least 80 documents at random to achieve 95% confidence with a 10% margin of error. For tighter margins, evaluate more.
Stratify your evaluation sample by document source, sector, and document quality (native PDF vs. scanned). Performance varies dramatically across these dimensions. A model that achieves 95% accuracy on native PDFs from bulge-bracket banks might drop to 80% on scanned documents from regional advisors.
Report confidence intervals, not point estimates. Saying "our model achieves 92% accuracy" is misleading without knowing the sample size and variance. Say instead: "our model achieves 92% accuracy (95% CI: 89%-95%) on a stratified sample of 100 documents."
Permutation Testing for Model Validity
For predictive models (not extraction), permutation testing is essential. Shuffle your target variable and retrain the model. If the shuffled model performs nearly as well as the real model, your real model is probably just fitting noise. This is especially important in private equity where sample sizes are small and overfitting is easy.
Bootstrapping provides another sanity check. Train your model on random subsamples of your data and measure variance in performance metrics. High variance suggests your model is unstable and may not generalize to new data.
Production Monitoring
Evaluation does not end at deployment. Set up monitoring for extraction quality in production. Sample 5 to 10 percent of extractions for human review. Track accuracy metrics over time. Watch for drift as document formats change or as you expand into new sectors.
V7 Go provides confidence scores for each extraction. Route low-confidence extractions (below 0.7) to human review automatically. Track the percentage of extractions requiring human review as a leading indicator of model performance. If the review rate climbs above 20%, investigate root causes.
The Build vs. Buy Decision Framework
If you are a PE firm evaluating whether to build custom machine learning models or adopt a pre-built AI agent platform, here is a practical decision framework.
Build Custom Models If:
You have a narrow, repeatable process. You invest in a single sector, you always extract the same metrics, and your document formats are consistent across deals.
You have proprietary data formats. Your target companies use non-standard reporting templates that are not well-represented in public datasets.
You have in-house ML expertise. You have data scientists or ML engineers on staff who can build, train, and maintain models.
You have a large volume of historical data. You have at least 500 to 1,000 labeled documents for training data, and you generate enough new documents each year to justify ongoing model maintenance.
You can commit to ongoing maintenance. You have budget and headcount for continuous monitoring, retraining, and improvement. This is not a one-time project.
Use Pre-Built AI Agents If:
You have high document variability. You invest across multiple sectors, and your document formats vary significantly from deal to deal.
You lack in-house ML expertise. You do not have data scientists on staff, and you do not want to hire them.
You need to deploy quickly. You want to start automating workflows in weeks, not months.
You value auditability and explainability. You need to trace every extracted figure back to its source document for compliance or investor reporting purposes.
You prefer predictable costs. You want a subscription fee rather than open-ended development costs.
For most PE firms, the second set of conditions applies. Variability in deal flow, lack of in-house ML talent, and need for rapid deployment make pre-built AI agents the more practical choice. Platforms like V7 Go provide extraction accuracy and workflow automation comparable to custom models without the engineering overhead.
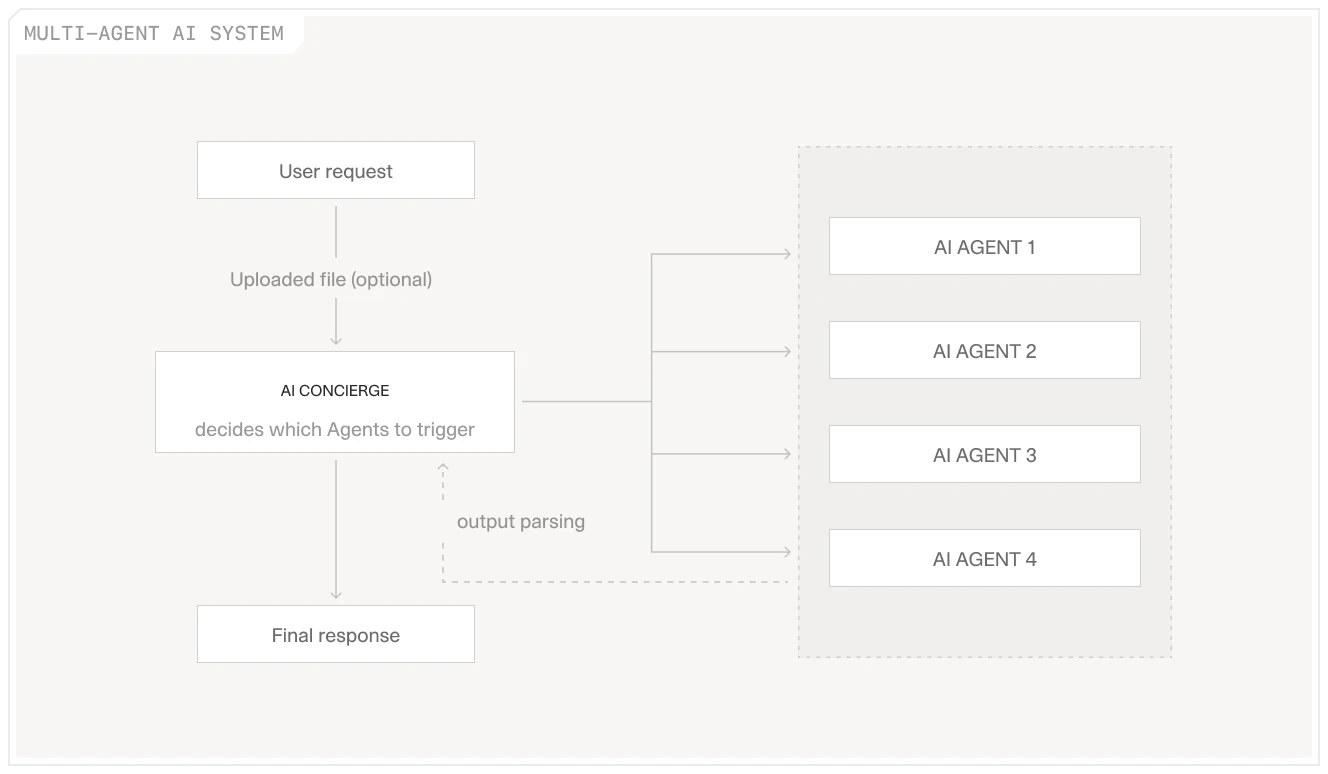
Multi-agent system architecture showing how a central orchestrator routes tasks to specialized agents for different document types and analysis workflows.
The Technical Reality: What Makes Extraction Models Hard
To understand why pre-built agents often outperform custom models, you need to understand the technical challenges of building an extraction model for financial documents. These challenges are not obvious from the outside, and firms embarking on custom development projects often underestimate them.
Challenge 1: OCR Quality and Layout Variability
Most financial documents are PDFs, and many of those PDFs are scanned images rather than native digital documents. This means the first step in any extraction pipeline is Optical Character Recognition (OCR)—converting the image of text into machine-readable text.
OCR is a solved problem for clean, high-resolution scans of printed text. But financial documents are rarely clean. They include tables with complex layouts, handwritten annotations, low-resolution scans, and multi-column formats. A production-grade OCR system needs to handle all of these cases without manual intervention.
Even after OCR, you face the layout analysis problem: identifying which text belongs to which section of the document. Is this number part of a table or part of a narrative paragraph? Is this heading a section title or a table column header? Getting this wrong leads to extraction errors that are hard to debug and fix.
Challenge 2: Entity Recognition and Disambiguation
Financial documents are full of entities: company names, people, dates, dollar amounts, percentages. An extraction model needs to identify these entities and classify them correctly. This is harder than it sounds because the same text can represent different entities depending on context.
For example, the text "50M USD" could be revenue, EBITDA, enterprise value, or debt. The model needs to use context—the surrounding text, the document structure, the section heading—to disambiguate. This requires sophisticated NLP models, typically based on transformer architectures like BERT or GPT, that can understand context and relationships between entities.
Challenge 3: Handling Missing or Inconsistent Data
Real-world documents are messy. A CIM might be missing a key metric, or it might report the metric in an unusual format. A compliance certificate might use a non-standard definition of EBITDA. An extraction model needs to handle these cases gracefully: either by flagging the missing data for human review or by making a reasonable inference based on available information.
This is where large language models excel. Unlike traditional rule-based extraction systems, LLMs can reason about missing data and make educated guesses. If a CIM does not explicitly state the revenue growth rate but provides revenue figures for two consecutive years, an LLM can calculate the growth rate. If a compliance certificate uses a non-standard EBITDA definition, an LLM can recognize the deviation and flag it for review.

Comparison of single-model AI versus multi-agent systems, showing how specialized agents improve accuracy and reliability for complex workflows.
Why V7 Go Agents Provide a Faster Path
V7 Go takes a different approach to document extraction than traditional custom model development. Instead of asking you to build and train your own models, V7 Go provides pre-configured agents that combine OCR, layout analysis, entity recognition, and LLM reasoning into a single workflow.
These agents are not black boxes. They are built on top of state-of-the-art models (like GPT-4 and Claude) and proprietary V7 technology for visual grounding and citation. When an agent extracts a figure from a document, it shows you exactly where in the source document that figure came from. This makes the extraction process transparent and auditable—critical requirements for private equity workflows where every number needs to be defensible in an investment committee meeting or an LP report.
The agents use your documents as context through Knowledge Hubs and V7's Index Knowledge technology, a proprietary approach to retrieval-augmented generation that provides traceable citations. This is fundamentally different from training a custom model on your data. The underlying LLM does not change. Instead, your documents become searchable context that the agent references when processing new files.
The agents are also configurable. If your firm has specific extraction requirements—say, you always want to extract a particular covenant term or a particular KPI—you can configure the agent to prioritize those fields. This configuration happens through a no-code interface. You define the fields you care about, provide a few examples for context, and the agent applies these configurations when processing documents. No model retraining required.
This approach addresses the three technical challenges described above:
OCR and layout analysis. V7 Go uses a multi-stage OCR pipeline that handles scanned documents, complex tables, and multi-column layouts. The system automatically detects document structure and routes different sections to the appropriate extraction logic.
Entity recognition. V7 Go's agents use LLMs to understand context and disambiguate entities. The system can recognize that "50M USD" in one section refers to revenue while "50M USD" in another section refers to debt, based on surrounding text and document structure.
Missing data. V7 Go agents flag missing or inconsistent data for human review rather than making silent errors. The system provides confidence scores for each extraction, allowing analysts to focus review time on low-confidence fields.
CIM dashboard showing extracted summary data, financial metrics, and structured output ready for analysis or system integration.
Implementation: What to Expect When Deploying AI Agents
Deploying AI agents for private equity workflows is not a plug-and-play process, but it is significantly faster and less resource-intensive than building custom models. Here is what a typical implementation looks like.
Phase 1: Workflow Mapping (1-2 Weeks)
The first step is to map your existing workflows and identify the specific documents and data fields you want to automate. This involves working with your deal team, portfolio monitoring team, and operations team to understand:
What documents do you process regularly? CIMs, compliance certificates, portfolio company reports, pitch decks, legal contracts, environmental reports.
What data fields do you extract from each document type? Be specific. Not just "financial data" but "TTM Revenue in USD, Adjusted EBITDA, EBITDA Margin, YoY Revenue Growth Rate."
What systems do you use to store and analyze the extracted data? Excel, your portfolio monitoring platform, a data warehouse, Salesforce.
What are your accuracy and auditability requirements? Do you need to trace every figure back to its source page? Do you need confidence scores?
This phase is critical because it defines the scope of the automation project and sets expectations for what the agents will and will not do. A common mistake is to try to automate everything at once. A better approach is to start with a single, high-value workflow—say, CIM triage—and expand from there once the initial workflow is proven.
Phase 2: Agent Configuration (1-2 Weeks)
Once you have mapped the workflow, the next step is to configure the agents. With V7 Go, this happens through a no-code interface where you define the data fields you want to extract, provide a few example documents for context, and set up any custom validation rules.
For example, if you are setting up a CIM triage agent, you might define fields like "Company Name," "Revenue," "EBITDA," "Growth Rate," "Sector," and "Geography." You upload a few sample CIMs. The agent uses these as reference examples when processing new documents. You can also define validation rules—for example, "Revenue must be a positive number" or "Sector must be one of the following: Healthcare, Technology, Industrials, Consumer."
This configuration process is iterative. You start with a basic configuration, test it on a few documents, review the results, and refine the configuration based on what you learn. Most firms complete two to three iterations before the agent's performance is satisfactory.
Phase 3: Pilot Testing (2-4 Weeks)
Before rolling out the agents to your entire team, you run a pilot test on a subset of documents. This allows you to validate the agent's accuracy, identify edge cases, and refine the configuration without disrupting your existing workflows.
During the pilot, you run the agent on 20 to 50 documents and compare the extracted data to what you would have extracted manually. You calculate accuracy metrics—precision, recall, F1 score—and identify any systematic errors or biases. You also gather feedback from the analysts who will be using the agents in production: Is the interface intuitive? Are the confidence scores helpful? Are there any missing features or edge cases that need to be addressed?
Based on this feedback, you refine the agent configuration and run a second round of pilot testing. Most firms complete the pilot phase in two to four weeks.
Phase 4: Production Rollout (Ongoing)
Once the pilot is successful, you roll out the agents to your entire team. This involves integrating the agents into your existing workflows—for example, setting up email forwarding rules so that incoming CIMs are automatically routed to the extraction agent, or configuring the agent to pull documents from your cloud storage system.
You also set up monitoring and feedback loops. V7 Go provides dashboards that show agent performance over time: how many documents have been processed, what the average confidence scores are, how many extractions required human review. You use this data to identify areas for improvement and to track the ROI of the automation project.
V7 Go's integration capabilities, showing connections to common enterprise systems for document ingestion and data export.
Security and Deployment Considerations
Private equity firms handle highly sensitive information. Before deploying any AI system, you need to understand the security model.
Data Residency and Processing
Ask where your documents are processed and stored. Cloud-based AI platforms typically process documents on their infrastructure. If you have data residency requirements (EU data must stay in EU), verify that the platform supports regional deployment. V7 Go offers deployment options that address these requirements for enterprise customers.
Access Controls and Audit Logs
Who can access the extracted data? V7 Go's Cases feature provides shareable workspaces with auditable trails. Every action—document upload, extraction, human review, export—is logged with timestamps and user IDs. This is essential for compliance and for reconstructing the data lineage behind any investment decision.
LLM Provider Security
If the platform uses third-party LLMs (like OpenAI or Anthropic), understand the data handling policies. Does the LLM provider retain your documents? Are they used for model training? Enterprise-grade deployments typically include data processing agreements that prohibit retention and training on customer data.
The ROI Calculation: Time Savings and Error Reduction
The business case for AI agents in private equity is straightforward: they save time and reduce errors. But quantifying the ROI requires understanding the baseline—how much time and money you currently spend on manual data processing—and realistic expectations for what automation can achieve.
Cost Model Assumptions
Consider a typical mid-market PE firm with the following profile:
Analyst fully-loaded cost: 150,000 USD per year, or approximately 75 USD per hour.
CIMs received per year: 250.
Time per CIM for manual screening: 40 minutes.
Total annual cost of manual CIM screening: 167 hours × 75 USD = 12,525 USD
With an AI agent, screening time drops to 8 minutes per CIM (mostly review time). Total annual cost: 33 hours × 75 USD = 2,475 USD. Savings: 10,050 USD per year on CIM screening alone.
Now consider covenant monitoring for a private credit fund:
Portfolio companies: 40.
Compliance certificates per quarter: 40.
Time per certificate for manual processing: 18 minutes.
Total annual cost: 48 hours × 75 USD = 3,600 USD.
With an AI agent, processing time drops to 4 minutes per certificate. Total annual cost: 11 hours × 75 USD = 825 USD. Savings: 2,775 USD per year.
For portfolio company reporting consolidation, the savings are larger because the baseline time is higher. If consolidation takes two analyst-days per quarter (64 hours per year), and automation reduces this to half a day per quarter (16 hours per year), the savings are 48 hours × 75 USD = 3,600 USD per year.
Total Cost of Ownership
Add up the savings across all workflows and compare to the platform cost. V7 Go pricing is custom based on usage, but enterprise subscriptions typically run 2,000 USD to 5,000 USD per month for a mid-sized PE firm. Against annual savings of 15,000 USD to 25,000 USD from the workflows above, the payback period is four to six months.
The calculation improves as you automate more workflows. The marginal cost of adding a new workflow is low (configuration time only), while the marginal benefit scales with document volume.
Error Reduction Value
The error reduction benefits are harder to quantify but potentially more valuable. Manual data entry is error-prone. An analyst might misread a number, transpose digits, or copy data from the wrong row of a table. These errors can propagate through your analysis and lead to incorrect investment decisions or compliance violations.
AI agents with visual grounding reduce these errors by automating the extraction process and providing citations for every extracted figure. In practice, firms that deploy AI agents for document extraction report error rates of 2 to 5 percent, compared to manual error rates of 5 to 10 percent. On high-quality native PDFs, error rates can drop below 2 percent. On poor-quality scans, expect higher error rates and more human review.
This improvement in accuracy has downstream benefits: fewer compliance violations, fewer investment committee questions about data discrepancies, fewer LP inquiries about reporting inconsistencies.
The Future: From Extraction to Analysis
The current generation of AI agents focuses primarily on extraction: pulling structured data out of unstructured documents. But the next generation will move beyond extraction to analysis and decision support.
Imagine an AI agent that not only extracts financial metrics from a CIM but also compares those metrics to your firm's investment criteria, flags red flags or inconsistencies, and generates a preliminary investment memo. Or an agent that monitors covenant compliance across your portfolio and proactively alerts you when a borrower is trending toward a breach, along with a recommended action plan.
This shift from extraction to analysis is enabled by advances in large language models and retrieval-augmented generation. Modern LLMs can not only extract data but also reason about it, synthesize information from multiple sources, and generate coherent narratives. When combined with domain-specific knowledge—your firm's investment criteria, your portfolio company data, your historical deal performance—these models can provide decision support that goes far beyond simple data extraction.
V7 Go is already moving in this direction with features like Cases and the AI Concierge. Cases allow you to organize documents and extracted data around a specific deal or portfolio company, creating a shared workspace where your team can collaborate and the AI can provide context-aware insights. The AI Concierge acts as an orchestrator: users express goals naturally, and the Concierge selects and runs the appropriate specialized agents, then synthesizes their outputs into a coherent analysis.
V7 Go's Concierge interface showing the Ask Go bar, agent grid, and intelligent task routing for complex workflows.
Key Takeaway
If you deploy AI agents for your private equity workflows, here is what changes for your team:
For analysts: Instead of spending hours copying data from PDFs into Excel, you spend that time investigating the three anomalies the AI flagged in the footnotes. You decide whether those anomalies represent material risks to the investment thesis. Your work shifts from data entry to judgment.
For portfolio managers: Instead of waiting three days after quarter-end for your team to consolidate portfolio company reports, you have the consolidated data within hours. You spend your time analyzing trends and identifying portfolio companies that need attention, not chasing missing data.
For compliance officers: Instead of manually reviewing 40 compliance certificates every quarter, you review the five that the AI flagged as potential covenant breaches. You have more time to investigate those cases thoroughly and to work with borrowers on remediation plans.
For managing directors: Investment committee meetings start with verified data, not "I think this is right but let me double-check." The audit trail exists if an LP ever asks how you arrived at a valuation or why you flagged a particular risk.
The common thread is that AI agents do not replace human judgment. They eliminate the manual work that prevents humans from exercising that judgment effectively. The bottleneck in private equity is not a lack of smart people. It is the volume of unstructured data those smart people need to process before they can do their jobs.
If you remember nothing else, remember this: start with one workflow. Pick the task where you spend the most time on data entry and the least time on analysis. Prove the value there first. Then expand.
To see how V7 Go can automate your document-heavy workflows—from CIM triage to portfolio monitoring—book a demo and bring a few sample documents from your current deal flow.

What is the difference between predictive models and extraction models in private equity?
Predictive models forecast future outcomes (like portfolio company revenue growth or exit multiples) based on historical numerical data. They require structured, time-series data and are used for portfolio performance analysis. Extraction models pull structured data out of unstructured documents like CIMs, contracts, and financial reports. They use OCR, NLP, and LLMs to automate the manual data entry that currently consumes analyst time. Most PE firms need extraction models more urgently than predictive models because the bottleneck is getting data into a usable format, not forecasting future performance.
+
Should we build custom machine learning models or use pre-built AI agents?
Build custom models only if you have a narrow, repeatable process with consistent document formats, in-house ML expertise, and at least 500 to 1,000 labeled documents for training. Most PE firms should use pre-built AI agents because they invest across multiple sectors with high document variability, lack in-house data science teams, and need to deploy automation quickly. Platforms like V7 Go provide extraction accuracy comparable to custom models without the engineering overhead or ongoing maintenance costs.
+
How accurate are AI extraction models for financial documents?
Modern AI agents typically achieve 90 to 95 percent field-level accuracy on high-quality, native PDFs. Accuracy drops on scanned documents, poor-quality images, or documents with unusual layouts. The key to production reliability is visual grounding and citations: the agent shows you exactly where in the source document each extracted figure came from, allowing you to verify the extraction in seconds. For edge cases or low-confidence extractions, the agent flags the field for human review rather than making a silent error. Expect to review 10 to 20 percent of extractions manually in typical production deployments.
+
How long does it take to deploy AI agents for private equity workflows?
A typical deployment takes 4 to 8 weeks from initial workflow mapping to production rollout. This includes 1 to 2 weeks for workflow mapping, 1 to 2 weeks for agent configuration, 2 to 4 weeks for pilot testing, and ongoing refinement after production launch. This is significantly faster than building custom models, which typically takes 6 to 12 months including data labeling, model training, and integration. The faster deployment time is one of the main advantages of pre-built AI agents over custom development.
+
Can AI agents handle documents they have never seen before?
The ROI depends on your document volume and current manual processing time. For CIM triage, firms typically save 130+ analyst hours per year by reducing screening time from 40 minutes to under 10 minutes per CIM. For covenant monitoring, the time savings are 35 to 40 hours per year. For portfolio company reporting, firms save 45 to 50 hours per year by automating data consolidation. Beyond time savings, AI agents reduce error rates from 5 to 10 percent (manual) to 2 to 5 percent (automated), which can prevent costly compliance violations or investment mistakes. Most firms see payback within 4 to 6 months when factoring in platform costs versus analyst time savings.
+
What is the ROI of deploying AI agents for private equity workflows?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

