Build breakthrough AI models.
Join leading AI research labs and Fortune 100s.







Create high-quality training data.
V7 supports all your labeling needs.



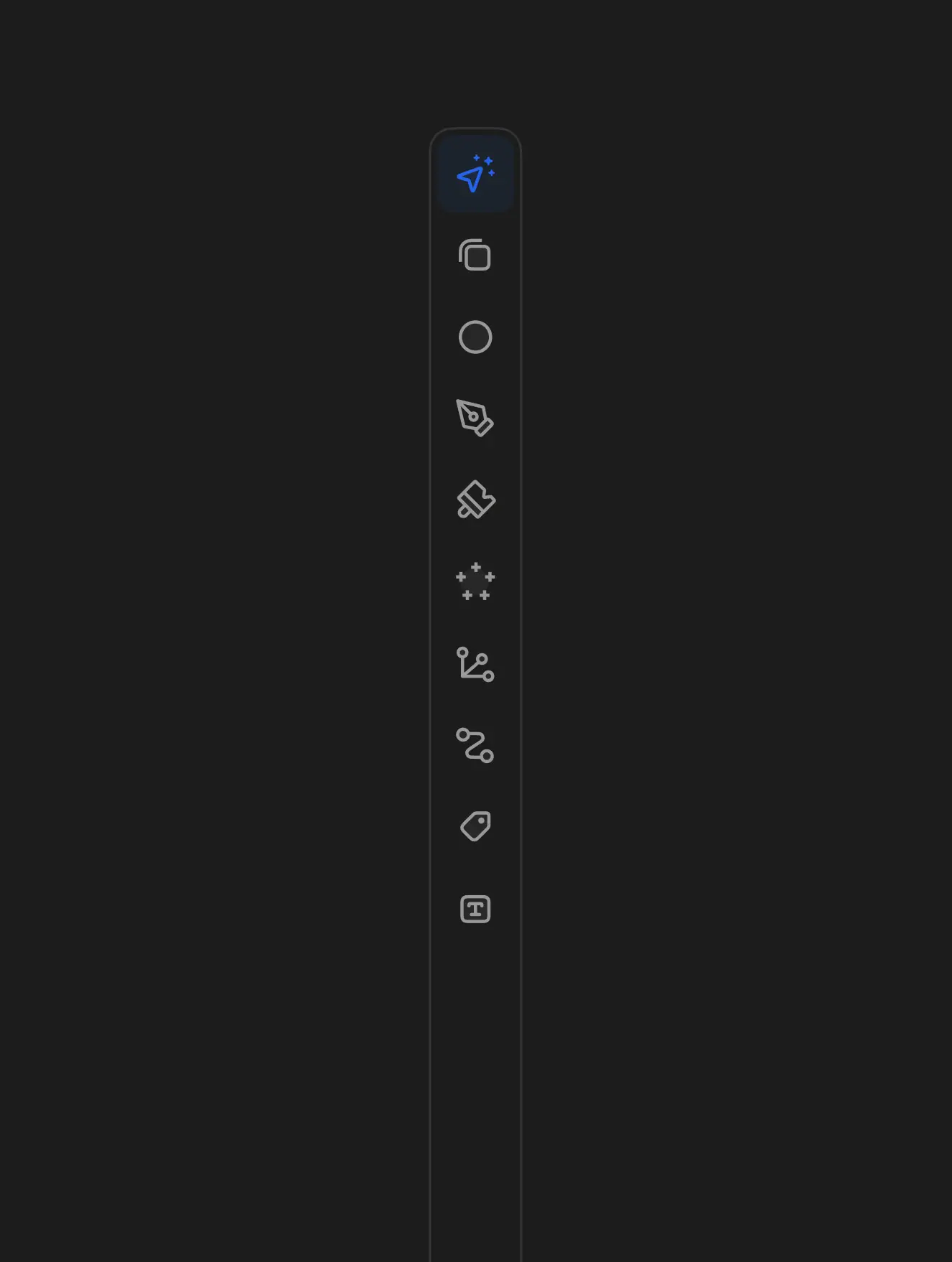
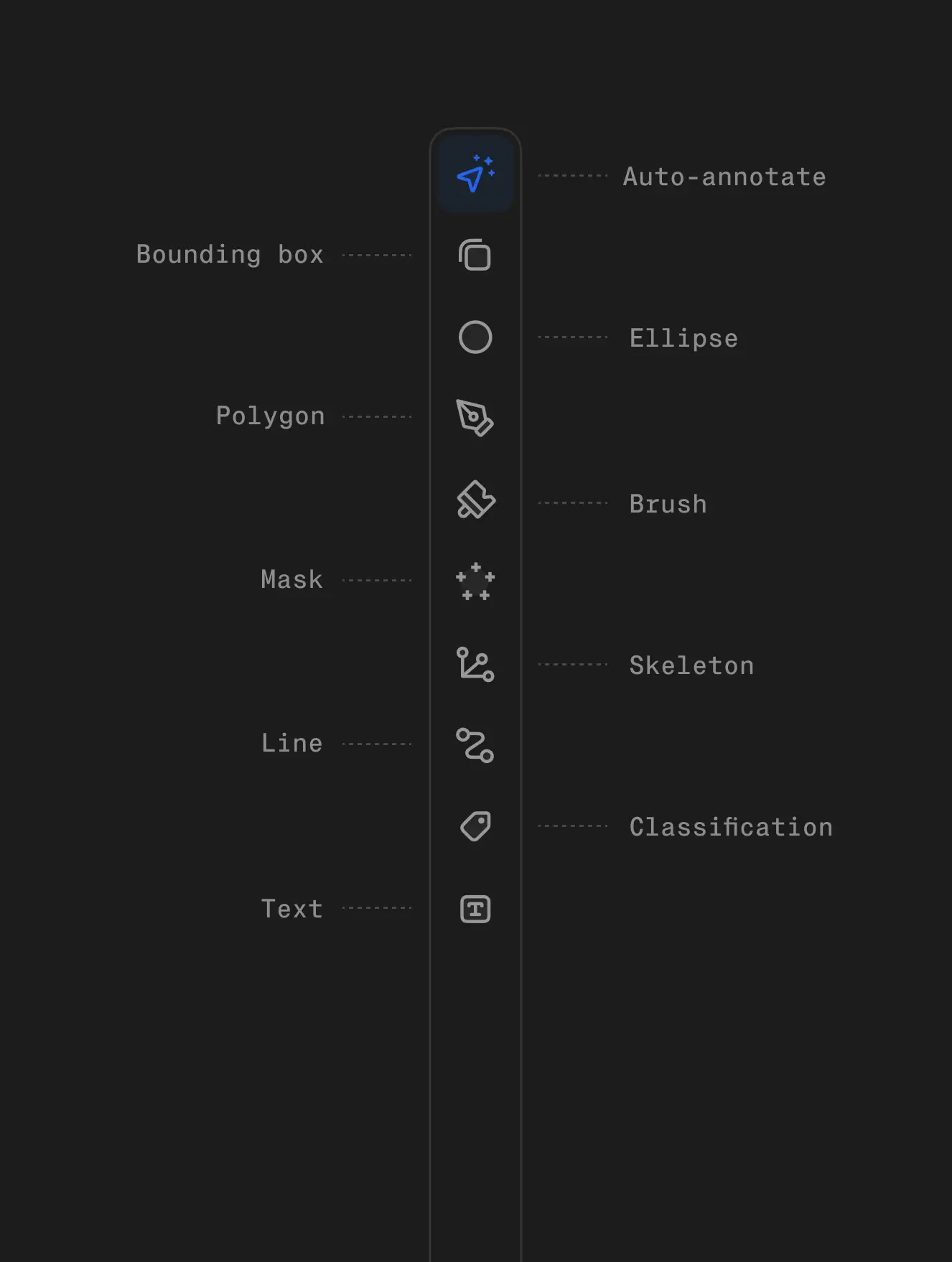






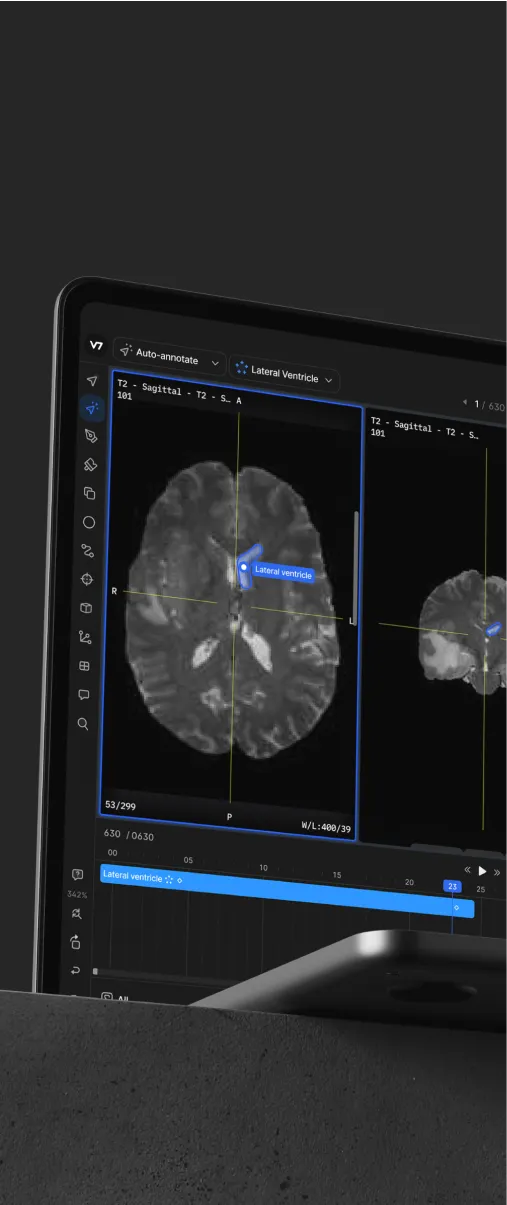
For many AI teams, creating high-quality training datasets is their biggest bottleneck. Annotation projects often stretch over months, consuming thousands of hours of meticulous work. V7 can speed up data annotation 10x, turning a months-long process into weeks.
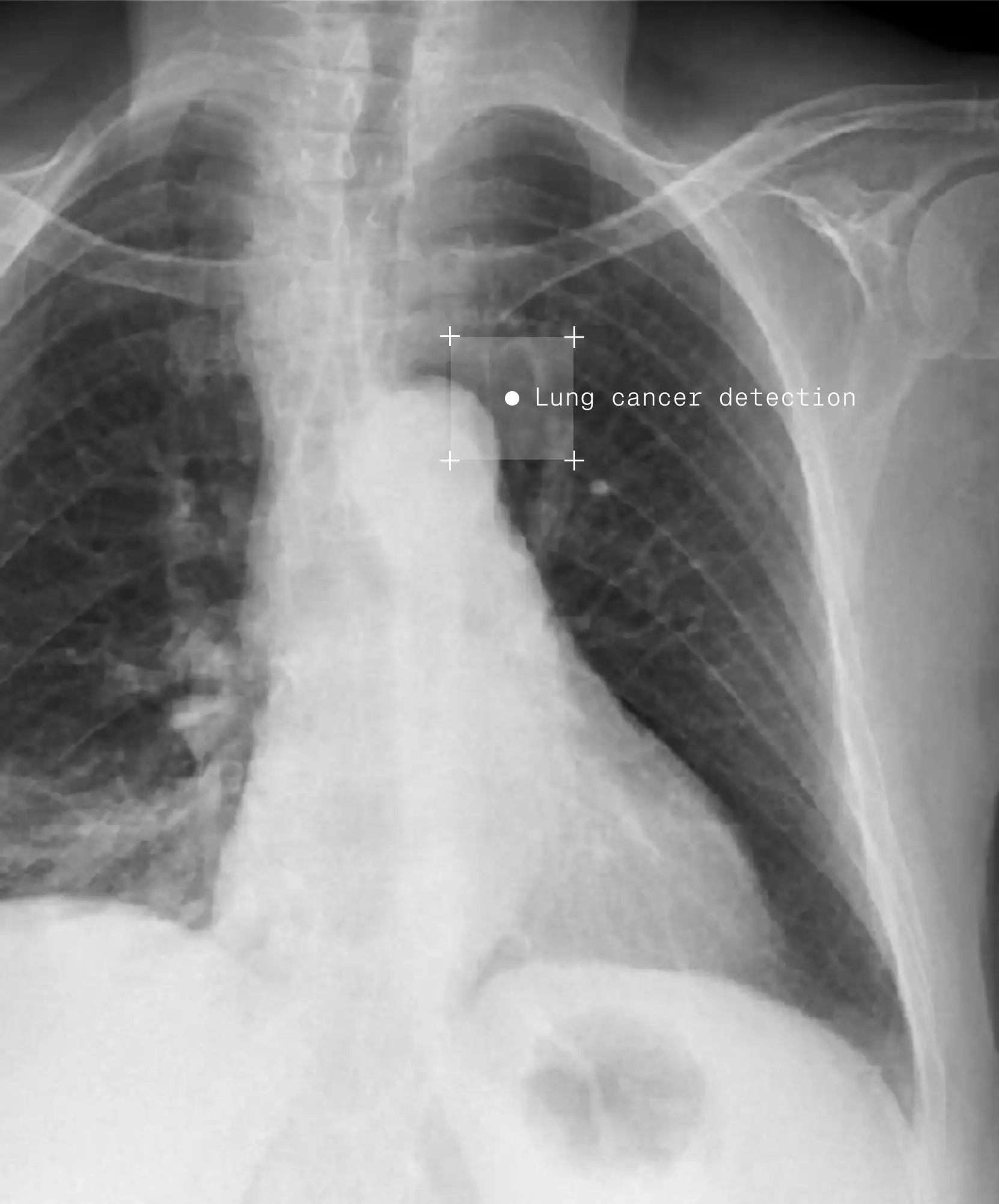
Use intuitive interface and AI-assisted tools to turn complex labeling tasks into a few simple clicks and adjustments. Work with any size dataset and file type, from videos, PDFs, and architectural drawings to specialized medical formats like SVS or DICOM.

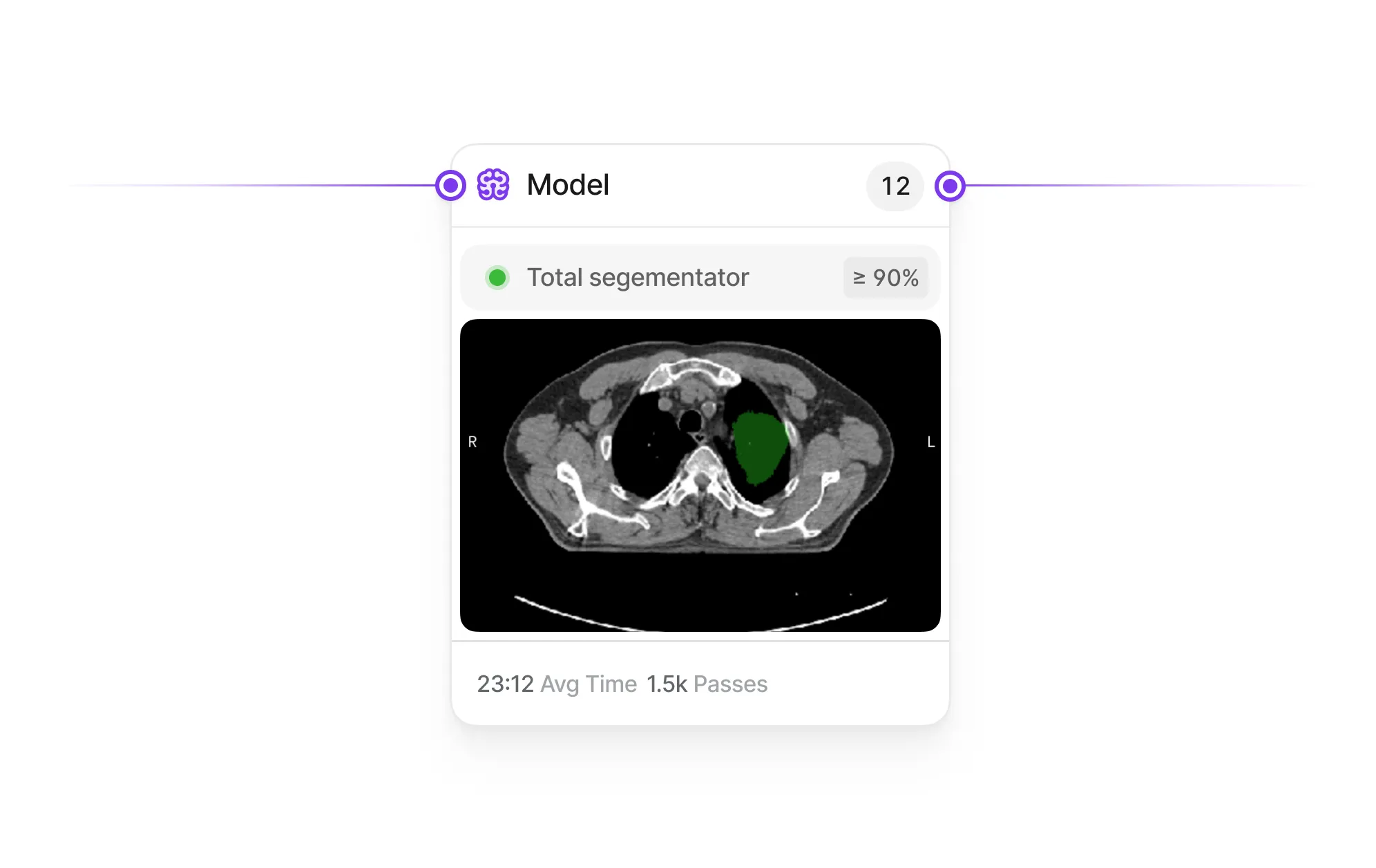
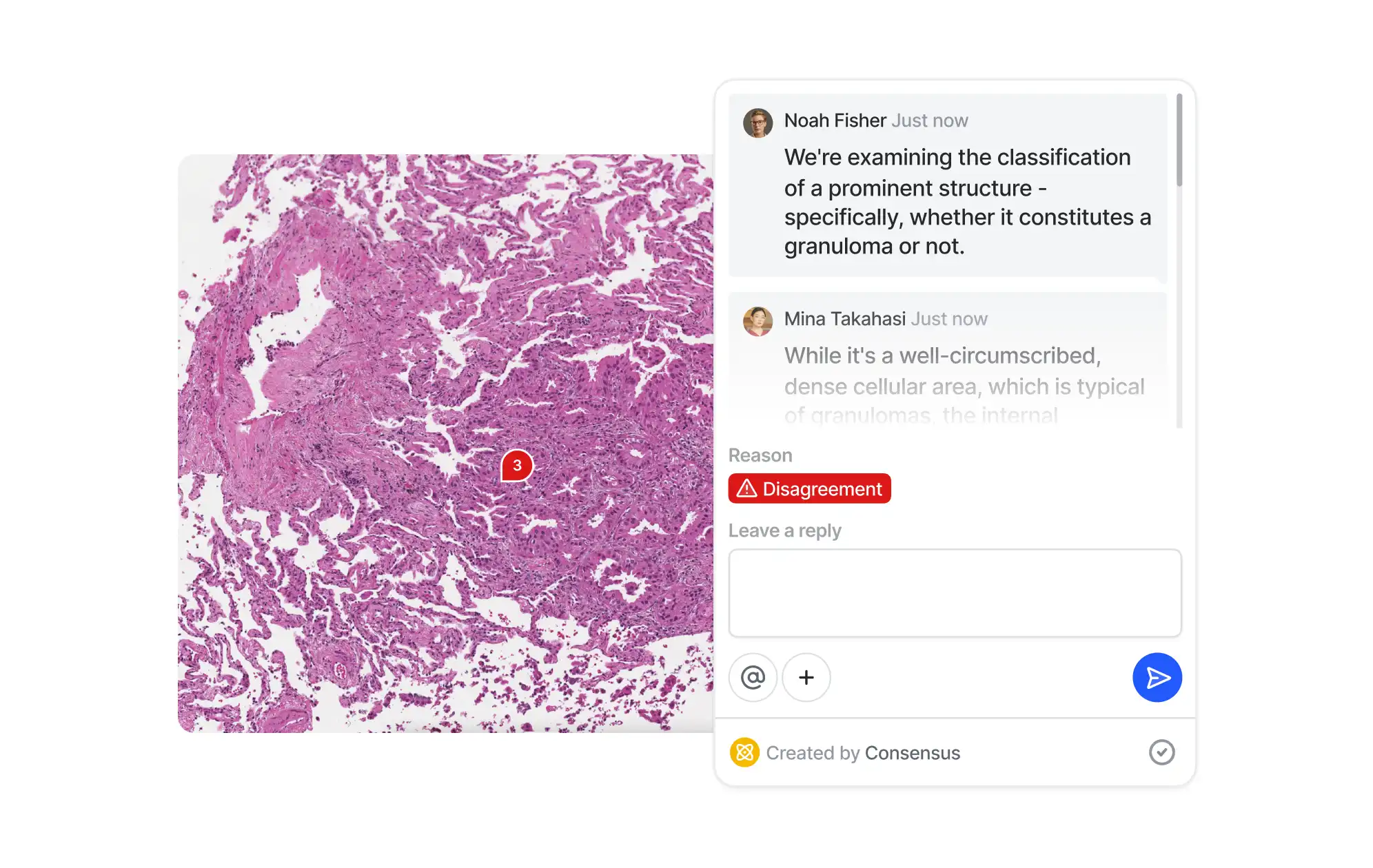
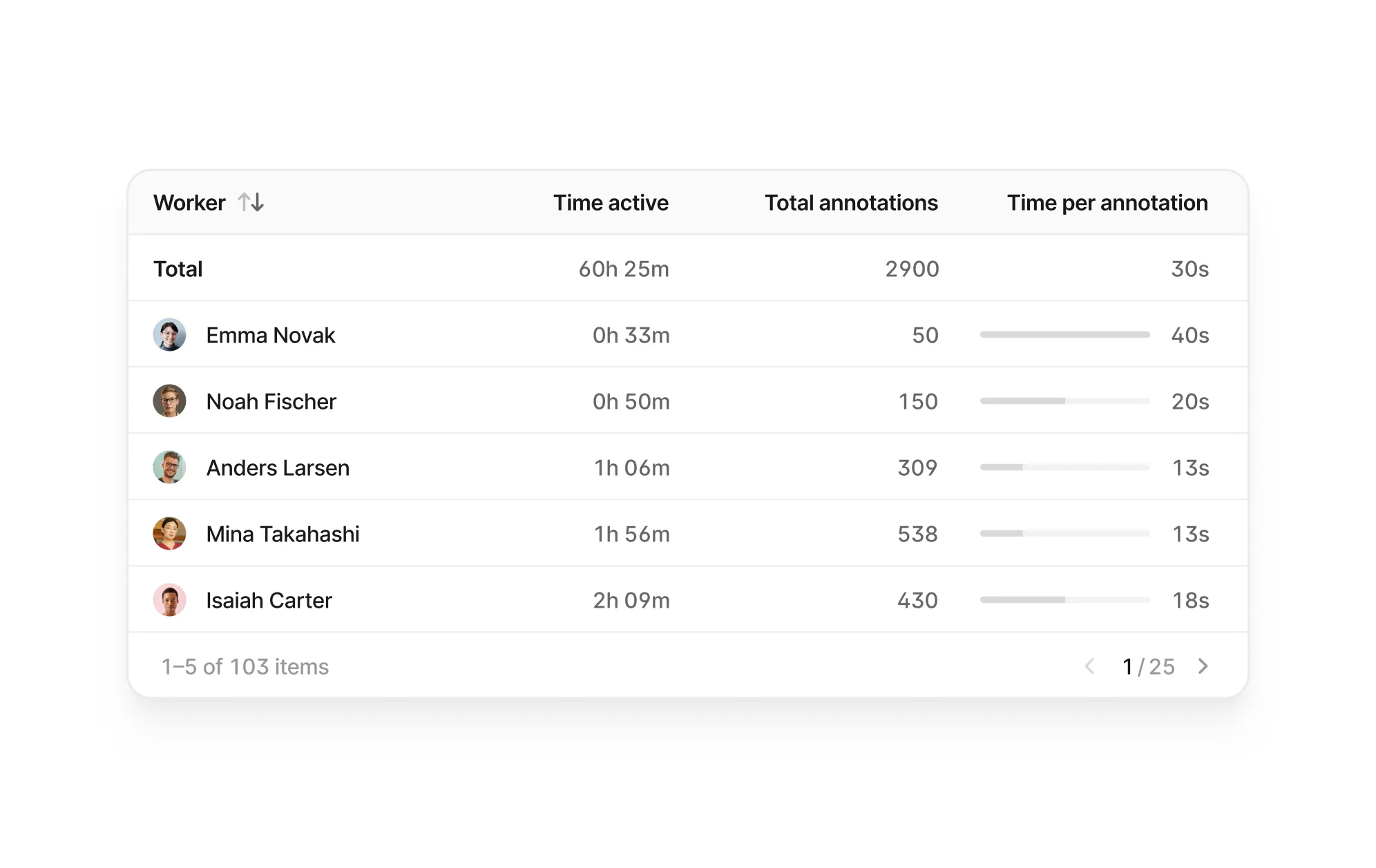
As annotation projects scale, AI teams struggle to track progress, maintain QA standards, and ensure accountability. Inconsistencies can quickly compound, leading to compromised data quality—which impacts the entire AI development lifecycle.
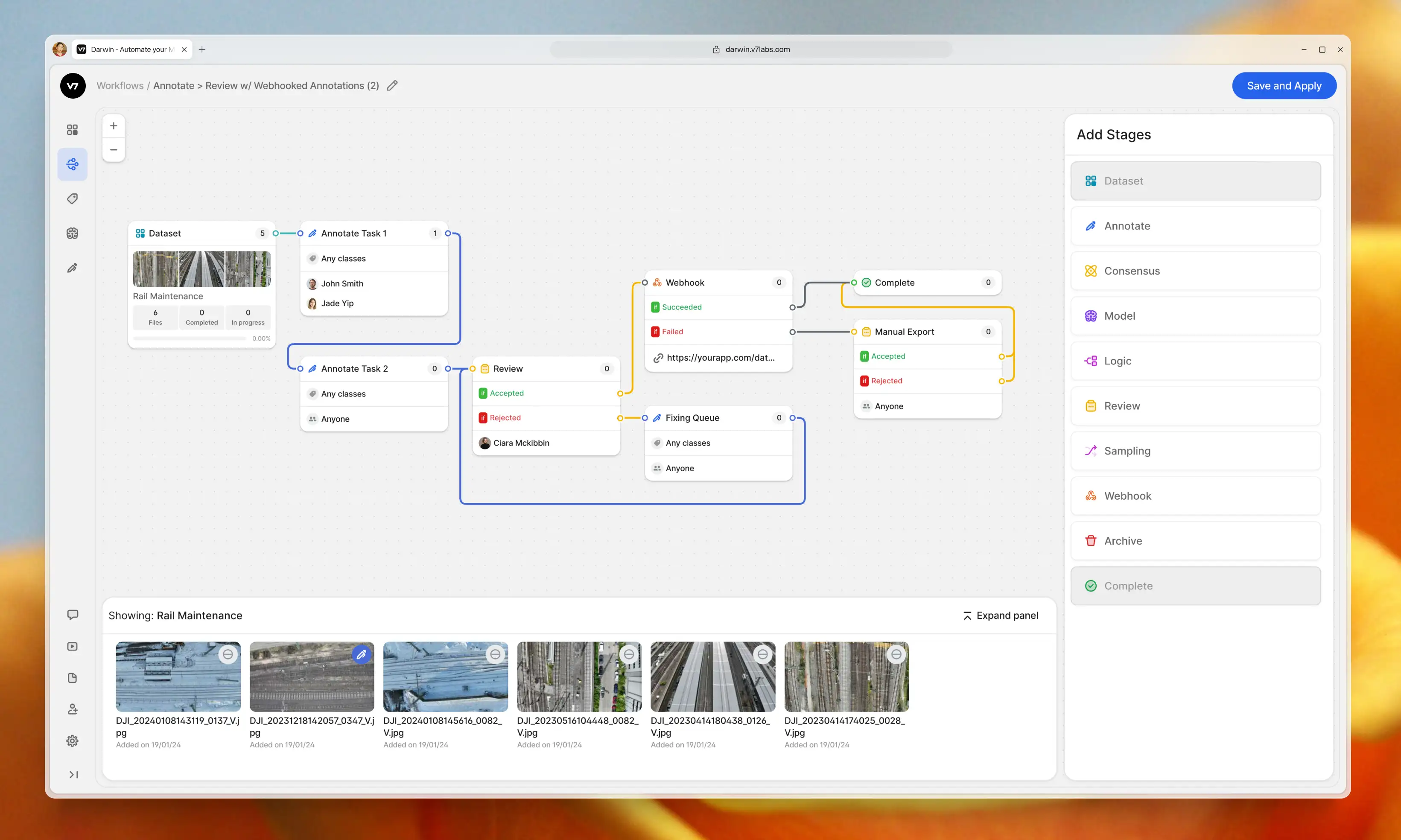
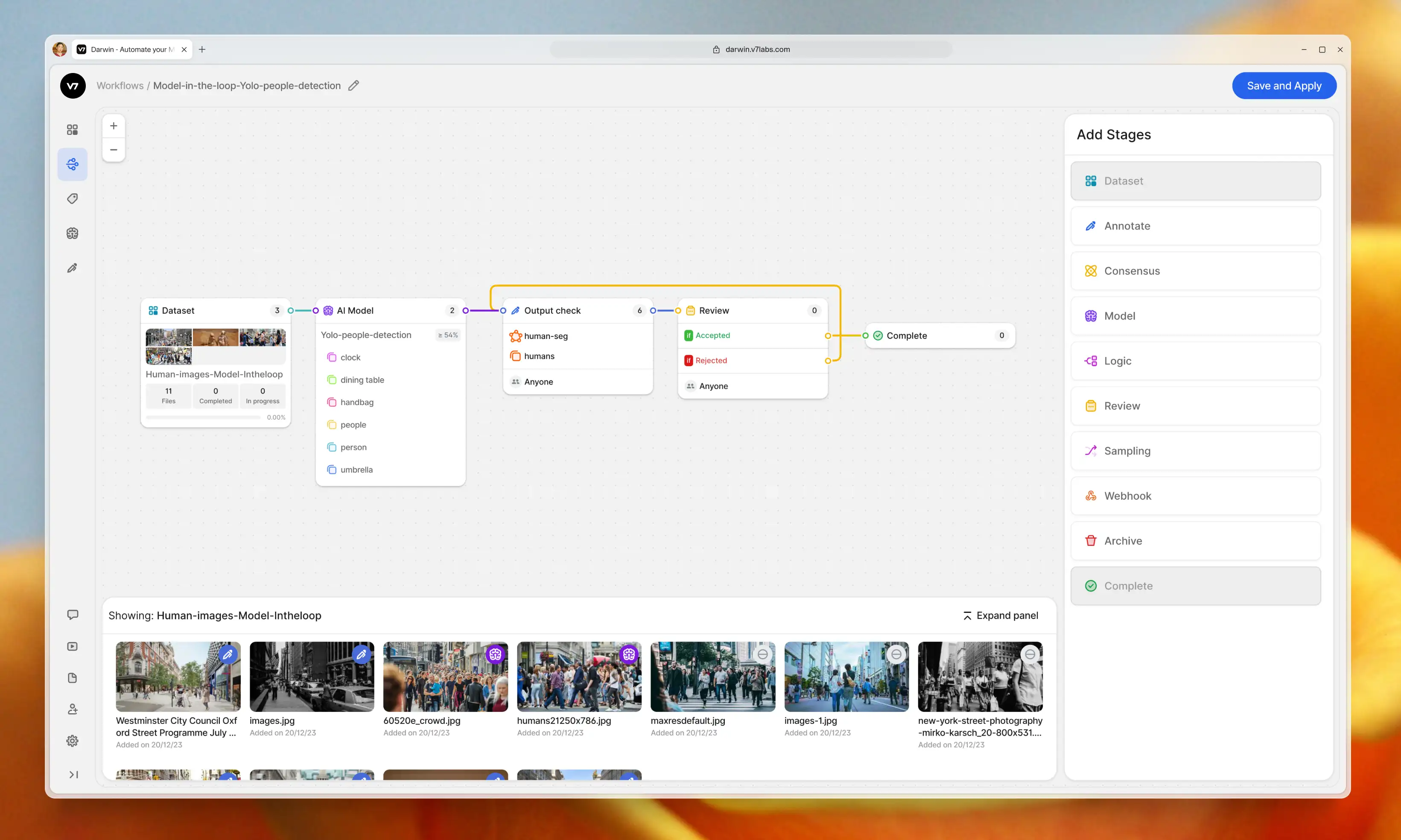
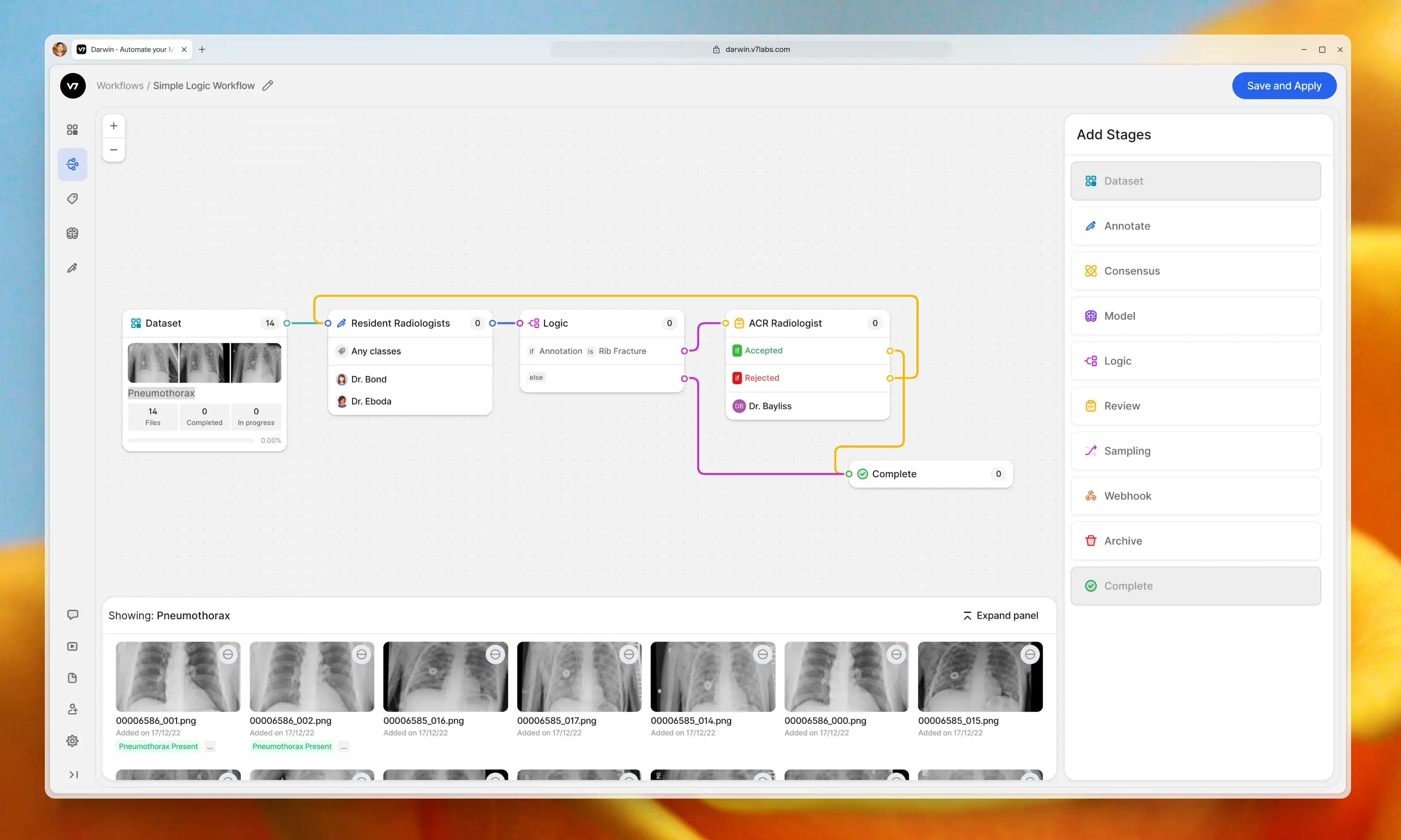
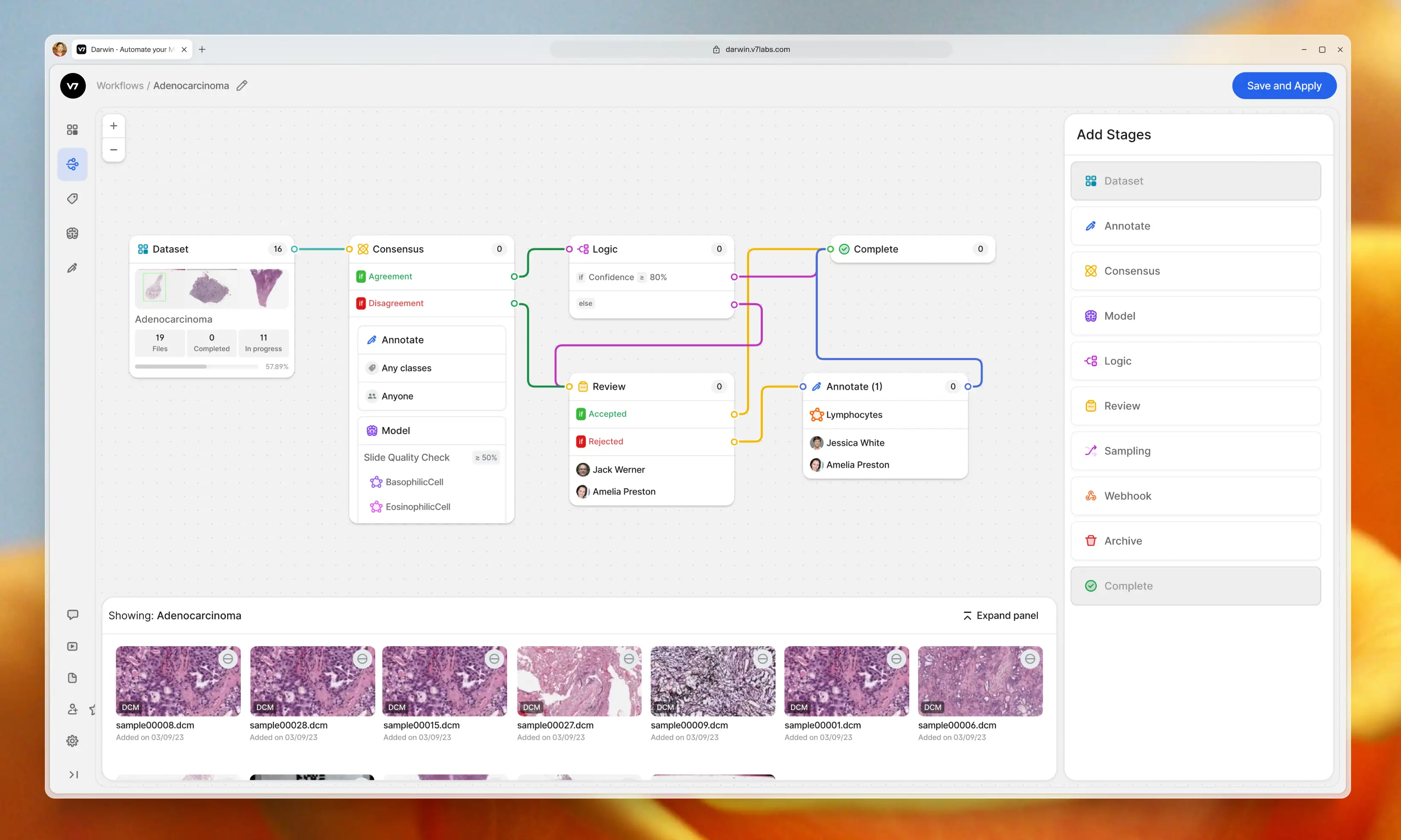
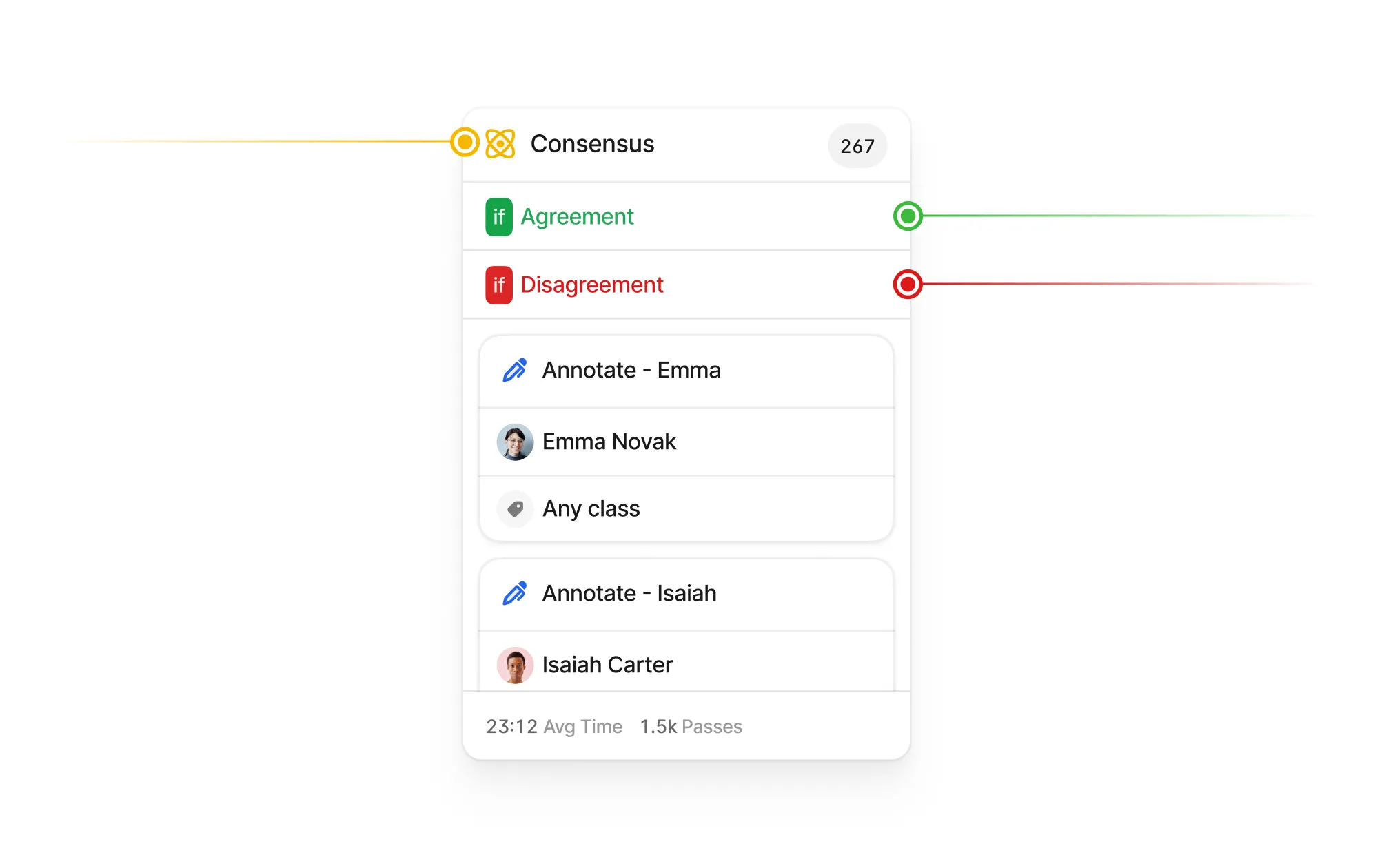
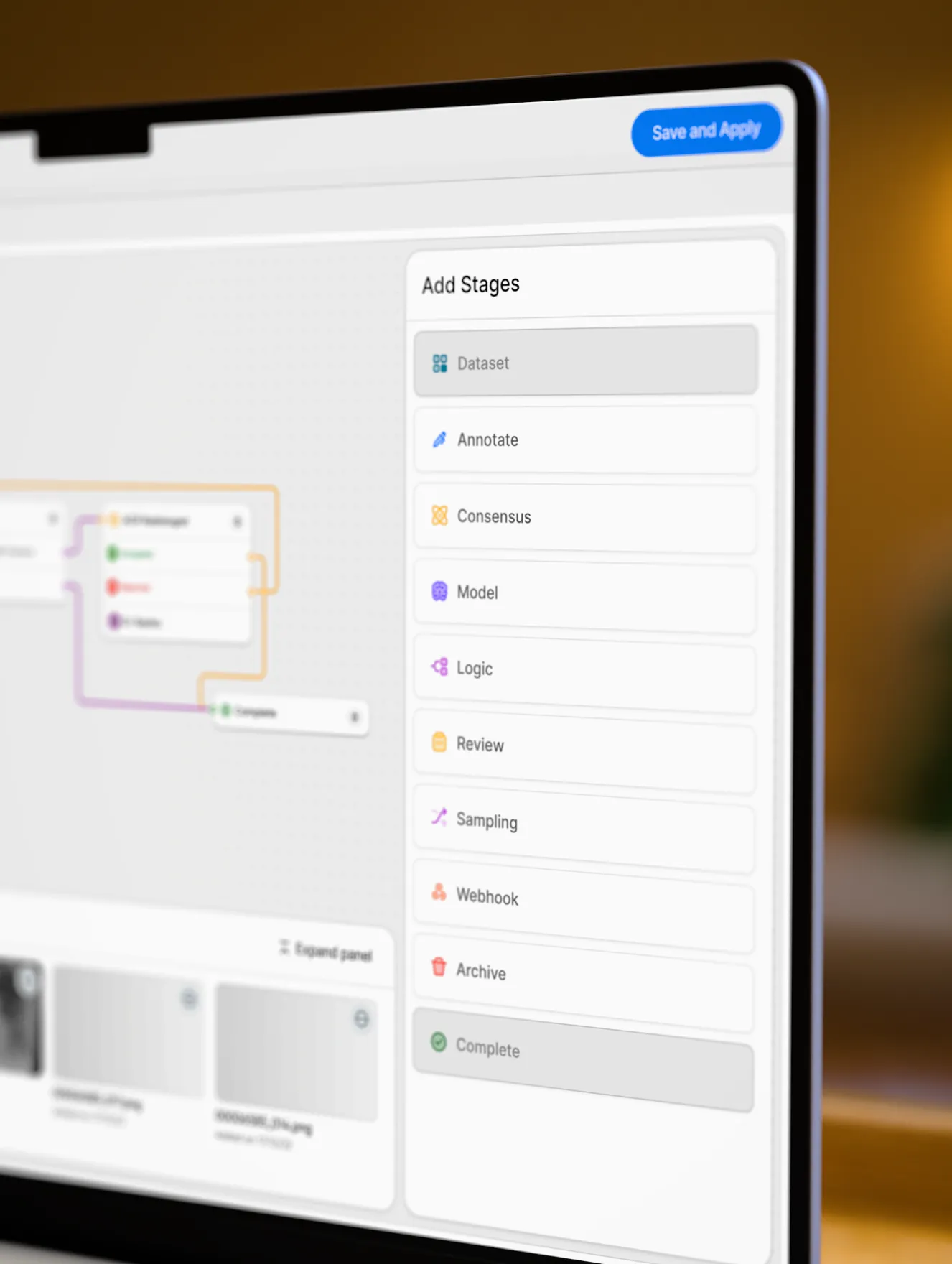
V7 allows you to design multi-stage review workflows to orchestrate your labeling process. Assign roles, tasks, and manage project completion. Use conditional logic and automations to always route data to the right stages or team members.