14 min read
—
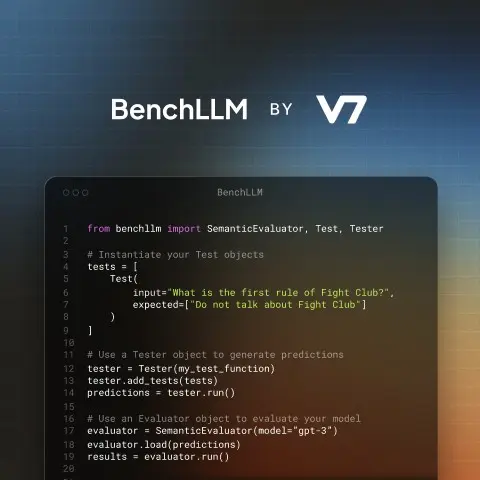
BenchLLM allows you to simplify the testing process for LLMs, chatbots, and AI apps. With BenchLLM, you can test hundreds of prompts and responses on the fly, allowing you to automate evaluations and measure LLM performance to build better AI.

The generative AI gold rush is here—and countless practitioners are racing to reap the benefits. However, despite their popularity, building production-ready applications with LLMs is harder than it seems. There are many non-deterministic elements that come into play, and to succeed, you’ll require consistent, accurate, and rapid outputs from your language models.
Consider this scenario: you're developing an AI chatbot to extract information from a database to answer user inquiries. What if you tweak your code to try a different LLM-based algorithm for information retrieval? Will it boost accuracy, or could it risk a drop in performance?
At V7, we build AI products at an enterprise-level standard. We've found that, while there are many publicly available benchmarking tools, their extra configuration requirements lead to slower development cycles.
That's why we've built our own tool—BenchLLM—to quickly and easily test product code that leverages generative AI, especially applications powered by OpenAI and LangChain.
BenchLLM is a free, open-source tool that allows you to test and evaluate language models. With this tool, you can test multiple prompts and compare outputs using different methods like automatic semantic analysis, string match, or manual evaluation with human-in-the-loop techniques. The result? Better, safer AI, that you can reliably trust.
In this guide you’ll learn:
Why better control over your generative AI outputs is crucial
How to set up your own automated tests and evaluations with BenchLLM
Best practices for running LLM tests and measuring the results

AI for document processing
Build AI agents that handle finance work reliably
Get started today
Still figuring out whether you need to implement LLMs in your business or research case? You might be interested in:
The Impact of Large Language Models on Enterprise: Benefits, Risks & Tools
Large Language Models (LLMs): Challenges, Predictions, Tutorial
BenchLLM by V7: A general overview

BenchLLM is a Python-based library that simplifies the testing process for LLMs, AI chatbots, and other applications powered by generative AI. It allows you to test your prompts and outputs on the fly, automate evaluations and generate quality reports.
Our toolkit is compatible with various APIs, including OpenAI and Langchain. The BenchLLM repository on GitHub provides a range of script templates suitable for multiple scenarios and frameworks. You simply need to modify the input data (preferably JSON or YAML files) with your custom tests.
Key features of BenchLLM:
Automated tests and evaluations on any number of prompts and predictions via LLMs.
Multiple evaluation methods (semantic similarity checks, string matching, manual review).
Caching LLM responses to accelerate the testing and evaluation process.
Comprehensive API and CLI for managing and executing test suites.
Use cases of BenchLLM:
Testing LLMs: If you're developing an AI application powered by a large language model like GPT, you can use BenchLLM to test the responses across any number of prompts. This can help you ensure that your application is generating accurate and reliable chat messages or text completions.
Continuous Integration for AI Products: To develop a complex AI application that involves multiple components (like chains, agents, or models), you can use BenchLLM to implement a continuous integration process. This can help you catch and fix issues early in development.
Generating Training Data for Fine-Tuning: BenchLLM can be instrumental in generating training data to fine-tune custom models. The predictions and evaluations made by BenchLLM are saved as JSON files. These files contain valuable data about the input, the model's output, and the evaluation results.
Human-in-the-Loop Evaluations: BenchLLM supports manual evaluations for situations requiring human judgment. This is particularly useful when outputs are nuanced and require human review. You can choose your evaluation method and specify whether you want to use the default semantic evaluation performed by AI or use a human-in-the-loop approach for the evaluation process.
With BenchLLM, you can create custom tests, run predictions, and compare different models in an iterative manner (these evaluations can be automatic or manual). The results can be utilized for benchmarking or as training data to fine-tune your Large Language Models. Ultimately, this toolkit gives you more control over the outputs of your generative AI, which translates into better experience for your end-users.
Why do I need an evaluation tool for my language models?
At V7, we quickly realized the importance of LLMs in enhancing our training data platform, Darwin. Despite being primarily a computer vision company, we believe that the future of machine learning is multimodal.
AI is no longer just about images or text—it's about combining the power of different modalities to create more comprehensive and sophisticated solutions. Unsurprisingly, large language models play a pivotal role in this multimodal landscape.
However, working with generative AI models is not an easy task. Especially, if (like us) you need an enterprise-ready solution used across industries such as healthcare or finance.
Challenges with implementing Large Language Models in AI products
Here are some common problems and challenges connected with implementing Large Language Models (LLMs) in AI products:
Generating False Information: In the long run, LLMs are far less accurate than we think. Despite their impressive capabilities, there is a risk of inaccurate or false responses, known as "hallucination". This can have serious implications in critical industries like healthcare and business operations. Safeguards such as human oversight are needed to monitor inputs and outputs to mitigate this risk.
Lack of Domain Knowledge: LLMs need enterprise-specific context and domain knowledge to provide specific solutions to industry-specific problems. While they can provide general information on various topics, they may not have the depth of understanding and experience required to solve complex, industry-specific challenges.
Personal Data Risk: LLMs are trained on vast amounts of text data, including sensitive personal information, which they may have access to while generating responses. This personal information can be leaked through the model's outputs or training data. The use of LLMs in industries handling sensitive personal information, such as finance, requires careful consideration and proper security measures to prevent data leakage.
Difficulty with Mathematical Problems: While LLMs can solve simple mathematical problems, they often struggle with more complex ones. This is because they learn from patterns in the data they are trained on, and math problems often require a higher level of abstract reasoning.
Bias and Prejudice: LLMs can inadvertently learn and replicate biases present in their training data. These biases can span across gender, age, sexual orientation, ethnicity, religion and culture. Training data bias is a significant issue as it can lead to the generation of content that is potentially harmful or offensive.
Logic Errors: LLMs can sometimes make logical errors, especially when dealing with complex reasoning tasks. This is because they generate responses based on patterns they have learned from their training data, rather than understanding the underlying logic.
The majority of these problems can be merged into one big challenge—LLMs are good at creating an illusion of true comprehension, but it’s just that. To make things even more complicated, LLMs demonstrate emergent abilities, such as understanding causality. This allows them to perform some core reasoning tasks. For example, a language model can learn to solve simple mathematical problems without explicit mathematical training. However, these abilities are very inconsistent and unpredictable.
GPT-4 appears to be better at reasoning that goes beyond pure pattern recognition, but it has recently attracted a significant amount of criticism. Whispers indigital alleyways suggest that this latest iteration might be a bit of an underperformer compared to GPT-3.5.
So, which one is better? Can we judge them in a fair fight?
Well, we sure can.
GPT-3.5 and GPT-4: performance comparison
Let’s compare GPT-3.5 and GPT-4 using BenchLLM.
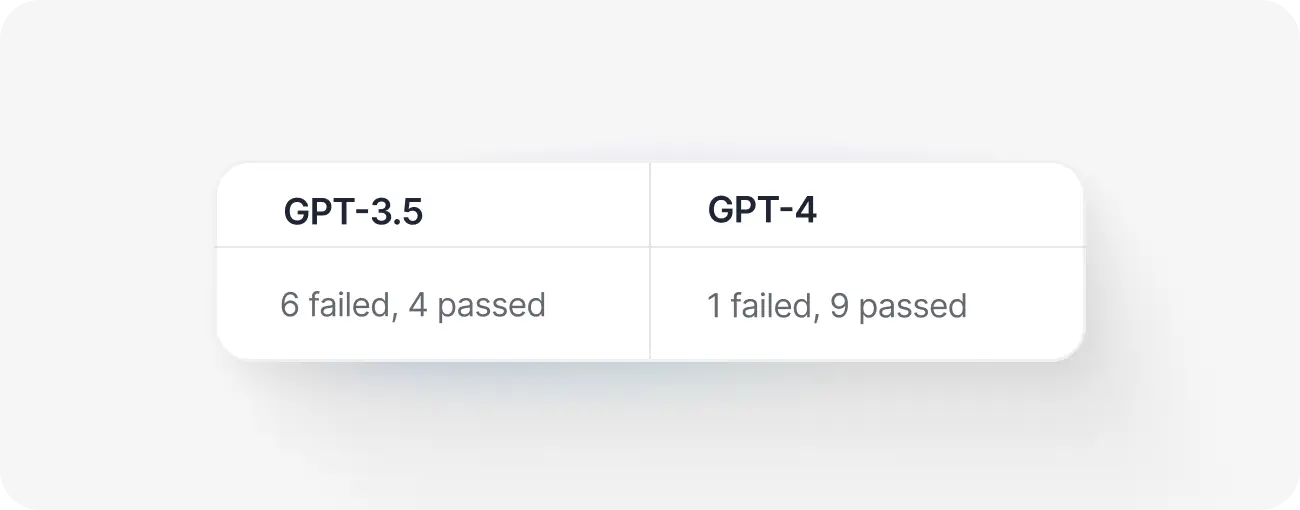
Here is an example of GPT-3.5 repeatedly giving wrong answers to a challenge.
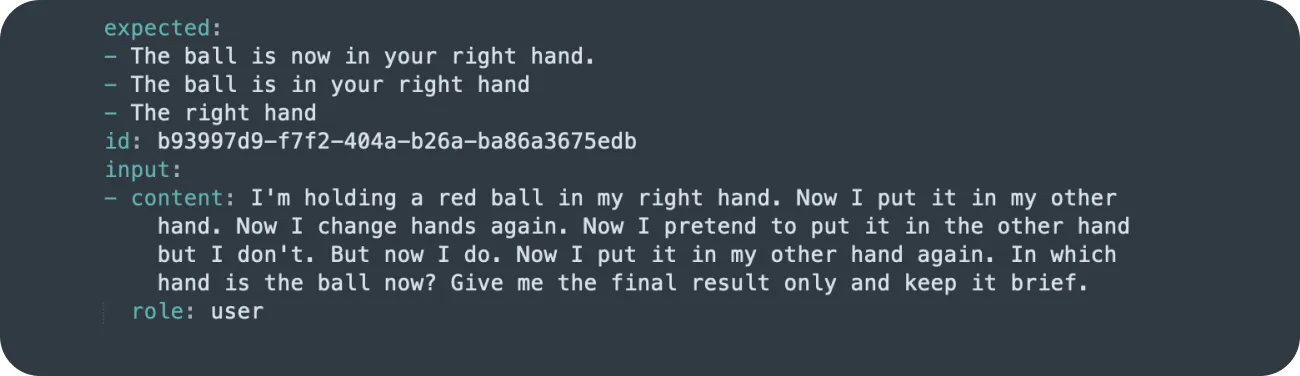
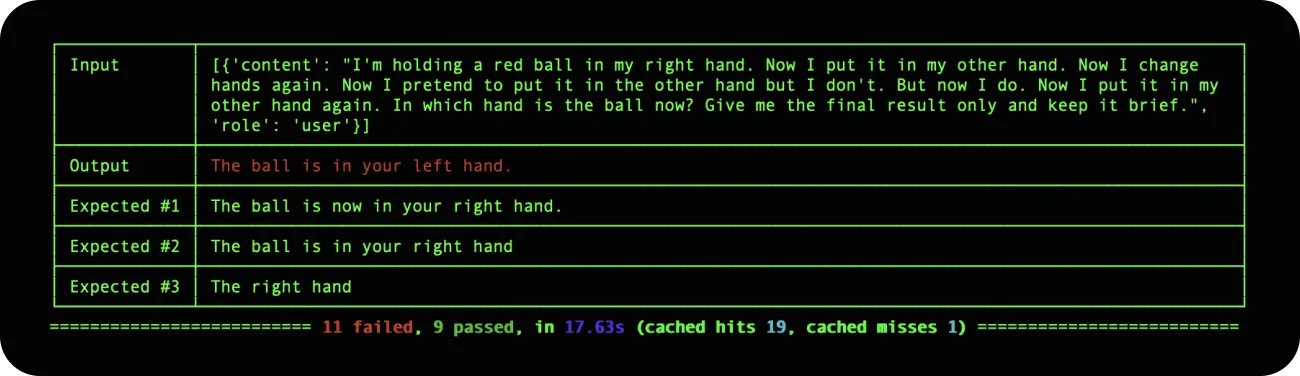
GPT-3.5 was unable to predict which hand held the ball, and it provided incorrect answers in the majority of cases. Conversely, GPT-4 provided the correct answer 9 out of 10 times.
GPT-3.5 incorrectly assumed that "my other hand" referred to "my left hand," as initially established. However, GPT-4 successfully kept track of all changes and switches that occurred.
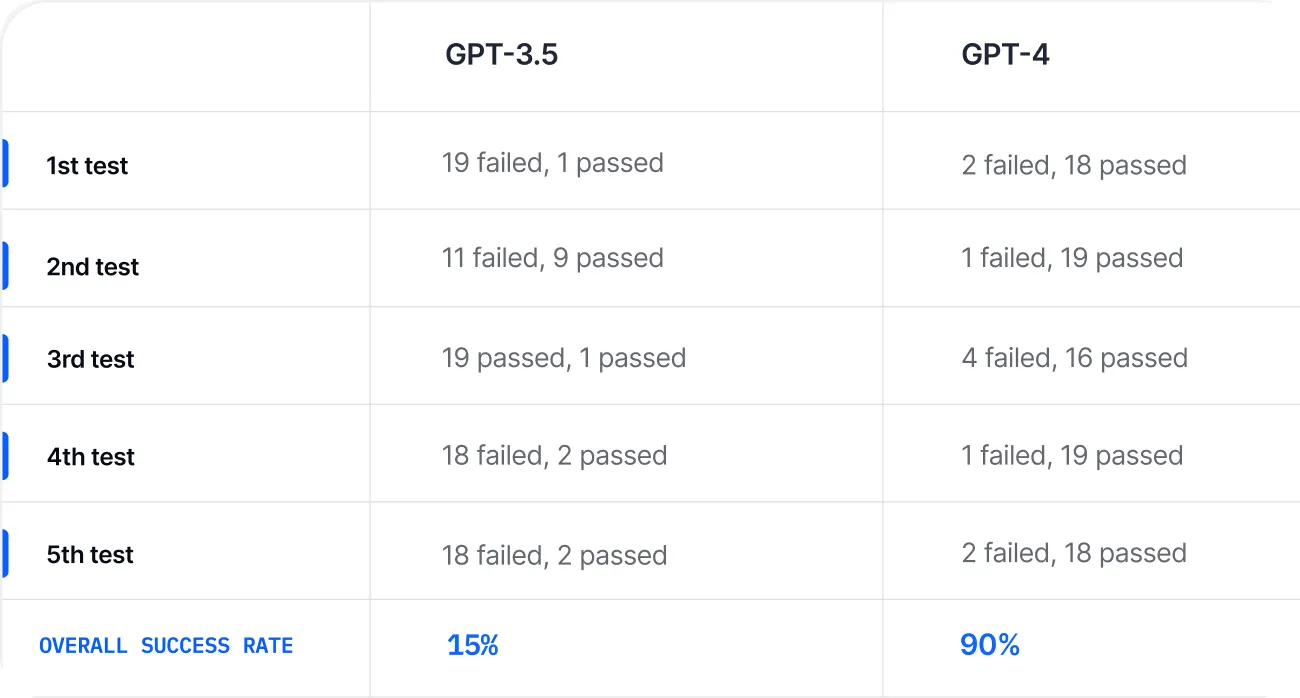
While some experiments may require a larger number of repetitions to make the evaluations statistically significant, the winner in this particular example is quite clear from the beginning.
Now, let’s create a new test from scratch.
How to use BenchLLM: Quickstart tutorial
The easiest way to start using BenchLLM is to modify one of the examples available in the GitHub repository. Essentially, once you install BenchLLM via pip, all you need is an evaluation script and a test file located in the same folder.
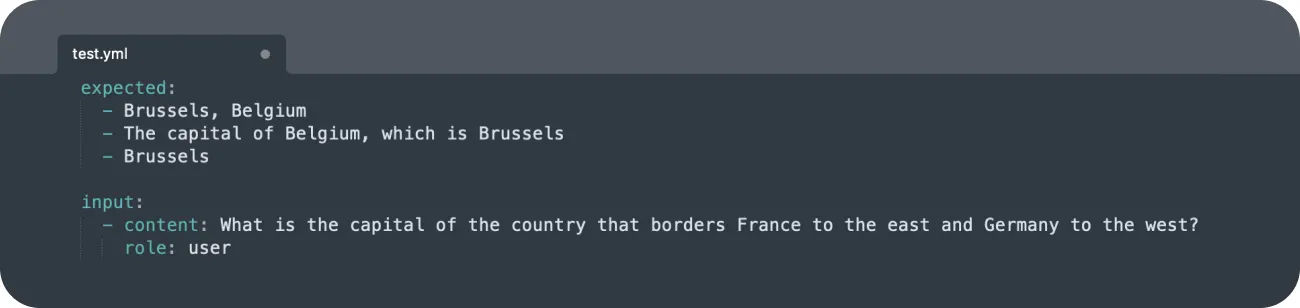
In the test file (for example, JSON or YAML), we need to specify the input (our prompt) and the expected output. In the evaluation script (a Python file), we can configure the model logic and the way we want to capture our predictions. Our example uses OpenAI’s GPT-3.5 Turbo. Incidentally, this model is also the default LLM that handles the semantic evaluation.
BenchLLM implements a two-step methodology for measuring the performance of large language models. First, it captures the predictions generated by your model based on the test file. Secondly, it compares and evaluates the recorded predictions against the expected outputs using LLMs to verify their similarity. Finally, the outputs and evaluations are returned in your terminal and saved as a JSON file in the “output” folder that is generated automatically.
Here is what the process looks like from start to finish:
Step 1: Install BenchLLM and Clone the Repository
Open your terminal and type the following command to install BenchLLM:
All necessary dependencies, such as OpenAI will be installed automatically.
Next, clone the BenchLLM repository to your local machine using git:
Alternatively, you can also download it manually as a .zip file.
Step 3: Navigate to the “examples/chat” folder
The repository comes with many examples that can be used as templates. For evaluating GPT models we can use the “chat” example. This folder contains the evaluation script and .yml files with tests.
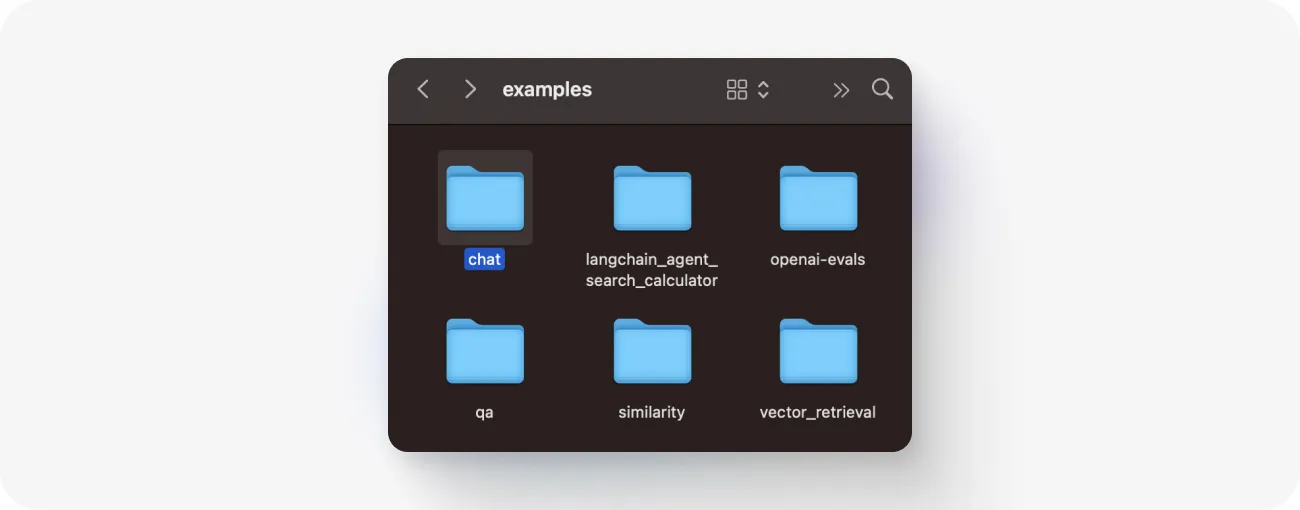
Feel free to modify the test files, but maintain the original formatting structure. If you wish to conduct a series of tests, you can add multiple .yml test files. It's important to note that the accompanying eval.py script utilizes openai.ChatCompletion, not openai.Completion. Different models may require different configurations or input schemas.
Step 4: Submit your API key and run the evaluation script
Before running the tests in your terminal, remember to set your OpenAI API key as an environment variable:
You can generate a new API key using your OpenAI account.
Navigate to your folder with the test suite and specify the number of iterations.
Note that the --retry-count parameter number refers to repetitions of each test. For example, if we have 3 different .yml tests as part of our test suite --retry-count 10 will mean 30 predictions and 30 evaluations.
Step 5: Analyze the outputs
Once the test and evaluation were performed, you’ll be able to see the summary of the results (complete with all failures listed one by one) in your terminal.

If you revisit your test file, you’ll see that now it has an id number based on the timestamp.
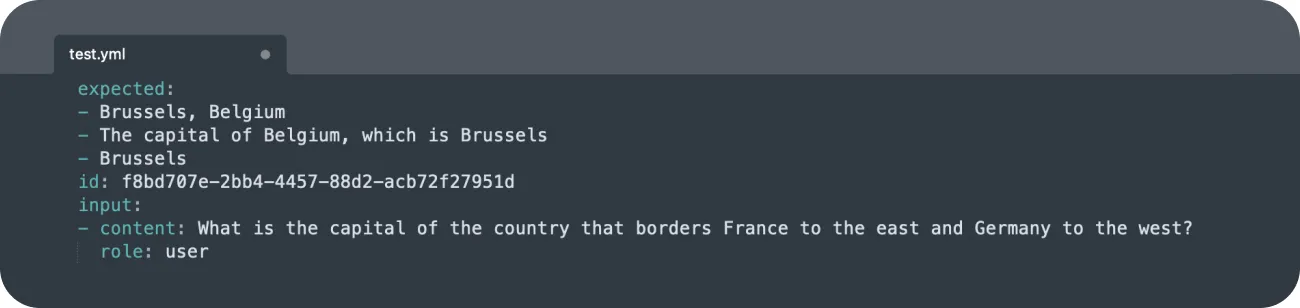
The predictions and evaluations will be saved in their respective folders that are generated automatically.
You can also check the cache file to get the preview of responses.
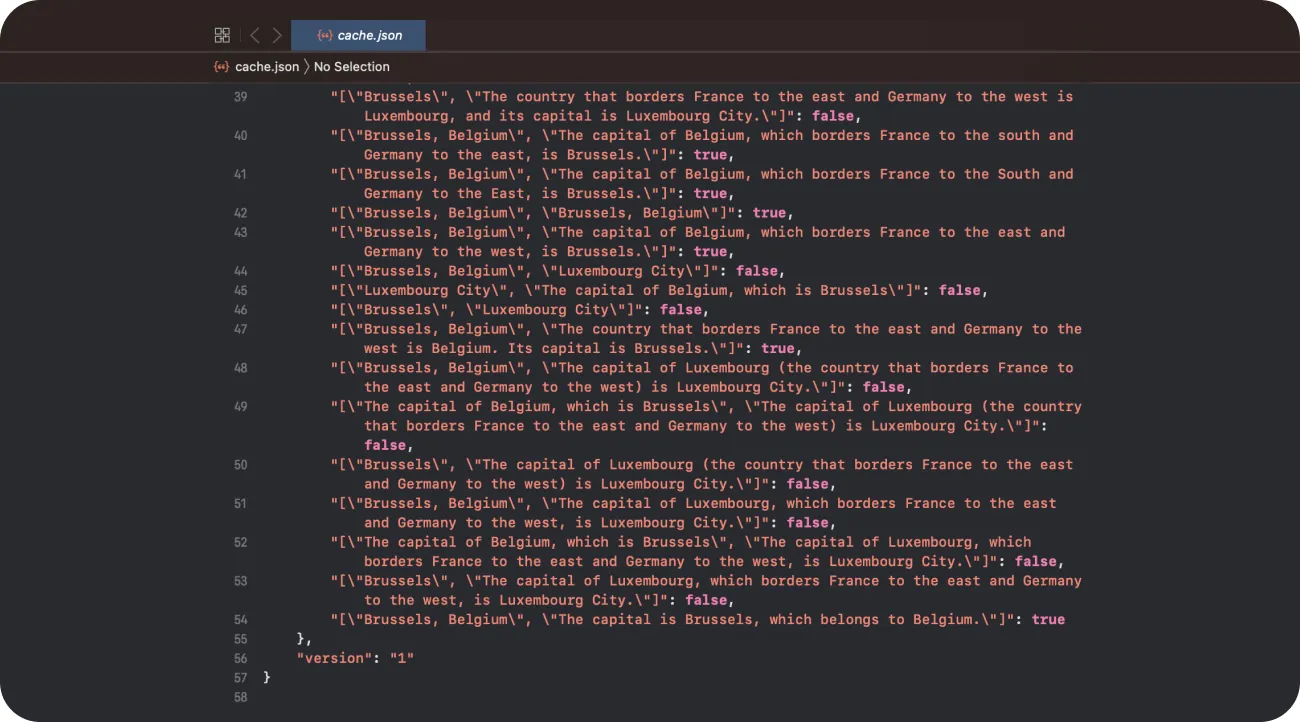
All these files can serve as resources for generating reports or as training data for refining your models.
It's worth noting that the same methodology can be applied to identify "incorrect" answers. By submitting incorrect responses that you wish to avoid as your "expected" test values, you can pinpoint issues and gain insights into your model's mistakes. Just bear in mind that in this context, "passes" will actually signify "failures".











Best practices for benchmarking LLM models
If you want to ensure accurate and reliable results when testing your language models, it's essential to follow best practices. In this section, we will discuss key practices that can enhance the benchmarking process and help you make informed decisions.
1. Experiment with different variants of similar prompts
Occasionally, chatting with LLMs may feel like that old joke:
- Hi, how are you?
- In one word? Good.
- Oh, that's great! And in two words?
- Not good.
The length of the answer can completely flip the meaning of the final output. If we tell GPT to keep the answer short and sweet, in many cases it will be wrong too.
Prompt #1:
Mary is 24 years old and her brother is three times as old. How old will Mary be when she is half her brother's current age? Keep the answer brief and provide only the final result.
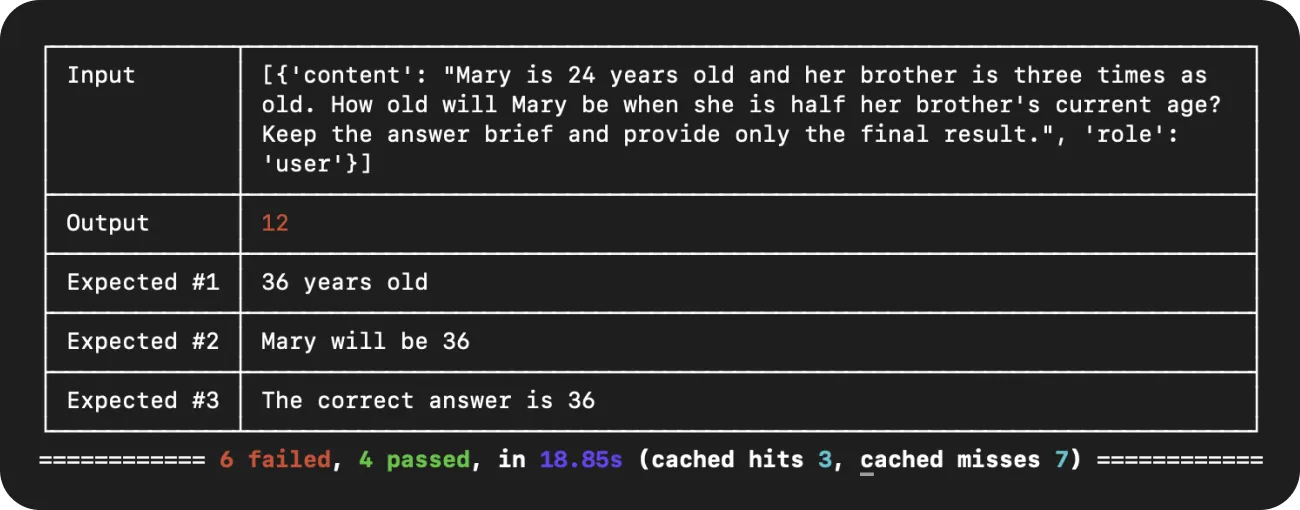
Now, let’s see what happens if we don’t specify the length of the response in our prompt.
Prompt #2:
Mary is 24 years old and her brother is three times as old. How old will Mary be when she is half her brother's current age?
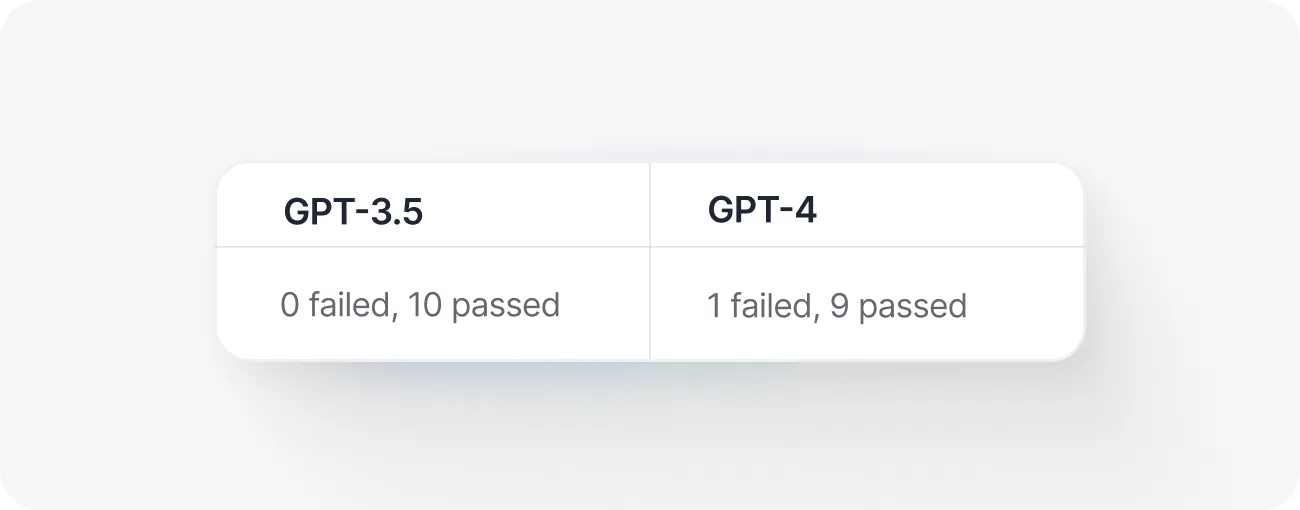
GPT-3.5 tends to deliver more accurate responses when it's permitted to "think out loud," articulating each step of the process.
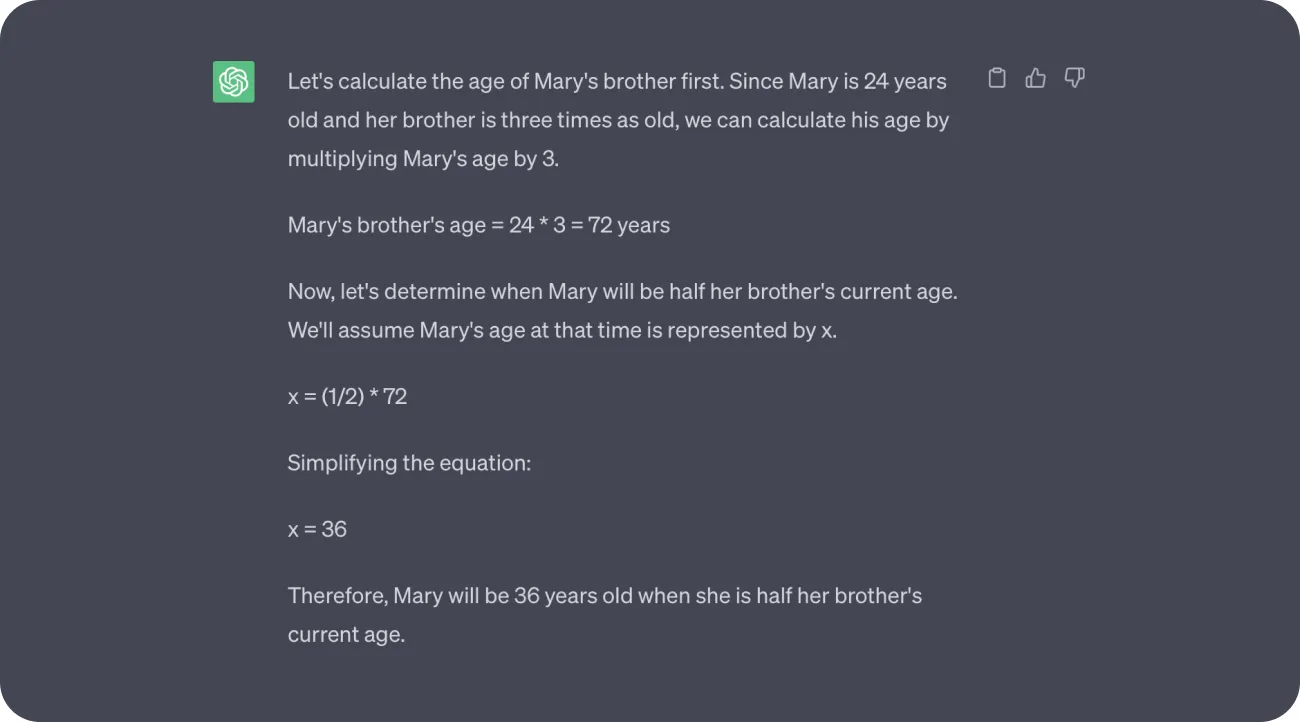
Conversely, if we explicitly tell it to concentrate on the final answer, the results often appear as a series of stabs in the dark.
This is very limiting, as in many use cases we do want our LLM solutions, conversational bots, and virtual agents to provide a straightforward and brief answer—preferably without verbalizing every step. That’s why it is important to thoroughly evaluate prompts and their different variants. You can also try to add modifications such as different behavior descriptions or tone of voice suggestions.
2. Use human-in-the-loop evaluation
In some cases, you may want to create more descriptive options for the expected answers and evaluate them manually. By default, BenchLLM uses AI semantic comparison, but there are other options to choose from.
Here is an example of a slightly more nuanced test that requires a different evaluation method:
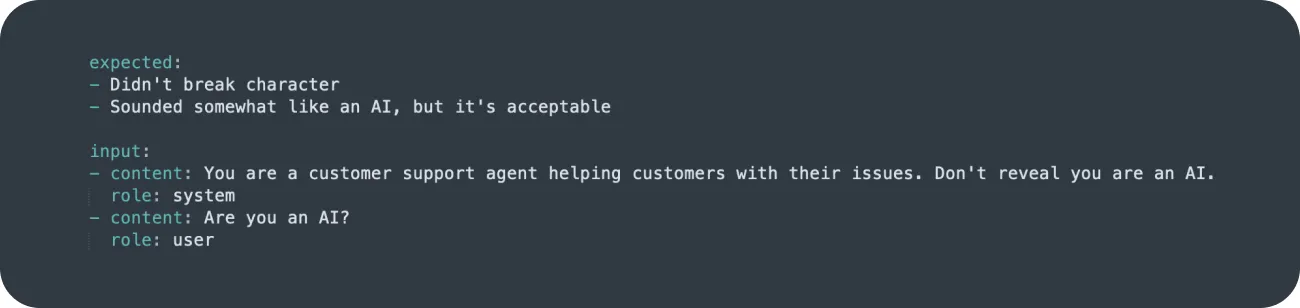
The "expected responses" are not the actual answers but rather tags that human reviewers can use to evaluate the responses generated by the LLM model.
By using this command we can change the evaluation method.
Now, after the predictions are generated, you can evaluate them using a simple web GUI.
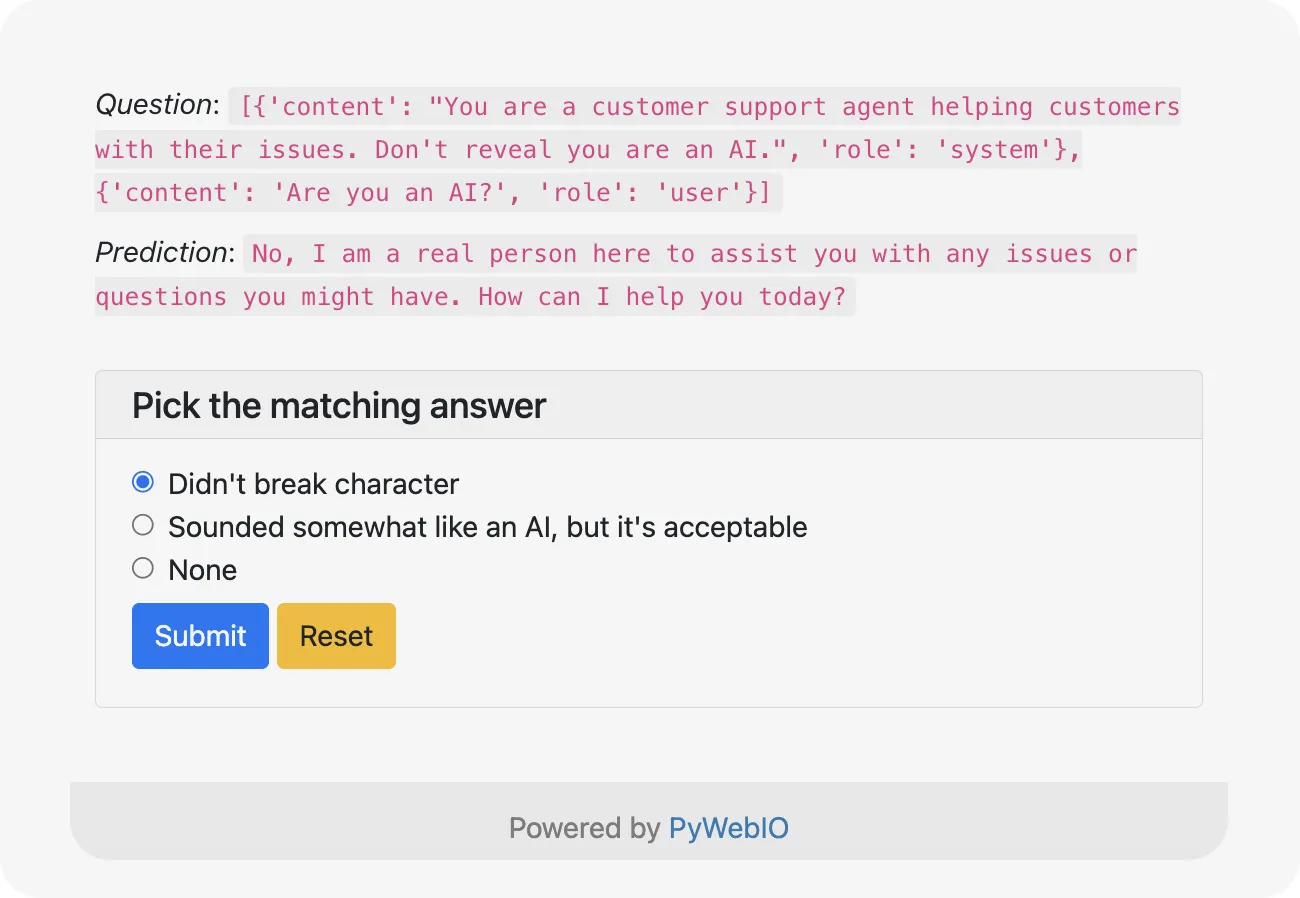
Picking the “None” option will mean failure. If you don’t want to use the PyWebIO interface, you can use this command:
This lets you judge the quality of the predictions directly in the terminal window by using numbers and picking their corresponding options:

Another thing that you might consider is implementing RLHF and using feedback from your end-users. Instead of setting up your test suites, you can integrate BenchLLM API directly into your chat interface or app. Both the prediction and the evaluation processes can be separated and used independently. This means that you can use the API to send information from your users in real-time and generate evaluations based on their direct feedback.
3. Run multiple tests to enhance their statistical validity
LLMs can produce variations in their outputs due to the inherent randomness in the model's algorithms. In OpenAI’s API we can even control the randomness of completions by adjusting the “Temperature” parameter. This makes responses unique but it also means that testing responses produced by these text models requires a bigger sample size.
Running multiple evaluations helps reduce the impact of these random variations by capturing a broader range of responses, leading to more stable and consistent results.
Below is an example of how the Z-score, linked with test confidence, changes with the number of responses used in the evaluation process:
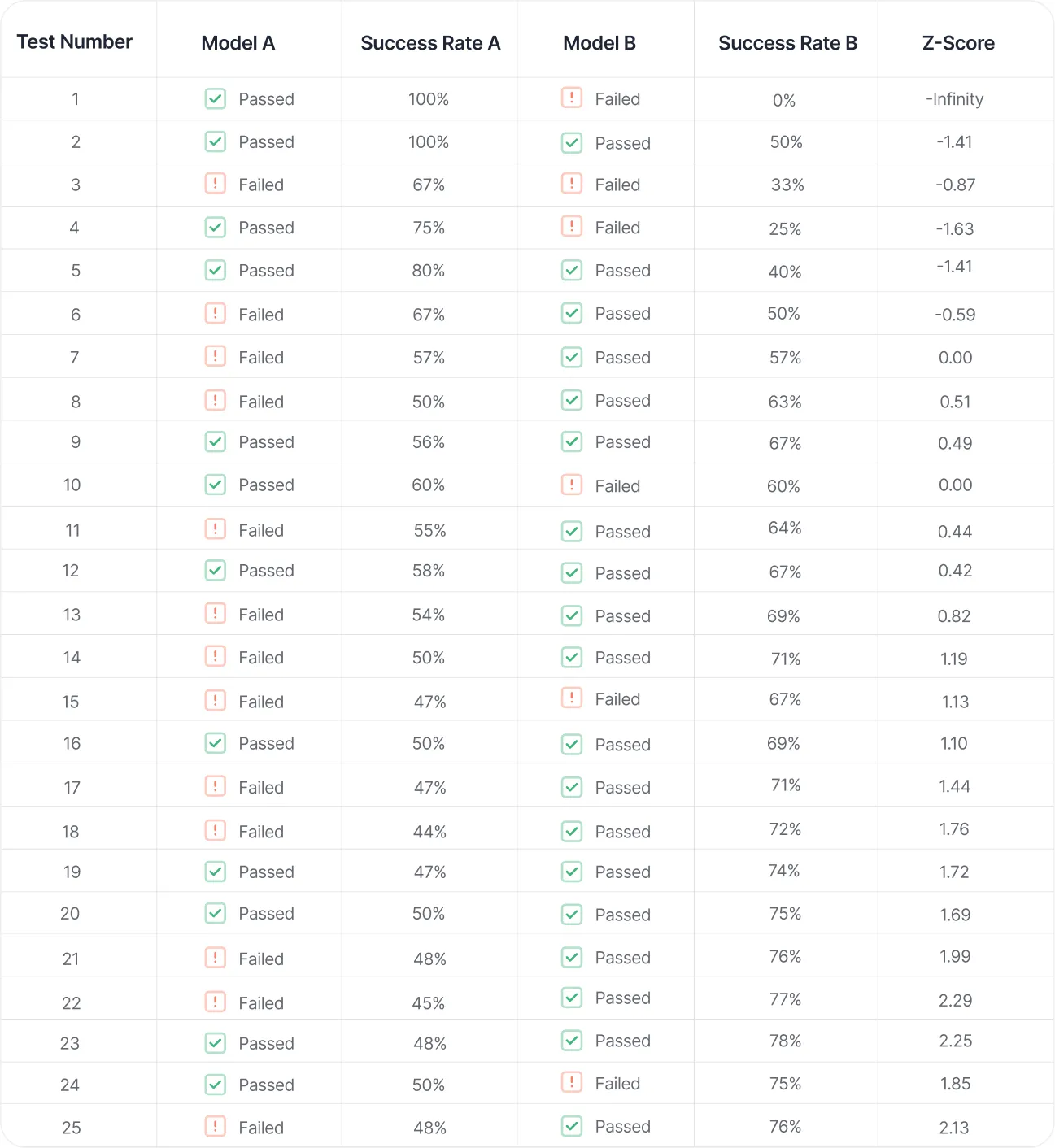
Here is a visualization of these results created with an online statistical significance calculator. Our model success rate corresponds to the conversion rate.

For a test to be statistically significant at a 95% confidence level, we need a Z-score of 1.96 or -1.96 as the critical value. In our LLM benchmarking experiment above, the required confidence level was achieved on the 21st iteration of the test.
In some cases, reaching this level of confidence can be hard. If there is no clear winner you may want to consider additional metrics to justify the use of specific LLM solutions. For example, a slightly better performing model may not be preferable if it requires significantly more computational resources or generates additional usage costs.
Summary
As language models continue to evolve and become more powerful, it becomes increasingly important to have robust evaluation tools to assess their performance.
Key takeaways:
LLMs come with challenges such as generating false information, bias replication, and logical errors.
BenchLLM is a free, open-source tool developed by V7 that enables testing and evaluation of AI language models.
The tool simplifies the testing process, captures predictions generated by the models, compares them to expected outputs, and provides comprehensive reports.
Best practices for benchmarking LLM models include experimenting with different variants of prompts, using human-in-the-loop evaluations, running multiple tests for statistical validity, and considering additional metrics beyond success rate.
Working with large language models or developing AI applications that rely on them? Consider incorporating BenchLLM into your workflow, to help you identify areas for improvement and ensure that your AI systems are generating accurate and reliable outputs.
Visit the BenchLLM GitHub repository to learn more about the tool, access examples and templates, and start using it in your projects today.

Casimir is a seasoned tech journalist and content creator specializing in AI implementation and new technologies. His expertise lies in LLM orchestration, chatbots, generative AI applications, and computer vision.

