Knowledge work automation
21 min read
—


A practitioner's guide to AI document processing in asset management. How firms are moving from manual Excel reconciliation to automated extraction workflows.

If you ask a General Partner at a mid-sized private equity firm where their portfolio data lives, they will point to a logo on a slide deck: eFront, Investran, Allvue. But if you ask the Vice President of Finance where the actual data lives, the data used to answer an urgent LP question at 8 PM on a Tuesday, they will point to Microsoft Excel.
This is still the reality of asset management in 2025. Despite a projected market growth from USD 3.68 billion in 2023 to USD 17.01 billion by 2030, according to Grand View Research, the industry's backbone remains a fragile mesh of spreadsheet workbooks, manual data entry, and offshore BPO teams re-keying figures from scanned PDFs.
The bottleneck is not the ledger. Modern portfolio management systems handle accounting logic well. The bottleneck is getting clean data into the ledger. When a quarterly report arrives as a 200-page PDF with tables spanning multiple pages, handwritten amendments, and footnotes explaining three different EBITDA calculations, someone has to read it, extract the numbers, and validate them against prior periods. That someone is usually an analyst with a VLOOKUP-heavy Excel file and a deadline that passed yesterday.
In this article:
The Intelligence Layer Problem: Why traditional OCR fails on real-world data rooms and what modern AI extraction actually solves.
Software Landscape: Comparing modern AI challengers (V7 Go, Nanonets, HyperScience) against legacy incumbents (SAP, Oracle, eFront).
Implementation Reality: Build versus buy economics, cloud versus on-premise tradeoffs, and what actually works in production.
V7 Go Workflows: Concrete examples of agentic extraction for CIMs, quarterly reports, and compliance documents.

AI for document processing
Move your team off manual data room reconciliation
Get started today
Why Asset Management Data Extraction Fails
The asset management industry has a data ingestion problem disguised as a software problem. Firms spend millions on portfolio management systems, but the systems only work if you can feed them clean, structured data. The reality is that most investment data arrives in formats designed for human reading, not machine parsing.
The Multi-Modal Data Room Challenge
A typical private equity data room contains documents that no single tool handles well. You will find scanned financial statements with tables that span multiple pages, where the header appears on page one and the data continues on page three. Excel files arrive with hidden tabs, merged cells, and formulas that reference external workbooks nobody can locate. Investment memos come as PDFs with embedded charts that look sharp on screen but convert to garbled pixels when processed.
One private equity analytics firm described the challenge in stark terms during a recent call: "We have 1,000 to 1,500 data points per data room. Not just revenue and EBITDA, but EBITDA from inception to exit for each deal, broken out by fiscal year, last twelve months, budget, and forecast. Each has a reference date. Some get updated in later quarterly reports. There is a lot of context that matters beyond just '2023 EBITDA.'"
Traditional OCR tools fail on this content because they treat documents as flat images. They can recognize text, but they cannot understand structure. When a balance sheet spans three pages with subtotals on page two and a footnote on page three explaining an adjustment, OCR gives you three disconnected text blocks. A human analyst still has to reconstruct the logic.
Modern data rooms contain thousands of unstructured documents. The challenge is not storage but extraction.
The Current Solution: Manual Reconciliation
Most firms handle this through one of three approaches, none of which scale.
In-House Analysts: Junior team members spend 60-70% of their time on data entry. They open PDFs, copy figures into Excel, cross-reference against prior quarters, and flag discrepancies. A single quarterly reporting cycle for a 20-company portfolio can consume 80+ analyst hours. One analyst described the process as "reading the same 50-page PDF four times because you are not sure if that EBITDA figure in the footnote supersedes the one in the summary table."
Offshore BPO Teams: Firms outsource extraction to teams in India or the Philippines. This reduces cost but introduces latency of 24-48 hour turnarounds and quality issues that compound over time. BPO teams follow rigid templates and struggle with non-standard documents or nuanced footnotes. When a GP uses a different format for their quarterly report, the offshore team marks it as an exception and it sits in a queue.
Legacy OCR with Manual Cleanup: Tools like ABBYY or Kofax extract text, but analysts still spend hours validating outputs, fixing table structures, and reconciling figures that the OCR misread or split incorrectly. The extraction is fast; the cleanup is not.
According to Grand View Research, AI process automation software for asset management is projected to reach USD 17 billion by 2030. The reason is simple: firms are desperate to escape the manual reconciliation trap. The question is which approach actually works.
V7 Go's agent library showing pre-built workflows for document processing and batch analysis.
What Modern AI Actually Solves in Asset Management
The breakthrough in 2024-2025 is not better OCR. It is the combination of computer vision, large language models, and agentic workflows that can understand document structure, extract context-aware data, and provide traceable citations. This changes what is possible.
Multi-Modal Computer Vision
Modern AI platforms use computer vision models trained on millions of financial documents. These models do not just read text. They understand layout. They recognize that a table header on page one governs data on page three. They identify footnotes, cross-references, and embedded charts.
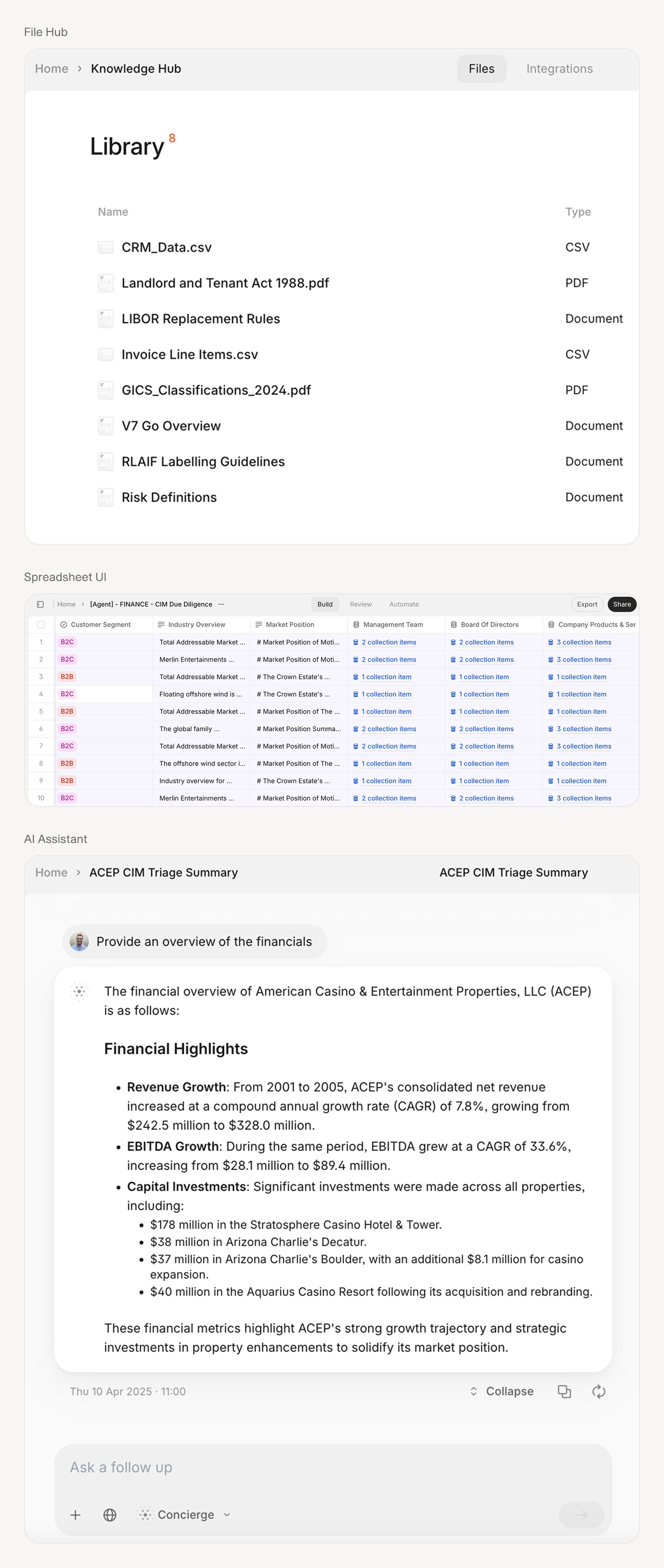
V7 Go's approach uses visual grounding: when the system extracts a figure like "EBITDA: $12.3M," it draws a bounding box around the source location in the PDF. This means analysts can verify extraction accuracy in seconds rather than re-reading entire documents. During a product demo, one solutions engineer explained the value: "If we cannot put a bounding box around the source, we tell you. We do not hallucinate and give you garbage data."
This citation capability addresses a core problem with RAG systems and generic LLM wrappers: they can generate plausible-sounding answers from context, but you cannot trace where the answer came from. For audit trails and LP reporting, traceability is non-negotiable.
Visual grounding allows analysts to verify extracted data by seeing the exact source location in the original document.
Context-Aware Extraction with LLMs
Large language models add semantic understanding to the extraction process. When a quarterly report lists three different EBITDA figures, budget, actual, and forecast, an LLM can distinguish between them based on surrounding context. It understands that "Adjusted EBITDA" in a footnote refers to the figure on the previous page, not a new metric.
This matters because financial documents are dense with cross-references, adjustments, and non-standard terminology. A pure OCR tool sees "EBITDA" five times and extracts five numbers without understanding which one represents the current period's actual performance. An LLM understands that the footnote on page twelve modifies the summary table on page three.
The key is structuring outputs properly. Most extraction workflows fail because they try to dump everything into a flat CSV. The better approach is to use JSON objects that preserve the relationships between data points. For example, instead of extracting "EBITDA: $12.3M" as a single field, you extract an object that includes the period (Q3 2024), the type (Adjusted), the source (Management Commentary, page 12), and the calculation basis (excluding one-time restructuring charges).
Agentic Workflows for Validation
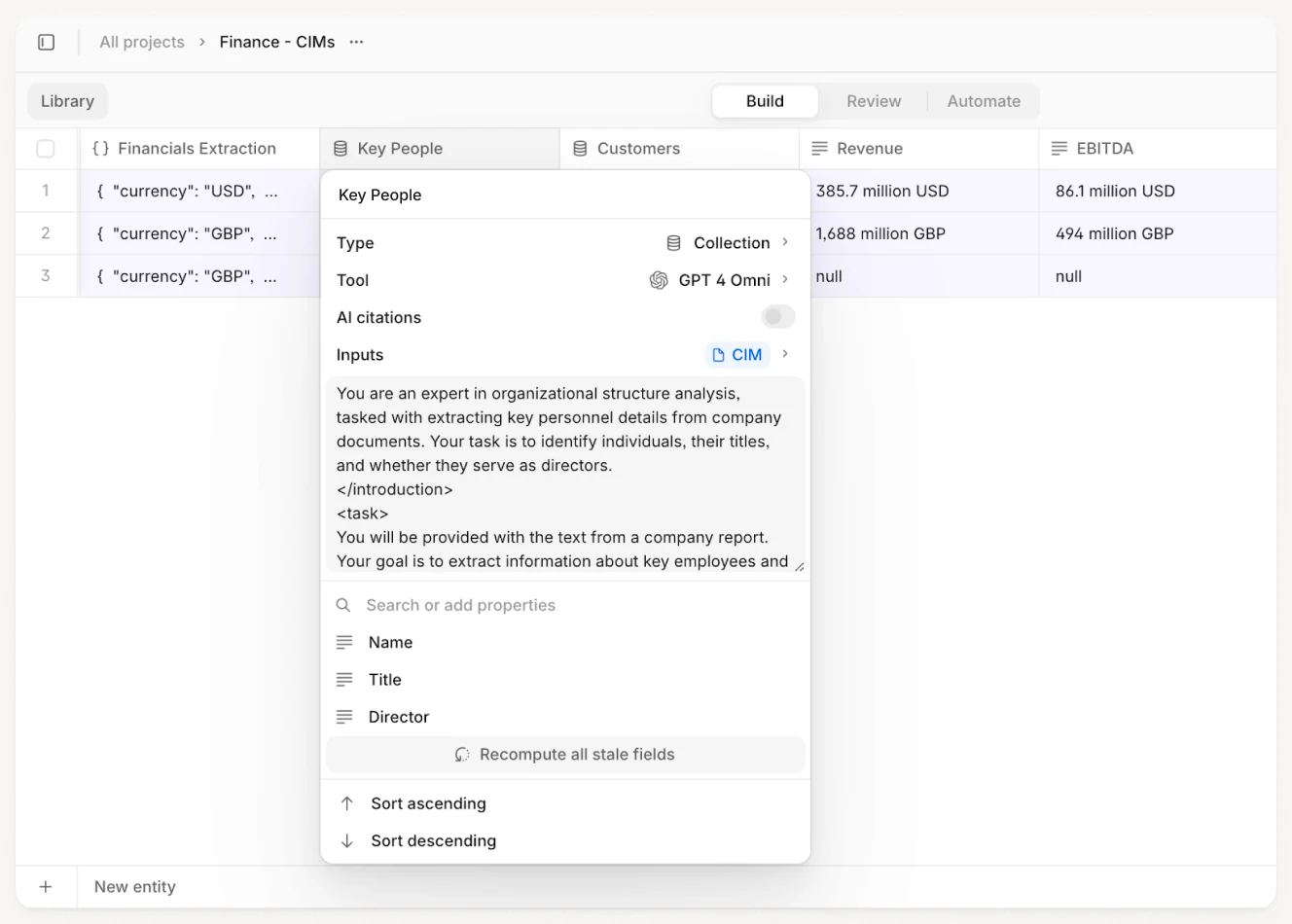
The final piece is workflow automation. Instead of extracting data into a generic file, modern platforms use agents, which are specialized AI workers that perform specific tasks in sequence.

A Financial Statement Analysis Agent might execute this workflow: ingest a quarterly report PDF, extract revenue, EBITDA, and net income for the current and prior period, calculate quarter-over-quarter growth rates, flag any figures that deviate more than 20% from forecast, and generate a structured JSON output with citations for each extracted field.
This agent runs in minutes, not hours, and produces output that can be directly imported into a portfolio management system or fed into downstream analytics. The critical difference from generic chatbots is that agents follow predefined steps. They do not improvise. This makes their outputs predictable and auditable.
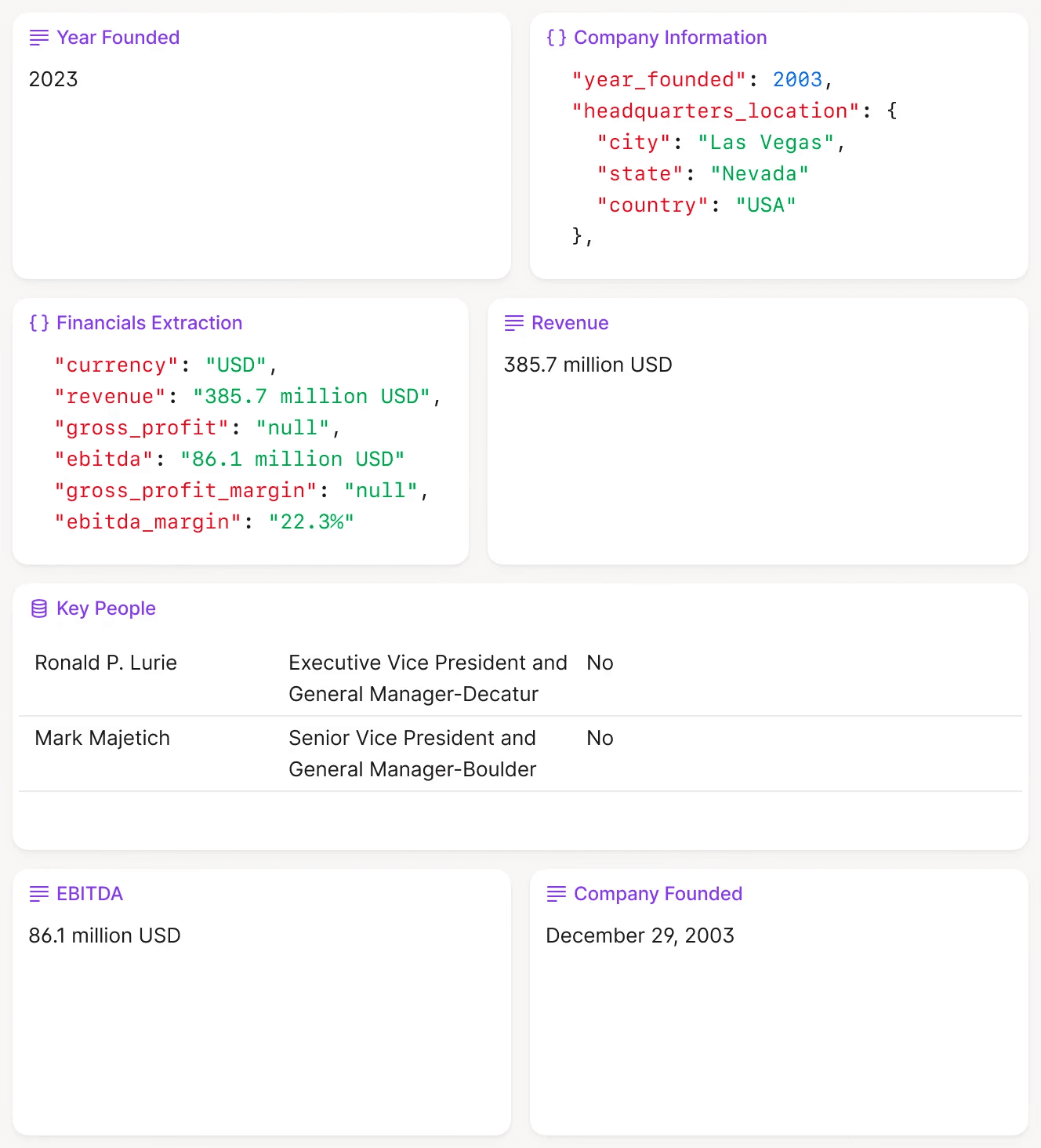
Structured data extraction with JSON output ready for database import. Each field includes source citations.
AI Asset Management Software: The Build vs. Buy Decision
Asset managers face a critical choice: build an in-house AI extraction capability or adopt a platform like V7 Go, Nanonets, or HyperScience. The economics of each path are clearer than they were two years ago.
The Case for Building
Some firms, particularly those with large technology teams, choose to build custom solutions. The argument is control: you can tailor the system to your exact document types, integrate deeply with proprietary databases, and avoid vendor lock-in.
A realistic build scenario looks like this. You need two computer vision engineers to train and maintain OCR models. You need one LLM engineer to fine-tune models for financial terminology. You need one data engineer to build pipelines and manage the database schema. You need half of a DevOps FTE to manage infrastructure, scaling, and monitoring.
Year one cost, including salaries, benefits, compute, and infrastructure: approximately $900,000. Ongoing maintenance after year one: approximately $350,000 per year. Timeline to first stable release: 12-18 months. Risk: the system becomes brittle when document formats drift or when the engineers who built it leave.
For a firm managing $5B+ in assets with a dedicated technology budget and a long-term horizon, building can make sense. The key question is whether document extraction is a core differentiator for your firm or a cost center you need to minimize.
The Case for Buying
Modern AI platforms offer pre-trained models, pre-built agents, and managed infrastructure. V7 Go provides out-of-the-box agents for common document types: CIMs, financial statements, compliance reports. It includes visual grounding and citation features that would take months to build internally. API integrations allow extracted data to flow directly into existing databases. Continuous model updates happen without requiring in-house ML expertise.
A realistic buy scenario: platform subscription of $120,000-$250,000 per year based on document volume. Integration sprint of 4-8 weeks to connect to your existing systems. Payback period of 3-6 months for teams processing 500+ documents per quarter.
The tradeoff is flexibility. Platform solutions work best when your documents fit common patterns. If your firm processes highly specialized document types with unique structures, you may need custom configuration or a hybrid approach where the platform handles 80% of documents and your team handles the remaining 20% manually.
CIM due diligence workflow using Cases. The interface shows extracted fields, entity analysis, and source citations in a single view.











Software Landscape: Modern AI vs. Legacy Systems
The asset management software market is bifurcating. On one side are legacy ERP and portfolio management systems that excel at accounting logic but struggle with data ingestion. On the other side are modern AI platforms that specialize in document processing but require integration with downstream systems. Understanding this landscape helps you architect the right stack.
Modern AI Challengers
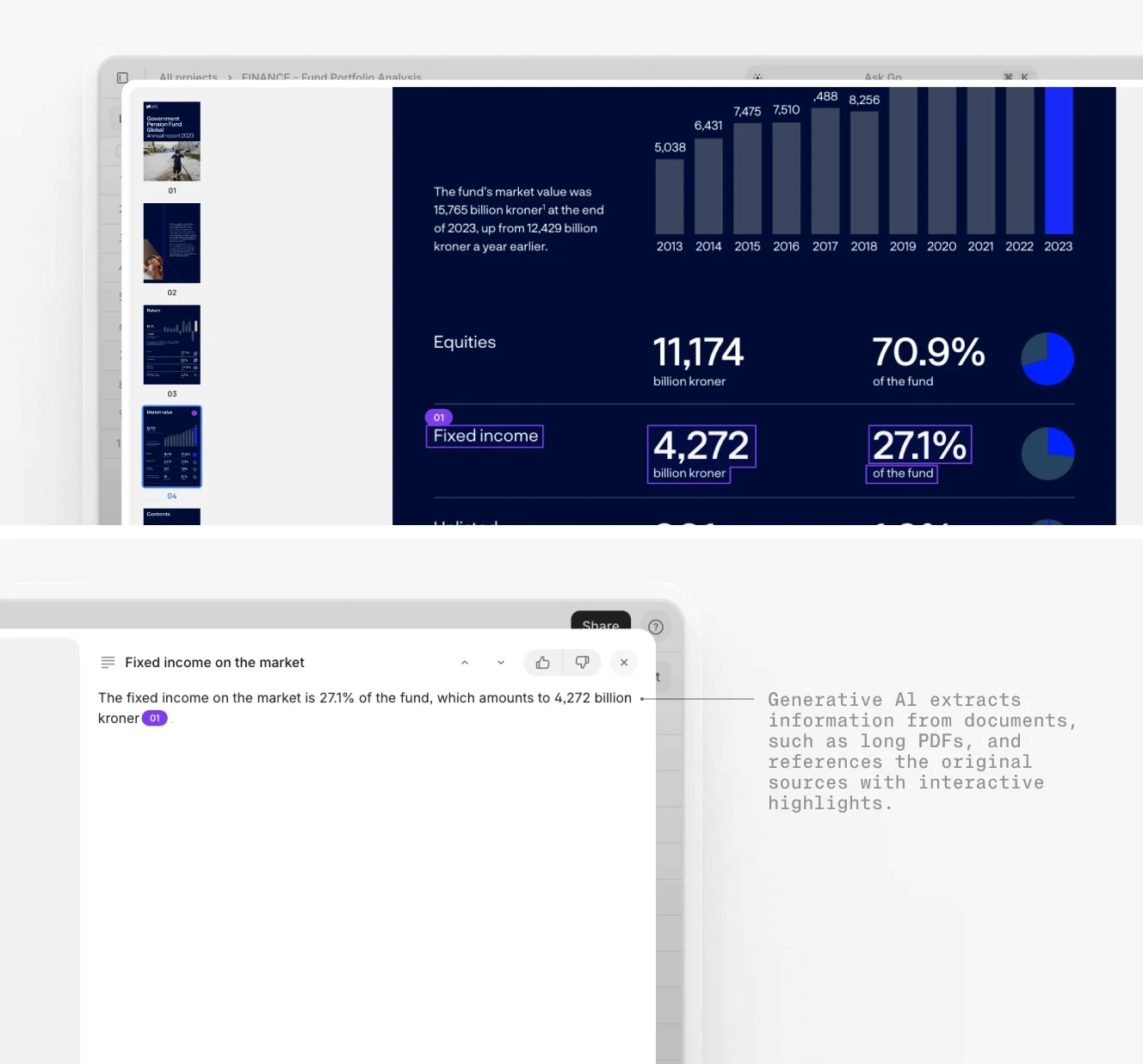
V7 Go is the intelligence layer for asset management workflows. Its core strength is multi-modal extraction with visual grounding. When you upload a CIM or quarterly report, V7 Go does not just extract text. It provides bounding boxes showing exactly where each figure came from. This is critical for audit trails and LP reporting where you need to trace every number back to its source.
Key capabilities include pre-built agents for CIM analysis, financial statement extraction, and due diligence workflows. Knowledge Hubs allow agents to reference firm-specific playbooks and historical data, so they understand your terminology and preferences. API integrations support direct database writes to PostgreSQL, Snowflake, and similar platforms.
Pricing is custom and enterprise-focused, typically based on document volume. Firms report 70-90% reduction in manual extraction time, with payback periods of 3-6 months for teams processing 500+ documents per quarter. User feedback from G2 and similar platforms highlights the accuracy of extraction and strong multi-modal capability. The main criticism is a steeper learning curve for non-technical users during initial rollout.
Automated extraction of key personnel data from investment memorandums.
Nanonets focuses on high-accuracy automation for repetitive document types. It works well for firms with standardized reporting formats, for example, a real estate fund that receives the same lease abstraction template from every property manager. Fast processing times and easy API integration make it suitable for high-volume workflows. Users report occasional accuracy issues on complex financial tables with non-standard layouts.
HyperScience targets enterprise-scale deployments with adaptive learning. The system improves over time as it processes more documents from your firm. This makes it suitable for large asset managers with diverse document types. Higher implementation costs and longer onboarding cycles of often 3-6 months are the main tradeoffs.
Rossum specializes in invoice and unstructured document processing. It is less common in asset management but used by some firms for expense processing and vendor invoice reconciliation. The interface is intuitive and requires minimal manual corrections, but customization options are limited for complex multi-page financial documents.
Legacy Incumbents
SAP and Oracle dominate the enterprise ERP market. Both offer asset management modules with strong accounting capabilities, compliance tools, and integration with existing financial systems. The challenge is data ingestion. These systems assume clean, structured data arrives at their doorstep. They do not provide native AI extraction.
Firms using SAP or Oracle typically pair them with third-party extraction tools or manual data entry processes. The strength is deep integration and comprehensive feature sets. The weakness is high total cost of ownership and slow adoption of modern AI capabilities.
Yardi is the dominant platform for real estate asset management. It offers property-specific workflows, integrated lease management, and financial reporting. For real estate funds, Yardi is often the system of record. However, it still requires manual data entry for lease abstracts, rent rolls, and property operating statements. Some firms now use AI extraction tools like V7 Go to feed Yardi rather than replacing it.
eFront specializes in alternative asset management including private equity, venture capital, and real estate. It provides end-to-end investment cycle management, detailed performance reporting, and LP portal functionality. eFront's strength is its deep understanding of alternative asset workflows. Its weakness is the same as other legacy systems: it assumes you can get clean data into the platform. Firms often use offshore teams or manual processes to prepare data for eFront import.
Asset Management Solutions: Implementation Reality& What Actually Works
The gap between vendor demos and production reality is significant. Here is what practitioners report from real implementations and how to avoid common failure modes.
Success Pattern: Start with High-Volume, Standardized Documents
The most successful AI extraction projects start narrow. Instead of trying to automate all document processing on day one, firms identify one high-volume, high-pain workflow and prove value there first.
Example: A mid-market PE firm processes 50 quarterly reports per quarter. Each report follows a similar format with income statement, balance sheet, cash flow, and management commentary. An analyst spends 2-3 hours per report extracting key metrics into Excel, checking them against prior quarters, and flagging variances for the investment team.
Implementation approach: Deploy a Financial Reporting Agent configured to extract revenue, EBITDA, net income, and debt levels. The agent processes all 50 reports in under an hour with 95%+ accuracy on standard fields. Analysts spend their time reviewing the 5% of fields flagged for human review rather than re-keying the 95% that extracted correctly.
Result: Analyst time drops from 150 hours to 20 hours per quarter. The 20 hours are spent on reviewing and validating agent outputs, not copying numbers. Payback period: 2 months.
Failure Pattern: Trying to Automate Everything at Once
The most common failure mode is scope creep. Firms try to build a universal extraction system that handles every document type simultaneously: CIMs, quarterly reports, compliance filings, legal agreements, tax documents. The pilot balloons from a focused 4-week sprint into an 18-month transformation program.
This fails because each document type has different structure, terminology, and validation requirements. A system optimized for financial statements will struggle with legal contracts. A system trained on CIMs will miss nuances in compliance reports.
Better approach: Deploy specialized agents for specific document types. Use V7 Go's agent library to configure separate workflows for CIM analysis, quarterly reporting, and compliance processing. Each agent is tuned for its specific task. Expand to new document types only after the first workflow is stable in production.
Batch processing of 10-Q filings showing automated extraction and table population.
The Integration Challenge
AI extraction is only valuable if the data flows into your existing systems. This requires API integration, data validation, and error handling that many firms underestimate during procurement.
V7 Go addresses this through its agent framework. After extraction, an agent can validate extracted data against business rules, for example, EBITDA should be positive, revenue growth should be within -50% to +200%. It can write structured JSON to a PostgreSQL database, trigger downstream workflows like sending a Slack notification if a covenant is breached, and generate audit logs with citations for every extracted field.
"We have agents that pull from the data room, extract the metrics we care about, validate against our schema, and write directly to our database. From there, our PowerBI dashboard auto-refreshes. The analyst is not in the middle copying things around. They review the dashboard and investigate the anomalies the agent flagged."
This end-to-end automation is what separates modern AI platforms from legacy OCR tools. OCR gives you text files. AI agents give you validated, structured data that supports decisions.

Automated reconciliation and discrepancy detection across financial documents.
V7 Go in Practice: Concrete Workflows
To make this concrete, here are three real-world workflows that asset management firms are deploying with V7 Go.
Workflow 1: CIM Triage for Deal Screening
A venture capital firm receives 200+ CIMs per quarter. Partners want to quickly identify companies that meet investment criteria, for example, SaaS companies with $5M+ ARR and 40%+ gross margins.
Traditional process: Analysts read each CIM, extract key metrics into a spreadsheet, flag companies for partner review. Time: 30-45 minutes per CIM.
V7 Go workflow: Upload CIM to V7 Go. A Deal Screening Agent extracts company name, sector, revenue, ARR, gross margin, and funding history. The agent applies investment criteria filters. It generates a one-page summary with pass/fail recommendation and citations. Output flows to Airtable for partner review.
Result: Processing time drops to 5 minutes per CIM. Partners review only the 15-20 companies that pass initial screening. Analyst time reallocates to deeper due diligence on qualified opportunities.
Workflow 2: Quarterly Portfolio Reporting
A private equity firm manages 25 portfolio companies. Each company submits a quarterly report spanning 15-30 pages with financial statements, KPI dashboards, and management commentary.
Traditional process: Analysts extract revenue, EBITDA, headcount, and customer metrics into a master Excel file. They cross-reference against budget and prior quarters. Time: 3-4 hours per company, or 100+ hours per quarter.
V7 Go workflow: Portfolio companies upload reports to a shared folder. A Financial Reporting Agent processes all 25 reports in parallel. The agent extracts standardized metrics and calculates variance vs. budget and prior quarter. It flags any company with greater than 20% variance or negative cash flow. Structured data writes to PostgreSQL. PowerBI dashboard auto-refreshes with latest portfolio metrics.
Result: Analyst time drops from 100 hours to 15 hours per quarter. Those 15 hours focus on reviewing flagged variances, not re-keying numbers. Portfolio-level insights are available within 24 hours of report submission instead of 5-7 days.
Workflow 3: Compliance Document Processing
A real estate fund must track compliance certificates for 50+ properties. Each property submits quarterly certificates confirming adherence to loan covenants, including debt service coverage ratio, occupancy rate, and capital expenditure limits.
Traditional process: Analysts read each certificate, extract covenant metrics, compare against loan agreements, flag potential breaches. Time: 1-2 hours per property, or 75+ hours per quarter.
V7 Go workflow: Property managers upload compliance certificates. A Compliance Reporting Agent extracts DSCR, occupancy, and CapEx spend. The agent references the loan agreement stored in a Knowledge Hub. It compares reported metrics against covenant thresholds. It flags any property within 10% of covenant breach. An alert is sent to the asset management team with citation showing the exact clause and reported figure.
Result: Compliance review time drops from 75 hours to 10 hours per quarter. Early warning system catches potential breaches before they occur, giving portfolio managers time to work with the property on remediation.

End-to-end financial analysis workflow from document ingestion to structured output.
The Cloud vs. On-Premise Debate
Asset managers handling sensitive financial data face a critical decision: cloud-based AI platforms or on-premise deployments. The answer depends on your regulatory constraints and operational requirements.
The Cloud Advantage
Cloud platforms offer faster deployment, automatic updates, and lower infrastructure costs. Grand View Research reports that cloud-based solutions represented 57.3% of the AI in asset management market in 2023, driven by cost efficiency and scalability.
For most firms, cloud deployment makes sense. Modern platforms like V7 Go provide enterprise-grade security, including SOC 2 Type II certification, ISO 27001, and GDPR compliance, with encryption in transit and at rest. Data residency options allow firms to keep sensitive information in specific geographic regions.
The practical benefit is speed. A cloud deployment can be live in days. An on-premise deployment requires procurement cycles, infrastructure setup, and ongoing maintenance that stretches timelines to months.
The On-Premise Case
Some firms, particularly those managing sovereign wealth funds or handling highly regulated assets, require on-premise deployments. Concerns include data sovereignty requirements where data must remain in specific countries, regulatory restrictions on cloud processing of certain document types, and internal security policies that prohibit external data processing entirely.
Hybrid Deployment Patterns
V7 Go and other modern platforms offer hybrid deployments that balance security requirements with operational efficiency. Two patterns work well in practice.
Pattern A: On-premise extraction with cloud hub. Sensitive PDFs remain on-premise. Extraction models run in your data center. Only embeddings and structured JSON leave the perimeter for indexing in a cloud Knowledge Hub. This keeps raw documents inside your firewall while enabling cloud-based search and retrieval.
Pattern B: Private VPC with customer-managed keys. The platform runs in a private virtual cloud peered to your network. Customer-managed encryption keys ensure that even the platform vendor cannot access raw document content. All audit logs export to your SIEM for monitoring.
The right pattern depends on your compliance requirements. Most firms find that cloud with SOC 2 controls meets their needs. Firms with specific regulatory constraints like SEC Rule 17a-4 or GDPR Article 28 requirements may need hybrid approaches.
Measuring ROI: What to Track
Asset managers evaluating AI extraction platforms should track specific metrics to justify investment and guide optimization.
Time Savings: Hours spent on manual data entry before vs. after implementation. Target: 70-90% reduction for standardized documents.
Example calculation: Baseline: 150 analyst hours per quarter at $110/hour fully loaded cost equals $16,500. Post-automation: 20 hours per quarter equals $2,200. Quarterly savings: $14,300. Annual savings: $57,200.
Accuracy Rate: Percentage of extracted fields that require no manual correction. Target: 95%+ for standard financial metrics, 85%+ for complex or non-standard fields.
Processing Speed: Time from document receipt to data availability in downstream systems. Target: same-day processing for quarterly reports, under 1 hour for urgent requests.
Error Reduction: Decrease in data entry errors that require correction or restatement. Manual processes typically have 2-5% error rates. AI extraction should reduce this to under 0.5%.
Analyst Reallocation: Hours freed up for higher-value work including due diligence, portfolio company support, and LP communication. This is often more valuable than direct cost savings because it improves the quality of investment decisions.

Performance comparison of different AI models for financial document processing tasks.
Common Pitfalls and How to Avoid Them
As organizations adopt AI extraction, several recurring obstacles tend to surface. The following pitfalls illustrate where implementations most often go off-track and what to do instead.
Pitfall 1: Underestimating Change Management
AI extraction changes how analysts work. Some will resist, viewing it as a threat to their role rather than a tool that eliminates tedious work. Successful implementations involve analysts in configuration and validation from day one. Position AI as a tool that frees them for analysis, not a replacement for their judgment.
Pitfall 2: Ignoring Edge Cases
AI extraction works well on standard documents but struggles with edge cases: handwritten amendments, documents in multiple languages, tables with unusual formatting. Build review workflows for flagged documents rather than assuming 100% automation. Plan for 5-10% of documents to require human review.
Pitfall 3: Lack of Validation Workflows
Even 95% accuracy means 1 in 20 fields is wrong. For critical metrics like covenant compliance, LP capital calls, and audited figures, implement validation workflows where analysts review extracted data before it flows to downstream systems. The goal is not to eliminate human review but to focus it where it matters.
Pitfall 4: Poor Integration Planning
Extraction is only valuable if data reaches decision-makers. Plan API integrations, database schemas, and downstream workflows before deployment. V7 Go's agent framework helps here by allowing you to define the entire workflow, from extraction to database write to notification, in a single configuration.
The Future: From Extraction to Intelligence
The current wave of AI in asset management focuses on extraction, getting data out of documents and into systems. The next wave will focus on intelligence, using that data to generate insights, identify patterns, and support decision-making.
Predictive Analytics on Extracted Data
Once you have clean, structured data flowing from quarterly reports, you can build predictive models. Identify portfolio companies likely to miss budget based on early-quarter trends. Predict covenant breaches 2-3 quarters in advance based on trajectory analysis. Flag companies with deteriorating unit economics before problems appear in headline metrics.
This requires combining AI extraction with traditional ML models. V7 Go provides the extraction layer. Firms build predictive models on top using tools like Python, R, or specialized analytics platforms.
Natural Language Querying
The next frontier is natural language interfaces to portfolio data. Instead of building SQL queries or Excel pivot tables, analysts will ask questions in plain English. "Which portfolio companies grew revenue faster than 20% last quarter?" "Show me all companies with EBITDA margins below 15% and declining headcount." "What is our total exposure to companies with more than 50% revenue from a single customer?"
V7 Go's Knowledge Hub feature enables this by indexing extracted data and allowing natural language queries with citations back to source documents. The Concierge routes questions to the right agent automatically, so analysts do not need to know which workflow to trigger.
Automated LP Reporting
Limited Partners increasingly demand detailed, frequent reporting. AI extraction enables automated LP report generation. Extract portfolio company metrics from quarterly reports. Aggregate to fund level. Generate performance attribution analysis. Create narrative commentary using LLMs. Produce formatted PDF reports with charts and tables.
This shifts LP reporting from a quarterly burden to an automated process that runs continuously as new data arrives.

Deep dive into Knowledge Hubs and Index Knowledge for advanced document intelligence.
Key Takeaway
If you implement AI extraction this quarter, here is what changes for your team.
For Analysts: Instead of spending 60% of your time copying numbers from PDFs into Excel, you spend 20% reviewing and validating AI outputs. The other 40% goes to actual analysis: investigating variances, building models, supporting portfolio companies. Your value shifts from data entry to data interpretation.
For Portfolio Managers: You get portfolio-level insights within 24 hours of quarter-end instead of waiting a week for analysts to finish data entry. You can ask ad-hoc questions and get answers in minutes, not days. When an LP calls with a question about sector exposure, you can answer during the call instead of promising to get back to them.
For CFOs: You reduce reliance on offshore BPO teams and manual processes that create audit risk. You have traceable citations for every figure in LP reports. You can scale reporting without scaling headcount.
For LPs: You get more frequent, more detailed reporting. You can drill down from fund-level metrics to individual portfolio company performance with full transparency into data sources.
The firms that move first on AI extraction will not just save time. They will build information advantages that compound over time. Better data leads to better decisions. Better decisions lead to better returns. Better returns lead to more capital and more opportunities.
To see how V7 Go can automate your document extraction workflows, from CIMs to quarterly reports to compliance certificates, book a demo.

What is the difference between traditional OCR and AI document extraction?
Traditional OCR converts images of text into machine-readable text. It works well for clean, typed documents but struggles with complex layouts, tables spanning multiple pages, or handwritten content. AI document extraction combines OCR with computer vision and large language models to understand document structure, context, and relationships between data points. For example, an AI system can recognize that a footnote on page three explains an adjustment to a figure on page one, whereas traditional OCR treats them as unrelated text blocks.
+
How accurate is AI extraction for financial documents?
Accuracy depends on document quality and standardization. For well-formatted financial statements with clear tables, modern AI platforms achieve 95-98% accuracy on standard fields like revenue, EBITDA, and cash. For complex documents with handwritten amendments, non-standard formatting, or multi-page tables, accuracy drops to 85-90%. The key is implementing validation workflows where analysts review extracted data before it flows to downstream systems. V7 Go's visual grounding feature helps by showing analysts exactly where each figure came from, making validation much faster than re-reading entire documents.
+
Can AI extraction handle documents in multiple languages?
Yes, modern AI platforms support multi-language extraction. V7 Go can process documents in 50+ languages. However, accuracy is highest for English, and performance varies by language. For asset managers with international portfolios, the best approach is to configure separate agents for different language groups and implement language-specific validation workflows. Some firms use AI translation as a pre-processing step, though this can introduce errors if financial terminology is not translated correctly.
+
How long does it take to implement AI extraction?
Implementation time varies by scope. For a focused use case like extracting key metrics from quarterly reports, deployment can take 2-4 weeks: one week for configuration and testing, 1-2 weeks for integration with existing systems, one week for analyst training and validation workflow setup. For enterprise-wide deployments covering multiple document types and complex integrations, expect 2-3 months. The fastest path is to start with one high-volume, high-pain workflow, prove ROI, then expand to additional use cases.
+
What happens when the AI extraction is wrong?
Pricing models vary by vendor. V7 Go and similar platforms typically charge based on document volume, per page processed or per document, with enterprise pricing for high-volume users. For a mid-market PE firm processing 5,000 pages per quarter, annual costs might range from $20,000-$50,000. Compare this to the cost of manual processing: if analysts spend 200 hours per quarter on data entry at a fully-loaded cost of $100/hour, that is $80,000 per year in labor costs alone.
+
How much does AI document extraction cost?
Go is more accurate and robust than calling a model provider directly. By breaking down complex tasks into reasoning steps with Index Knowledge, Go enables LLMs to query your data more accurately than an out of the box API call. Combining this with conditional logic, which can route high sensitivity data to a human review, Go builds robustness into your AI powered workflows.
+
Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

