23 min read
—


Discover how LLMs can impact your organization. We discuss how to automate customer service, conduct AI competitor analysis, or deploy autonomous agents within your business.

Occasionally, the tech world presents us with a new and promising tool that has the potential to revolutionize everything. Some companies eagerly experiment with it, while others prefer to watch from a distance.
Today, from the corporate greats to nimble startups, the burning question is:
Should we start using LLM and foundation models now, or should we wait and continue observing from the sidelines?
And, this is just the beginning. A flurry of additional questions are set to follow:
Will ChatGPT and Large Language Models (LLMs) turn the business landscape upside down, or will they simply blend into the norm, becoming part and parcel of everyday operations? Is this just handy tech to automate some tasks or is this the prologue to an AI-dominant corporate ecosystem?
We are tempted to lean towards the "game-changer" scenario. There is a long answer as to why, but if you cannot wait, you can jump to specific sections of this primer right now:
Changes brought by Large Language Models and generative AI in tech
Practical applications of LLMs to help companies save money or improve their operations
Overview of important LLM tools and foundation models set to impact on the market
Hopefully, this article will help you navigate the hurdles of adopting large language models in business.
Before we dive into the specifics and explore practical examples and use cases, let's take a step back and view the bigger picture.

AI for document processing
Run AI agents across your entire finance organization
Get started today
LLMs can play a vital role in designing conversational interfaces for multi-modal AI systems, thereby improving the interaction between humans and AI. This not only enhances the user experience but also facilitates the seamless integration of AI into everyday tasks and processes.
How foundation models differ from other recent tech “hypes”
Let’s consider cryptocurrencies, virtual reality, and the so-called “metaverse” for a moment. These all seemed like amazing ideas at one time or another. They were predicted to change the world as we know it. However, no matter how exciting a new technology may be, there are always three significant hurdles it needs to clear:
Getting people to use it (the user experience hurdle)
Building the tech to support it (the infrastructure hurdle)
Keeping it secure and private (the legal hurdle)

If we carefully analyze how each of these “revolutionary” technologies checks against these points, it is not that surprising that they have struggled to truly take off.
For example, virtual reality may be great for gaming, but using it for a simple HR meeting instead of a Zoom call can be an impractical overkill. Online payments and digital banking are useful, but for cryptocurrencies, scaling regulatory challenges has limited adoption.
We can use technology to create simulations of our surroundings, essentially replicating real-world experiences. However, it is important to note that merely making everyday practices virtual for the sole purpose of being innovative may not provide any concrete benefits.
However—
LLMs are a different kind of beast.
LLMs and foundation models are not simply digitalising everyday experiences or environments. Instead, they involve combining almost all knowledge available online into a model that can effectively solve real world problems. In essence, instead of creating a simulation of external reality, with LLMs, we have created a living, interactive simulation of human language itself—complete with some of the knowledge that is encoded in it.
Generative AI powered by large language models can write emails to your customers, create website assets, and extract information from your data. However, using this technology for such tasks can feel like using a nuclear reactor to boil a kettle for a cup of coffee. The real heavy-duty use cases for generative AI are still emerging.
In essence, LLMs can create structured outputs from unstructured inputs.
And that is something quite new.
This is a genuine advantage and benefit for countless applications. We don’t just use technology to make experiences futuristic, or for the sake of them looking “innovative”. LLMs get stuff done, rather than creating hype without substance.
LLMs like ChatGPT have now become so powerful, they can pass the Turing Test. However, this has hardly made the news, because everyone is too busy creating amazing things with it!
So, what is the actual impact of ChatGPT on the world of business?
The impact of LLMs and foundation models on the business landscape
LLMs have promising practical applications that elevate them beyond hype. They are more than just a set of tools: they require a change in the entire framework and methods of using AI.
In essence, foundation models, and particularly Large Language Models (LLMs), have shifted the paradigm of AI development and deployment.
Now, to make sure that we’re on the same page when it comes to terminology—
What exactly are foundation models?
Foundation models are versatile ML models that are trained on extremely large datasets. Think along the lines of billions of articles, books, or images. To handle this amount of data, newer versions of models like the GPT engine are trained using thousands of NVIDIA GPUs.
But—
Once the training is completed, these models can be used on standard consumer-grade equipment. It takes millions of dollars-worth of processing power to train a foundation model like LLaMa or Stable Diffusion, but it takes a Macbook Air to deploy it locally and use it for pretty much anything you want. It’s worth noting, some open source foundation models are restricted to research-oriented use only, so you should be careful about implementing them in your business operations.
Take a look at an example of a local LLM offering ChatGPT-like capabilities and local deployment:
The primary difference between the “old” and the “new” paradigm is that you can use extremely powerful AI models without having to train your own. Foundation models can write, code, and generate images, which covers a significant portion of business operations.These pre-trained models can be used and adapted for specific tasks or uses. Currently, there are many free solutions available, which makes this a popular and accessible approach.

Not only does the new paradigm simplify the integration of AI into a variety of business use cases, but it also delivers solutions that outperform custom-built alternatives. For example, a ChatGPT model can be deployed as a virtual assistant, providing personalized and contextually appropriate responses to customer queries without requiring a substantial dataset of customer service scripts and conversations.
This change in the usage of AI from task-specific custom models to broader and more versatile foundation models represents a significant paradigm shift for businesses. Foundation models offer improved capabilities within their respective domains and they democratize access to machine learning solutions.
It is worth noting that LLMs have emergent abilities, such as an understanding of causality. These models learn to identify cause-and-effect relationships within text data just by observing patterns during training. This allows them to engage in complex reasoning tasks. For example, ChatGPT is a language model, but it also learned to solve simple mathematical problems on its own (under specific conditions) without explicit mathematical training.
While traditional AI models were quite capable of solving specific tasks, their flexibility was very limited. With foundation models and LLMs, you can create complex workflows and handle more unique scenarios with confidence.
How to implement LLMs and foundation models into your business operations
Let's assess the current situation.
We are all adapting to the circumstances and waiting for things to become clearer. However, it is important to recognize that once the business world has a better understanding, the business landscape will be significantly different. If you don’t adopt new frameworks, your competitors who have done so may have the upper hand. However, it could also backfire if you use this technology recklessly.
While generative AI carries some inherent risks, it still solves more problems than it creates. Regarding LLMs, they can greatly benefit your company. Utilizing foundational models can optimize your current processes and dramatically reduce costs.

Additionally, you can now tackle initiatives that may have previously been unfeasible due to financial restrictions.
However, the best approach is to use human-in-the-loop solutions.
"Collecting user feedback and using human-in-the-loop methods for quality control are crucial for improving AI models over time and ensuring their reliability and safety. Capturing data on the inputs, outputs, user actions, and corrections can help filter and refine the dataset for fine-tuning and developing secure ML solutions."
Alberto Rizzoli
Beyond Baseline Accuracy: Developing Industry-Ready LLMs
Whatever your foundation models do, the majority of their output should be reviewed and approved by a professional. Establishing processes that include reviews and human QA is still essential.
Here are some popular use cases that you can start experimenting with today:
1. Harnessing insights from your unstructured data
Many organizations have a lot of unstructured data, but they don't always use it to its full potential. This might include feedback from customers primarily used for anecdotal references by your customer success team or internal communications data that might hold a wealth of insights. By leveraging LLMs, your organization can extract meaningful insights from this data. With automation that removes confidential information from customer conversations, you can easily categorize the data for NLP-like analysis to fine-tune your messaging and create more effective value propositions.

Moreover, LLMs can significantly enhance information retrieval from your internal documentation, policies, and other knowledge reservoirs. Furthermore, you can utilize external data such as social media posts for sentiment analysis, offering a more comprehensive understanding of your audience's perception.
2. Translating documents, drafting policies, and generating logs/documentation
LLMs, with their advanced language processing abilities, can serve as your digital translators or drafters for complex documents such as policies and legal contracts. In an era where businesses are increasingly global, you may often deal with partners or clients that use different languages. With an LLM like OpenAI’s GPT-4, you can translate content across multiple languages in real-time. Moreover, the system can be tailored to understand the nuances of legal jargon and draft legal contracts, thereby eliminating the need for manual drafting.

Furthermore, LLMs can streamline your document creation process. By providing the model with basic bullet points or outlines, it can generate a complete set of document templates, software documentation, or changelogs. This capability extends beyond legal documents to other areas such as technical and business-related content. It can significantly reduce the time and effort spent on drafting and translating these documents.
3. Powering content generation and marketing strategies
While generating high-quality blogs still requires a lot of input from copywriters and some additional editing rounds, once the core content is ready, you can create an unlimited number of derivative pieces in a matter of minutes. Repurposing content is an integral part of any digital marketing strategy, and with LLMs, it has never been easier.
Many LLMs and generative AI tools come with presets and templates that allow you to create specific types of content.
By feeding your original blog post into a model like ChatGPT, you can generate a series of engaging social media posts, emails, or other assets. However, in the era of AI-generated content, the value of originality cannot be overstated. Therefore, case studies, interviews, and reports presenting new and original information remain crucial for your brand's credibility.
4. Screening and filtering candidate resumes
The recruitment process can be greatly improved by utilizing LLMs (Language Learning Models) to compare candidate resumes with job descriptions or other established criteria. This can help recruiters to quickly weed out candidates who may not be the right fit for the job. Additionally, the recruitment process could be further streamlined by implementing AI-powered technology to generate customized email templates for different stages of the process.
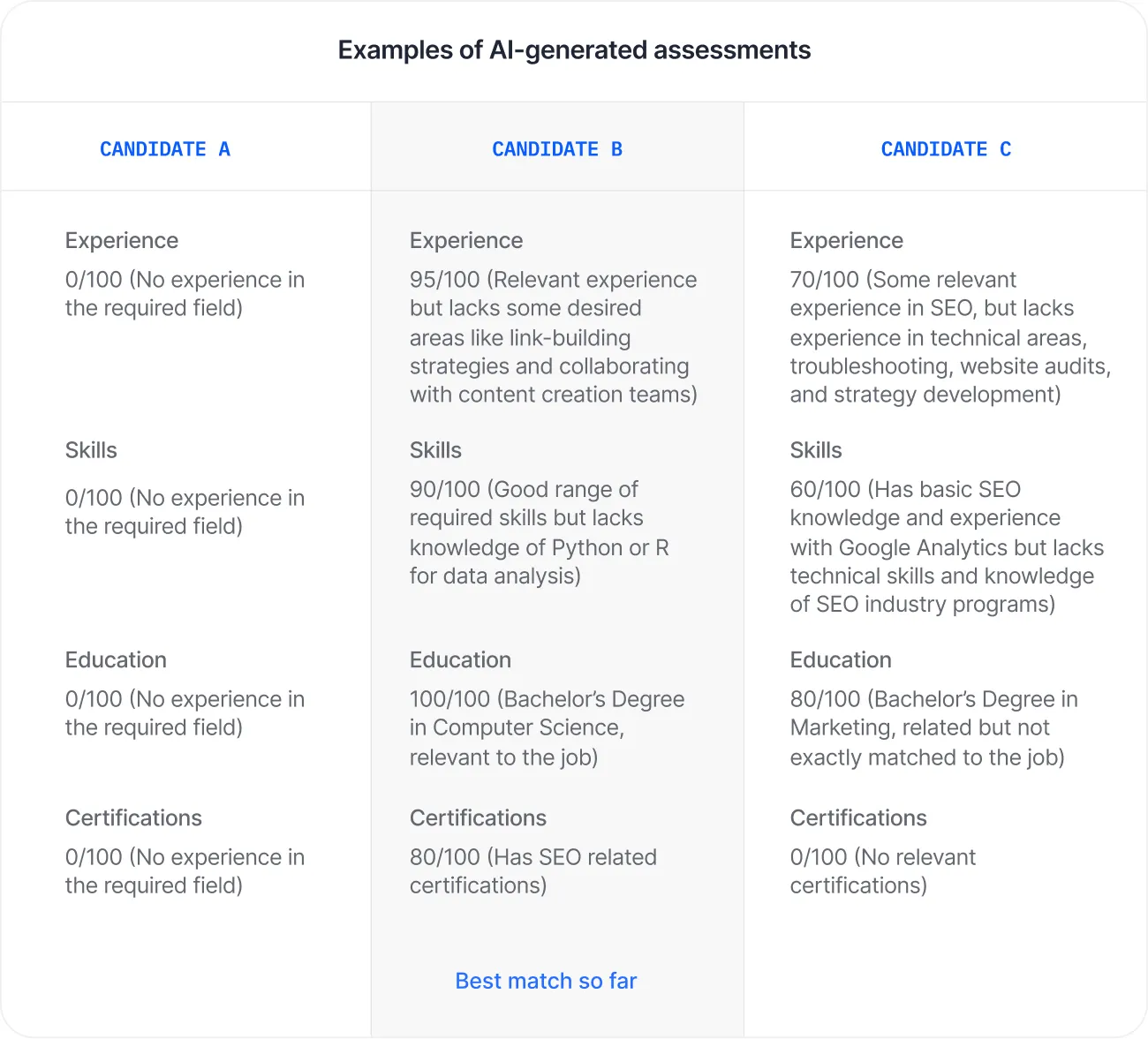
Using LLMs and AI would not only save recruiters time and effort, but also ensure that all candidates receive clear and consistent communication throughout the process.
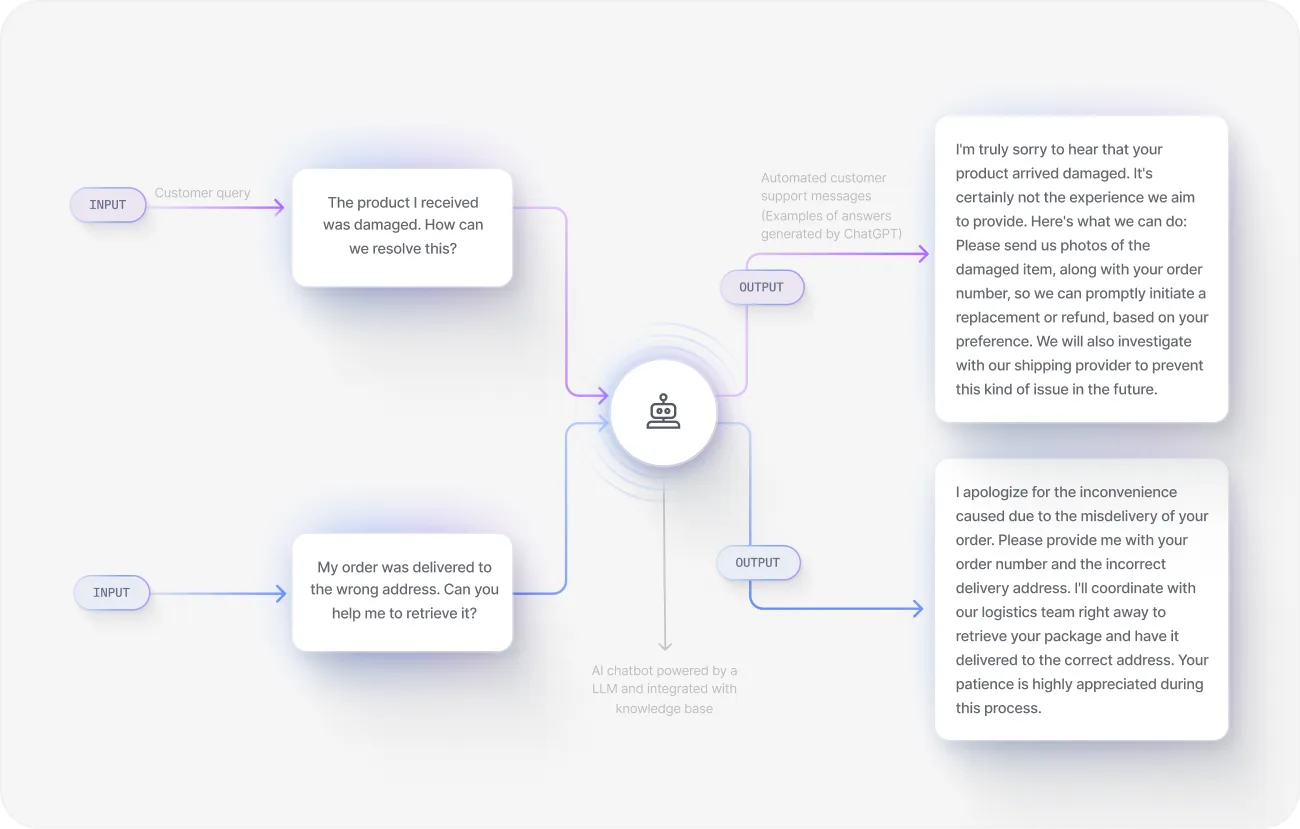
5. Automating customer service and content moderation
LLMs can play a transformative role in automating customer service and content moderation. They can handle customer queries, provide immediate assistance, and offer personalized solutions. Moreover, with reinforcement learning from human feedback and fine-tuning, the model can improve its performance over time.
With tools like LangChain and Pinecone, you can connect ChatGPT with your internal knowledge hubs by turning them into embeddings and vector databases.
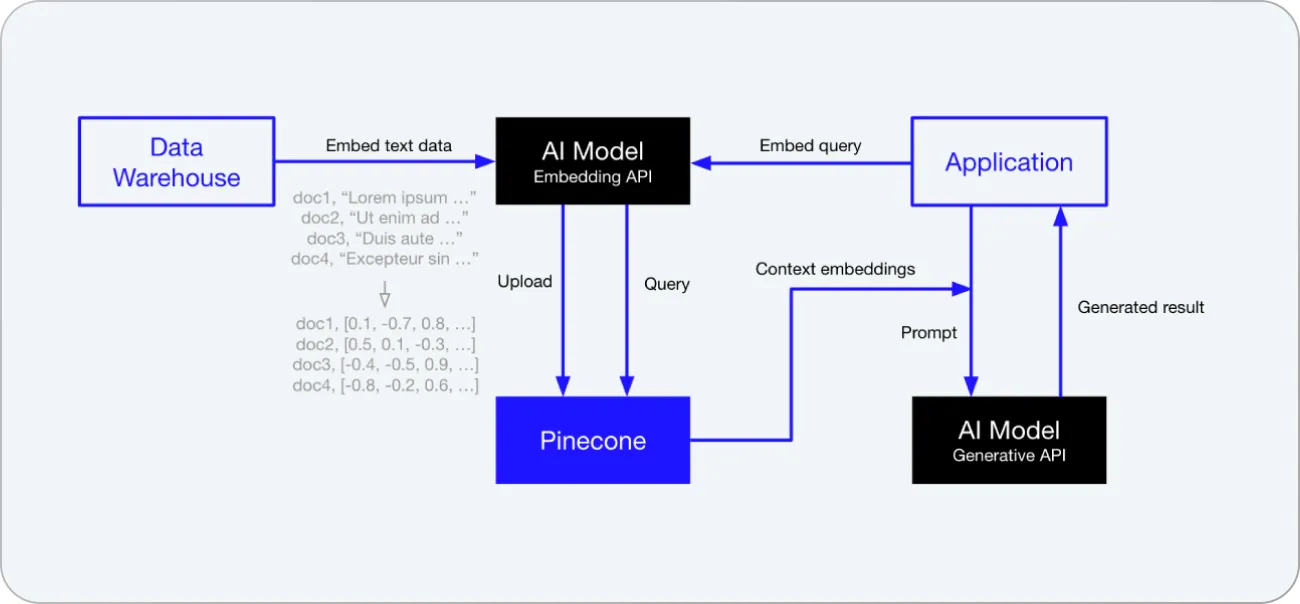
With some frameworks, it is easy to make LLMs perform complex operations that involve your custom data. Alternatively, you can also fine-tune models and feed them new information directly through OpenAI's API.
The same principles can be used for content moderation. Your review or comment plugins can be integrated with LLMs that automatically detect unwanted messages. LLMs can be successfully utilized for content moderation, ensuring community guidelines are upheld, and inappropriate content is filtered out effectively.
6. Deploying autonomous agents to solve complex problems
Autonomous agents are AI entities that mimic human behavior in virtual environments. Recently, researchers from Stanford University and Google Research have developed agents that utilize memory, reflection, and planning to generate highly believable behavior. Each agent was equipped with a "memory stream" of timestamped observations, scored for recency, importance, and relevancy. These generative agents could communicate with each other and display emergent behavior, demonstrating the remarkable progress we've made in the field of AI.
Although this technique is still in its early stages, LLMs enable the deployment of autonomous agents capable of brainstorming and problem-solving. Many of them work by running an infinite loop. For example, here is the flow of Baby AGI, a Python script for deploying task-driven autonomous agents using LLMs:
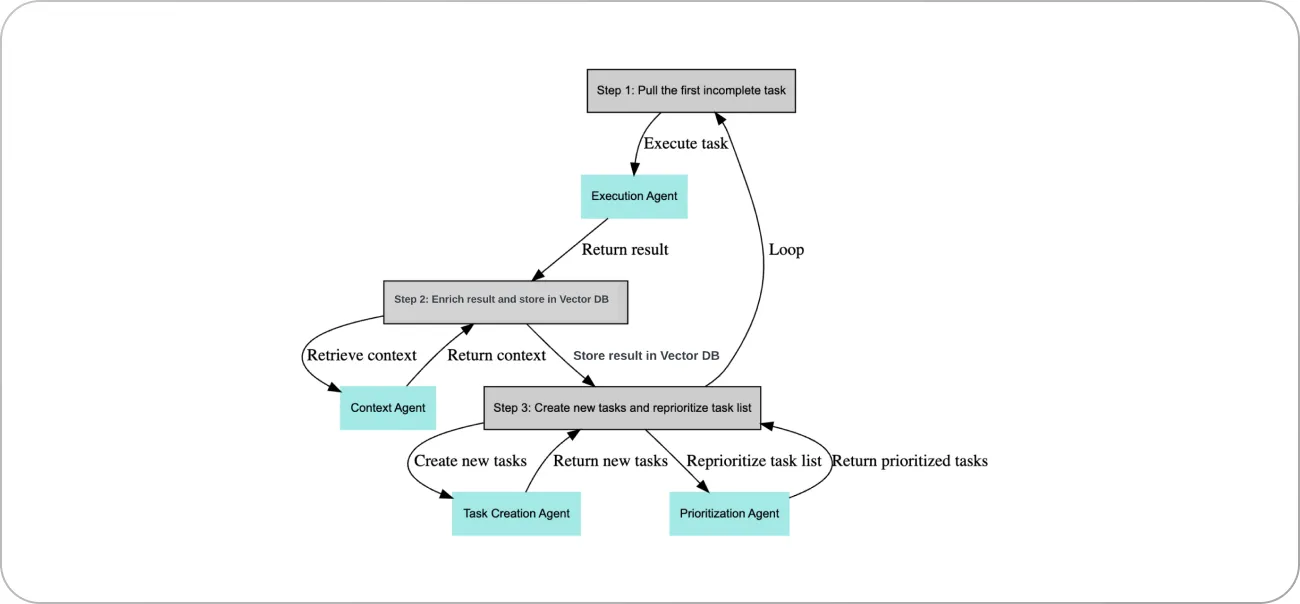
So, what can be some business use cases for autonomous agents?
Imagine having a team of virtual agents, each powered by ChatGPT, working collaboratively to come up with the best possible solution to any problem.
Instead of generating one output, you can use multiple iterations based on feedback sessions and revisions between a "bad cop" agent and a "good cop" agent. Their conversation history can be analyzed to understand the reasoning behind their outcomes. The AI would be able to correct itself and iteratively produce better outputs, as well as role-play complex scenarios.
What can autonomous agents do?
Autonomous AI agents are quite good at collecting and retrieving all sorts of information they can find online. You can release autonomous agents to collect data on your competitors, perform all sorts of audits, or generate reports.
7. Facilitating multi-modal AI systems with conversational interfaces
LLMs can play a vital role in designing conversational interfaces for multi-modal AI systems, thereby improving the interaction between humans and AI. This not only enhances the user experience but also facilitates the seamless integration of AI into everyday tasks and processes.
For instance, while V7 is primarily a training data platform for solving computer vision tasks, we are also implementing foundation LLM models for prompt-based interaction with images. We are also using technologies like CLIP for semantic segmentation happening in the back end for some of our auto-labeling features. The boundaries between visuals and text are blended together into a framework that incorporates multiple modalities.
8. Conducting market research and competitor analysis
LLMs and foundation models are useful in conducting market research and competitor analysis, replacing the need for specialized human analysts. By integrating LLMs with data analytics platforms, businesses can generate reports on market trends, consumer behavior, and competitive positioning.
LLMs can gather information about competitors from various platforms like G2 and Crunchbase, providing insight into their strategies, strengths, and weaknesses. Social media analysis can also help you identify trends and potential threats or opportunities for your businesses. Advanced sentiment analysis capabilities help businesses gauge public opinion about their brand and products to address potential issues.
Essential tools for implementing foundation models into your business operations
As we can see, the impact of LLMs and foundation models on the business landscape is substantial. These models are not only reshaping our approach to problem-solving but also unlocking new avenues for growth and innovation.
While it's evident that these tools offer revolutionary advantages, their implementation can be a daunting task without the right knowledge and resources. So, let's move on to the next critical topic: understanding the essential tools that you can leverage to effectively integrate LLMs and foundation models into your business operations.
ChatGPT/OpenAI API
Various iterations of GPT models have existed for some time. However, it was only with recent updates that the true potential of LLMs came to light. Historically, OpenAI and GPT models were utilized to power third-party applications and SaaS services that focused on specific tasks, such as content creation or customer service automation. Now, they have become a staple of digital marketing, coding, and all types of online communication.

As previously mentioned, GPT engines are far more intuitive and versatile than traditional natural language processing models. This API differs from typical NLP services by being programmable for various tasks through prompt design, not just narrow tasks like sentiment analysis.
Text is processed in units called tokens, with a maximum model context length of 32,000 tokens (approximately 24,000 English words). With the current selection of top-quality models, using the OpenAI API is so affordable that implementing GPT is a logical choice even for minor tasks and automations (GPT-3.5 Turbo costs $0.002 per 1K tokens).
Right now, the ecosystem is becoming even more customizable thanks to the implementation of official plugins. The possibilities for integration are endless, and the process is easier than ever, with many no-code options available.
Dolly 2.0 + Databricks
Dolly, developed by Databricks, is a large language model (LLM) that has been trained to exhibit ChatGPT-like human interactivity, with a particular focus on following instructions.
Dolly 2.0's entire package has been open-sourced, including the training code, the dataset, and the model weights, all of which are suitable for commercial use. This means any organization can leverage Dolly to create, own, and customize powerful LLMs capable of interacting with people, without paying for API access or sharing data with third parties.

The model has wide-ranging applications across the enterprise. It can be used for summarization and content generation, which have already received positive feedback from initial customers. For instance, it can summarize lengthy technical documents or generate content for social media posts. Dolly aims to provide organizations with the power to create high-quality models for their domain-specific applications, without handing their sensitive data over to third parties.
Read more: How to Turbocharge Your AI & MLOps with Databricks & V7
LangChain
LangChain is a versatile and comprehensive framework for developing applications that leverage language models. It has a modular structure and offers extendable interfaces and external integrations for building any Language Learning Model (LLM) powered systems. LangChain supports a wide range of use cases, including autonomous agents, agent simulations, personal assistants, question answering, chatbots, querying tabular data, code understanding, Interacting with APIs, text extraction, summarization, and evaluation.
The ecosystem of integrated LLMs, systems, and products built around LangChain is fueled by a community of developers. You can also access a lot of comprehensive guides for integrating other products with LangChain. This makes LangChain a flexible, and community-supported framework for building applications and workflows that harness the power of language models.
Pinecone
Pinecone is a powerful platform designed to manage vector embeddings, which are crucial for building "long-term memory" for foundation models. These embeddings carry important semantic information in a way that is easy to process by LLMs. However, with a large number of attributes, these embeddings can be challenging to handle. That's where Pinecone comes in.

Pinecone simplifies data management with an easy-to-use interface for inserting, updating, and deleting data. It also offers efficient storage and querying capabilities, handling the complexity and scalability of these tasks. Pinecone supports distributed and parallel processing, real-time data updates, and metadata-based queries. It ensures data preservation through routine backups and selective indexing.
Integration is another significant aspect of Pinecone. It seamlessly melds with existing data processing ecosystems and facilitates easy integration with AI tools like LangChain, LlamaIndex, and ChatGPT's Plugins.
Chroma
Chroma is an open-source database designed specifically for managing embeddings in AI applications, with a particular emphasis on Large Language Models (LLMs). As a part of a new computing stack, Chroma gives LLMs the ability to maintain long-term memory, enhancing their capability to understand and interact with data.
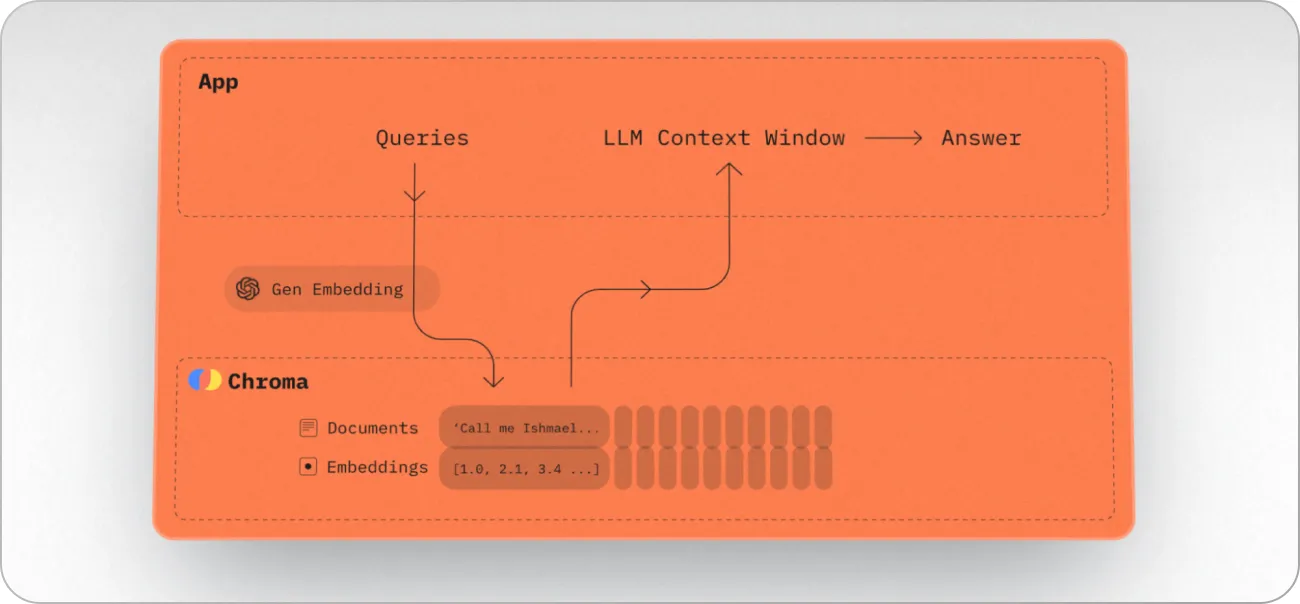
The database streamlines the handling of embeddings, enabling users to create collections for storing and managing embeddings, documents, and related metadata. Furthermore, it can automatically tokenize, embed, and index text documents. It also supports queries based on custom embeddings, allowing for precise and relevant data retrieval.
Chroma's inherent flexibility allows for easy integration with other AI development tools like LangChain. This ease of integration, coupled with its powerful features and scalability, positions Chroma as a pivotal tool for building AI applications, especially those involving LLMs. Future updates include the addition of features like automatic clustering and query relevance, further extending its utility in the AI development landscape.
HuggingFace, open source LLMs, and LLaMa derivatives
A recent report that leaked online suggests that major players in the LLM game are seriously worried about their lack of competitive edge against open-source solutions. Why pay for ChatGPT when you can deploy a local ChatGPT-like solution on your own for free and control everything? Well, for starters, some of the free options available right now should not be used for commercial purposes and don’t have a commercial use license. But it is only a matter of time before we have a plethora of options available that can be used for business operations.
While software development in the context of corporate processes is more organized, a community of AI enthusiasts are using open frameworks to run wild. The speed of progress and recent developments in the space of LLMs since the release of LLaMa by Meta has been astonishing, and some problems that were supposed to be addressed within months and years were solved by the community within days.
ElevenLabs
ElevenLabs is an AI-driven speech synthesis platform that renders human intonation and inflections with remarkable fidelity. It utilizes deep learning models to generate high-quality spoken audio in any voice and style, which expands storytelling tools for creators and publishers.
Although not an LLM itself, ElevenLabs can be seamlessly integrated with Large Language Models to complement their capabilities with highly realistic speech synthesis. This combination results in an enriched user experience, providing not only intelligent text responses but also lifelike spoken dialogues.
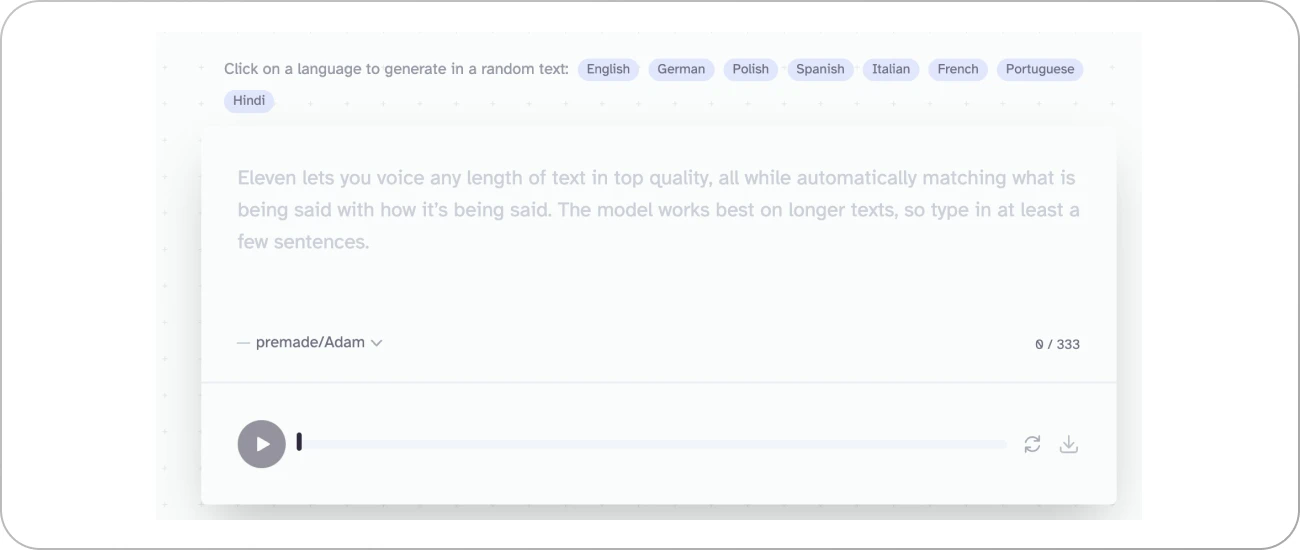
ElevenLabs excels at quickly converting any length of text into professional audio while automatically adjusting delivery based on context. This feature makes it perfect for a wide range of applications, including storytelling, news articles, and audiobooks. The platform's ability to generate emotions, including laughter, adds another level of realism to its audio output.











Potential challenges and considerations
Let's now revisit the three pivotal challenges mentioned at the beginning of the article: adoption rate, infrastructure, and regulation.
Adoption Rate
LLMs are already being used by programmers, marketers, and recruiters to solve daily tasks. But will customers embrace them? The beauty of these models lies in their seamless integration into existing processes, often invisible to the end customer. In most scenarios, users might not even know or mind whether a tech support query was handled by a human or a human-assisted AI.
Furthermore, LLM solutions like ChatGPT have attracted a diverse user base who find interacting with AI stimulating and straightforward. This trend might popularize conversational interfaces that have been on the horizon for years. Rather than navigating menus or utilizing tools, users may come to expect that their instructions will be executed upon issuing commands or prompts.
Infrastructure
This area presents a significant challenge. Currently, we can build workflows and connect OpenAI's GPT-4 or GPT-3.5 via an API, facilitating integration with virtually any system. We can also create advanced automations with no-code tools like Zapier. However, it raises the question: who will take the lead in this evolving landscape?
You may remember when OpenAI's DALL-E 2 Image Generator was released last year. It was a significant step forward in the space of generative AI, but soon after, solutions like MidJourney and Stable Diffusion also began to gain traction, advancing rapidly in the realm of visual foundation models.
With that in mind, while ChatGPT continues to dominate the headlines, the landscape for text-based AI is much more nuanced, with major players such as Microsoft, Meta, and Google entering the game.
Watch the replay of our webinar: What's Next for Large Language Models
Since Meta released their LLaMA foundation model as open source in late February, there has been an exponential increase in research and the creation of fine-tuned models. Initiatives like Open LLaMA aim to make these solutions more accessible for commercial use. It's now possible for anyone to deploy a ChatGPT-like language model on a personal computer and integrate it with any system they want, including vector databases. Emerging solutions in this space include Chroma, Pinecone, and LangChain.
Many companies now face a crucial decision: "Should we utilize OpenAI now, or should we opt for fine-tuning and employing an open-source solution for greater control and independence?"
Legal regulations and ethical concerns
This remains the biggest unknown for businesses looking to integrate LLMs and foundation models into their operations. As these models become more ubiquitous and powerful, it will be important for companies to stay up-to-date on any regulations and best practices surrounding their use. This includes issues related to privacy, data ownership, and the potential for biases in the models. It will be important for companies to prioritize prompt engineering and transparency in their use of LLMs and foundation models to ensure ethical and responsible deployment.
What are the next steps?
Large Language Models (LLMs) and foundation models have the potential to significantly impact the business landscape. These models are versatile and can be adapted to a variety of use cases, including automating customer service, content generation, and even autonomous problem-solving. The implementation of LLMs and foundation models in business operations requires careful consideration of the legal and ethical implications, as well as the need for human oversight and quality assurance. However, the benefits of utilizing these models, such as improved efficiency, cost reduction, and broader versatility, make them an attractive option for companies looking to stay ahead of the curve in an ever-changing technological landscape.
However, there are still many challenges that need to be taken into consideration:
LLMs offer a limited window of context (it can be 4K, 8K, or 32K tokens depending on the model or framework you are using) which limits their capabilities when it comes to processing bigger inputs without additional training
Few-shot prompting with multiple examples works best for producing high quality outputs but it can be difficult to incorporate in workflows that need multiple formats and types of generated messages.
Quality of your own training data for fine-tuning the foundation models is more important than ever. LLMs are great for generic tasks using information available online. But it also means that the advantage you can have over other companies using LLMs is the quality of your own datasets.
In conclusion, while LLMs and foundation models offer revolutionary advantages, their implementation can be challenging without the right knowledge and resources. However, the benefits of utilizing these models, such as improved efficiency, cost reduction, and broader versatility, make them an attractive option for companies looking to stay ahead of the curve in an ever-changing technological landscape. With careful consideration of legal and ethical implications, as well as the need for human oversight and quality assurance, LLMs and foundation models have the potential to significantly impact the business landscape.

Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

