Document processing
12 min read
—

Your guide to evaluating and implementing AI that reads, understands, and extracts data from the documents your business runs on, from invoices to contracts to reports.

Picture this: an analyst is spending hours manually copying line items from hundreds of PDF invoices into a spreadsheet. The work is monotonous, the risk of typos is high, and every minute spent on data entry is a minute not spent on strategic analysis (or, to be frank, more interesting work).
This scenario is less than ideal, and all too common. According to Gartner, unstructured data, much of it in formats like PDFs, accounts for 80% of all enterprise data.
This inefficiency stems from a fundamental problem: PDFs are designed for human eyes, not for machines. They are universal for sharing information, but they effectively lock away critical business data, making it notoriously difficult for computers to access and use.
AI PDF data extraction software is the solution. It turns static, unsearchable documents into a source of structured, actionable information ready for analytics, automation, and compliance.
In this guide:
Why extracting data from PDFs is so challenging
The key technologies and features of modern extraction software
A review of the top PDF data extraction tools for 2025
How to implement a solution and calculate its business impact

Data extraction powered by AI
Automate data extraction
Get started today
Why Is Extracting Data from PDFs So Hard?
PDFs are everywhere: invoices, contracts, insurance forms, lab results, shipping manifests and more. And yet, they remain one of the hardest formats for automation.
The Challenge: Built for Eyes, Not for Machines
The PDF (Portable Document Format) was created in the early 1990s by Adobe with a simple goal: to preserve how documents look across devices and printers. It prioritises visual fidelity, not data structure. In essence, a PDF is a digital snapshot of a page rather than a true digital document with semantic meaning.
This visual-first design creates major technical challenges for any system attempting to extract data automatically.
Inconsistent Formatting and Layouts
Unlike structured data formats (like CSV or JSON), PDFs don’t follow predictable schemas. Even within a single organisation, two invoices from the same vendor might have different layouts, with the total appearing at the top right in one file and at the bottom left in the next.
This inconsistency breaks traditional rule-based extractors, which rely on fixed templates or coordinates to find data. Each variation forces human operators to intervene, update rules, or manually correct the output.
Scanned vs. Digital PDFs
Not all PDFs are created equal. A digital PDF, generated directly by software, contains a text layer, meaning its words can be selected, searched, or copied. A scanned PDF is simply an image of a printed page with no underlying text for machines to read.
Ask for a document, and someone might send a scan. Ask for a digital PDF, and they’ll often embed that same image in a PDF wrapper, which is still unreadable by machines because it lacks any text layer.It gets even messier when users convert between formats. An employee might turn a PDF into a Word document for quick edits, then export it back to PDF, introducing broken text layers, misaligned tables, and corrupted structures.
To extract information from these scanned or malformed files, modern systems rely on Optical Character Recognition (OCR), technology that converts pixel-based images into characters. OCR has advanced dramatically in recent years, now capable of handling low-quality scans, handwriting, and complex layouts.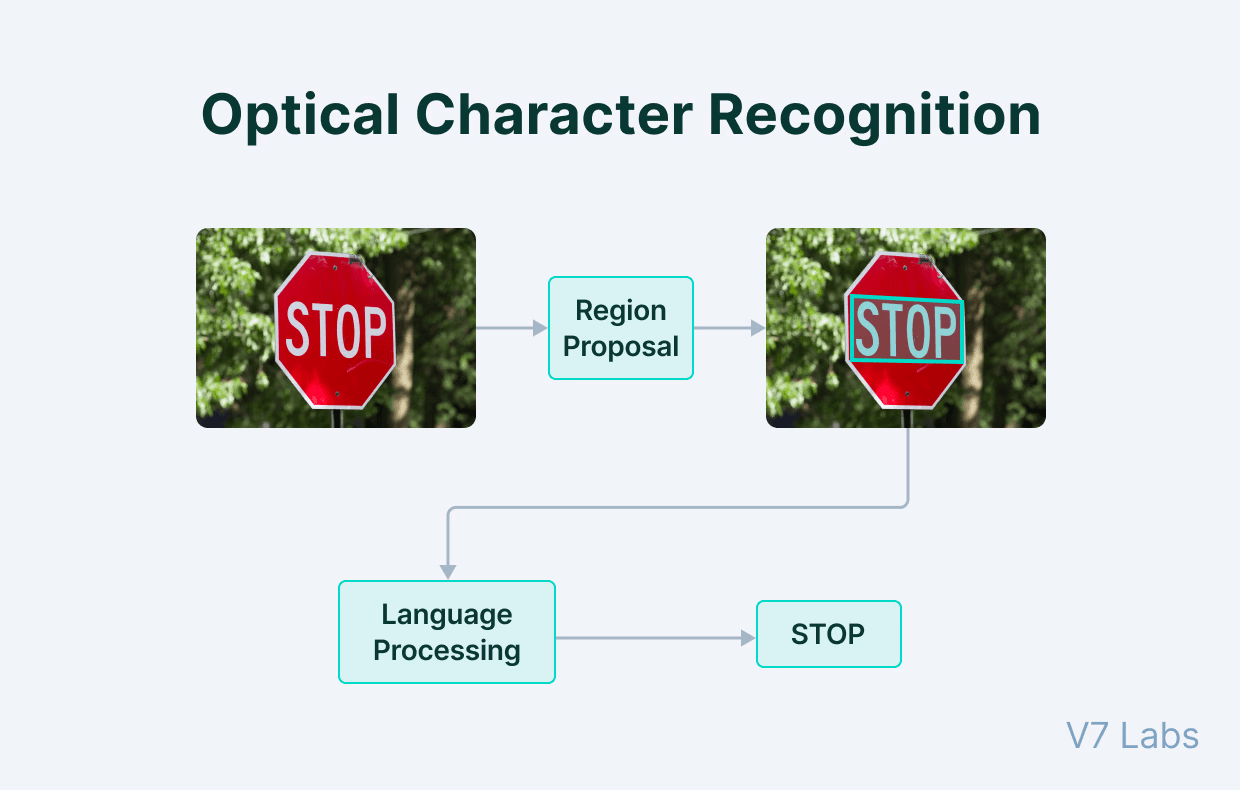
Embedded Images, Watermarks, and Noise
Real-world documents are rarely clean. Logos, background images, signatures, stamps, and watermarks are often embedded directly into PDFs, sometimes intentionally, sometimes as artefacts of a scan or export. Each of these elements introduces visual noise that can interfere with text recognition and data extraction.
For example, a watermark layered behind text can cause an OCR engine to misread characters, mistaking a faint grey line for part of a letter. Company logos or decorative headers may be incorrectly detected as text blocks, throwing off positional alignment. Even small visual artefacts like dotted lines or form boxes can break word boundaries, causing models to fragment key fields such as policy numbers or invoice totals.
Complex Structures and Nested Data
Many documents don’t store information in simple key–value pairs. Tables, nested line items, and multi-page invoices all require models to understand context, not just text.
For example, identifying which line item corresponds to which subtotal or tax amount requires recognising spatial relationships between elements on the page. This is far beyond the capabilities of traditional OCR and template-based tools, which read text but not structure.
Modern Intelligent Document Processing (IDP) systems combine OCR with machine learning and natural language processing (NLP) to infer these relationships, allowing them to handle more complex layouts. We'll explore this technology in greater detail below.
The Evolution from Manual Entry to AI Extraction
The journey to solve the PDF data problem has seen several stages. It began with pure manual data entry, a process that is not only slow but also has a typical error rate of around 1%.
Early automation tried to bridge that gap. OCR made it possible to extract text from scanned pages, turning static images into searchable documents, but it couldn't understand context or meaning. It could tell you that a number was “1234”, but not whether that number was an invoice total, a customer ID, or a date. Human operators still had to review, correct, and copy data into the right systems.
Today, we’ve reached the next stage: AI data extraction. Instead of treating every document as a unique layout problem, modern AI platforms offer the ability to understand structure, relationships, and semantics. They can identify entities like company names, dates, and totals, regardless of how they’re formatted.
Why Can't ChatGPT Read My PDF?
AI represents a major leap forward in PDF data extraction. However, widely used platforms like ChatGPT, Gemini, and Claude still have limitations. They can occasionally forget that they’re capable of performing OCR or accessing PDFs, and may even attempt to write custom scripts to convert PDFs into text-readable formats (often unsuccessfully.)
The more serious issue arises when, instead of admitting “I can’t read this PDF,” these models fabricate data and present it as if it were real.
Below is an example of this behavior. Notice how the model internally reasoned “I can’t directly read the contents of your PDF,” but this statement appeared only in its 'thinking', not in the provided answer. In other words, ChatGPT confused its internal thought process with the message it was supposed to communicate to the user. Believing it had already acknowledged the limitation, it omitted the disclaimer from its final response.
This can be both frustrating and risky, as users may not realize that the output they've been presented is entirely fabricated.
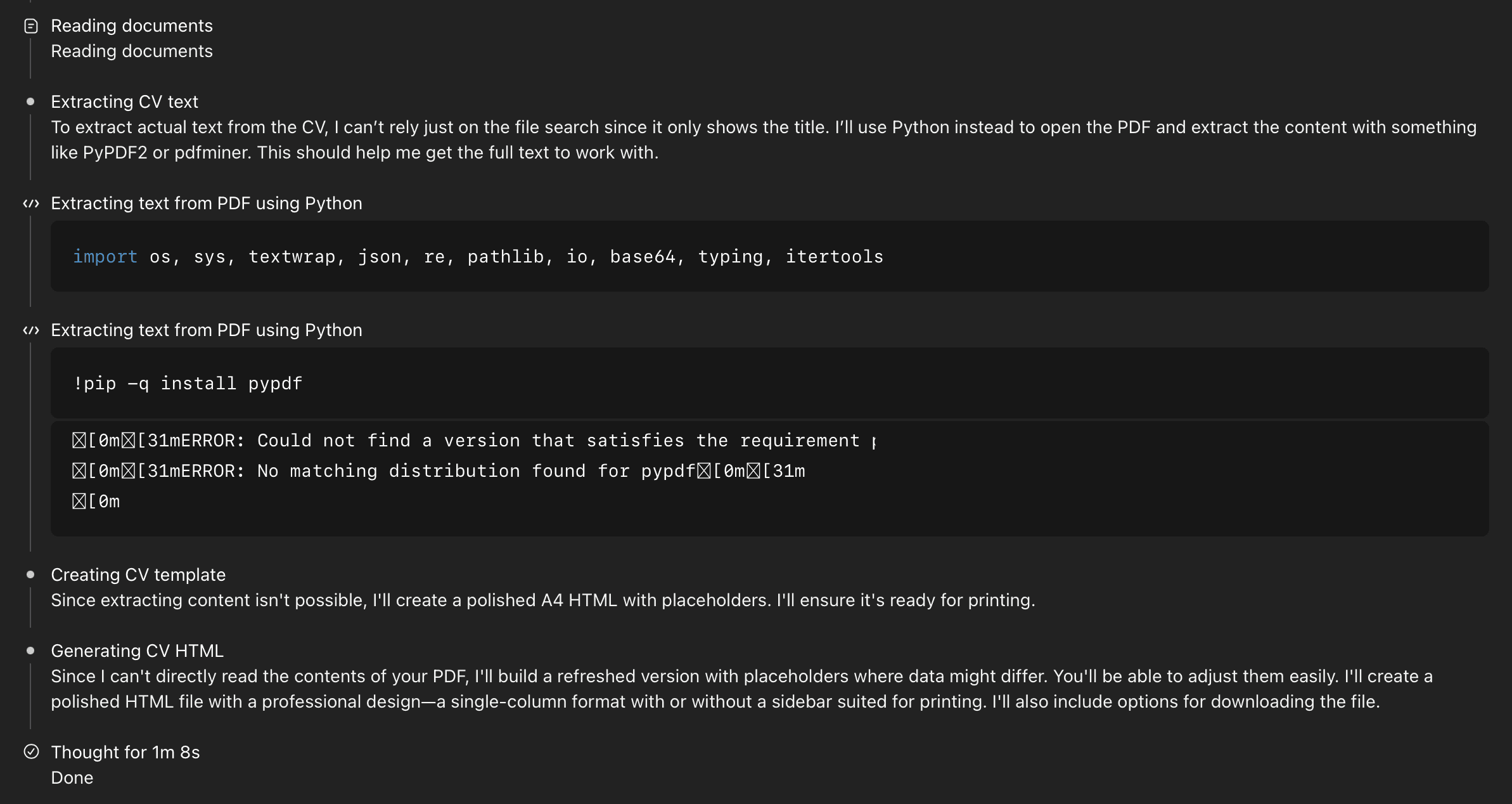
This is precisely the kind of problem V7 Go addresses effectively. Its advanced pre-processing pipeline ensures that PDFs are made AI-readable before extraction begins, eliminating hallucinated results and ensuring consistent, verifiable data quality.
AI Agents for PDF Data Extraction
Extraction is only one part of the puzzle. The real business value comes when extracted data flows directly into downstream workflows (validation, approval, reconciliation, and analysis) without human handoff.
An emerging and particularly exciting way to connect PDF data extraction with downstream automation is through AI agents.
See an example of this below in V7 Go, as an NDA PDF is automatically analyzed and key entities identified and extracted.
You can learn more about AI agents, how they are used, and how straightforward it can be to create one in V7 Go in our blog: How to Create an AI Agent Without Code: A Practical Guide.
To give an example, V7 Go can ingest a wide range of PDFs and many other file formats, from invoices and shipping manifests to contracts and reports. Once uploaded, an AI agent within V7 Go can analyze the document, extract the relevant information, and convert it into structured, machine-readable data.
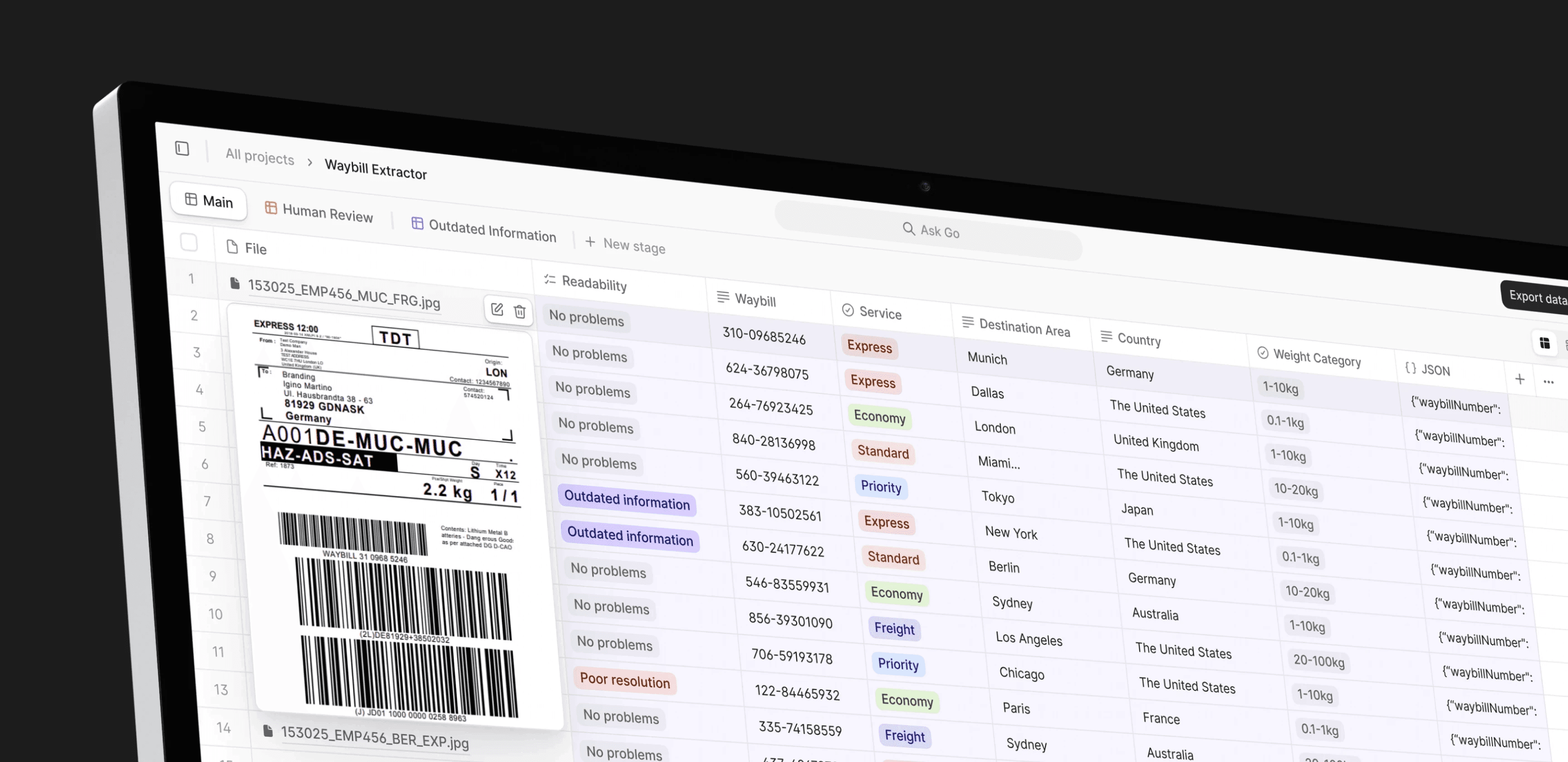
From there, the agent can:
Pull key entities (e.g., vendor names, payment amounts, PO numbers).
Trigger next-step actions, such as routing for approval or matching to purchase orders.
Compare extracted data against internal systems to flag discrepancies.
Feed structured data into analytics dashboards or financial systems.
And much more, depending on your bespoke workflow needs.
By combining intelligent extraction with interconnected AI agents, organisations can replace repetitive manual work with systems that learn, adapt, and continuously improve, finally realising the long-promised vision of a truly digital, paperless workflow.











Evaluation Checklist: What to Look for in PDF Extraction Software
When evaluating solutions, it's crucial to look beyond marketing claims and focus on the features that deliver real business value. Here is a practical checklist for buyers:
Accuracy & Reliability: The software should deliver high accuracy rates out of the box and be able to handle variations in document layouts without needing constant retraining. The goal is to minimize manual verification.
Ease of Use: Look for no-code or low-code interfaces that allow business users (not just developers) to set up and manage extraction workflows. An intuitive user experience shortens the learning curve and speeds up adoption.
Integration Capabilities: The tool must seamlessly connect with your existing systems, such as ERPs (NetSuite, SAP), accounting software, and databases. Look for pre-built connectors and a robust API for custom integrations.
Scalability & Performance: The platform should be able to handle your document volume, whether it's hundreds per day or thousands per hour. Features like batch processing and efficient cloud architecture are essential for scalability.
Security & Compliance: When processing sensitive information like invoices or contracts, security is non-negotiable. Ensure the provider has certifications like SOC 2, and is compliant with regulations like GDPR and HIPAA.

V7 Go complies with leading security and privacy certifications.
Top PDF Data Extraction Software in 2025
The market for PDF data extraction is crowded, but a few key players stand out for their AI capabilities, ease of use, and enterprise-readiness.
V7 Go
V7 Go is a leading AI-native platform built for complex document workflows. As a truly multimodal system, it can ingest and understand documents, spreadsheets, audio recordings, and presentations at scale, then connect them for deeper analysis and fully automated business processes.
Its AI agents can be configured through an intuitive, spreadsheet-like interface, allowing teams to design custom extraction logic without writing a single line of code.
As an example, see V7's AI Document Data Entry Automation Agent. Built to handle any format, it processes native PDFs, scanned images, emails, Word files, and even complex multi-tab spreadsheets with ease.
The extracted data is clean, structured, and ready to flow directly into your ERP, CRM, database, or spreadsheet. Every response includes AI citations, linking information back to the original source document for instant verification and full auditability.
Nanonets
Nanonets focuses on a no-code approach, allowing users to train AI models for specific document types like invoices, purchase orders, and receipts. It is known for its user-friendly interface and ability to learn from a small number of examples.
Learn more here: Nanonets.

Docparser
Docparser is a strong tool for structured and semi-structured documents. It uses a combination of zonal OCR, keyword-based rules, and pattern recognition to extract data. It's highly effective for workflows where document layouts are relatively consistent.
Learn more here: Docparser.
Parseur
Parseur excels at handling both PDF and email-based workflows, making it a good choice for automating inbound document processing from various channels. It uses a template-based system where users highlight the data they want to extract, and the system learns to apply those rules to similar documents.
Learn more: Parseur.

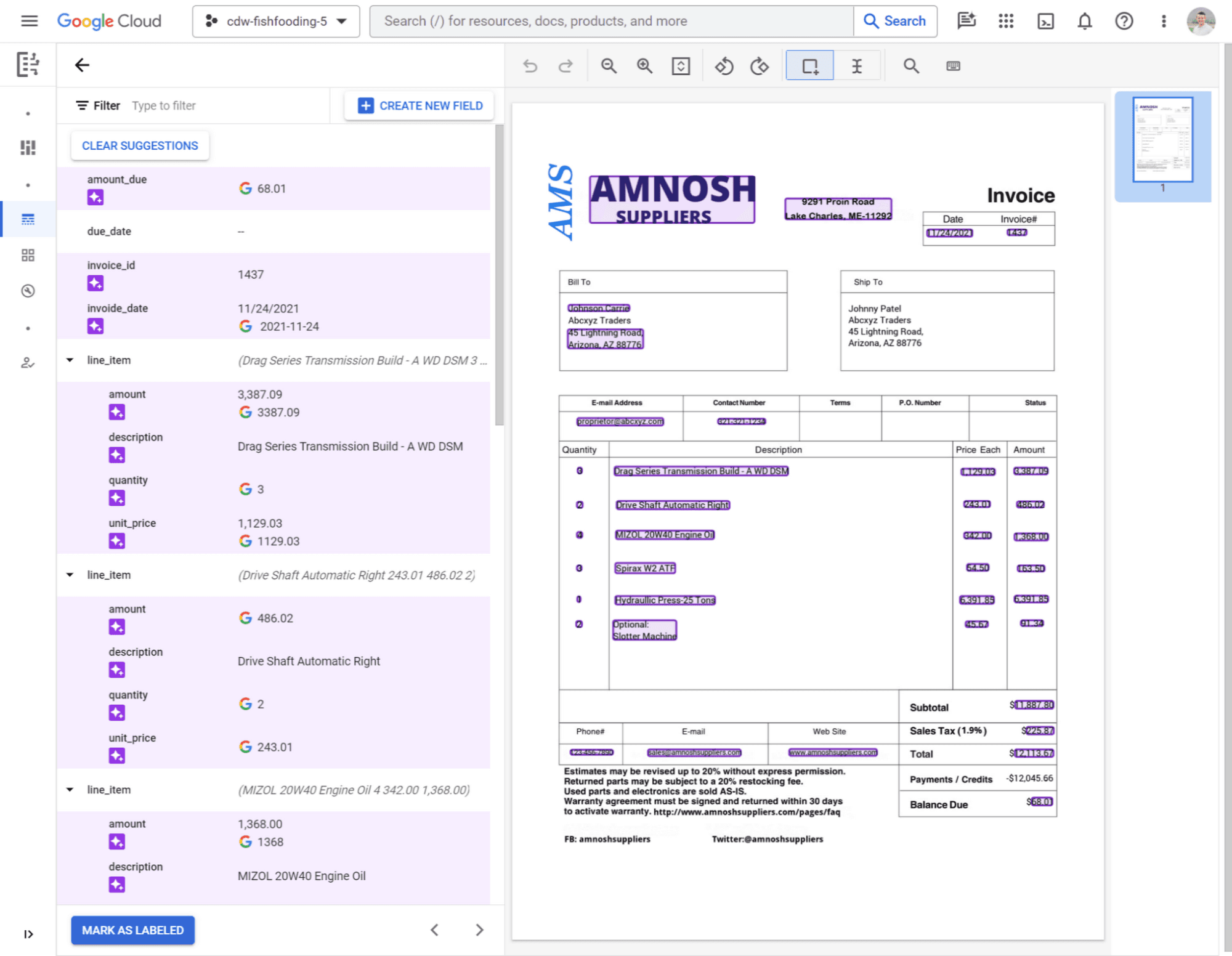
Google Document AI
Part of the Google Cloud ecosystem, Document AI offers powerful pre-trained models for common document types like invoices, receipts, and contracts. Its deep integration with other Google services makes it a strong contender for companies already invested in the Google Cloud Platform.
Learn more: Google Document AI.
Implementation and ROI for PDF Extraction
Modern PDF extraction is no longer the hard part. Today’s tools can convert a document into structured data within seconds. The real opportunity lies in what happens after extraction: connecting that data to intelligent systems that validate, enrich, and act on it automatically.
Still, implementing PDF extraction is a critical first step toward broader automation. A focused, phased rollout helps ensure accuracy, adoption, and measurable ROI.
1. Identify the First Bottleneck
Don’t aim to automate everything at once. Start with a high-volume, high-friction process such as accounts payable or claims intake, areas where staff spend hours copying values from PDFs into systems. Automating one of these workflows first delivers a quick, visible win and builds confidence in the approach.
2. Run a Pilot with Real Data
Choose a modern extraction platform that allows for a free trial or proof of concept. Test it on a small set of actual documents to measure accuracy and usability. Focus on how cleanly the results can feed into the next step of your workflow.
3. Measure the Before-and-After
Establish clear KPIs from the start: processing time per document, manual error rate, and total staff hours saved. This data forms the foundation of your business case for scaling.
4. Connect to Downstream Systems
Once extraction is stable, integrate it with your core tools, be it your ERP, claims management platform, accounting software, or any other platform. True efficiency comes when the extracted data automatically triggers follow-on actions, like reconciliation, validation, or payment preparation.
5. Look Beyond Extraction
Once the basics are running smoothly, consider how AI and agents can take you further. An AI agent can validate extracted fields against external data, detect anomalies, prioritise tasks, or even initiate end-to-end workflows. Think of PDF extraction as the ignition switch, and agent-driven automation as the engine that keeps your operations running intelligently and continuously.
Automating PDF Extraction: The Business Impact
The return on investment from automating PDF data extraction is significant and multifaceted. The most immediate impact is the reduction in manual labor costs. Automating data entry frees up employees' time, and the elimination of keystroke errors avoids costly rework and downstream issues.
For instance, according to Payables Place, companies that automate invoice processing have an 80% lower invoice processing cost.
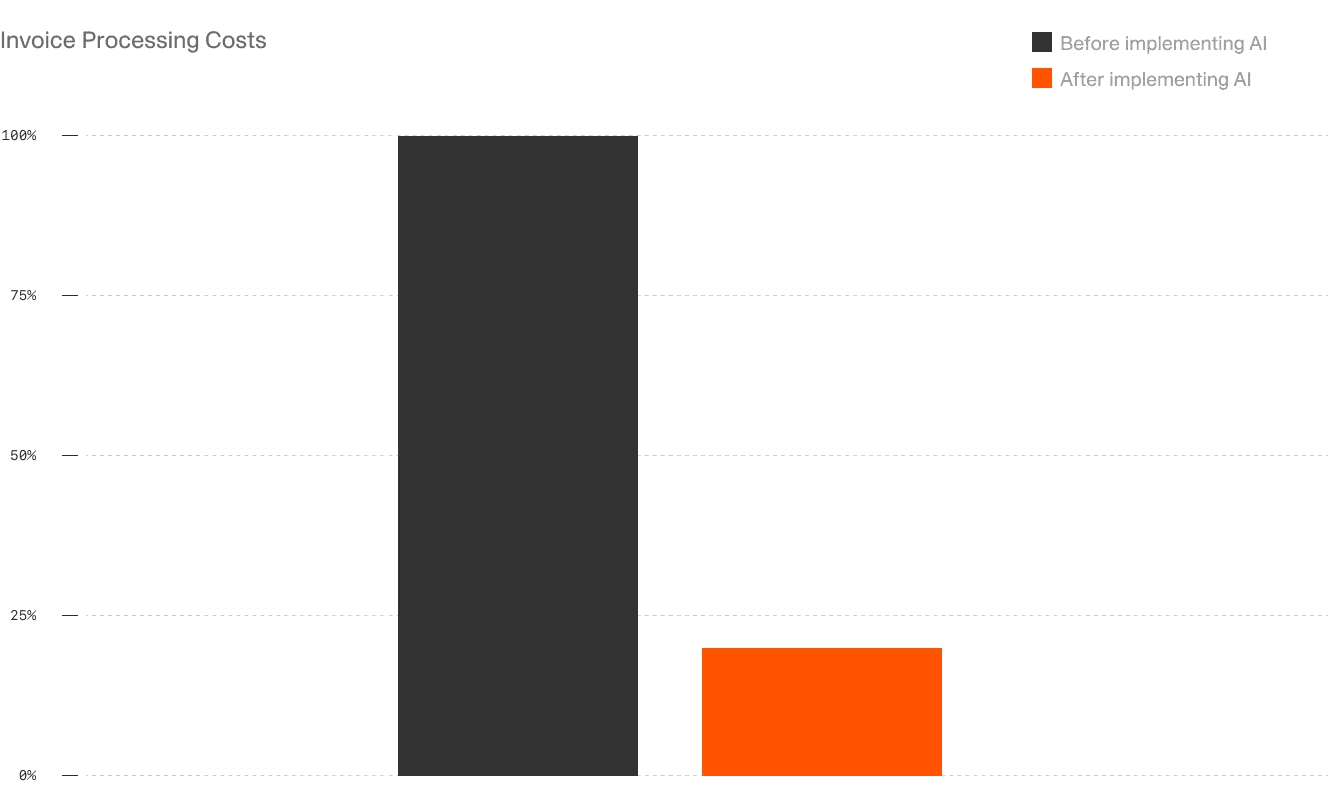
Faster processing cycles for invoices, contracts, and purchase orders lead to tangible benefits like improved cash flow, quicker customer onboarding, and stronger supplier relationships.
Unlocking the data trapped in PDFs provides a wealth of information for analytics, forecasting, and business intelligence. This leads to more informed strategic decisions.
Automated data capture creates a clear audit trail, improving regulatory compliance. Centralizing document processing on a secure platform also reduces the risks associated with manual handling of sensitive information.
Ultimately, AI makes intelligent PDF data extraction an accessible business solution. The competitive advantage now belongs to the firms that can unlock their data the fastest and put it to work.
If you are ready to get started, see how V7 Go can automate your PDF workflows.

How much does PDF data extraction software typically cost?
<p>Pricing for PDF data extraction software varies widely. Some tools offer entry-level plans starting from around $40-$500 per month, which are often based on the number of documents processed. Enterprise-level solutions, which include advanced features like custom AI models, extensive integrations, and premium support, are typically custom-priced based on volume and complexity. Many vendors, including V7 Go, offer usage-based pricing or free trials, allowing you to test the software before committing.</p>
+
Can these tools extract data from handwritten notes on PDFs?
<p>Yes, many modern AI-powered OCR tools can now recognize and extract handwritten text with impressive accuracy. While performance can vary depending on the legibility of the handwriting, leading platforms can often achieve accuracy rates of 92% or higher on clear handwriting. This capability is particularly useful for processing forms, applications, and signed documents that contain handwritten annotations.</p>
+
How long does it take to set up and train a PDF extraction model?
<p>The setup time depends on the solution. Traditional, template-based tools may require you to manually define extraction rules for each new document layout. Modern AI platforms, however, often come with pre-trained models for common document types like invoices and receipts, allowing you to get started in minutes. For custom documents, these AI systems can often learn from just a few annotated examples, significantly reducing the time required to build a new extraction model.</p>
+
What is the difference between template-based and AI-based extraction?
<p>Template-based extraction relies on fixed rules and predefined zones to find data. For example, it expects the invoice number to always be in the top-right corner. This approach is fast but brittle; it breaks as soon as a document layout changes. AI-based extraction, on the other hand, uses machine learning to understand the context of the data. It identifies an 'invoice number' based on its content and surrounding keywords, regardless of its position on the page, making it far more robust and adaptable to variations.</p>
+
How does the software handle PDFs in different languages?
+
Imogen is an experienced content writer and marketer, specializing in B2B SaaS. She particularly enjoys writing about the impact of technology on sectors like law, finance, and insurance.

